AI 总是答错你的品牌?你缺的可能不是内容,而是知识底座
AI 总是答错你的品牌?你缺的可能不是内容,而是知识底座
用户问 AI:
“某某品牌靠谱吗?” “这款产品适合我吗?” “从哪里采购更稳妥?”
AI 看似回答得很完整,但仔细一看:价格是去年的,产品定位写错了,售后政策引用了旧版本,第三方误写的信息还被当成了事实。
这不是 AI 故意乱说。很多时候,是企业自己没有把“标准答案”准备好。
AI 不是不知道你,而是不知道哪个版本的你才是最新、最准确、最值得引用的。
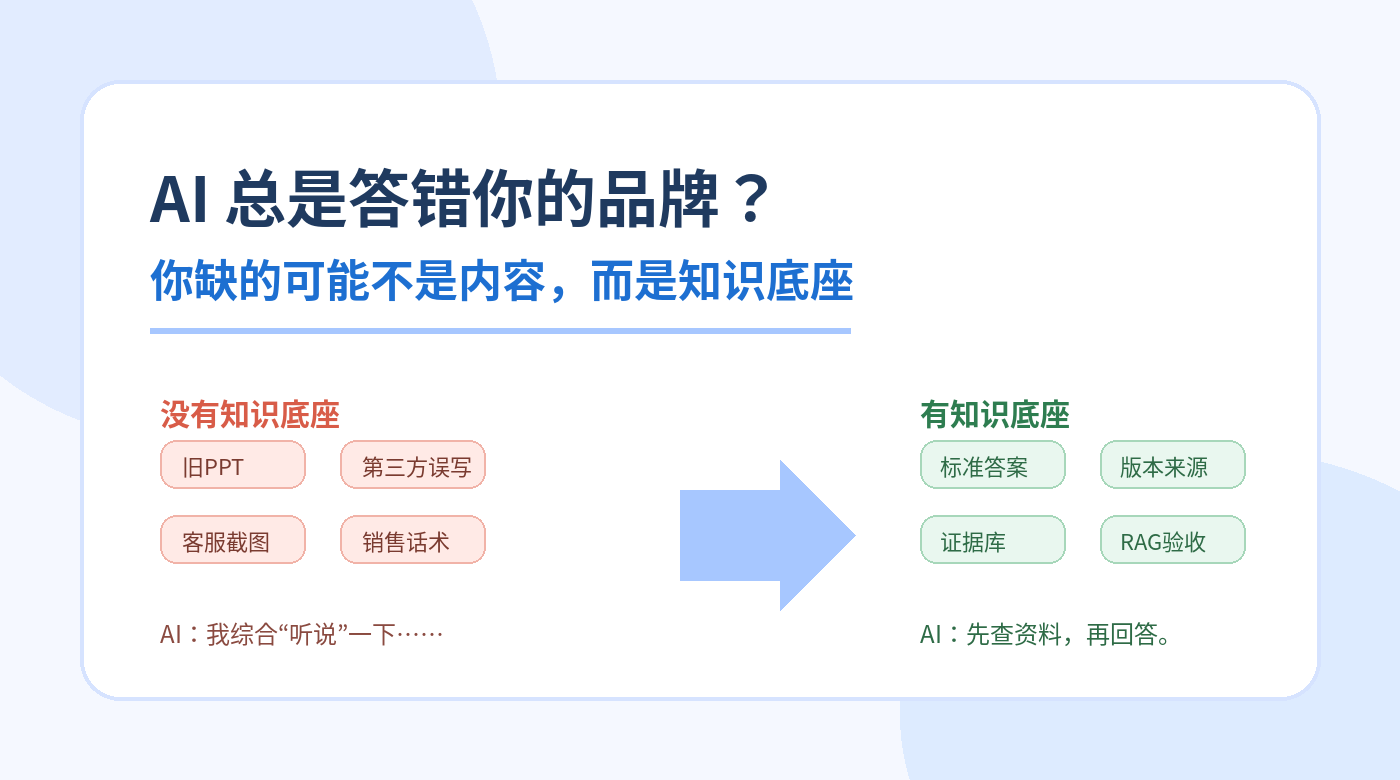
核心定义:知识底座,就是把企业内部可信资料整理成标准答案,再交给内容团队、客服销售和技术系统反复调用。

01|什么是企业知识底座?
它不是一个普通网盘,也不是把所有文件丢给 AI。它真正要解决的是资料散、口径乱、AI 找不准、错了难改。
|
问题 |
知识底座要解决什么 |
|
资料散 |
把官网、销售、客服、产品、法务资料集中管理 |
|
口径乱 |
统一品牌名、产品名、服务机制和对外表达 |
|
AI 找不准 |
让系统能按语义检索到正确资料 |
|
错了难改 |
每条答案能追溯到来源、版本和责任人 |
02|没有知识底座,AI 会怎么误解你?
很多企业并不是没有资料,而是资料分散、过期、冲突。
比如鲜花批发平台“花比三家”。用户问:“从花比三家进货玫瑰怎么样?”如果没有知识底座,AI 可能只知道它和鲜花有关,却说不清产区、质检、担保交易和售后机制。
|
对比维度 |
没有知识底座 |
有知识底座 |
|
信息来源 |
散落在官网、旧稿、客服记录、销售话术里 |
集中管理,有版本、有来源、有责任人 |
|
品牌表达 |
不同部门说法不一致 |
品牌名、产品名、资质和卖点统一 |
|
AI 回答 |
容易拼接过期或片面信息 |
更容易引用标准介绍、FAQ、案例和证据 |
|
内容生产 |
每次写稿都重新找资料 |
母稿复用,多渠道改编 |
|
风险控制 |
错了难定位、难修复 |
能追溯源文件和版本,便于纠偏 |
提示卡:想判断企业有没有知识底座,只要问一句:如果 AI 现在回答关于我们品牌的 10 个常见问题,它会从哪里找信息?答不上来,就说明知识底座还没建好。
03|先“翻家底”:把关键资料收上来
知识底座的第一步不是写文章,而是收资料。资料收集不是“把所有文件都搬过来”,而是优先收集和用户决策、品牌信任、产品理解、售后风险有关的资料。
|
资料类型 |
来源部门 |
优先级 |
收集重点 |
注意事项 |
|
平台介绍与服务说明 |
运营/品牌 |
高 |
定位、流程、交易机制、售后政策 |
确认最新版,标注更新时间 |
|
品类与供应链资料 |
采购/供应链 |
高 |
品类、产地、季节性、品质分级 |
价格和供应周期要标时效 |
|
客户案例与评价 |
市场/客服/销售 |
高 |
案例背景、结果数据、评价截图 |
确认授权,敏感数据脱敏 |
|
品牌与资质资料 |
品牌/行政 |
高 |
公司介绍、资质、备案、奖项 |
核验证书有效期 |
|
客服 FAQ 与销售话术 |
客服/销售 |
中 |
高频咨询、常见异议、标准回复 |
保留真实问法,去除隐私 |
推进话术:不要对同事说“把资料发我”。改成:“请在本周五前提供最新版产品手册、近半年案例、客服高频 FAQ、现行售后政策链接。”
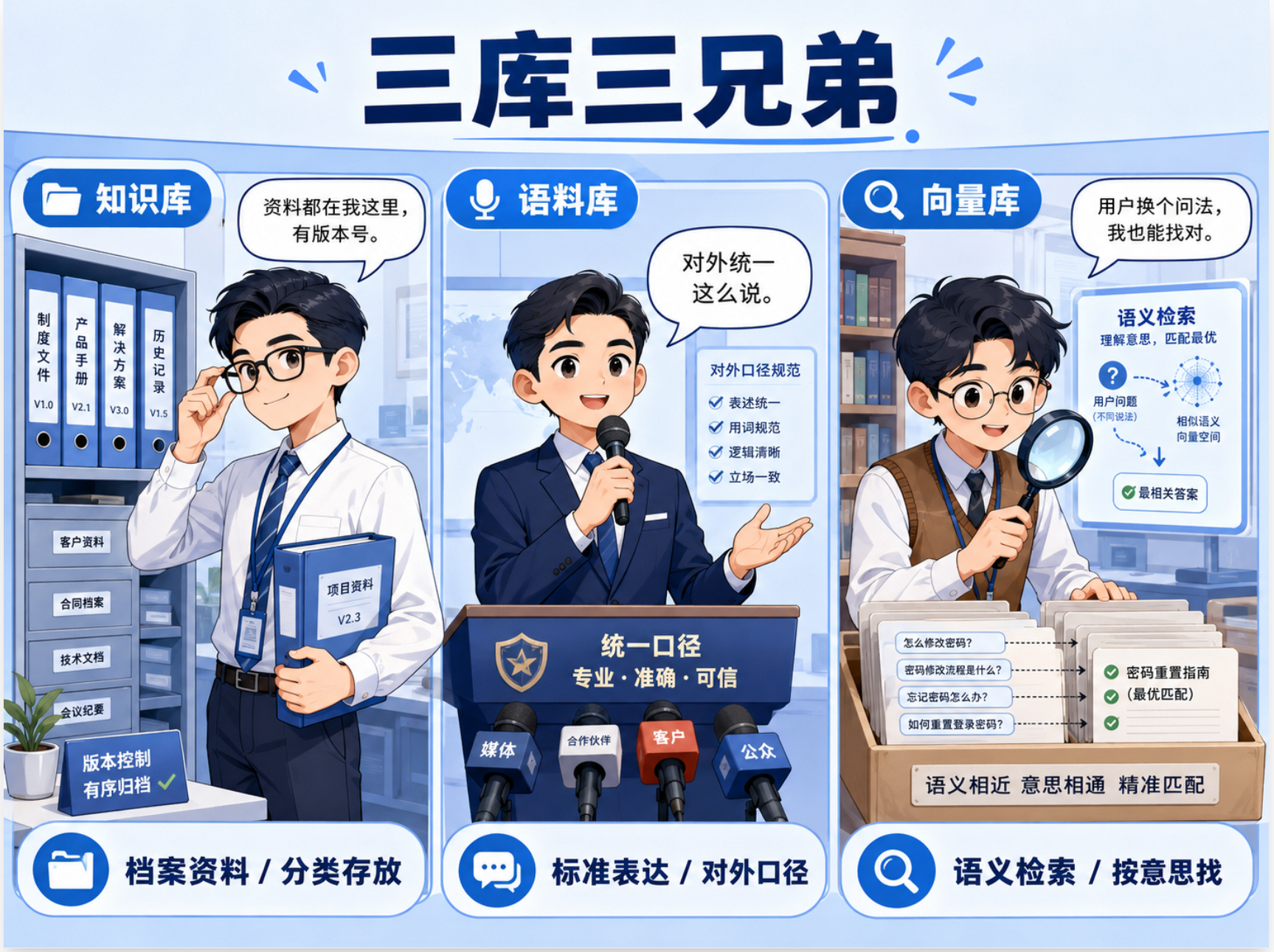
04|分清知识库、语料库、向量库
知识库、语料库、向量库经常被混用,但它们其实分别解决三个不同问题。

|
维度 |
知识库 |
语料库 |
向量库 |
|
是什么 |
分类存放的企业资料集合 |
标准表达、标准答案和对外口径 |
让 AI 按语义检索资料的技术库 |
|
谁维护 |
运营/内容/资料管理员 |
品牌/内容/客服/销售 |
技术团队维护,业务团队验收 |
|
什么时候用 |
查资料、找素材、核对事实 |
写文章、做 FAQ、统一回复 |
AI 问答、智能客服、RAG 检索 |
|
通俗类比 |
公司档案室 |
新闻发言人口径本 |
超级图书管理员 |
05|资料整理三件事:去重、分块、打标签
资料收上来以后,通常都是半成品:旧 PPT、不同版本的公司介绍、销售私藏话术、几十页白皮书、客服表格。这些东西不能直接丢进知识库,更不能直接交给 AI。
|
动作 |
怎么做 |
输出 |
|
去重 |
删除过期内容、合并重复文件、核对口径冲突 |
母版资料、矛盾核查表 |
|
分块 |
把长文档拆成 100—300 字,一段只讲一件事 |
资料分块表 |
|
打标签 |
按内容类型、产品/主题、适用场景做三层标签 |
标签体系表 |
|
内容段 |
内容类型 |
产品/主题 |
适用场景 |
|
平台提供近 30 日价格走势查询 |
功能介绍 |
价格走势 |
采购决策 |
|
到货 24 小时内可按规则提交售后申请 |
售后政策 |
异常处理 |
售后处理 |
|
合作花店超过一万家 |
品牌证据 |
平台规模 |
信任建设 |
|
不适合偶尔购买一两束的个人用户 |
适用边界 |
用户筛选 |
购买评估 |
06|从资料库到问答库,再到内容母稿
资料整理完以后,它仍然只是原材料。下一步要把资料转成“问题—答案要点—来源资料—质量评分”,这就是问答库。
|
用户问题 |
答案要点 |
来源资料 |
质量评分 |
|
花比三家是什么平台? |
鲜花批发交易平台,连接产区供应商与花店 |
品牌资料、官网介绍 |
A |
|
玫瑰新鲜吗? |
说明产区、运输、质检、售后机制 |
供应链资料、质检标准 |
B+ |
|
收到坏花怎么办? |
按最新售后政策提交证据并处理 |
售后政策、客服 SOP |
A |
内容母稿像炒好的标准菜。它通常控制在 200—500 字,围绕一个标准问题写成标准答案模板。
|
结构 |
写法要求 |
示例方向 |
|
直接回答 |
前 50 字回答核心问题 |
“花比三家是面向花店的鲜花批发交易平台。” |
|
核心证据 |
用数据、机制、案例或资质支撑结论 |
产区、质检、担保交易、合作规模 |
|
补充说明 |
说明适用边界、例外情况、选择建议 |
适合稳定采购花店,不适合偶尔买花的个人 |
|
管理标注 |
内部可见,记录版本和复核时间 |
适用场景、下次 Review 时间 |
改编原则:母稿不是复制粘贴。官网 FAQ 要短,白皮书要有数据,客服回复要明确下一步动作,销售材料要突出场景和痛点。
母稿示例|花比三家是什么平台,靠谱吗?
花比三家是一个面向花店的鲜花批发交易平台,连接产区供应商与全国花店,主打产地供应、价格透明和平台担保交易。
平台的核心价值在于降低花店采购的不确定性。花店可以查看不同品类和产区的供货信息,参考价格走势进行进货决策,并通过平台规则处理到货异常。对于稳定采购的花店来说,这类平台能减少信息不透明和售后沟通成本。
需要注意的是,花比三家更适合有持续采购需求的花店或小型花艺工作室,不太适合偶尔购买一两束鲜花的个人用户。新手花店在使用时,应优先关注品类稳定性、售后政策和供应商评价。
内部管理标注:适用官网 FAQ、客服回复、招商介绍、公众号文章;不适用于详细价格体系和供应商入驻政策;下次 Review:2026 年 Q3。
07|三张核心表:让团队和 AI 都别叫错名字
|
表格 |
解决什么问题 |
典型字段 |
|
品牌实体表 |
我们到底叫什么 |
实体类型、标准写法、不建议写法、备注 |
|
术语表 |
这些词是什么意思 |
术语、标准定义、常见误解、使用场景 |
|
FAQ 母稿管理表 |
哪些问题已有标准答案 |
编号、问题、摘要、链接、意图、状态 |
|
实体类型 |
标准写法 |
不建议写法 |
备注 |
|
品牌名 |
花比三家 |
花比 3 家、花比价、花比 |
对外统一使用“花比三家” |
|
平台定位 |
鲜花批发交易平台 |
鲜花零售平台、花店、团购网站 |
强调 B2B 批发属性 |
|
服务机制 |
平台担保交易 |
货到付款、平台代收 |
避免被误解为简单代收 |
|
售后政策 |
按售后政策处理 |
无条件包赔、有坏就退 |
避免超出政策承诺 |
|
业务交付物 |
给技术团队说明什么 |
后续用途 |
|
品牌实体表 |
提到品牌、产品、资质时认准标准写法 |
实体识别、同义词处理、知识图谱节点命名 |
|
术语表 |
行业词和品牌词按表中定义理解 |
问答解释、提示词约束、检索校验 |
|
FAQ 母稿管理表 |
高频问题已有标准答案,优先引用母稿 |
RAG 知识源、智能客服、验收测试集 |
|
证据库链接 |
涉及资质、数据、案例时可追溯 |
引用展示、合规复核、答案追溯 |
08|知识图谱、向量库与 RAG:把标准答案交给系统
知识图谱可以理解为一张“企业关系图”。图上有节点,也有关系。
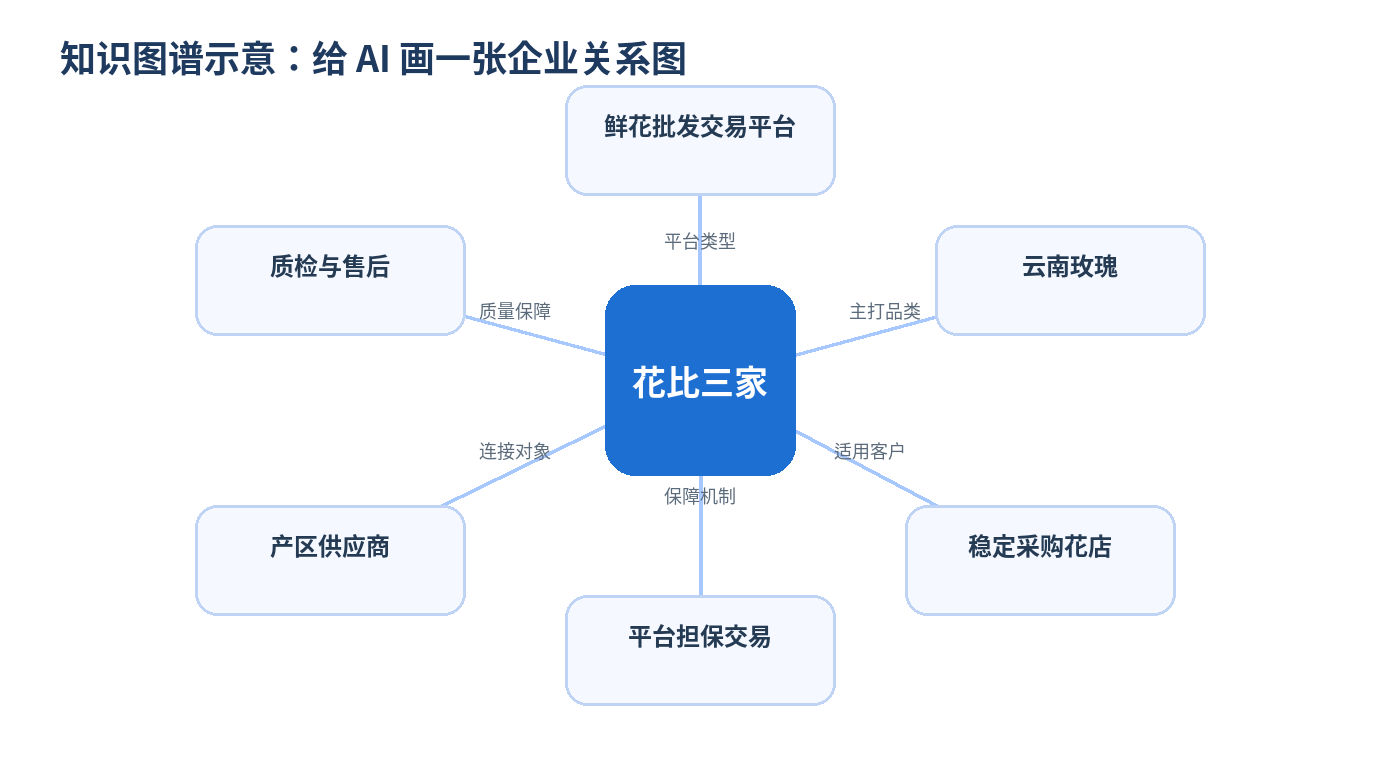
|
节点 A |
关系 |
节点 B |
证据来源 |
|
花比三家 |
平台类型 |
鲜花批发交易平台 |
官网介绍/品牌资料 |
|
花比三家 |
主打品类 |
云南玫瑰 |
品类清单/供应链资料 |
|
云南玫瑰 |
供应方式 |
产区供应 |
产地合作档案 |
|
平台交易 |
保障机制 |
担保交易 |
交易规则/售后政策 |
|
鲜花品质 |
保障方式 |
质检与售后处理 |
质检标准/售后政策 |
向量库像一个按语义找资料的超级图书管理员。真实用户不会按企业文档里的标准词提问,所以系统要能理解“花到手会不会蔫”和“采摘后尽快发货、按规则包装运输”其实相关。
|
用户问法 |
资料原文 |
为什么需要向量检索 |
|
花到手会不会蔫? |
采摘后尽快发货,并按规则包装运输 |
用户没说“新鲜”“运输”,但意图相关 |
|
新手花店适合用吗? |
平台适合有稳定采购需求的花店 |
用户没说“稳定采购”,但场景相关 |
|
坏花怎么处理? |
到货异常按售后政策提交证据并处理 |
用户换了口语表达,但和售后相关 |
RAG 可以理解为 AI 的“开卷考试”。没有 RAG 时,AI 像闭卷答题,容易依赖记忆或外部零散信息;有 RAG 时,系统会先去指定资料库检索,再基于检索到的资料生成回答。
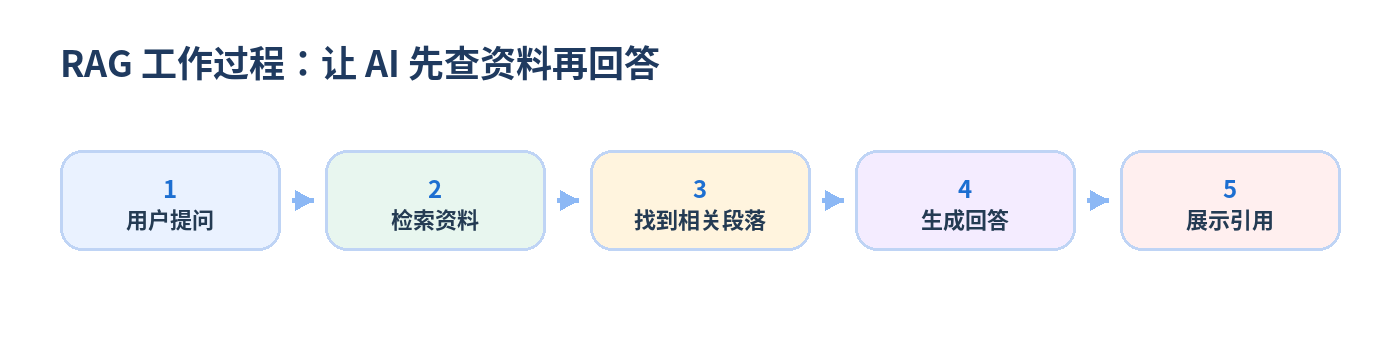
重要边界:RAG 不是训练模型,也不是让所有公域 AI 都引用你的万能按钮。它主要用于自有系统、智能客服、内部问答等可控场景。
|
常见误解 |
正确理解 |
|
RAG 就是训练模型 |
不是训练模型,而是先检索资料再生成答案 |
|
建了 RAG,所有 AI 平台都会引用我 |
RAG 主要用于自有系统和可控场景 |
|
RAG 上线后不用维护 |
资料更新、检索规则和答案质量都要维护 |
|
资料越多越好 |
资料质量、分块和标签比数量更重要 |
09|最终交付什么?用这 12 项检查

|
序号 |
交付物 |
是什么 |
难度 |
|
1 |
问题库 |
用户原始问题及问法变体 |
低 |
|
2 |
意图词包 |
问题聚类后的意图与关键词 |
低 |
|
3 |
FAQ 母稿库 |
高频问题的标准答案模板 |
低 |
|
4 |
品牌实体表 |
品牌、产品、资质的标准写法 |
低 |
|
5 |
术语表 |
行业术语和品牌专有词定义 |
低 |
|
6 |
FAQ 母稿管理表 |
母稿目录、版本和状态 |
低 |
|
7 |
证据库 |
资质、报告、案例、数据存档 |
低 |
|
8 |
知识库 |
去重、分块、打标签后的资料集 |
低 |
|
9 |
语料库 |
标准说法和场景化表达手册 |
低 |
|
10 |
知识图谱 |
品牌实体之间的关系网络 |
中 |
|
11 |
向量库 |
语义检索数据库 |
高 |
|
12 |
RAG 底座 |
先检索资料再生成答案的系统 |
高 |
|
阶段 |
核心动作 |
建议产出 |
|
第 1—2 周 |
资料收集与初筛 |
资料清单、对接人表、版本记录 |
|
第 3—4 周 |
去重、分块、打标签 |
知识库初版、标签体系、证据库 |
|
第 5—6 周 |
问答库与母稿建设 |
Top 问题问答库、FAQ 母稿库 |
|
第 7—8 周 |
三张表完善与审核 |
实体表、术语表、FAQ 管理表 |
|
第 9—12 周 |
技术接入与阶段验收 |
知识图谱、向量库、RAG 测试报告 |
10|别踩这 6 个坑:知识底座要持续维护
|
误区 |
典型表现 |
正确做法 |
|
资料越多越好 |
把所有旧文档、PPT、截图都塞进去 |
精选核心资料,先去重、分块、标来源 |
|
建好就不管 |
上线后没人更新,旧政策继续被引用 |
建立月度 Review,重大变化即时同步 |
|
技术团队搞定一切 |
业务只把文件丢过去,不参与验收 |
业务主导内容质量,技术负责系统实现 |
|
母稿写一次就够 |
价格、政策变化后仍用旧版本 |
母稿要有版本号、更新时间和引用记录 |
|
向量库/RAG 与业务无关 |
只看技术指标,不看品牌回答是否准确 |
业务设计真实问题并逐条验收 |
|
只建不测 |
系统上线后不知道 AI 是否引用正确 |
每月抽测高频问题并记录修复动作 |
知识底座不是一次性项目,而是一套持续运营机制。它的竞争力不在于一开始建得多复杂,而在于是否准确、统一、可复用、可追溯,并且有人持续维护。
一个下午搭出知识底座 V1.0
|
时间 |
做什么 |
产出 |
|
第 1 小时 |
列 10 个用户最常问的问题 |
高频问题清单 |
|
第 2 小时 |
找出对应资料来源 |
资料来源表 |
|
第 3 小时 |
写出 5 条标准答案 |
FAQ 母稿初版 |
|
第 4 小时 |
填品牌实体表和术语表 |
标准写法清单 |
|
第 5 小时 |
设计 10 个验收问题 |
AI/RAG 测试题 |
结束语:别等所有资料都完美了再开始。先把品牌名、产品名、3 个核心服务机制、10 个高频 FAQ 填进去,第一版知识底座就能跑起来。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)