浅谈:特征工程与过拟合
特征工程
特征工程是从原始数据中选择、转换和创建新特征,以提高机器学习模型性能的过程。它涉及利用领域知识从数据中提取最相关的信息,并以适合机器学习算法的方式表示出来。
简单来说,特征工程就是把"原始数据"翻译成"模型能听懂的语言"的过程。例如,原始数据是"客户上周二下午2:30访问了网站,浏览了5个产品页",经过特征工程后变成"工作时间购物"和"高浏览转化率"这样模型更容易理解的输入。
特征工程-常用预测(分类,回归)模型:
- 分类算法:LR , SVM,RF
- 树模型:GBDT, XGBoost, LightGBM, CatBoost
序贯特征选择 (SFS)
序贯特征选择 (SFS) 就像选秀淘汰制——从0开始,每次只加一个最能提升模型表现的特征,直到加无可加为止。
# SFS执行逻辑(前向搜索)
已选特征池 = []
候选特征池 = [196个v_i*v_j特征]
while True:
对每个候选特征:
临时加入已选池,训练模型,记录CV得分
选出 加入后提升最大 的那个特征
if 提升 > 阈值:
移入已选池,移出候选池
else:
停止(再也加不动了)
假设我们已生成196个多项式特征,命名为 new{i} _ {j}:
v_3单独用可能重要性一般
v_14单独用也一般
但 v_3 × v_3 (平方项) 可能捕捉了非线性关系
v_12 × v_14 可能代表了某种技术参数的交互效应
| 特征名 | 实际含义 | 示例值 |
|---|---|---|
| new3_3 | v_3 × v_3 (v_3的平方) | 2.5×2.5=6.25 |
| new3_14 | v_3 × v_14 | 2.5×1.8=4.5 |
Round 1: 尝试所有196个特征单独加入
→ new3_3 使MAE降低最多 (从850→780)
→ 选中 new3_3,已选池=[new3_3]
Round 2: 在已有[new3_3]基础上,尝试剩余195个
→ new12_14 使MAE再降 (780→720)
→ 选中 new12_14,已选池=[new3_3, new12_14]
Round 3: 尝试剩余194个
→ new3_14 使MAE降到680
→ 选中 new3_14…
…
Round N: 加入 new5_8 后MAE只降了2(<阈值5)
→ 停止,最终保留特征如:[new3_3, new12_14,new3_14, …] 共K个
=> 从196个暴力组合中,只保留20-30个真正有用的(如new3_3、new12_14等),其余全部扔掉。
什么是CV得分?
CV得分 = Cross-Validation Score(交叉验证得分)=> 多次模拟考试取平均成绩
把训练集切成5份,轮流用4份训练、1份测试,测5次取平均。=> 这样得到的分数比只测一次更靠谱,能防作弊、防过拟合。
过拟合
过拟合就算强行记忆,参数太多了,你把答案背下来了,也叫死记硬背,只要超出一点,就摸不到头脑,完全没办法进行解答。
特征如果特别多的话,可能会出现打架,导致过拟合。
过拟合(Overfitting) 是导致模型在实际应用中表现糟糕的主要原因之一。
训练MAE = 400(模型似乎很准),测试MAE = 800(实际预测误差翻倍)=> 典型的过拟合
| 方法 | 作用 |
|---|---|
| 早停 | 监控验证集MAE,patience=15轮无改善则停止训练 |
| 神经网络 | 在神经网络中随机丢弃20%神经元 |
| L1/L2正则化 | 线性回归添加 L1或L2正则化 |
| 集成方法 | 使用Blending组合随机森林、XGBoost和神经网络 |
如何防止模型过拟合?
- 模型层面优化
- 数据层面优化
- 业务逻辑约束
如何在模型层面进行优化?
-
正则化技术(使用小一点、弱一点的模型):
树模型(catboost,xgboost):调整max_depth(深度,建议5-8)、min_samples_leaf(建议10-20,代表每个叶子节点至少包含的样本数)
神经网络:添加dropout层(0.2-0.5) + L2正则化
线性模型:增大L1/L2正则化系数 -
早停机制(连续10次没有下降,就停止训练/完成训练):模型训练轮次是5000次,但是我在2000次就结束了。监控验证集loss,设置patience=10-20个epoch,patience代表允许验证集损失validation loss连续不改善的轮次(epochs)数量。有可能会过拟合,我们需要额外的数据去做评估,需要通过验证集loss。
-
集成方法(把模型之间做融合):使用Blending(用70%训练基模型,30%训练元模型),通过30%训练线性模型,得到基模型的百分比。
正则化技术
树模型
XGBoost中的超参数
params = {
'objective': 'reg:squarederror', # 目标函数,回归问题用平方误差
'eval_metric': 'mae', # 评估指标,平均绝对误差
'learning_rate': 0.01, # 学习率,控制每棵树对最终结果的影响,越小越保守
'max_depth': 6,# 树的最大深度,防止过拟合
'subsample': 0.8, # 每棵树随机采样的样本比例,防止过拟合
'colsample_bytree': 0.8, # 每棵树随机采样的特征比例,防止过拟合
'seed': 42, # 随机种子,保证结果可复现
'nthread': -1 # 使用全部CPU线程加速训练
}
在sklearn决策树中,可以使用 min_samples_leaf参数
from sklearn.ensemble import RandomForestRegressor
# 尝试不同值观察效果
model = RandomForestRegressor(
min_samples_leaf=10, # 初始建议值
n_estimators=100,
random_state=42
)
model.fit(X_train, y_train)
XGBoost 没有 min_samples_leaf 这个参数,在 XGBoost 中,类似的参数是:min_child_weight,即一个叶子节点上最小的样本权重和(对于回归问题就是样本个数的和)。如果一个叶子节点的样本权重和小于这个值,则不会再分裂。
神经网络
如果使用神经网络,可以增加 layers.Dropout 层
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(128, activation='relu', input_shape=(X_train.shape[1],)),
layers.Dropout(0.2),
layers.Dense(64, activation='relu'),
layers.Dropout(0.1),
layers.Dense(1)
])
神经网络是一种受人脑神经元结构启发的机器学习模型。核心思想是通过大量“神经元”节点的层层连接和非线性变换,自动学习输入特征与输出目标之间的复杂映射关系。
线性模型
如果使用线性模型,比如逻辑回归,可以使用L1或L2正则化系数
model = LogisticRegression(
max_iter=100,
verbose=True,
random_state=42,
tol=1e-4,
penalty='l2', # 或 'l1'
C=1.0, # 正则化强度倒数,越小正则化越强
)
L1 正则化项是模型权重的绝对值之和: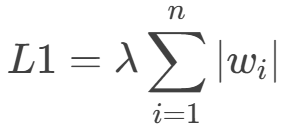
L2 正则化项是模型权重的平方和: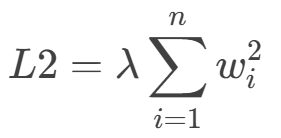
早停机制
使用早停机制,可以让模型初始化训练次数更多一些
model = xgb.train(
params,
dtrain,
num_boost_round=2000,
evals=evals,
early_stopping_rounds=20,
verbose_eval=100
)
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss',patience=20, restore_best_weights=True)
history = model.fit(
X_train_scaled, y_train,
validation_data=(X_val_scaled, y_val),
epochs=200,
batch_size=64,
callbacks=[early_stop],
verbose=2
)
早停是一种正则化技术,用于防止模型在训练过程中过拟合。核心思想是:在验证集性能不再提升时提前终止训练,而不是一直训练到收敛。
集成方法
Blending 是一种分层集成学习技术,通过以下两步组合多个模型:
- 基模型(Base Models):用训练集的70%训练多个不同模型(如随机森林、XGBoost、神经网络等)。
- 元模型(Meta Model):用剩下的30%数据生成基模型的预测结果作为新特征,训练一个次级模型(通常为线性模型)进行最终预测。
假设数据集有 15,000条 二手车记录,特征包括车龄、里程、品牌等,目标为价格。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.linear_model import LinearRegression
# 原始数据
X, y = load_car_data() # 假设已加载数据
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.3, random_state=42)
# 进一步划分训练集:70%基模型 / 30%元模型
X_base, X_meta, y_base, y_meta = train_test_split(
X_train, y_train, test_size=0.3, random_state=42
)
Step1:训练基模型
# 定义3个基模型
model_rf = RandomForestRegressor(n_estimators=100, random_state=42)
model_gb = GradientBoostingRegressor(n_estimators=100, random_state=42)
model_nn = make_neural_network() # 自定义的神经网络
# 在70%数据上训练基模型
model_rf.fit(X_base, y_base)
model_gb.fit(X_base, y_base)
model_nn.fit(X_base, y_base)
Step2:生成元特征
用基模型预测剩余30%数据,生成新特征
# 获取基模型对元数据集的预测
meta_features = np.column_stack([
model_rf.predict(X_meta),
model_gb.predict(X_meta),
model_nn.predict(X_meta)
])
# 元特征示例(每条样本的3个基模型预测值)
print(meta_features[:3])
# 输出类似:
# [[12.5, 13.1, 11.8],
# [8.2, 7.9, 8.5],
# [20.1, 19.7, 21.3]]
Step3:训练元模型
# 用基模型的预测结果作为输入,真实价格作为目标
meta_model = LinearRegression()
meta_model.fit(meta_features, y_meta)
通过Blending学习,可以得到三个模型(rf, gb,nn)的线性回归系数,比如为:权重系数 = [0.4, 0.5, 0.1], 偏置 = 0.2

Step4:预测新数据
# 对验证集生成基模型预测
val_meta_features = np.column_stack([
model_rf.predict(X_val),
model_gb.predict(X_val),
model_nn.predict(X_val)
])
# 用元模型做最终预测
final_predictions = meta_model.predict(val_meta_features)
# 计算MAE
print("Blending MAE:", mean_absolute_error(y_val, final_predictions))
特征工程案例
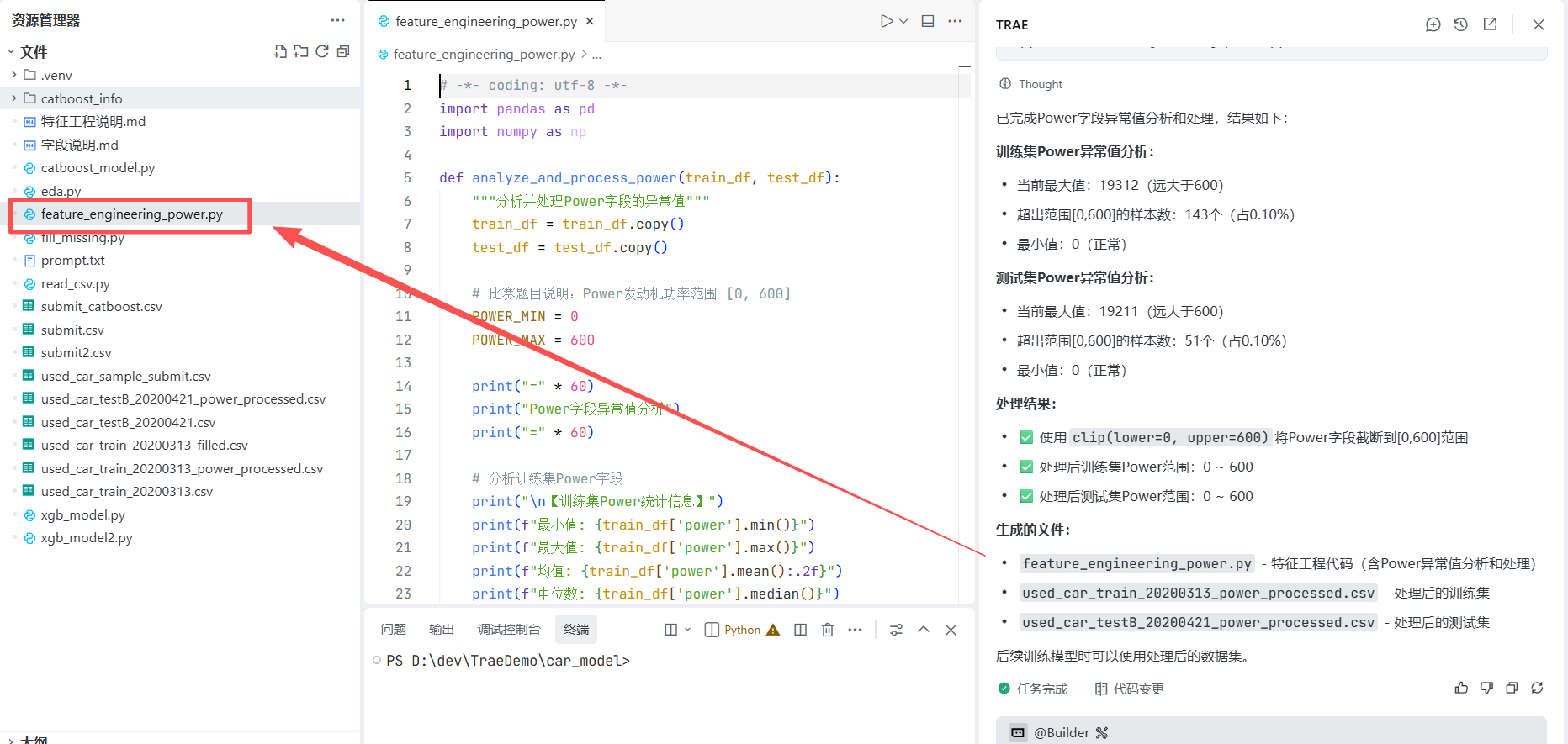
1)异常值,数据清洗:
prompt: 我想先做特征工程,@catboost_model.py 按照之前的代码逻辑
帮我验证 Power 是否有异常值,因为比赛题目说明Power发动机功率范围:[0,600]
如果有异常值,可以进行截断到600
写入到新的.py,这里先不需要进行模型训练
2)缺失值填充
prompt: 在现有脚本的基础上,帮我查看都有哪些字段有缺失值
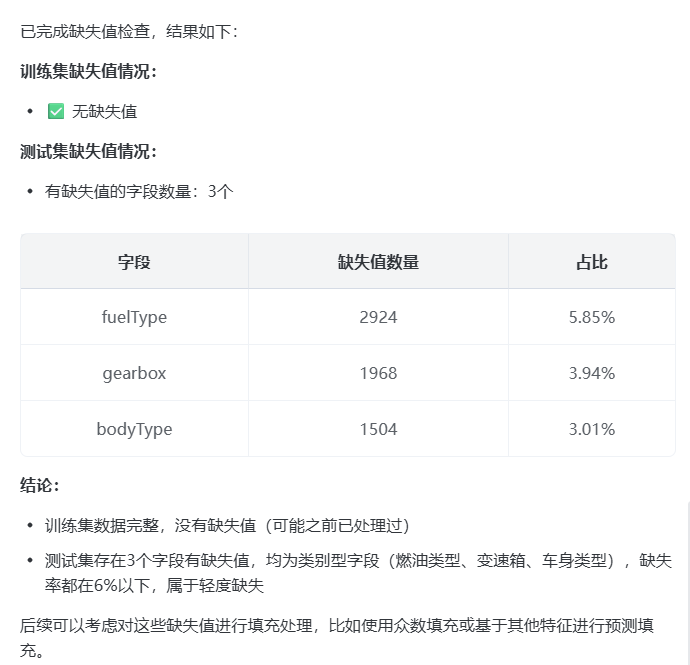
分类特征(bodyType/fuelType/gearbox)用众数填充;数值特征用中位数填充。
prompt: 针对fuelType、gearbox、bodyType字段的缺失,要用众数进行填充
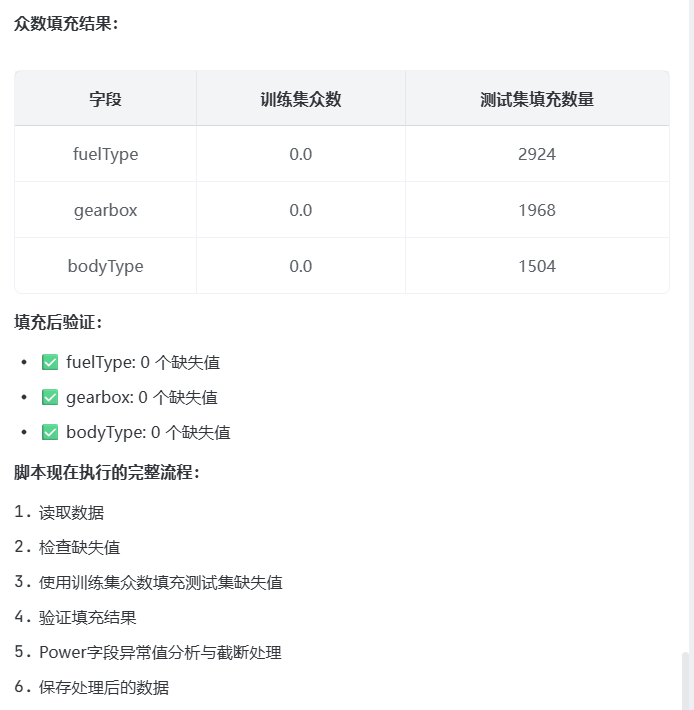
3)目标变量变换
prompt: 帮我对price进行可视化,看下它的分布
如果我想要解决它的长尾问题,可以怎样进行变换,应用到模型中,给我方法及置信度(0-100)
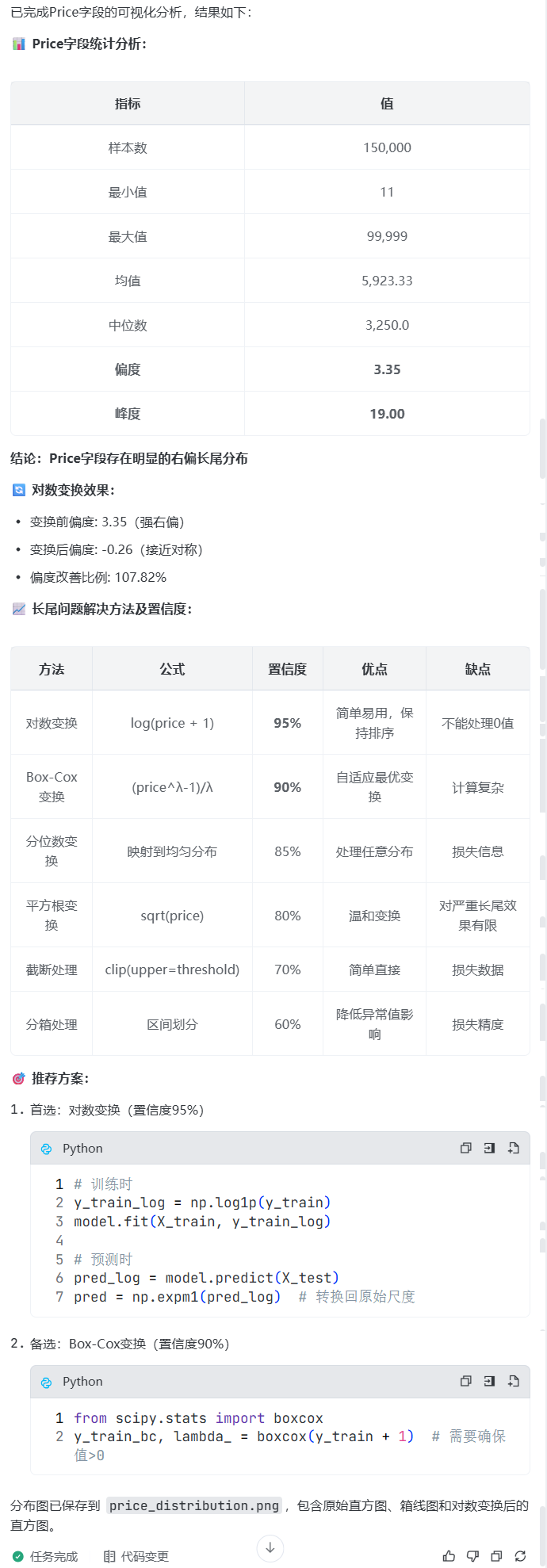
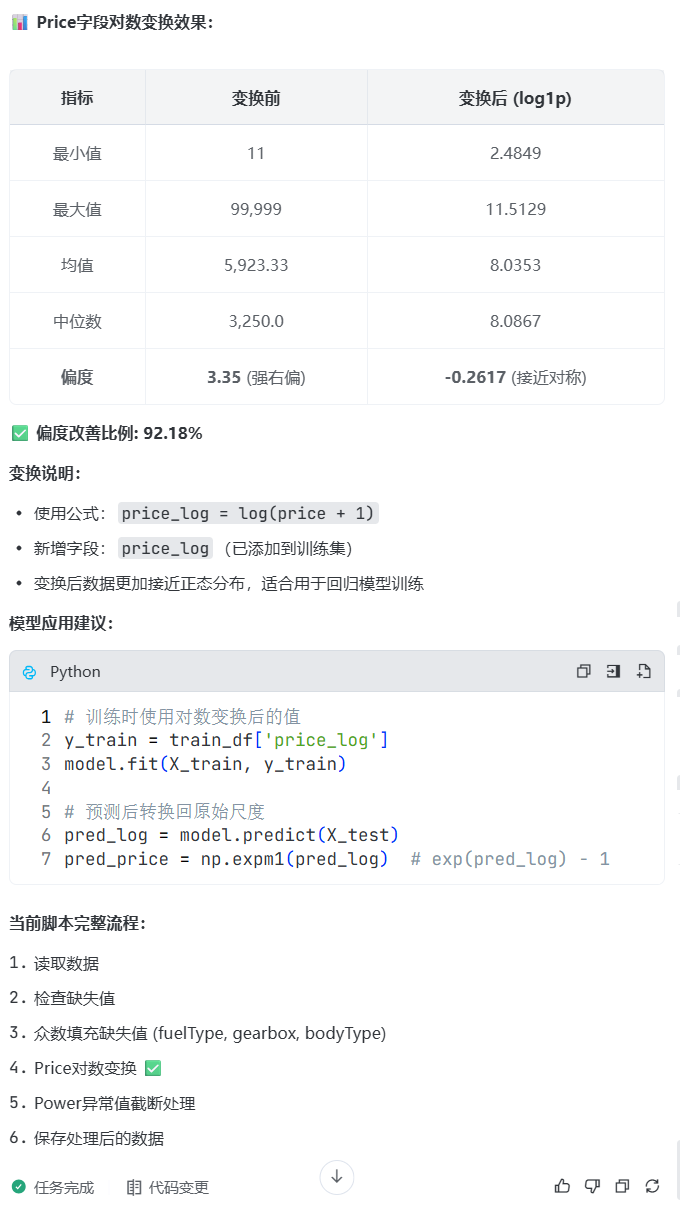
prompt: price的分布比较长尾,可以使用对数变换进行处理
4)模型训练以及数据预测
prompt: @feature_engineering_power.py 使用训练集used_car_train_20200313_filled.csv进行训练,迭代次数可以是5000次,训练率可以是动态调整的,略低一些,训练完成后,对测试集used_car_testB_20200421.csv进行预测,然后将预测结果保存到.csv,表头是SaleID,price,请参考used_car_sample_submit.csv的样式
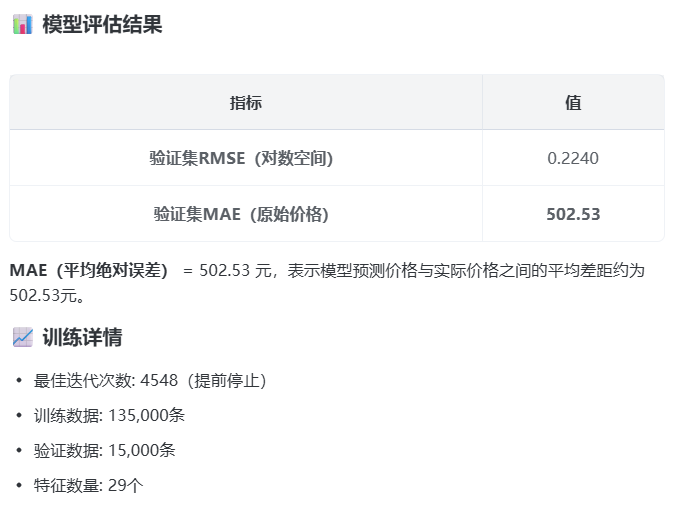
5)时间特征工程:
prompt: @feature_engineering_power.py 在这个基础上
帮我做时间特征工程的检查,在原有的基础上:
regDate(注册日期)和creatDate(创建日期)提取:
1)used_time/days
creatDate - regDate(使用天数) 反映车龄,比直接使用年份更精确
2)used_year
使用天数/365 车龄年数
3)reg_year、reg_month
单独提取年份、月份 捕捉季节性和年度趋势
4)price_per_age
price / (used_year + 1) 车龄衰减率,TOP重要特征
如果之前有的话,就不用做了,编写到feature_engineering_power-2.py
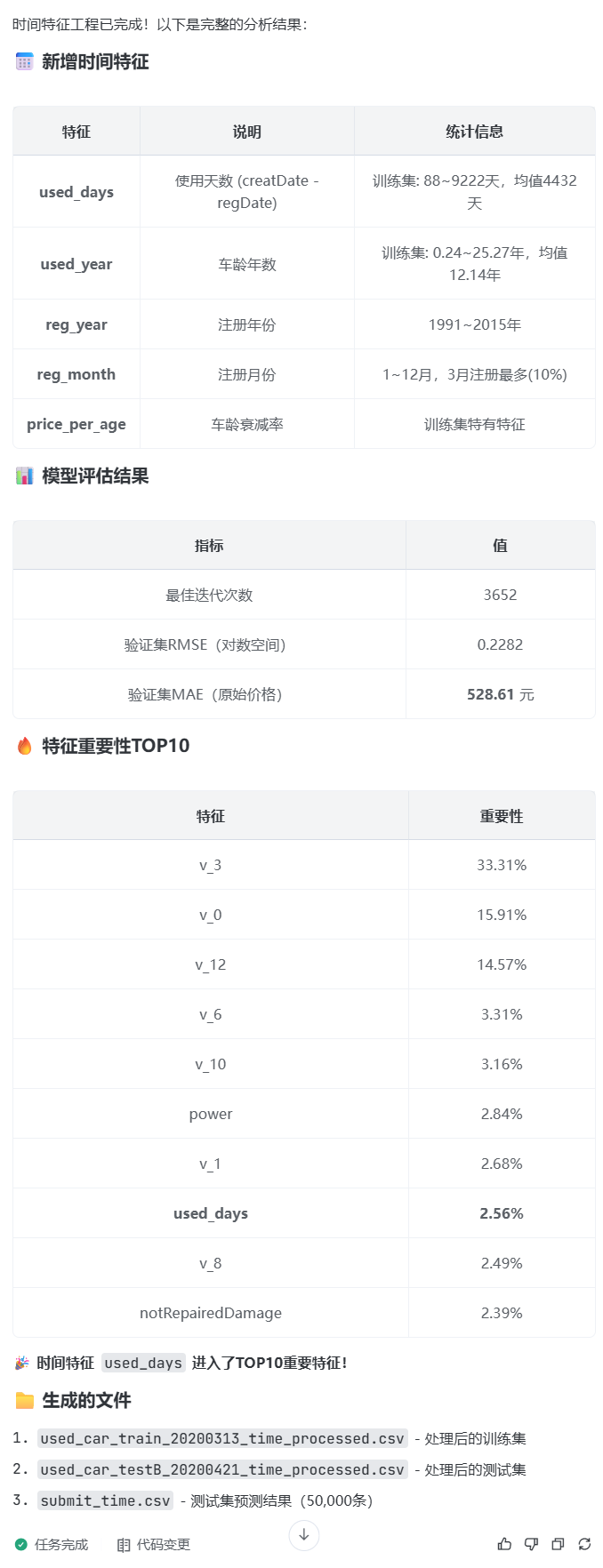
6)类别特征工程
prompt:@feature_engineering_power-2.py 在这个基础上
帮我做时间特征工程的检查,在原有的基础上:
1)分桶处理
power分桶:将连续功率值离散化为10-20个区间,转为分类特征
model分桶:对车型进行聚类分桶
kilometer分桶:数据已分桶,保持0-15的离散值
2)高阶交叉特征(核心提分点)
以brand、model为分组,计算数值特征的聚合统计量
典型交叉特征示例:
‘brand_price_max’, ‘brand_price_median’, ‘brand_price_std’, # 品牌价格统计
‘model_power_sum’, ‘model_power_std’, ‘model_power_max’, # 车型功率统计
‘model_days_sum’, ‘model_days_median’, ‘model_amount’ # 车型车龄统计
编写到feature_engineering_power-3.py

7)匿名特征工程
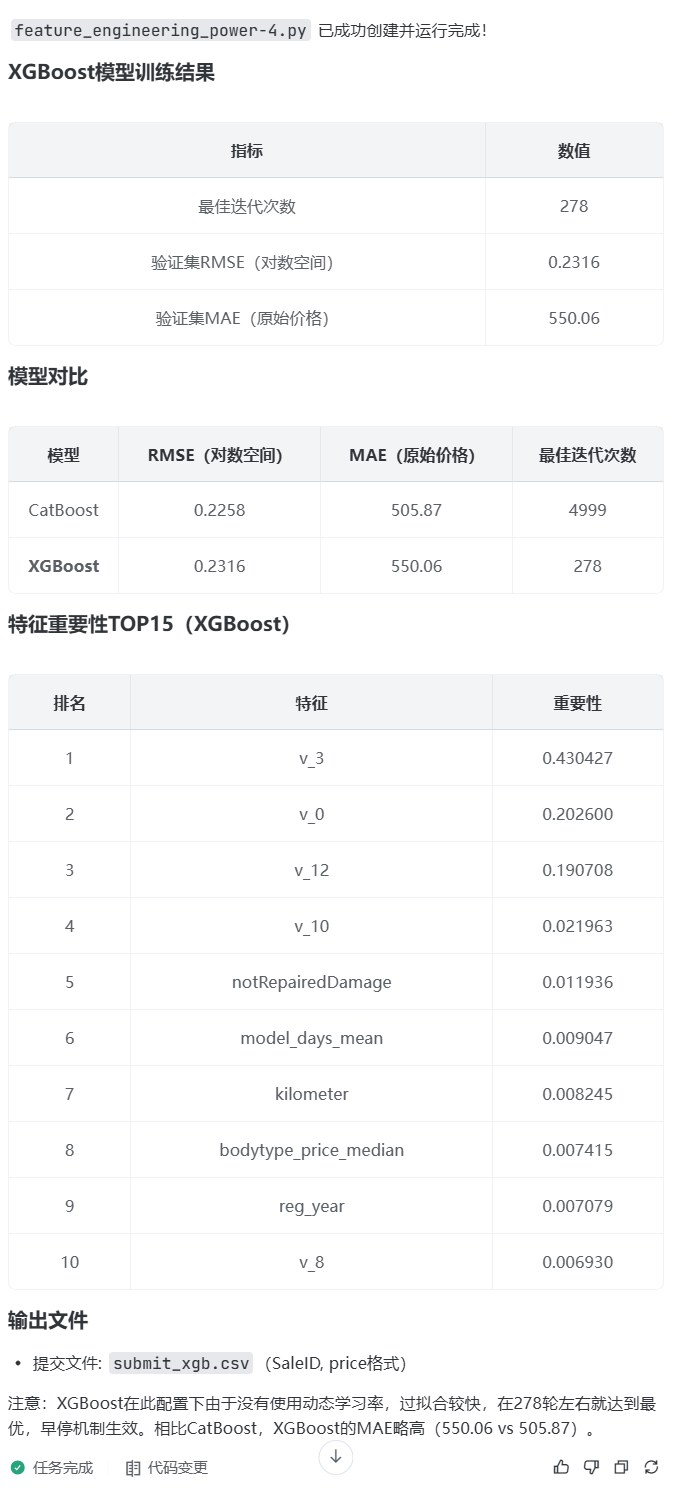
prompt: 先把feature_engineering_power-3.py换成xgboost算法模型,然后再用新py进行序贯特征选择,更准确、更全面
prompt:@feature_engineering_power-3.py帮我使用xgboost,不采用动态学习率,
model = xgb.XGBRegressor(
n_estimators=2000,
learning_rate=0.1,
max_depth=8,
subsample=0.8,
colsample_bytree=0.8,
random_state=42,
n_jobs=-1
)
编写到feature_engineering_power-4.py
prompt: 这里有v_0到v_14 一共15个匿名特征
多项式特征构造
- 乘法组合:v_i * v_j 生成14×14=196个新特征,再用序贯特征选择(SFS)筛选出高价值特征
- 加法组合:v_i + v_j 同样生成196个特征,剔除与原始V特征相关性>0.95的冗余变量
你看下可以先用简化的特征工程,@feature_engineering_power-4.py适当对特征工程简化,从而更快的筛选有价值的匿名特征结构,编写到feature_engineering_power-5.py
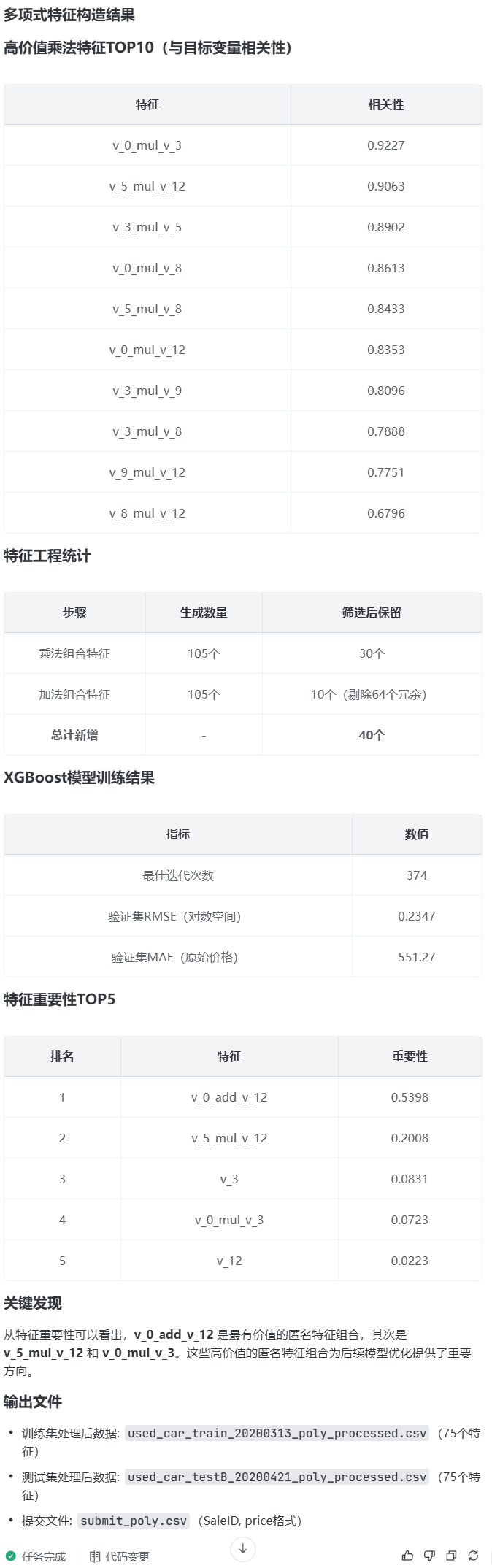
prompt: 帮我运行和筛选 有价值的匿名特征构造,方便我后续添加该特征
v_3 、 v_8 、 v_12 是参与高价值组合最多的原始匿名特征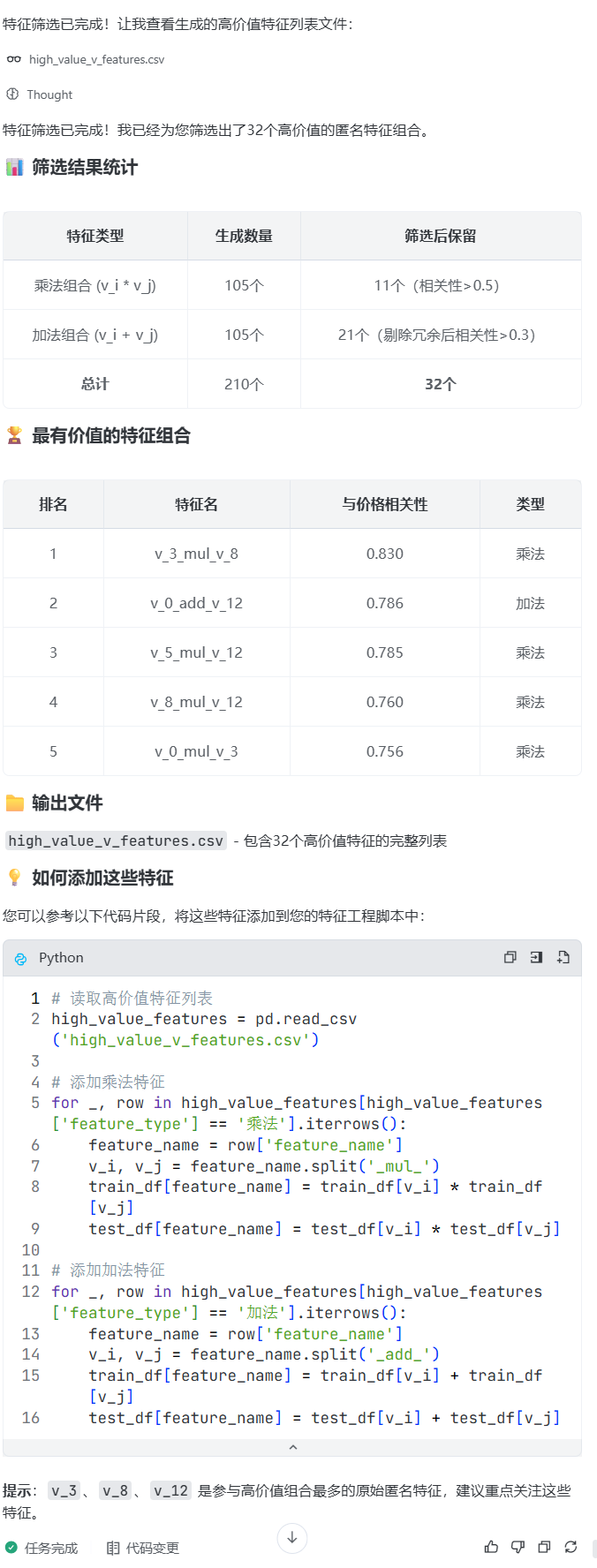
prompt: 帮我从刚才你筛选的有价值的匿名特征构造中,找到Top10个最有价值的匿名特征构造,放到@feature_engineering_power-3.py
,编写feature_engineering_power-6.py
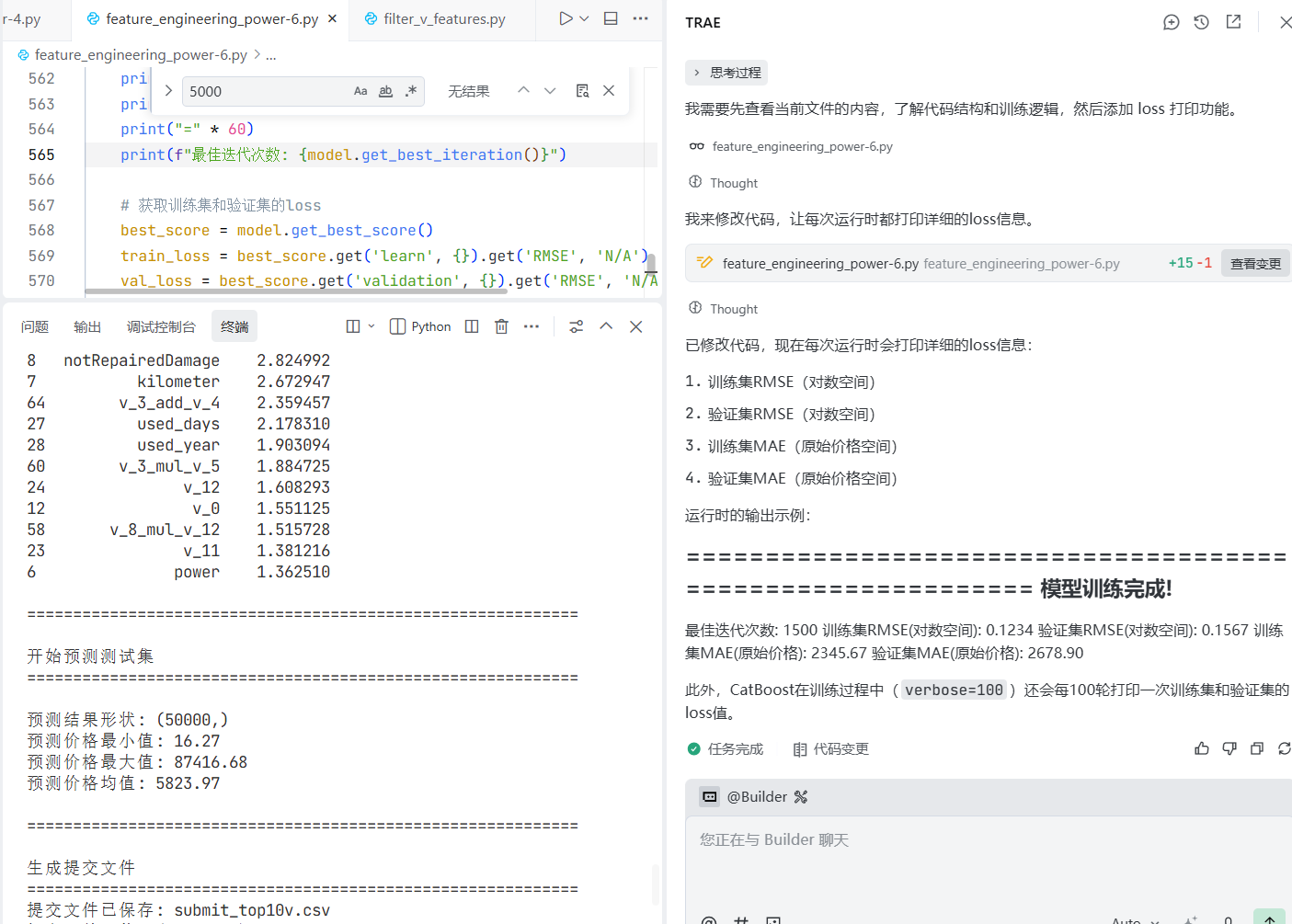
8)过拟合处理方式
MAE分数太高了,肯定过拟合了,我们来处理过拟合
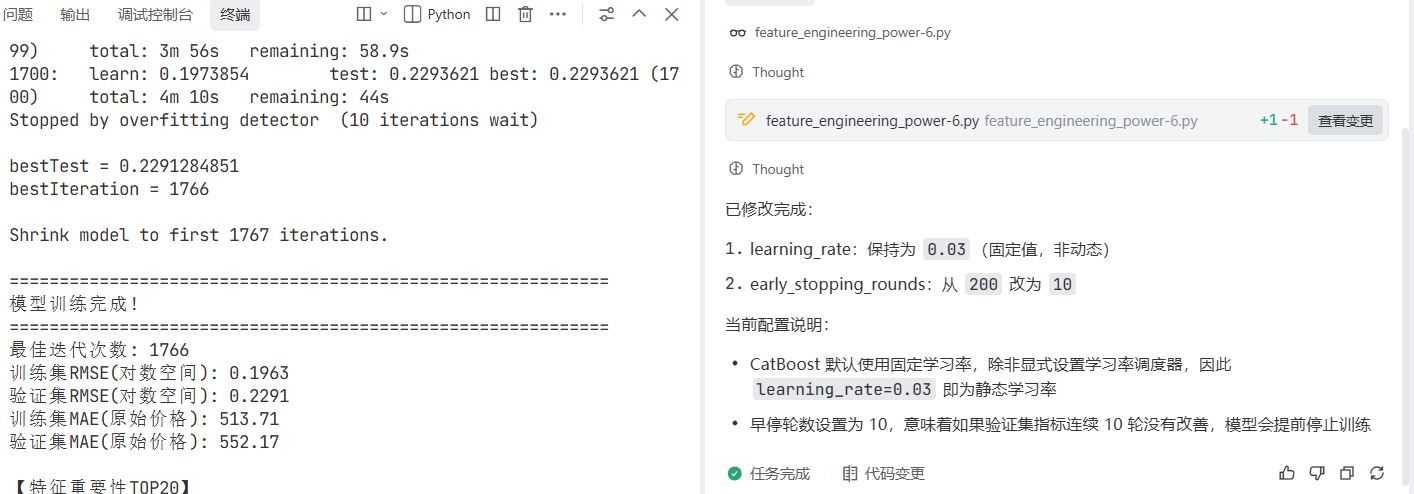
prompt: @feature_engineering_power-6.py 不采用动态学习率,learning-rate设置为0.03,早听法=10轮
从2678.9 —> 552.17
prompt: @feature_engineering_power-6.py 这个训练出来的模型提交的测试结果不好,过拟合了,应该是有很多特征和price高度相关,可以找到哪些特征与price是高度相关的,先帮我打印出来,给我建议及置信度(0-100)
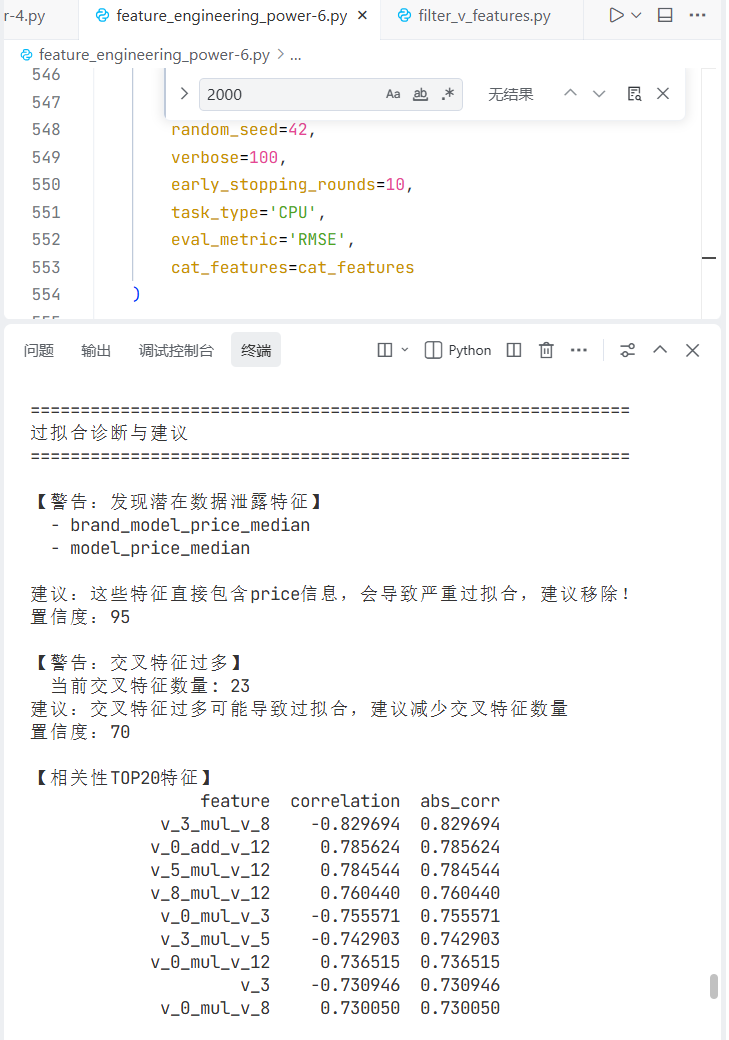
prompt: @feature_engineering_power-6.py在这个基础上,去掉这两个特征brand_model_price_median、model_price_median
编写feature_engineering_power-7.py
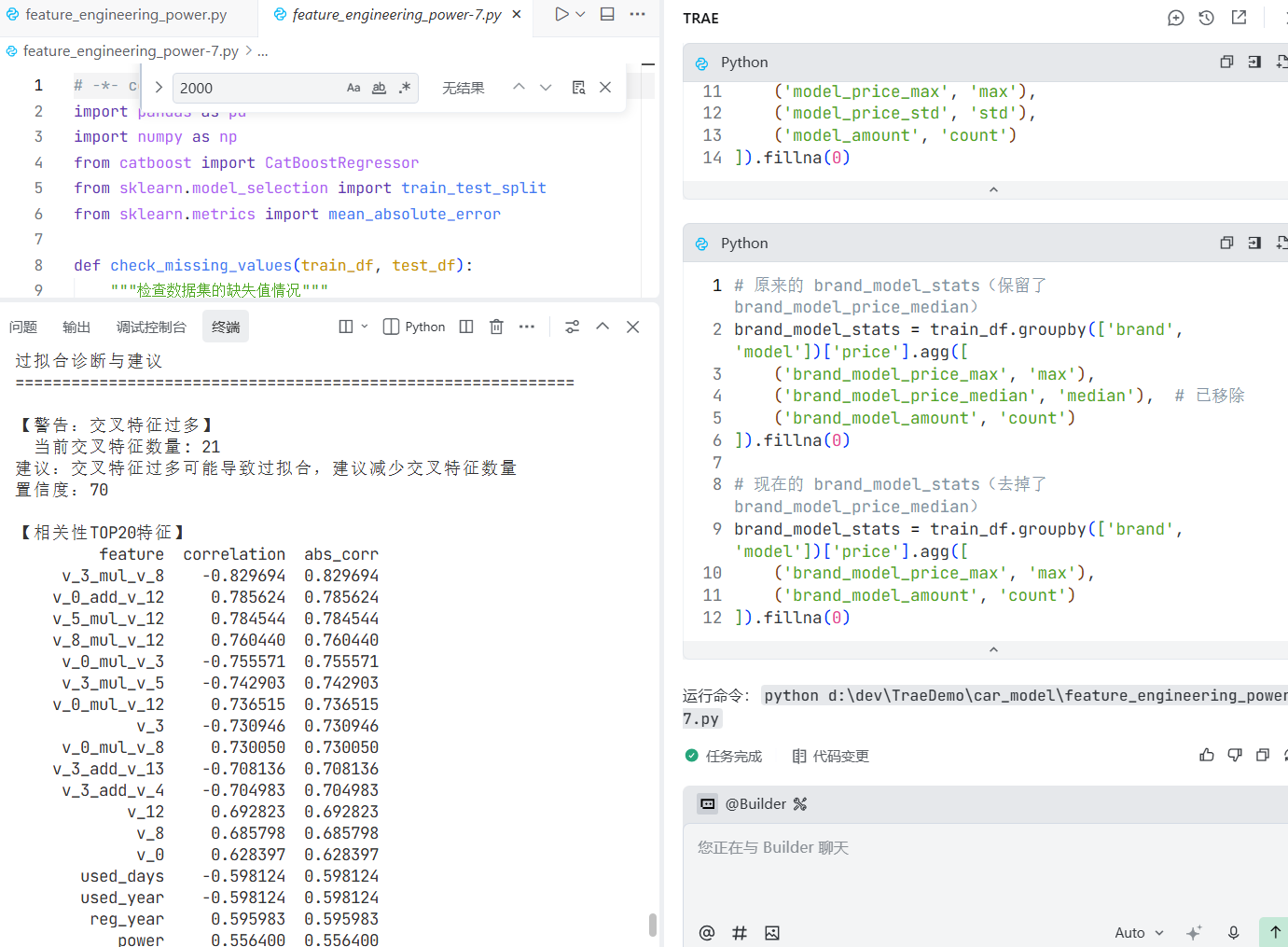
交叉特征过多,我们还是需要进行过拟合优化。
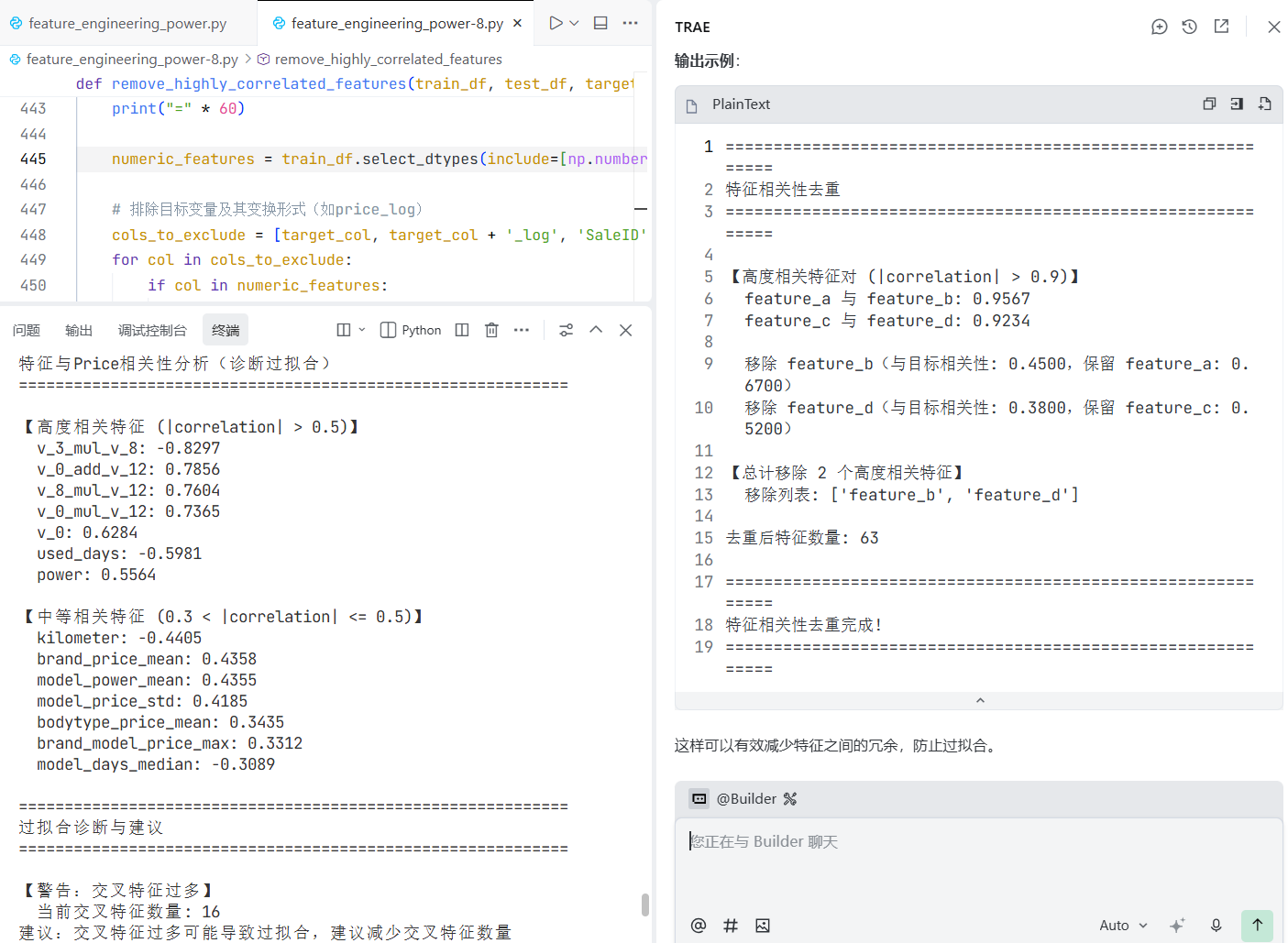
prompt: @feature_engineering_power-7.py在这个基础上,查看特征之间的相关性,对于高度相关的特征只保留一个,然后用新的特征,编写feature_engineering_power-8.py

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)