内容整理二:Vision Transformer(VIT)
全网最强ViT (Vision Transformer)原理及代码解析:全网最强ViT (Vision Transformer)原理及代码解析 - 知乎
PS:如果是初次入门的同学,可以直接跳过下面的内容,从上面的链接中学习。
核心攻坚:Vision Transformer (ViT)
- 理论阅读:精读神作 An Image is Worth 16x16 Words。这篇论文彻底改变了 CV 领域。阅读时,复杂的数学推导可能是个坎。遇到难以理解的公式,直接用 Mathpix 把它们提取出来放到你的 Overleaf 学习笔记里,逐行推导梳理。你需要深刻理解图像是如何被切分成 Patch,并转化为一维 Token 序列的.
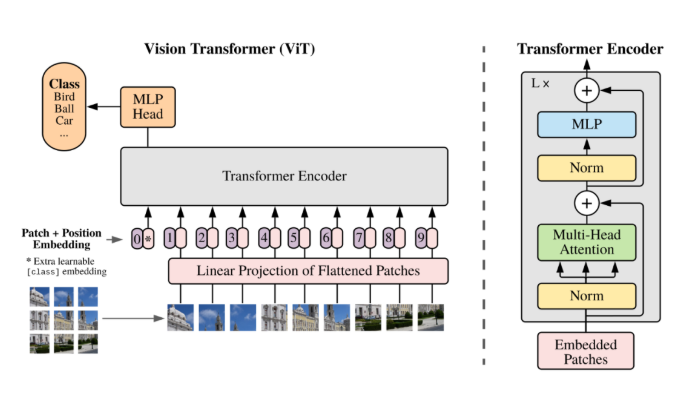
ViT (Vision Transformer) 核心原理解析报告
论文全称:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
核心标签: 计算机视觉里程碑、CV与NLP大一统、大规模预训练、颠覆CNN
1. 背景与痛点:被 CNN 统治的视觉世界
在 2020 年之前,人工智能的两个大方向有着截然不同的命运:
- 自然语言处理 (NLP): Transformer 架构(如 BERT, GPT)一统天下。大家发现,只要把 Transformer 做得足够大,喂给它海量的文本,它的表现就像没有天花板一样不断飙升。
- 计算机视觉 (CV): 依然是卷积神经网络(CNN,如 ResNet)的绝对主场。
为什么不能直接把 Transformer 用在图像上? Transformer 的核心是全局自注意力机制 (Self-Attention),它要求序列中的每一个元素都要和其他所有元素计算关联度。 如果把一张 $224 \times 224$ 的图片直接喂给 Transformer,它会把每个像素当成一个单词,这就意味着一个像素要和另外 50,176 个像素算注意力。计算量呈平方级爆炸,当时的显卡根本算不动。
前人的妥协: 为了解决计算量问题,前人发明了各种“魔改”的注意力机制(比如只算局部 $7 \times 7$ 的像素,或者跳着算)。但这些特殊的结构极其破碎,在 GPU/TPU 上运行效率极低。
ViT 的野心: 我们能不能不做任何魔改,直接把 NLP 里最标准、工业界优化得最完美的 Transformer 直接拿来处理图片?
2. 核心思想:把图片当成一句话 (An Image is Worth 16x16 Words)
ViT 的解决思路极其暴力却又无比优雅:既然像素太多算不动,那我就把图片切成块 (Patches)。
我们可以把这个过程想象成“图像的语言化”:
- 英文句子: "I / love / learning / deep / learning." (5 个单词)
- 图像输入: 将一张完整的图片,切成横竖排列的 $16 \times 16$ 像素的小方块。这一个个小方块,在模型眼里就等同于英语里的“单词”。
极简的数学推演:
假设我们有一张标准的 ImageNet 图片,大小为 $224 \times 224$ (RGB 3通道)。
- 切块: 设定每个块的大小为 $16 \times 16$ 像素。
- 算数量: 宽能切 $224 \div 16 = 14$ 块,高能切 $14$ 块。整张图被切成了 $14 \times 14 = 196$ 个块。
- 算维度: 每个块包含 $16 \times 16 \times 3 = 768$ 个像素值。
就这样,一张 3D 的图像 $[224, 224, 3]$,被物理学切割并展平,变成了一个 2D 矩阵 $[196, 768]$。 在 Transformer 看来,这就是一句由 196 个单词组成的句子,每个单词是一个 768 维的词向量。 模态的壁垒被彻底打通了!
3. 模型架构拆解:四大步骤
ViT 的模型架构完全照搬了 NLP 中的 Transformer,没有任何专门为视觉定制的卷积操作。
第一步:线性映射 (Linear Projection / Patch Embedding)
切好的 $[196, 768]$ 的矩阵,会通过一个简单的全连接层(可以理解为一个无激活函数的 $1 \times 1$ 卷积),把它映射到一个统一的特征维度 $D$。转换后的特征被称为 Patch Embeddings(图像块嵌入)。
class PatchEmbed(nn.Module):
""" 2D Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, norm_layer=None, flatten=True):
super().__init__()
# img_size = (img_size, img_size)
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.flatten = flatten
# 输入通道,输出通道,卷积核大小,步长
# C*H*W->embed_dim*grid_size*grid_size
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x)
if self.flatten:
x = x.flatten(2).transpose(1, 2) # BCHW -> BNC
x = self.norm(x)
return x第二步:安插“间谍” ([class] token)
模仿 NLP 里的 BERT,作者在由 196 个图像块组成的序列最前面,硬塞进去第 197 个向量([class] token)。 这个 token 一开始是随机的,它跟着所有图像块一起进入网络,通过注意力机制不断吸收其他 196 个块的信息。等网络处理完毕后,我们直接丢弃那 196 个块的输出,只取这个 [class] token 的结果,认为它浓缩了整张图的全局特征,并直接用它进行分类分类。
第三步:赋予空间灵魂 (Position Embeddings)
因为 Transformer 是同时处理所有数据的,它不知道第一块在左上角,最后一块在右下角。 为此,我们需要生成 197 个位置编码向量,直接与前面的图像特征按位相加 (Add)。有趣的是,作者发现用最简单的一维排号(从 1 数到 196)效果就很好,不需要专门设计复杂的二维坐标编码。

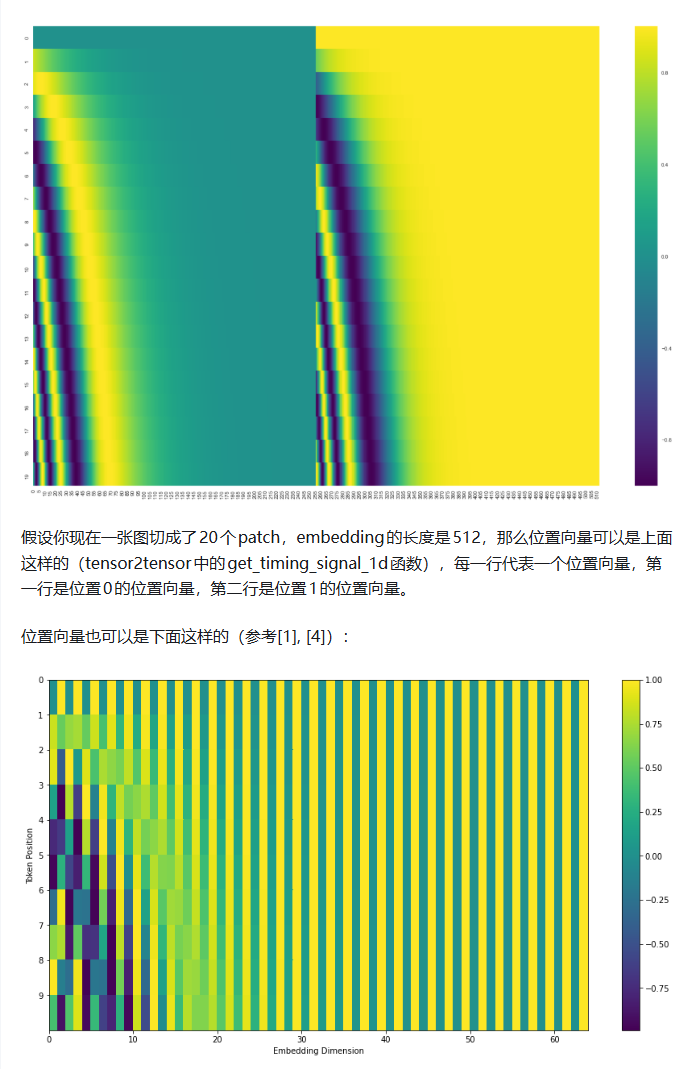
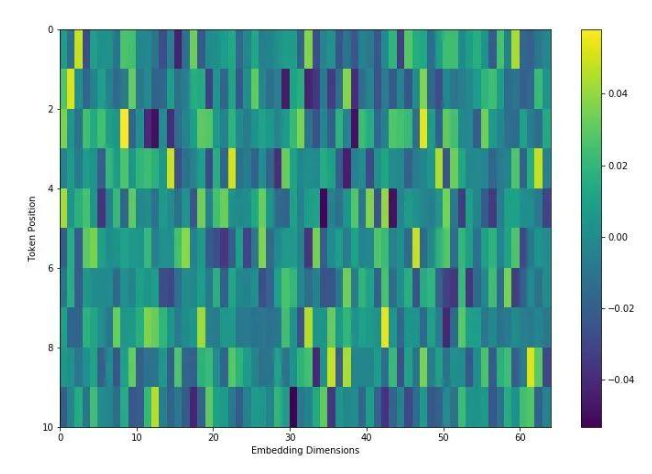
第四步:标准的 Transformer Encoder
拼装好后,数据直接送入 Transformer 编码器。编码器内部只有两个主要组件不断交替:
- 多头自注意力机制 (Multi-Head Attention): 负责让 197 个块互相“交流”,学习图像的全局依赖关系。
- 多层感知机 (MLP): 负责特征的非线性映射。 (每一层都会配合 LayerNorm 和残差连接操作)。
4. 底层灵魂:归纳偏置 vs. 大数据 (Inductive Bias)
这也是这篇论文在深度学习理论上最重要的贡献。
为什么 CNN 曾经那么强? 因为 CNN 自带“作弊码”——归纳偏置 (Inductive Bias)。卷积核天生假设“相邻的像素关系更紧密(局部性)”,而且知道“左上角的猫和右下角的猫都是猫(平移等变性)”。在数据量不大的时候,CNN 靠着这些先验知识能学得又快又好。
为什么 ViT 是真正的潜力股? ViT 是一个“纯白板”。它切块之后,根本不知道块与块之间谁挨着谁,一切的空间关系、图像常识,都要靠强大的全局注意力机制从零开始学。
- 劣势: 在中等规模数据(如 ImageNet,130万张)上,ViT 的准确率略逊于同级别的 ResNet。因为数据不够,白板没学明白。
- 绝杀: 作者抛出了深度学习黄金定律——"Large scale training trumps inductive bias"(大规模训练胜过归纳偏置)。当把预训练数据放大到 1400万(ImageNet-21k)甚至 3亿张(JFT-300M)时,奇迹发生了。ViT 自己从海量数据中悟出的底层规律,彻底压倒了人类专家设计的 CNN 结构。
5. 实验结果与工程亮点
- 算力性价比的碾压: 在达到同期最优准确率(SOTA,ImageNet 88.55%)的情况下,超大杯的 ViT-H/14 消耗的预训练算力,不到当时最强 CNN (Noisy Student) 的四分之一。
- 迁移学习的工程 Trick: 通常我们会用更高分辨率的图片进行微调(Fine-tuning)。比如预训练用 $224 \times 224$ (切 196 个块),微调拿 $384 \times 384$ (切 576 个块)。 序列变长了 Transformer 不怕,但位置编码不够分了怎么办? 作者使用了一个巧妙的 2D 插值法:把原来 196 个一维位置编码还原成 $14 \times 14$ 的网格,用几何插值放大到 $24 \times 24$,再展平成 576 个一维编码。这也是整个模型唯一手动注入了 2D 图像先验知识的地方。
6. 总结与意义
ViT 的伟大之处不在于它提出了多么复杂的公式,而在于它用极简的暴力美学证明了一件事: 计算机视觉和自然语言处理的底层架构是可以统一的。 只要数据和算力足够,通用的 Transformer 架构完全可以舍弃特定领域的归纳偏置。它直接为后来这几年的多模态大模型(如 CLIP、Sora、GPT-4V 等)铺平了底层架构的道路,标志着大模型“大基建时代”的全面到来。
备注:当然上面的内容,一眼可以看出来是LLM生成的内容,确实是将学习过程中的过程步骤经过模型进行了梳理,如果有不对的地方,也欢迎大家指出。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)