多平台 Web Scraping 实战指南:用 Bright Data + MCP 实现自动化数据采集(2026)
多平台 Web Scraping 实战指南:用 Bright Data + MCP 实现自动化数据采集(2026)
一、前言
如果你做过多平台 web scraping,你一定踩过这些坑:IP 被封、CAPTCHA 无限弹、网站一改版脚本全崩。各平台结构规则不一、站点改版易导致解析失效、Agent汇总数据缺乏可追溯性等问题频发。
落地关键在于两点:一是将网页检索、抓取等工作交给专业采集基础设施,二是通过标准协议将采集能力对接MCP以及相关SKILL,正是解决这一问题的关键。Bright Data MCP是一个企业级数据采集平台,无需用户搭建和维护基础设施,支持弹性扩展,搭配SKILL让模型统一调用采集工具,由服务端承担解锁和采集工作,高效应对采集痛点。
本质上,这种方式是把最耗时且不稳定的反爬与采集问题交给专业基础设施处理,让多平台数据采集更接近工程化可控。地址:https://get.brightdata.com/mcpserver-m
二、数据流架构
用户只需提供站点和关键词,Bright Data MCP自动处理抓取与反爬,Claude按SKILL.md规则调用对应结构化工具(无专用工具时降级用Markdown抓取),最终统一输出固定Schema的JSON供下游直接使用。
用户输入(商品 URL / 关键词 + 站点)
↓
已连接 Bright Data MCP
↓
按 SKILL.md 优先级调用工具
↓
统一 JSON(见 Skill 中的 Schema)
↓
下游表格、监控或存储
三、环境
- Bright Data 账号(用于获取 MCP 配置和 API Token):点击链接
- Claude Desktop / Claude Code/Cursor/CodeX都可以,可以配置MCP
- 多平台数据采集 Skill
- python运行环境(最好3.0+)
四、配置 Bright Data MCP Server
登录到Bright Data后台控制面板,点击左侧“AI网关”菜单,然后选择“MCP”
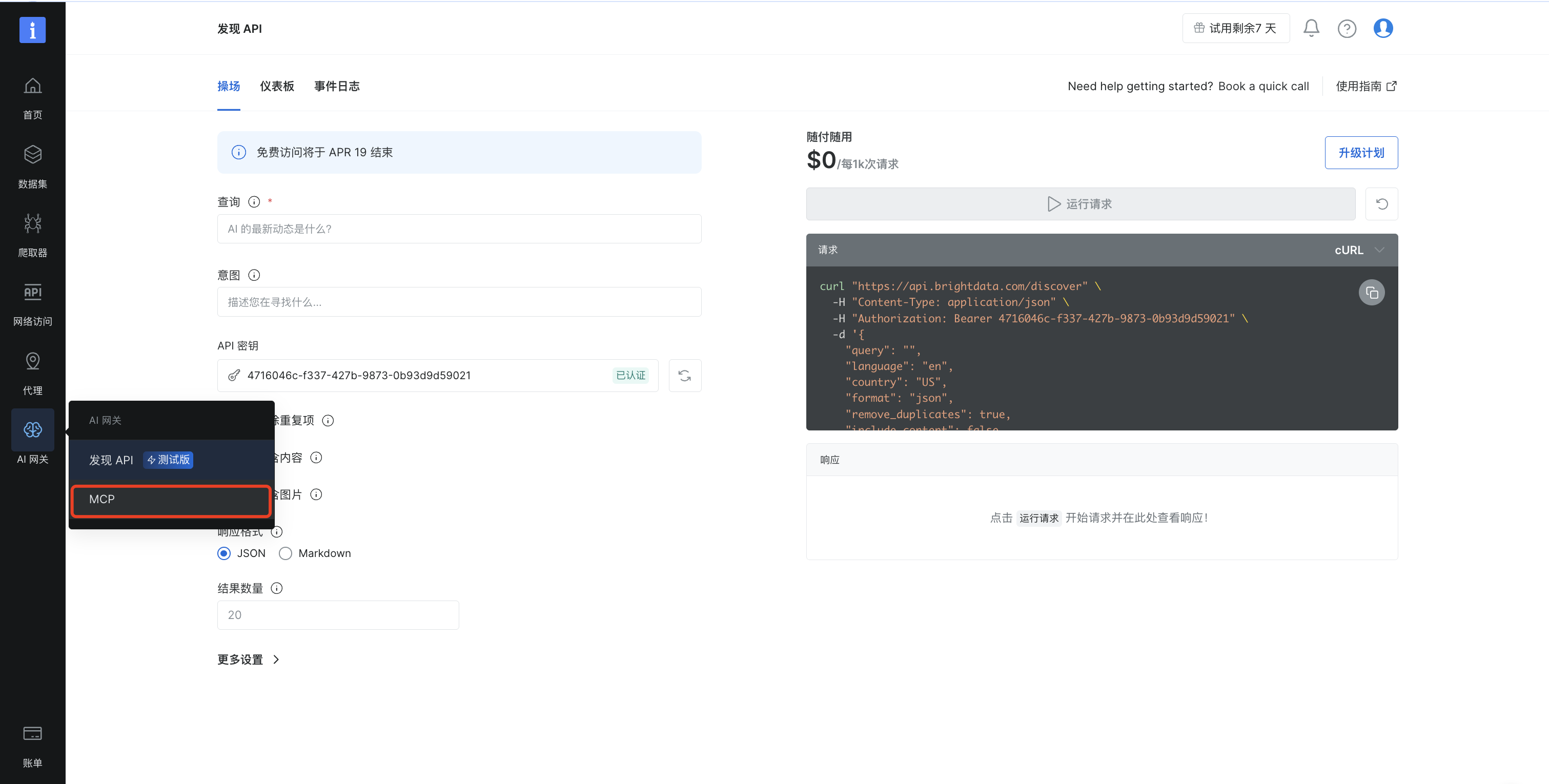
在“选择工具”中选择“电子商务”,然后点击继续配置
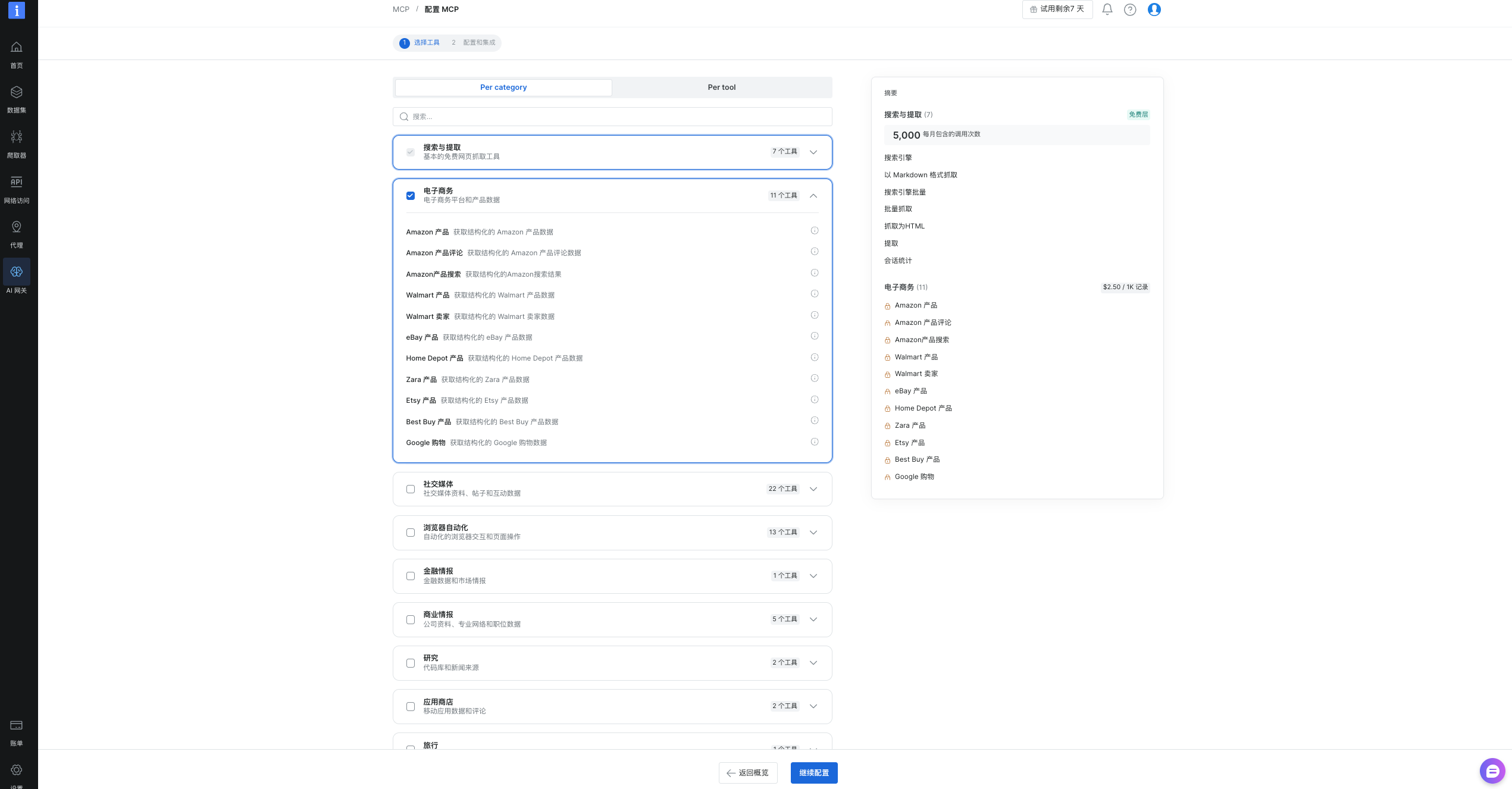
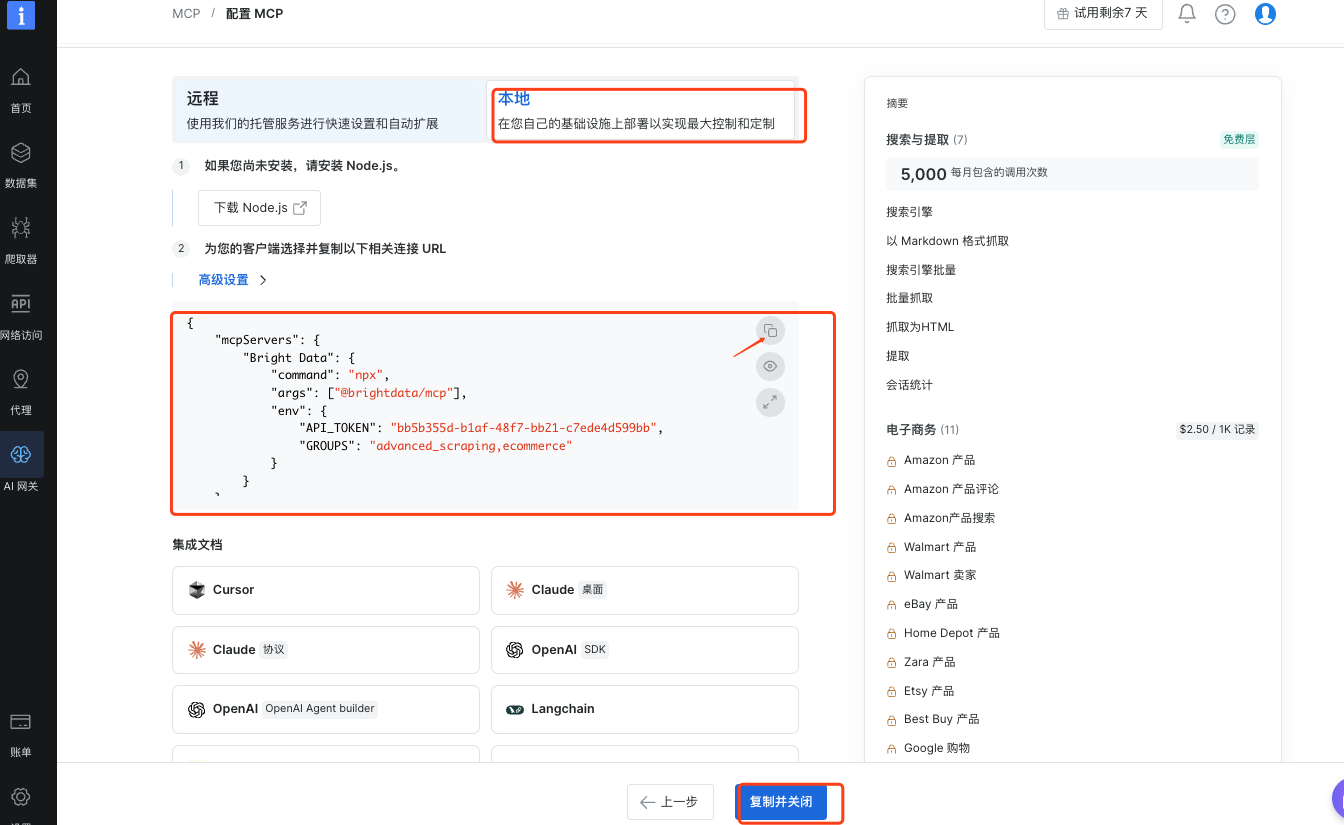
在配置和集成中选择“本地”,然后点击“复制并关闭”
接下来就可以看到我们的的MCP配置已经设置成功了,可以免费5000次请求
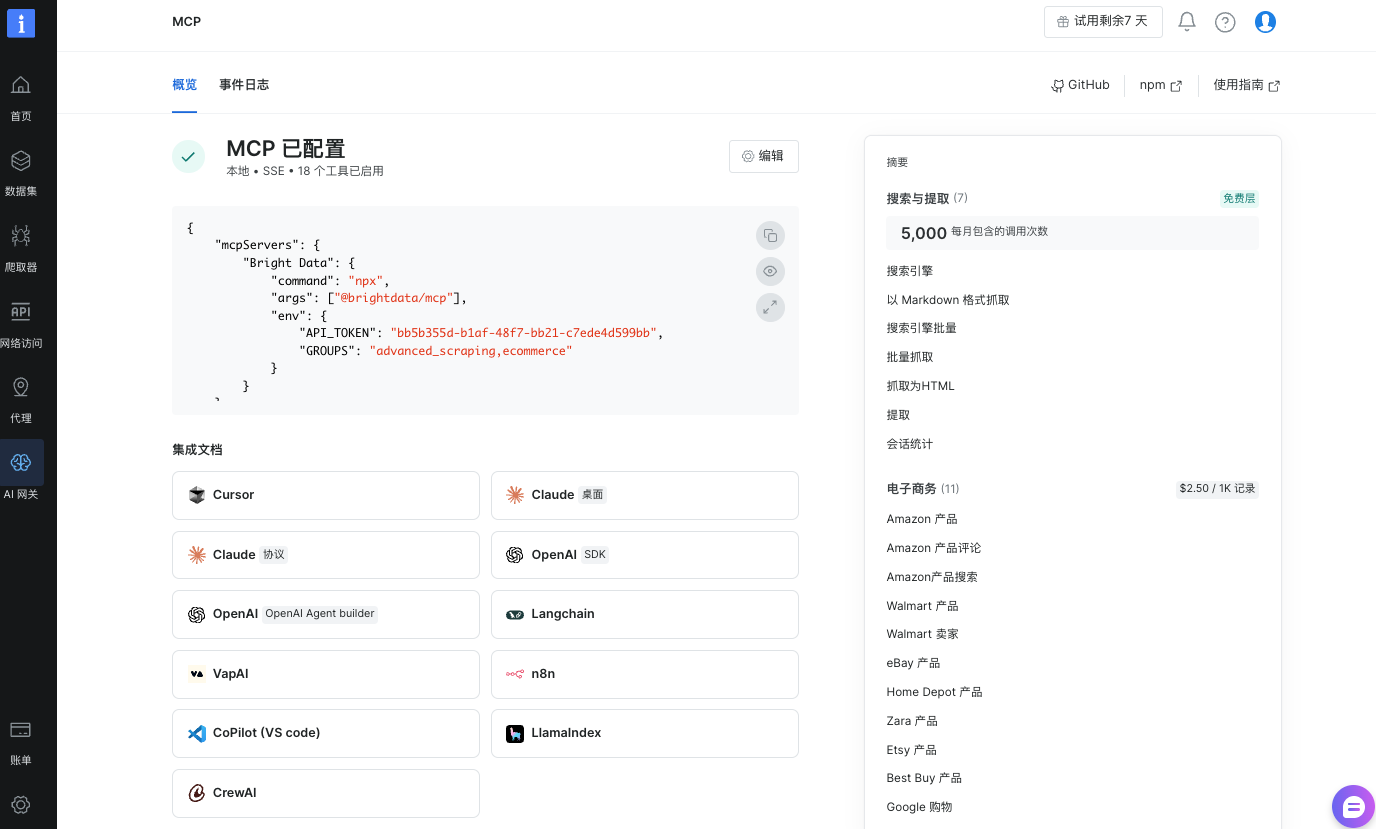
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "YOUR_BRIGHTDATA_API_KEY",
"GROUPS": "advanced_scraping,ecommerce"
}
}
}
}
说明:YOUR_BRIGHTDATA_API_KEY 为官方文档中的环境变量名;GROUPS 取 ecommerce 以包含 Amazon / eBay 等电商类 web_data_,advanced_scraping 用于 extract、scrape_batch 等辅助能力;POLLING_TIMEOUT 控制 web_data_ 轮询等待时间(秒)。
在设置-用户管理界面还有促销代码
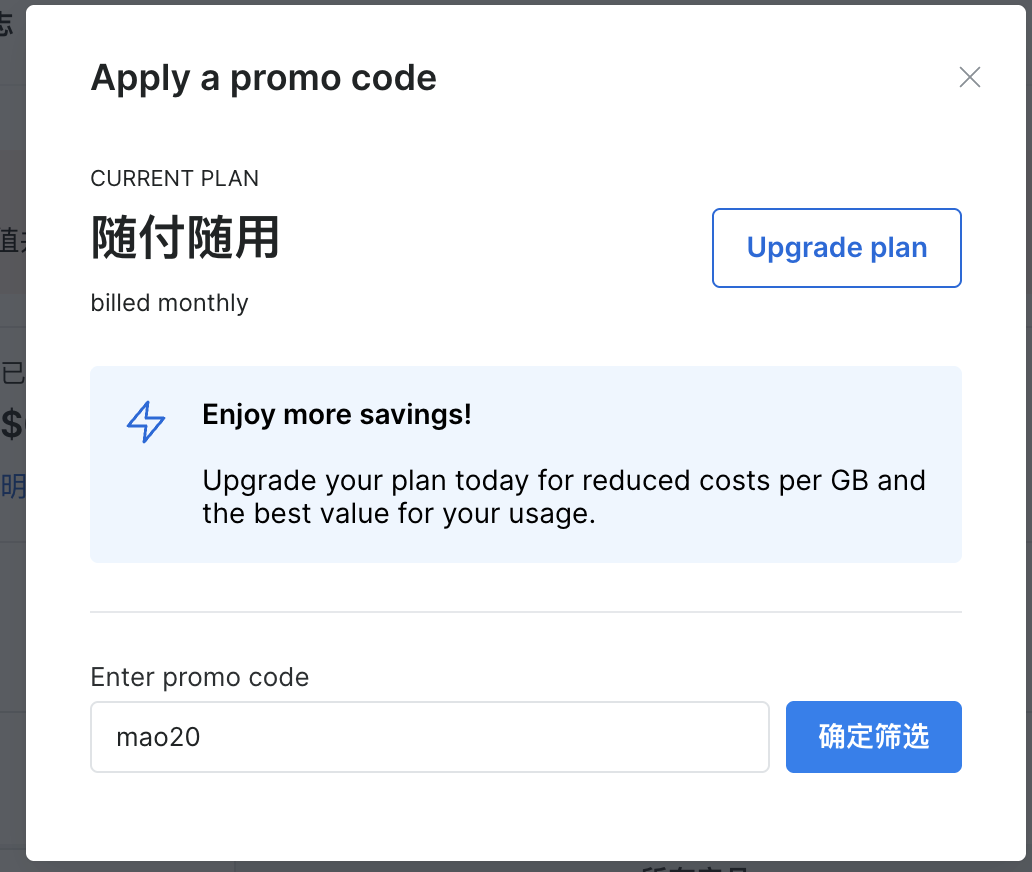
然后输入mao20折扣码,就可以获得20美元体验金。

五、启用 Skill
将skill放到claude、cursor 、codeX都是可以的,这里我拿cursor示例。首先可以配置下rules,用户在 Cursor 中讨论 Bright Data 多平台采集时,提醒先读取仓库中的 SKILL.md。在路径.cursor/rules/brightdata-multi-platform.mdc配置如下
---
description: (可选,仅 Cursor)当用户在 Cursor 中讨论 Bright Data 多平台采集时,提醒先读取仓库中的 SKILL.md。
globs:
alwaysApply: false
---
以下仅在 **使用 Cursor 作为 MCP 宿主** 时起辅助作用;**Skill 正文以仓库根目录 `SKILL.md` 为准**,本规则不能替代该文件。
当对话涉及 **Amazon、eBay、Temu** 商品抓取或多平台数据采集,且用户意图依赖 **Bright Data MCP** 时:
1. 读取 **`SKILL.md`**(若工作区根目录为本仓库则路径为根目录 `SKILL.md`,否则可能是 **`brightdata-claude-kit/SKILL.md`**);亦可通过 **`@SKILL.md`** 由用户显式附加。
2. 禁止在未调用 MCP 工具并得到返回前编造价格、评分或库存。
3. 输出须符合 `SKILL.md` 中的 JSON Schema,并包含 **`raw_tool`**。
接下来配置下skills,在路径.cursor/rules/brightdata-multi-platform/SKILL.md配置你的skills,我已把skills上传到githup,可自取。
比如我想爬取亚马逊的商品数据输入提示词:
Amazon 搜索「冲锋衣」,站点首页:https://www.amazon.com,爬取10页;优先 web_data_amazon_product_search,否则页面抓取;输出完整 JSON
可以看到MCP会自动调用SKILL去进行操作
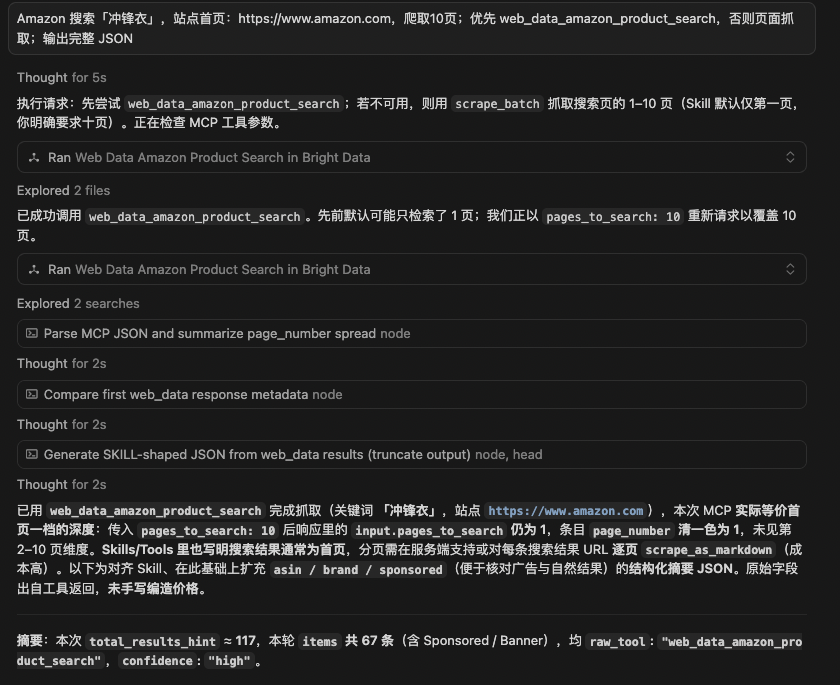
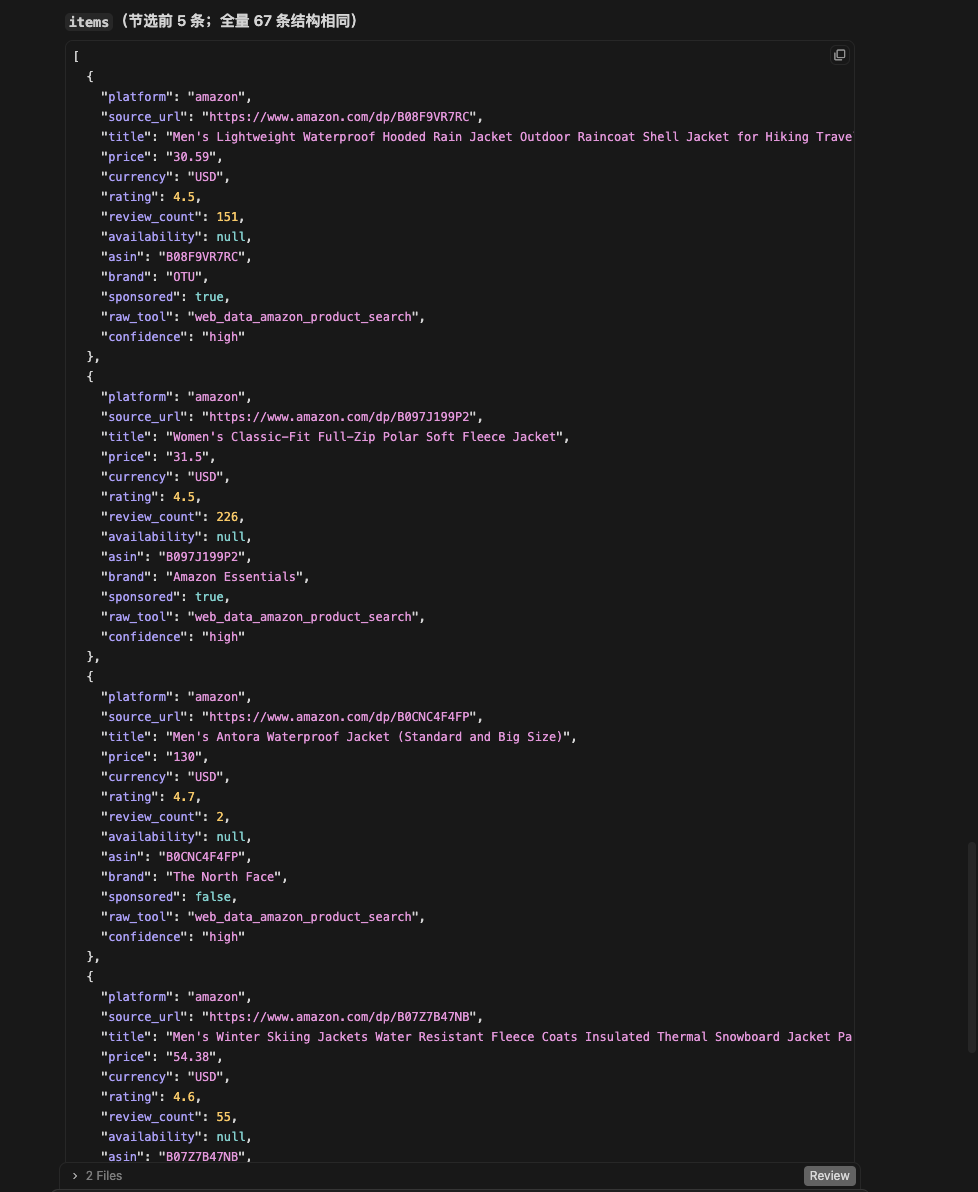
最终输出的结果如下:
接着我想爬取eBay上的商品数据。输入下面的关键字
关键词「冲锋衣」,这次改成在 eBay(ebay.com) 上找。先帮我搜出几条正常的商品链接(链接里有 /itm/),再抓标题、价格这些,最后用 JSON 给我。
执行之后
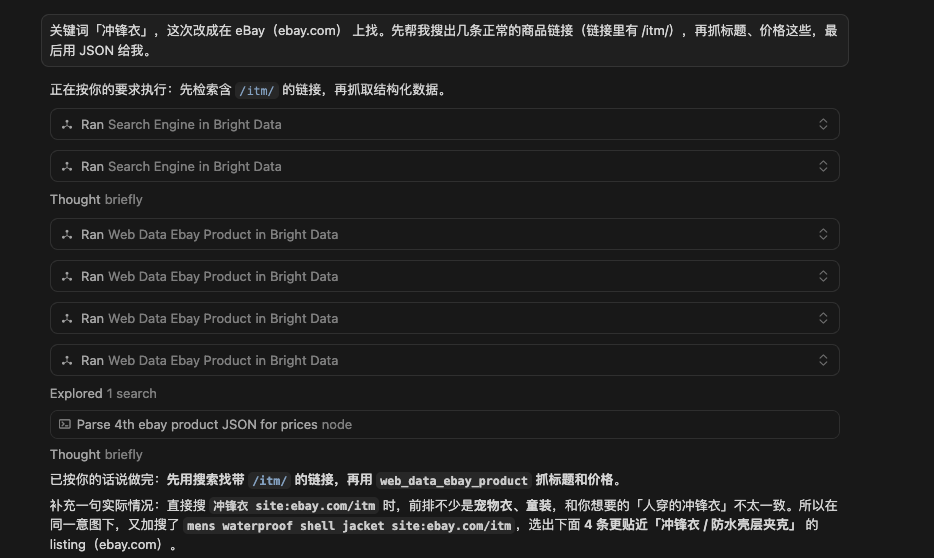
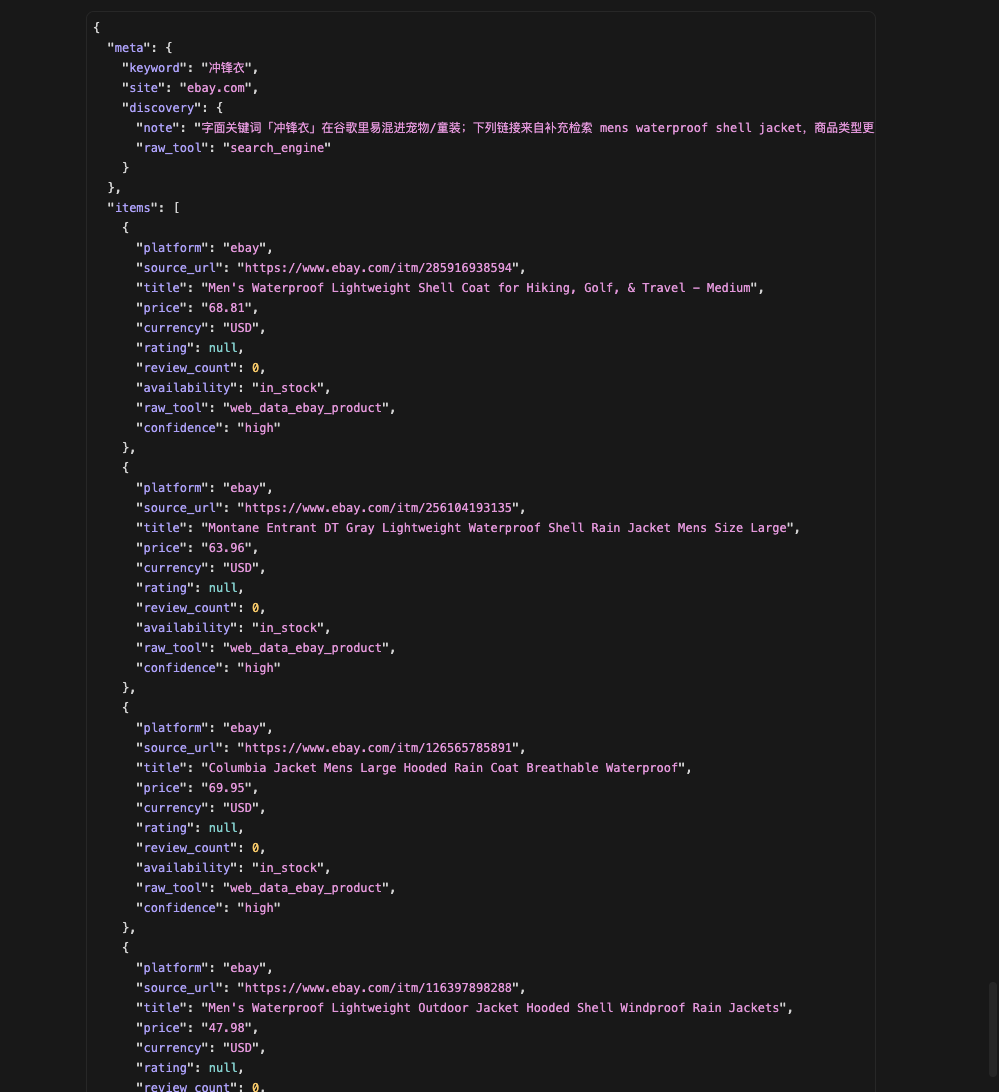
最终爬取到结果如下:
FAQ
1、Bright Data MCP 是免费的吗?
是的,MCP 提供免费额度,并支持 AI Agent 实时访问 Web 数据。
2、哪种 proxy 最适合 web scraping?
Residential proxies 最适合高反爬网站,因为其真实用户 IP 更难被检测。
3、可以用 proxy 抓 Google 吗?
不可以,必须使用 SERP API,否则会返回 HTTP 403。
4、MCP 和 Web Scraper API 有什么区别?
MCP 是调用层,Web Scraper API 是数据采集执行层。
六、总结
以前要做跨平台商品比价,要么自己写爬虫、租代理、折腾反爬,要么维护好几套脚本累死人。各平台经常改版,光修解析就能把人耗光。自建爬虫的成本不在“写代码”,而在“长期维护反爬”。Bright Data + MCP 的价值在于:把最难、最不稳定的部分(代理、解锁、解析)完全外包,让你只关注数据本身。
- 接入 Bright Data MCP:专门做采集的基础设施,反爬、代理、解析全交给它,你只管拿结果。
- 配一个 Skill(SKILL.md):告诉 Claude 先调哪个工具、输出什么格式,防止模型瞎编字段。
- 分平台处理:Amazon、eBay 有现成的结构化接口(web_data_*),Temu 没有就改用 Markdown 抓取再提取,一样能跑。
最后你只需要在 Claude、Cursor 里配置好 MCP,给个关键词和站点,剩下的自动执行,返回统一格式的 JSON。不管是自己看价格、存数据库,还是做监控告警,下游直接接就行。
如果想快速验证这套方案,可以直接跑一下本文中用到的skill , 不用自己写爬虫、不用管反爬、不用担心改版崩掉,只需要等结果就行。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)