TPAMI 2020 | U2Fusion:一种统一的无监督图像融合网络
01 论文信息
- 论文题目: U2Fusion: A Unified Unsupervised Image Fusion Network
- 论文作者: Han Xu,Jiayi Ma,Junjun Jiang,Xiaojie Guo,Haibin Ling
- 发表单位: 武汉大学,哈尔滨工业大学,天津大学,纽约州立大学石溪分校
- 发表会议\期刊: TPAMI 2020
- 代码链接: https://github.com/hanna-xu/U2Fusion
02 论文主要贡献
1.提出了适用于多种图像融合任务的统一框架。具体而言,我们利用一个统一的模型和统一的参数来解决不同的融合问题。该方案克服了诸多不足,如针对不同问题需采用不同解决方案、训练过程中存在存储和计算问题,以及持续学习中出现的灾难性遗忘问题。
2.设计了一种新的图像融合无监督网络。通过约束融合图像与源图像之间的相似性,该网络克服了大多数图像融合问题中普遍存在的障碍,即缺乏通用真值标签和无参考度量指标。
3.发布了一个新的对齐红外与可见光图像数据集 RoadScene,为图像融合基准评估提供了新选择。该数据集可在https://github.com/hanna-xu/RoadScene获取。
4.在六个数据集上针对多模态、多曝光和多聚焦图像融合任务对所提方法进行了测试。定性和定量结果均验证了 U2Fusion 的有效性和通用性。
03.方法
3.1问题建模
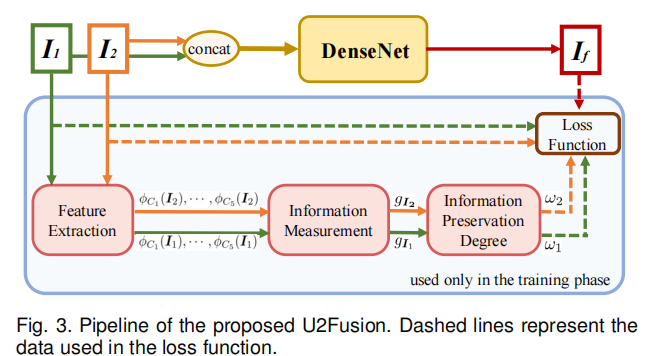
为了保留源图像中的关键信息,本模型通过信息度量来确定关键信息的丰富程度。若源图像包含丰富的信息,则该图像对融合结果至关重要,融合结果应与该源图像保持较高的相似性。
为解决不同类型源图像中的关键信息存在显著差异这一问题,本研究综合考虑源图像的多方面属性,提取浅层特征(纹理、局部形状等)和深层特征(内容、空间结构等),用于信息度量的计算,作为统一的度量方式以确定源图像的信息保留程度。
源图像为 I 1 I_1 I1, I 2 I_2 I2,训练一个 DenseNet生成融合图像If。特征提取的输出为特征图 ϕ C 1 ϕ C_ 1 ϕC1 ( I 1 I_ 1 I1 ),⋯, ϕ C 5 ϕ C_ 5 ϕC5 ( I 1 I_ 1 I1 )和 ϕ C 1 ϕ C_ 1 ϕC1 ( I 2 I_ 2 I2 ),⋯, ϕ C 5 ϕ C_ 5 ϕC5 ( I 2 I_ 2 I2 )。对这些特征图进行信息度量,得到两个度量值gI1和gI2;经过后续处理,最终得到信息保留程度 ω 1 ω_1 ω1和 ω 2 ω_2 ω2。在损失函数中,需用到 I 1 I_1 I1、 I 2 I_2 I2、 I f I_f If、 ω 1 ω_1 ω1和 ω 2 ω_2 ω2,整个过程无需真值标签。在训练阶段,通过计算ω1和ω2来定义损失函数,并优化 DenseNet 模块以最小化损失函数
3.1.1 特征提取
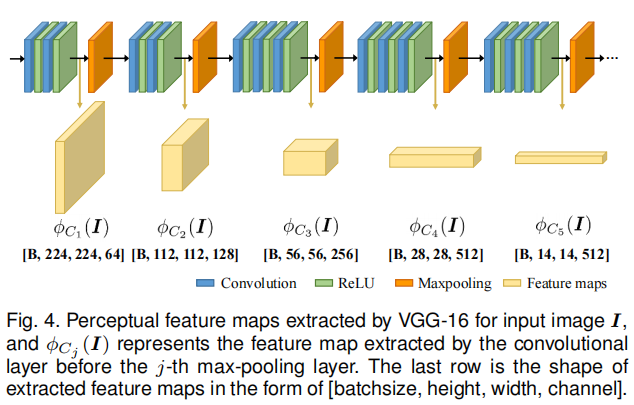
本研究采用预训练的 VGG-16 网络 进行特征提取,如图 4 所示。在模型中,输入图像 I I I首先被统一为单通道,然后复制为三通道输入到 VGG-16 中。取最大池化层之前(最大池化层会压缩图像尺寸、丢失部分细节)各卷积层的输出作为后续信息度量所需的特征图
with tf.device('/gpu:1'):
# 将单通道输入图像调整为VGG16网络所需的224x224尺寸
# 然后将单通道图像复制三次,转换为三通道图像(VGG16需要RGB输入)
self.S1_VGG_in = tf.image.resize_nearest_neighbor(self.SOURCE1, size = [224, 224])
self.S1_VGG_in = tf.concat((self.S1_VGG_in, self.S1_VGG_in, self.S1_VGG_in), axis = -1)
self.S2_VGG_in = tf.image.resize_nearest_neighbor(self.SOURCE2, size = [224, 224])
self.S2_VGG_in = tf.concat((self.S2_VGG_in, self.S2_VGG_in, self.S2_VGG_in), axis = -1)
# 使用VGG16网络提取源图像1的多层特征
# VGG特征能够捕获图像的高层语义信息
vgg1 = Vgg16()
with tf.name_scope("vgg1"):
self.S1_FEAS = vgg1.build(self.S1_VGG_in)
# 使用VGG16网络提取源图像2的多层特征
vgg2 = Vgg16()
with tf.name_scope("vgg2"):
self.S2_FEAS = vgg2.build(self.S2_VGG_in)
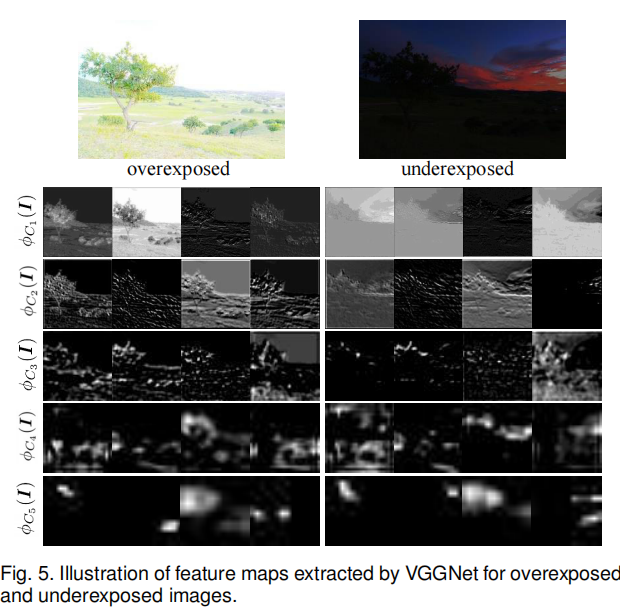
为直观分析,图 5 展示了多曝光图像对的部分特征图。 ϕ C 1 ϕ C_ 1 ϕC1 ( I I I )和 ϕ C 2 ϕ C_ 2 ϕC2 ( I I I )对应的特征基于浅层特征(如纹理、形状细节),在这些层中,过曝光图像的特征图仍比欠曝光图像包含更多信息;相比之下,高层特征图 ϕ C 4 ϕ C_ 4 ϕC4 ( I I I )和 ϕ C 5 ϕ C_ 5 ϕC5 ( I I I )主要保留深层特征(如内容、空间结构),在这些层中,欠曝光图像的特征图包含与过曝光图像相当甚至更多的信息。因此,浅层特征与深层特征的结合,能够全面表征源图像的本质信息,而这些信息可能难以通过人类视觉感知系统直接察觉。
3.1.2 信息度量
为度量提取特征图中包含的信息,本研究采用特征图的梯度进行评估。与基于通用信息论的度量指标相比,图像梯度是基于局部空间结构的度量,感受野较小;在深度学习框架中,梯度在计算和存储效率上更具优势,因此更适合用于 CNN 中的信息度量。信息度量的定义如下 g I = 1 5 ∑ j = 1 5 1 H j W j D j ∑ k = 1 D j ∥ ∇ ϕ C j k ( I ) ∥ F 2 g_{I} = \frac{1}{5} \sum_{j=1}^{5} \frac{1}{H_{j} W_{j} D_{j}} \sum_{k=1}^{D_{j}} \left\| \nabla \phi_{C_{j}^{k}}(I) \right\|_{F}^{2} gI=51∑j=15HjWjDj1∑k=1Dj
∇ϕCjk(I)
F2
其中, ϕ C j ϕ C_ j ϕCj ( I I I )表示图 4 中第 j个最大池化层之前卷积层提取的特征图; k表示 D j D_j Dj 个通道中第 j个通道的特征图; ∥ ⋅ ∥ F ∥⋅∥ _F ∥⋅∥F表示弗罗贝尼乌斯范数,用于量化特征图梯度的强度; Δ \Delta Δ表示拉普拉斯算子,用于计算特征图的梯度。
3.1.3 信息保留程度
为保留源图像中的信息,需分配两个自适应权重作为信息保留程度,用于定义融合图像与各源图像之间相似性的权重。权重越高,意味着期望融合图像与对应源图像的相似性越高,该源图像的信息保留程度也越高。
记自适应权重为 ω 1 \omega_1 ω1和 ω 2 \omega_2 ω2,它们通过信息度量值 g ( I 1 ) g(I_1) g(I1)和 g ( I 2 ) g(I_2) g(I2)来估计。由于 g ( I 1 ) g(I_1) g(I1)和 g ( I 2 ) g(I_2) g(I2)的差值为绝对值,而非相对值,其差值可能远小于自身数值,难以体现两者的差异,因此引入一个预定义的正常数c对数值进行缩放,以实现更优的权重分配。因此, ω 1 \omega_1 ω1 和 ω 2 \omega_2 ω2 定义如下:
[ ω 1 , ω 2 ] = softmax ( [ g I 1 c , g I 2 c ] ) \left[\omega_1, \omega_2\right] = \text{softmax}\left(\left[\frac{g_{I_1}}{c}, \frac{g_{I_2}}{c}\right]\right) [ω1,ω2]=softmax([cgI1,cgI2])
其中,我们使用 softmax \text{softmax} softmax 函数将 g I 1 c \frac{g_{I_1}}{c} cgI1 和 g I 2 c \frac{g_{I_2}}{c} cgI2 映射到 0 到 1 之间的实数,并确保 ω 1 \omega_1 ω1 和 ω 2 \omega_2 ω2 之和为 1。然后,将 ω 1 \omega_1 ω1 和 ω 2 \omega_2 ω2 用于损失函数,以控制特定源图像的信息保留度。
3.2 损失函数
损失函数的设计主要用于两个目的:一是保留源图像中的关键信息,二是训练适用于多种融合任务的单一模型。损失函数由两部分组成,定义如下:
L ( θ , D ) = L sim ( θ , D ) + λ L ewc ( θ , D ) L(\theta, D) = L_{\text{sim}}(\theta, D) + \lambda L_{\text{ewc}}(\theta, D) L(θ,D)=Lsim(θ,D)+λLewc(θ,D)
其中, θ \theta θ 表示 DenseNet 中的参数, D D D 表示训练数据集。 L sim ( θ , D ) L_{\text{sim}}(\theta, D) Lsim(θ,D) 是融合结果与源图像之间的相似性损失。 L ewc ( θ , D ) L_{\text{ewc}}(\theta, D) Lewc(θ,D) 是为持续学习设计的项,将在下一小节中描述。 λ \lambda λ 是一个超参数,用于控制权衡关系。
我们从两个方面实现相似性约束,即结构相似性和强度分布。
由于结构相似性指标(SSIM)是最广泛使用的度量指标,它根据光、对比度和结构信息的相似性来模拟失真 [38],因此我们使用它来约束 I 1 I_1 I1、 I 2 I_2 I2 和 I f I_f If 之间的结构相似性。因此,在 ω 1 \omega_1 ω1 和 ω 2 \omega_2 ω2 控制信息保留度的情况下, L sim ( θ , D ) L_{\text{sim}}(\theta, D) Lsim(θ,D) 的第一项公式如下:
L ssim ( θ , D ) = E [ 1 − ω 1 ⋅ S I f , I 1 − ω 2 ⋅ S I f , I 2 ] L_{\text{ssim}}(\theta, D) = \mathbb{E}\left[ 1 - \omega_1 \cdot S_{I_f, I_1} - \omega_2 \cdot S_{I_f, I_2} \right] Lssim(θ,D)=E[1−ω1⋅SIf,I1−ω2⋅SIf,I2]
其中, S x , y S_{x,y} Sx,y 表示两个图像 x x x 和 y y y 之间的 SSIM 值。
对强度分布差异的约束,我们通过第二项来补充 L ssim ( θ , D ) L_{\text{ssim}}(\theta, D) Lssim(θ,D),该项由两个图像之间的均方误差(MSE)定义:
L mse ( θ , D ) = E [ ω 1 ⋅ MSE I f , I 1 + ω 2 ⋅ MSE I f , I 2 ] L_{\text{mse}}(\theta, D) = \mathbb{E}\left[ \omega_1 \cdot \text{MSE}_{I_f, I_1} + \omega_2 \cdot \text{MSE}_{I_f, I_2} \right] Lmse(θ,D)=E[ω1⋅MSEIf,I1+ω2⋅MSEIf,I2]
在 α \alpha α 控制权衡关系的情况下, L sim ( θ , D ) L_{\text{sim}}(\theta, D) Lsim(θ,D) 公式如下:
L sim ( θ , D ) = L ssim ( θ , D ) + α ⋅ L mse ( θ , D ) L_{\text{sim}}(\theta, D) = L_{\text{ssim}}(\theta, D) + \alpha \cdot L_{\text{mse}}(\theta, D) Lsim(θ,D)=Lssim(θ,D)+α⋅Lmse(θ,D)
# ============ 损失函数定义部分 ============
# SSIM(结构相似性)损失:衡量生成图像与源图像之间的结构相似性
# SSIM值范围在[0,1],值越大表示越相似,因此损失 = 1 - SSIM
# SSIM1: 生成图像与源图像1的结构相似性损失
# SSIM2: 生成图像与源图像2的结构相似性损失
''' SSIM loss'''
SSIM1 = 1 - SSIM_LOSS(self.SOURCE1, self.generated_img)
SSIM2 = 1 - SSIM_LOSS(self.SOURCE2, self.generated_img)
# MSE(均方误差)损失:使用Frobenius范数计算生成图像与源图像之间的像素级差异
# mse1: 生成图像与源图像1的均方误差
# mse2: 生成图像与源图像2的均方误差
mse1 = Fro_LOSS(self.generated_img-self.SOURCE1)
mse2 = Fro_LOSS(self.generated_img-self.SOURCE2)
# ============ 加权损失计算 ============
# 根据自适应权重对两个源图像的损失进行加权求和
# ssim_loss: 加权后的结构相似性损失,信息更丰富的图像损失权重更大
self.ssim_loss = tf.reduce_mean(self.s[:, 0] * SSIM1 + self.s[:, 1] * SSIM2)
# mse_loss: 加权后的均方误差损失
self.mse_loss = tf.reduce_mean(self.s[:, 0] * mse1 + self.s[:, 1] * mse2)
# 最终的内容损失 = SSIM损失 + 20 * MSE损失
# SSIM损失关注结构相似性,MSE损失关注像素级精度
# 系数20用于平衡两种损失的尺度,确保两者对总损失的贡献相当
self.content_loss = self.ssim_loss + 20 * self.mse_loss
3.3 基于弹性权重巩固(EWC)的多融合任务单一模型
不同的融合任务通常对特征提取和特征融合有不同要求,这直接体现在 DenseNet 参数的差异上,导致需要训练多个架构相同但参数不同的模型。然而,部分参数存在冗余,这些模型的利用率有较大提升空间。这促使我们训练一个具有统一参数的单一模型,整合多个模型的功能,从而适用于多种融合任务。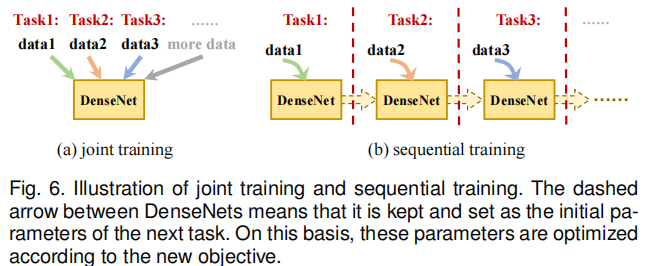
实现这一目标有两种方式:联合训练和顺序训练。
如图 6(a) 所示,联合训练是一种简单的方法,在整个训练过程中保留所有训练数据,每次批量训练时随机选择多个任务的数据。但随着任务数量的增加,两个待解决的问题愈发突出:一是需长期存储先前任务的数据,导致存储压力大;二是需使用所有数据进行训练,在计算难度和时间成本上均面临挑战。
在顺序训练中,不同任务需使用不同的训练数据,如图 6(b)所示。因此,训练过程中仅需存储当前任务的数据,解决了联合训练中的存储和计算问题。但当模型为获取新能力而训练新任务时,会出现新的问题:先前任务的训练数据不可用 。随着训练的持续进行,模型参数会为适应新任务而优化,同时遗忘之前任务的学习能力,这一问题被称为 “灾难性遗忘”。
为避免这一缺陷,本研究采用弹性权重巩固(EWC)算法进行改进。在 EWC 中,当前任务参数 θ \theta θ与先前任务参数 θ \theta θ之间的平方距离,会根据参数对 θ \theta θ的重要性进行加权,总损失函数中包含了用于持续学习的损失项 L e w c L _{ewc} Lewc (θ,D)。设与参数重要性相关的权重为 μ i μ_i μi,则 L e w c L _{ewc} Lewc (θ,D)定义如下:
L ewc ( θ , D ) = 1 2 ∑ i μ i ( θ i − θ i ∗ ) 2 L_{\text{ewc}}(\theta,D) = \frac{1}{2} \sum_{i} \mu_i (\theta_i - \theta_i^*)^2 Lewc(θ,D)=21∑iμi(θi−θi∗)2
为评估参数重要性, μ i \mu_i μi 取费雪信息矩阵的对角线元素,并通过旧任务数据的梯度平方近似计算,定义如下:
μ i = E [ ( ∂ ∂ θ i ∗ log p ( D ∗ ∣ θ ∗ ) ) 2 ∣ θ ∗ ] \mu_i = \mathbb{E}\left[ \left( \frac{\partial}{\partial \theta_i^*} \log p(D^* \mid \theta^*) \right)^2 \mid \theta^* \right] μi=E[(∂θi∗∂logp(D∗∣θ∗))2∣θ∗]
式中 “log p (D* | θ*)” 是旧任务数据 D在参数 θ下的 “对数似然”,反映 θ* 对旧数据的拟合能力; 对 θᵢ求偏导(∂/∂θᵢ),得到 “参数 θᵢ* 变化对旧数据拟合能力的影响程度”;E • 平方后取期望(E [・]),最终得到 μᵢ,本质是 “旧任务中参数 θᵢ* 的梯度波动水平”, 梯度越大,参数对旧任务越重要,μᵢ越大。 log p ( D ∗ ∣ θ ∗ ) \log p(D^* \mid \theta^*) logp(D∗∣θ∗) 可近似替换为 − L ( θ ∗ , D ∗ ) -L(\theta^*,D^*) −L(θ∗,D∗) ,因此上式可转换为:
μ i = E [ ( − ∂ ∂ θ i ∗ L ( θ ∗ , D ∗ ) ) 2 ∣ θ ∗ ] \mu_i = \mathbb{E}\left[ \left( -\frac{\partial}{\partial \theta_i^*} L(\theta^*,D^*) \right)^2 \mid \theta^* \right] μi=E[(−∂θi∗∂L(θ∗,D∗))2∣θ∗]
由于费雪信息矩阵可在丢弃旧数据 D ∗ D^* D∗ 之前计算得到,因此模型训练当前任务时无需依赖 D ∗ D^* D∗。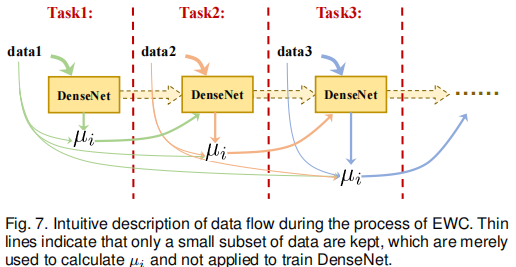
若存在多个旧任务,需根据具体任务及对应数据调整 L ewc ( θ , D ) \mathcal{L}_{\text{ewc}}(\theta,D) Lewc(θ,D),然后对各任务的梯度平方取平均,得到最终的 μ i \mu_i μi。训练过程和数据流如图 7 所示。
在多任务图像融合中, θ \theta θ 为 DenseNet 的参数。首先,训练 DenseNet 以解决任务 1(多模态图像融合),通过最小化相似性损失实现;当需要添加任务 2(多曝光图像融合)的处理能力时,先计算参数重要性权重 μ i \mu_i μi,然后通过最小化 L ewc \mathcal{L}_{\text{ewc}} Lewc 项巩固重要参数,避免灾难性遗忘,同时通过最小化相似性损失 L sim \mathcal{L}_{\text{sim}} Lsim 调整不重要参数,以适应多曝光图像融合任务;最后,训练 DenseNet 处理多聚焦图像融合任务时,根据前两个任务计算 μ i \mu_i μi,后续的弹性权重巩固策略与任务 2 相同。通过这种方式,EWC 可适配多任务自适应图像融合场景。
3.4 网络架构
本研究采用 DenseNet 生成融合图像 I f I_f If,是一种无需设计融合规则的端到端模型,其输入为 I 1 I_1 I1和 I 2 I_2 I2的拼接结果。
U2Fusion 中 DenseNet 的架构包含 10 层,每层均由卷积层和激活函数组成。所有卷积层的卷积核大小均设为 3×3,步长设为 1;卷积操作前采用反射填充(对输入特征图的边界进行 “镜像扩展”),以减少边界伪影;未使用池化层,避免信息丢失。前 9 层的激活函数为 LeakyReLU(斜率设为 0.2),最后一层的激活函数为 tanh。
在前 7 层中,采用密集连接卷积网络(DenseNet)中的密集连接块 ,在每一层与所有其他层之间建立短连接直接连接,可减少梯度消失问题(反向传播时,梯度从输出层向输入层传递,每经过一层就被 “缩小” 一次,到了浅层(靠近输入层)的梯度几乎趋近于 0),同时增强特征传播并减少参数数量 。特征图的通道数均设为 44;后续 4 层逐步减少特征图的通道数,最终输出单通道融合图像。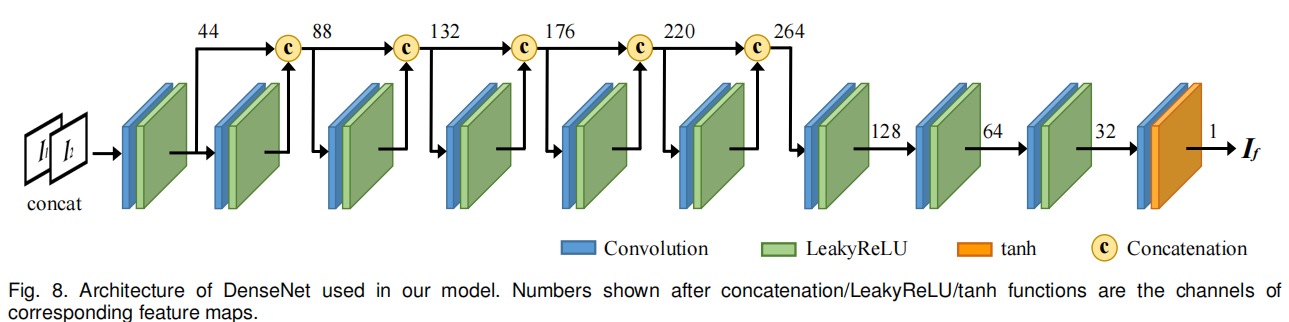
self.batchsize = BATCH_SIZE
# 初始化生成器网络(编码器-解码器架构)
# 编码器: 2通道输入 -> 5层密集卷积块 -> 264通道特征(44*6)
# 解码器: 264通道特征 -> 4层卷积 -> 1通道输出
self.G = Generator('Generator')
self.var_list = []
# 定义两个输入源图像(单通道灰度图)
self.SOURCE1 = tf.placeholder(tf.float32, shape = (BATCH_SIZE, INPUT_H, INPUT_W, 1), name = 'SOURCE1')
self.SOURCE2 = tf.placeholder(tf.float32, shape = (BATCH_SIZE, INPUT_H, INPUT_W, 1), name = 'SOURCE2')
self.c = tf.placeholder(tf.float32, shape = (), name = 'c')
print('source shape:', self.SOURCE1.shape)
# 网络前向传播: 将两个输入图像输入生成器网络,得到融合后的图像
# 内部流程: concat(I1, I2) -> 编码器(特征提取) -> 解码器(图像重建) -> 融合图像
self.generated_img = self.G.transform(I1 = self.SOURCE1, I2 = self.SOURCE2, is_training = is_training, reuse=False)
self.var_list.extend(tf.trainable_variables())
3.5 RGB 输入处理
首先将 RGB (色彩信息与亮度信息混合存储)输入转换到 YCbCr 颜色空间(Y 通道由 R、G、B 加权求和得到,Cb、Cr 通道通过 “原色与亮度的差值” 计算),仅对 Y 通道(亮度通道)通过 U2Fusion 的核心网络(DenseNet)进行融合 —— 因为图像的结构细节主要集中在 Y 通道,且该通道的亮度变化比色度通道更显著,Cb 和 Cr 通道(色度通道)采用传统方法(加权平均策略)融合,公式如下:
C f = C 1 ⋅ ∣ C 1 − τ ∣ + C 2 ⋅ ∣ C 2 − τ ∣ ∣ C 1 − τ ∣ + ∣ C 2 − τ ∣ C_f = \frac{C_1 \cdot |C_1 - \tau| + C_2 \cdot |C_2 - \tau|}{|C_1 - \tau| + |C_2 - \tau|} Cf=∣C1−τ∣+∣C2−τ∣C1⋅∣C1−τ∣+C2⋅∣C2−τ∣
其中, C 1 C_1 C1和 C 2 C _2 C2分别表示两幅源图像的 Cb/Cr 通道值, C f C _f Cf表示融合结果的对应通道值, τ τ τ设为 128。随后,通过逆转换将融合图像转换回 RGB 空间,从而将所有图像融合问题统一为单通道图像融合问题。
def rgb2ycbcr(img):
"""
RGB到YCbCr颜色空间转换函数
- Y通道(亮度通道):由R、G、B加权求和得到,反映图像的亮度信息
其中权重系数基于人眼对不同颜色的敏感度
- Cb通道(蓝色色度):通过"蓝色与亮度的差值"计算
- Cr通道(红色色度):通过"红色与亮度的差值"计算
"""
R=img[:,:,0]
G=img[:,:,1]
B=img[:,:,2]
Y = 0.299 * R + 0.587 * G + 0.114 * B
Cb = -0.1687 * R - 0.3313 * G + 0.5 * B + 128 / 255.0
Cr = 0.5 * R - 0.4187 * G - 0.0813 * B + 128 / 255.0
return Y, Cb, Cr
def fuse_chroma_channels(C1, C2, tau=128/255.0):
"""
Cb和Cr通道(色度通道)融合函数
"""
abs_diff1 = np.abs(C1 - tau)
abs_diff2 = np.abs(C2 - tau)
# 避免除零
denominator = abs_diff1 + abs_diff2 + eps
C_f = (C1 * abs_diff1 + C2 * abs_diff2) / denominator
return C_f
# Y通道融合:通过U2Fusion的核心网络(DenseNet)对Y通道进行融合
def ycbcr2rgb(Y, Cb, Cr):
"""
YCbCr到RGB颜色空间的逆转换函数
将融合后的Y通道与处理后的Cb、Cr通道重新组合,转换回RGB颜色空间。
"""
R = Y + 1.402 * (Cr - 128 / 255.0)
G = Y - 0.34414 * (Cb - 128 / 255.0) - 0.71414 * (Cr - 128 / 255.0)
B = Y + 1.772 * (Cb - 128 / 255.0)
R = np.expand_dims(R, axis=-1)
G = np.expand_dims(G, axis=-1)
B = np.expand_dims(B, axis=-1)
return np.concatenate([R, G, B], axis=-1)
3.6 多输入处理
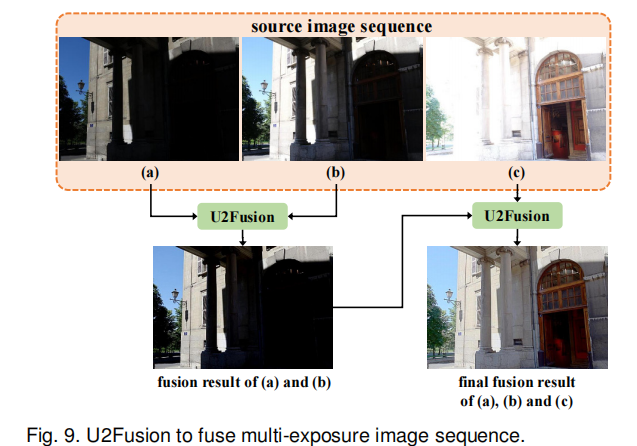
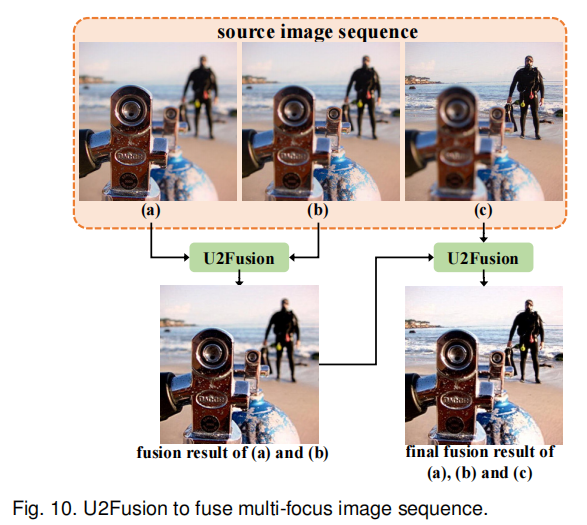
在多曝光和多聚焦融合中,需融合源图像序列(即源图像数量超过两幅)。此时,可对源图像进行序贯融合:如图 9 和图 10 所示,首先融合两幅源图像,得到中间结果;然后将中间结果与另一幅源图像融合。
04.实验分析
4.1 可见光与红外图像融合

U2Fusion 的融合结果清晰度高于其他对比方法。
U2Fusion 还可用于融合 RoadScene 数据集中的 VIS(RGB)图像与灰度 IR 图像,由于融合仅在 Y 通道( 负责承载亮度与结构细节)进行,Cb、Cr 通道直接沿用 VIS 图像的原始色度数据,因此融合结果更接近经 IR 图像增强的 VIS 图像。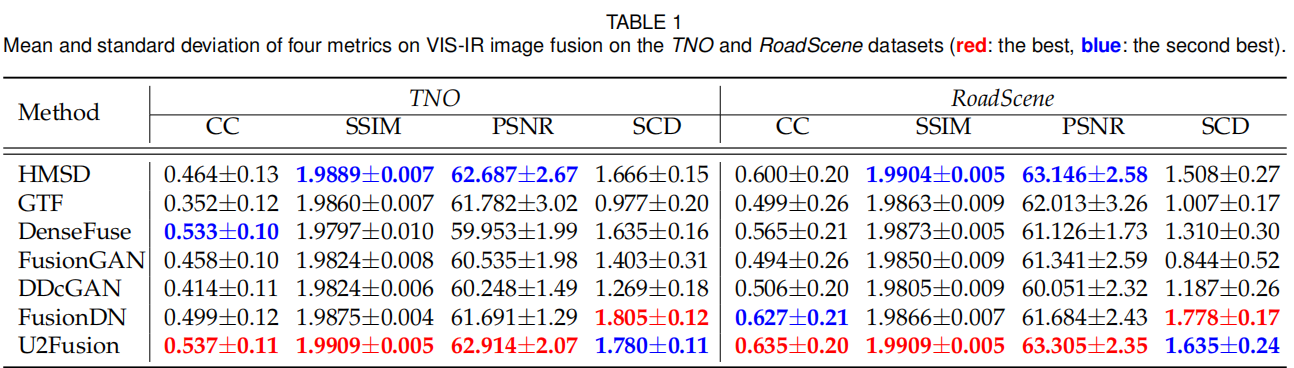
四个度量指标:相关系数(CC)、结构相似性(SSIM)、峰值信噪比(PSNR)、差异相关(SCD)。其中,CC 衡量源图像与融合结果之间的线性相关程度;PSNR 评估融合过程导致的失真;SCD 量化融合图像的质量。
U2Fusion 在两个数据集的 CC、SSIM、PSNR 指标上均排名第一,在 SCD 指标上与最优结果相差较小。
4.2 消融实验
4.2.1 弹性权重巩固(EWC)的消融实验
为验证 EWC 的有效性,设计对比实验:不使用 EWC,对任务进行序列训练。从三个维度分析 EWC 的有效性:相似性损失、 μ i μ_i μi的统计分布、训练阶段的中间融合结果。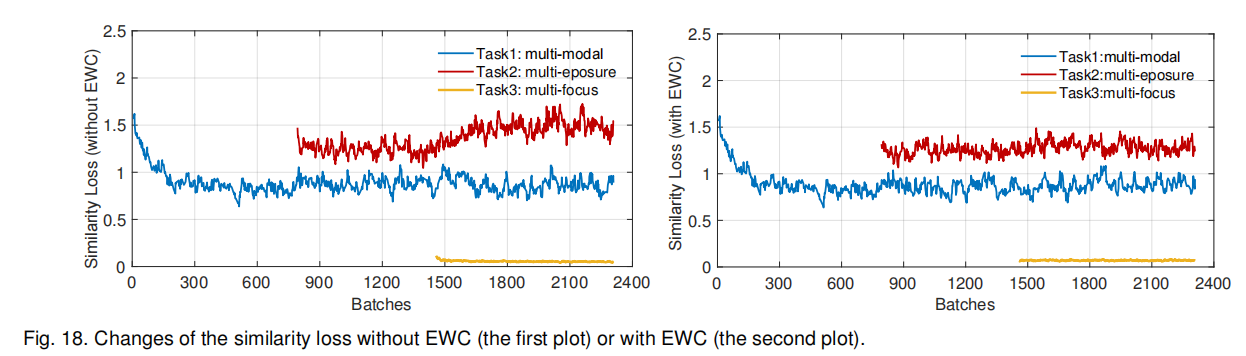
相似性损失的变化如图 18 所示。任务 2开始训练后 ,任务 1 的损失差异不明显;但训练任务 3 时,不使用EWC时任务 2 验证集的损失显著增加.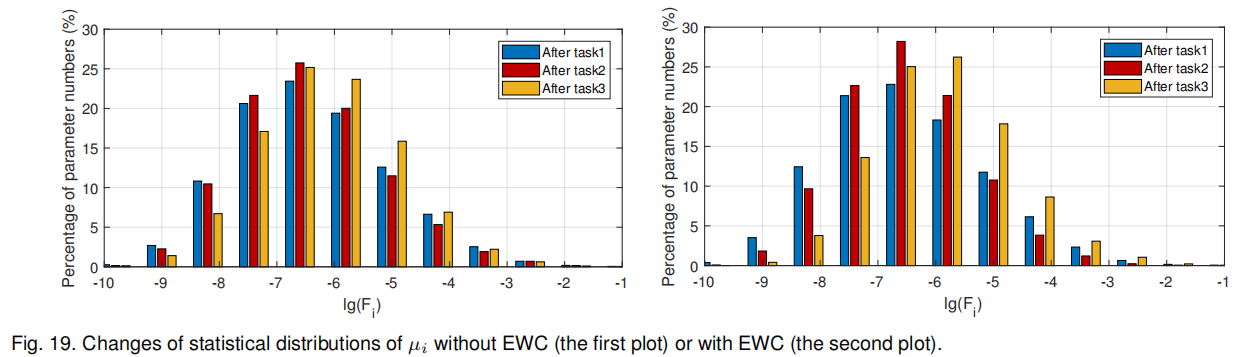
μ i μ_i μi的统计分布如图 19 所示。不使用 EWC 时,三个任务训练完成后 μ i μ_i μi的分布差异不大(左图),参数仅与当前任务相关, μ i μ_i μi仅反映参数对当前任务的重要性;而使用 EWC 后,大值 μ i μ_i μi的比例显著增加(右图),表明网络中出现了更多重要参数 ,小值 μ i μ_i μi的比例下降,说明网络冗余减少. 定性对比结果如图 20 所示。不使用 EWC 时,模型在任务 2 上图像整体亮度降低,且任务 1 的结果在(b)(c)中存在明显差异;而使用 EWC 后,这两个问题均得到缓解。
定性对比结果如图 20 所示。不使用 EWC 时,模型在任务 2 上图像整体亮度降低,且任务 1 的结果在(b)(c)中存在明显差异;而使用 EWC 后,这两个问题均得到缓解。
4.2.2 多任务相互促进的统一模型
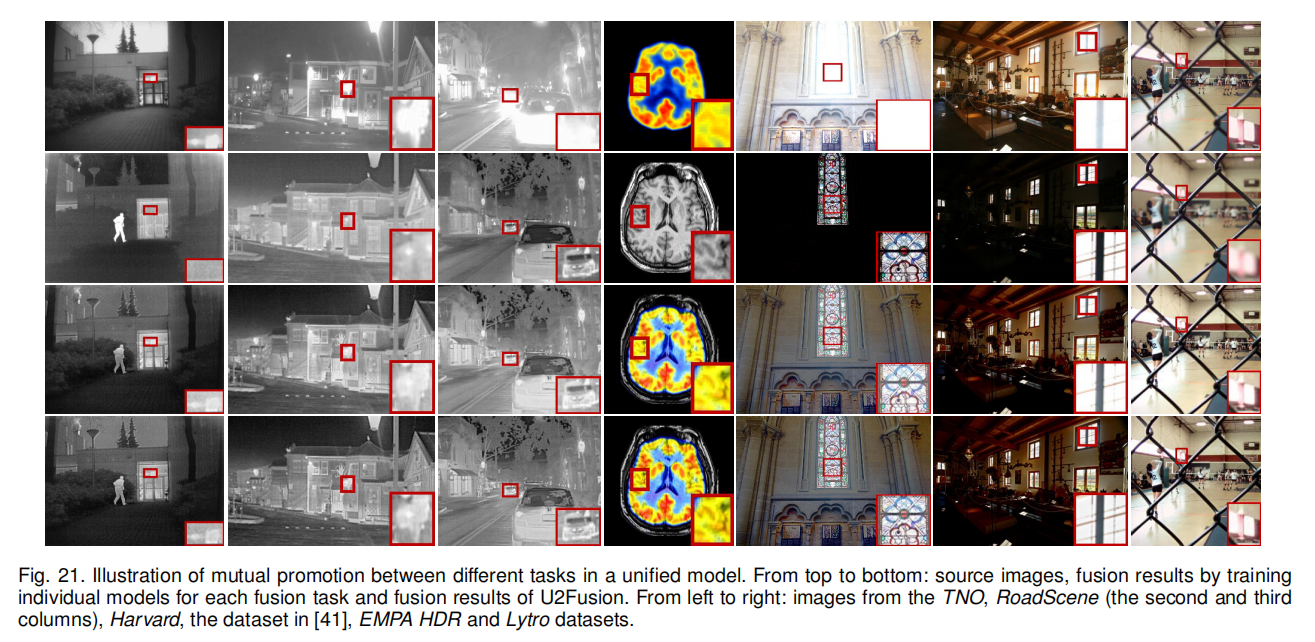
与单独训练的模型相比,经多曝光图像融合训练的统一模型 U2Fusion,对这些过曝光区域的处理效果更优,表征更清晰,U2Fusion 的结果边缘比单独训练模型的结果更清晰锐利。
4.2.3 自适应信息保留程度的消融实验
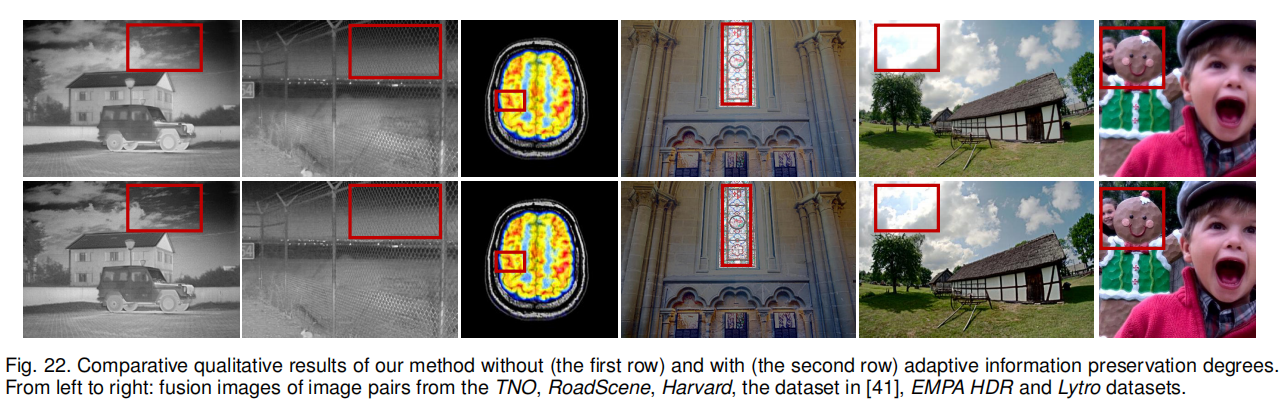
如图 22 所示,第一行为 ω 1 ω _1 ω1和 ω 2 ω _2 ω2固定为 0.5 的结果(模型对两个源图像的信息 “平均分配权重”),第二行为 U2Fusion 的结果,无自适应信息保留程度的结果效果更差.
4.2.4 训练顺序的影响
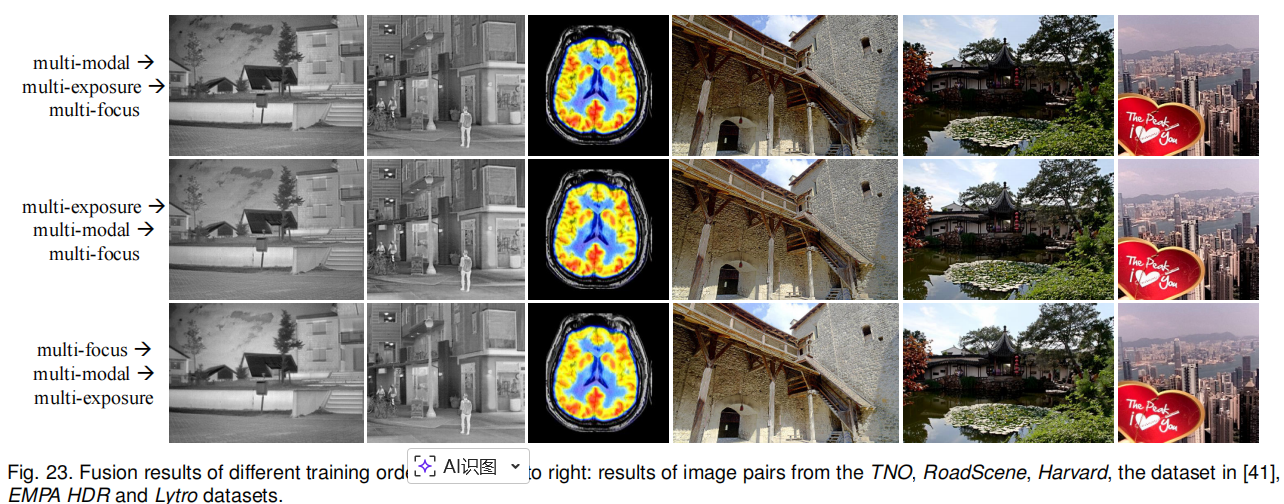
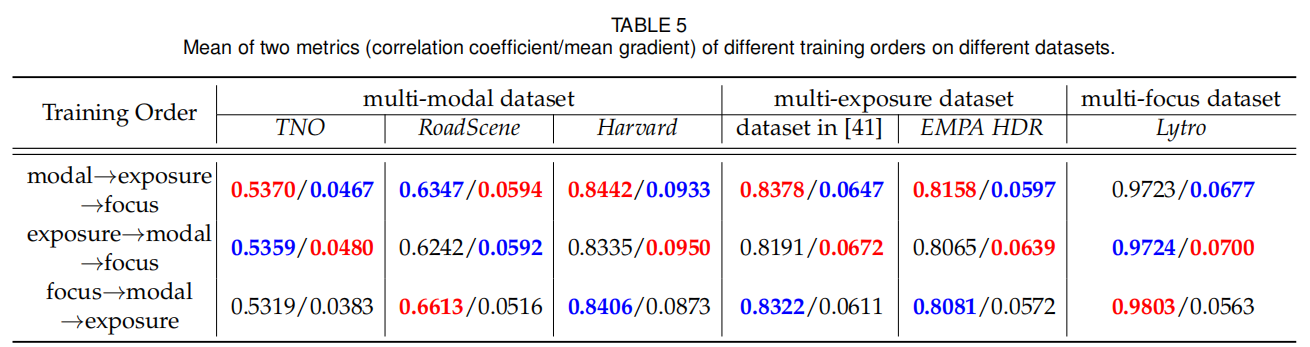
通过图23定性分析和表5定量分析,多模态和多曝光的训练顺序对融合结果影响较小,而多聚焦的训练顺序影响相对显著,平均梯度大幅下降。“多模态→多曝光→多聚焦” 的顺序性能最优,因此 U2Fusion 采用该训练顺序。
4.2.5 U2Fusion 与 FusionDN 的对比
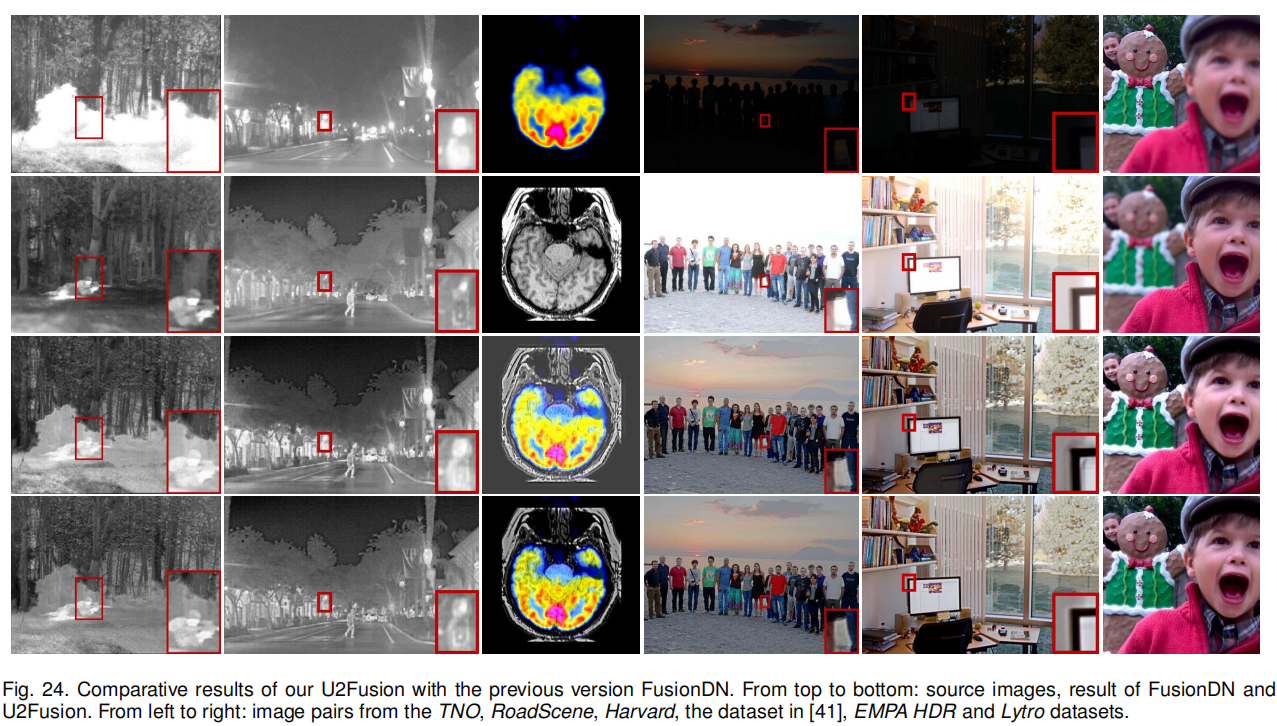
首先,改进了信息保留程度分配策略,基于提取特征的信息度量进行分配。图 24 的第一、二列U2Fusion保留了源图像中更多的细节。
其次,修改了损失函数:第四、五列中 FusionDN 的结果,U2Fusion 移除梯度损失后,通过 SSIM 和改进的信息保留程度分配策略保留结构信息,结果仍保持清晰,且伪边缘得到缓解。
此外,FusionDN 仅通过 SSIM 保留强度分布,U2Fusion 新增 MSE 损失后,亮度偏差问题得到解决,最后一列U2Fusion 结果的强度与源图像更接近。
最后,将首个任务从 VIS-IR 图像融合扩展为多模态图像融合(涵盖 VIS-IR 和医学图像融合)。第三列中 FusionDN 的结果边缘模糊、背景呈灰色,而 U2Fusion 的结果显著更优。
05 个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解所限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本公众号立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)