数据集|草莓成熟度目标检测数据集-3类530张图
·
数据集|草莓成熟度目标检测数据集-3类530张图
一、数据集概述
在草莓自动化采摘与生长监测中,成熟度视觉识别面临以下典型难题:
- 红色果实与背景区分困难:草莓成熟时呈红色,而其叶片、未熟果常为绿色或浅黄,但在自然光照下,红色果实与深绿色背景的边界并不总是清晰,尤其当果实处于阴影或被叶片部分遮挡时,传统颜色阈值方法极易失效。
- 成熟度过渡模糊:草莓从“半熟”(semi-ripe)到“完熟”(fully-ripe)的颜色变化是一个连续过程,不同品种、不同光照下同一成熟度的外观差异甚至可能大于不同成熟度之间的差异,导致人工标注一致性差。
- 小目标与密集场景:草莓常成簇生长,果实之间相互贴合,且部分果实体积较小,通用目标检测模型容易出现漏检或边界框粘连。
- 公开数据集规模小且类别粗:现有草莓数据集多采用“成熟/未成熟”二分类,或仅有数百张图片。三级别(未熟-半熟-完熟)的细粒度数据集极其匮乏,难以支撑实际农业中“最佳采摘窗口”的精准判断。
本数据集共包含 530 张 高分辨率草莓田间图像,专门针对上述痛点设计,能够有效解决以下问题:
- 三级成熟度精细化检测:提供明确的 unripe(未熟)、semi-ripe(半熟)、fully-ripe(完熟) 三类标注,可直接用于训练目标检测模型(如YOLO26、RT-DETR、Faster R-CNN),实现从“能否采摘”到“何时采摘”的定量判断。
- 复杂场景下的鲁棒性学习:图像中涵盖了叶片遮挡、果实重叠、不同角度场景,有助于提升模型在实际机器人部署环境中的抗干扰能力。
- 半熟状态的精确建模:半熟阶段是商业采摘中最具决策价值的节点——过早采摘糖分不足,过晚采摘不耐储运。
- 小样本迁移学习基线:530张图片规模适中,既可用于从头训练轻量级检测器,也可作为大模型微调(fine-tune)的高质量领域数据集,特别适合资源有限的高校实验室或农业创业团队快速启动。
二、数据标注图片实例
该数据集通过精心设计的采集和标注流程,方便为研究学习使用。
- 图像分辨率:640x640 像素
- 标注格式:Labelme JSON格式,包含对象类别和精确标注边界。
- 类别标签体系(共6类):
| 熟度 | 英文标签 | 标注ID | 说明 |
|---|---|---|---|
| 未熟 | unripe | 0 | 果实整体呈白色、浅绿色或青色,表面硬实,种子多为绿色,无明显红色区域 |
| 半熟 | semi-ripe | 1 | 果面出现粉红或浅红色区域(通常覆盖30%~70%表面),局部仍带白/绿色,质地开始变软 |
| 完熟 | fully-ripe | 2 | 果实整体呈深红色或鲜红色,表面有光泽,种子呈金黄色或红色,香气明显,适合立即采摘 |
示例如下:

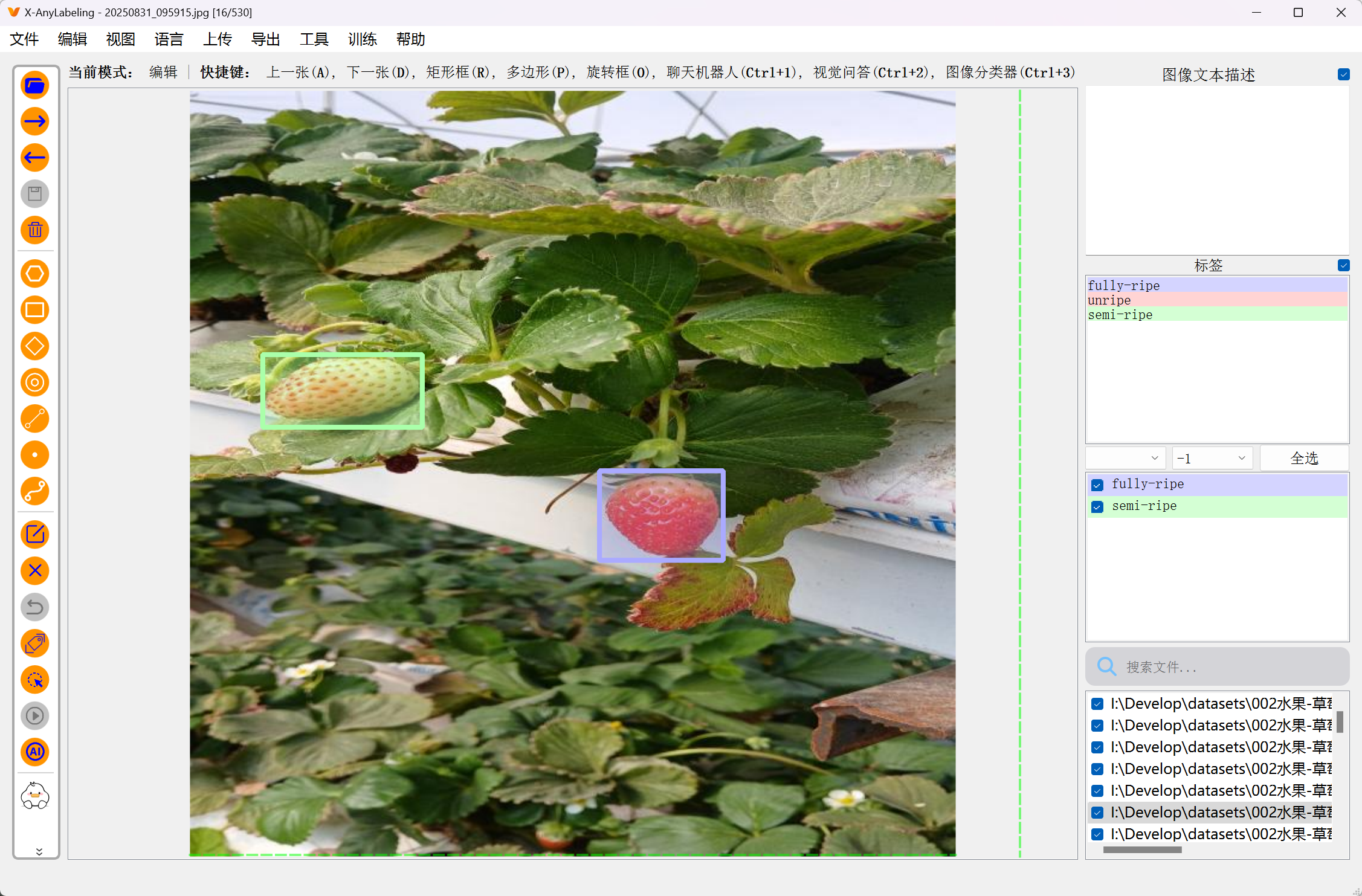
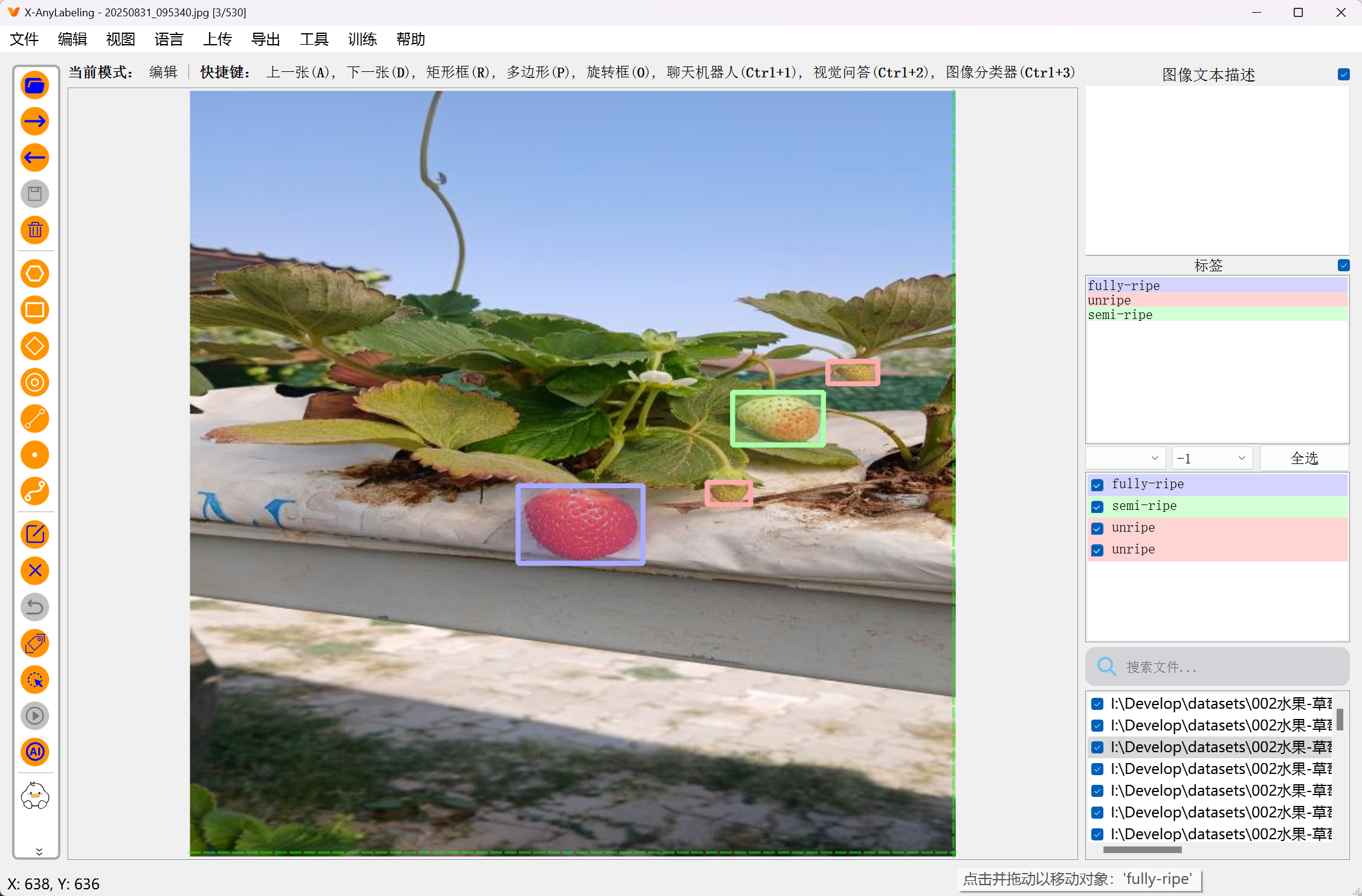
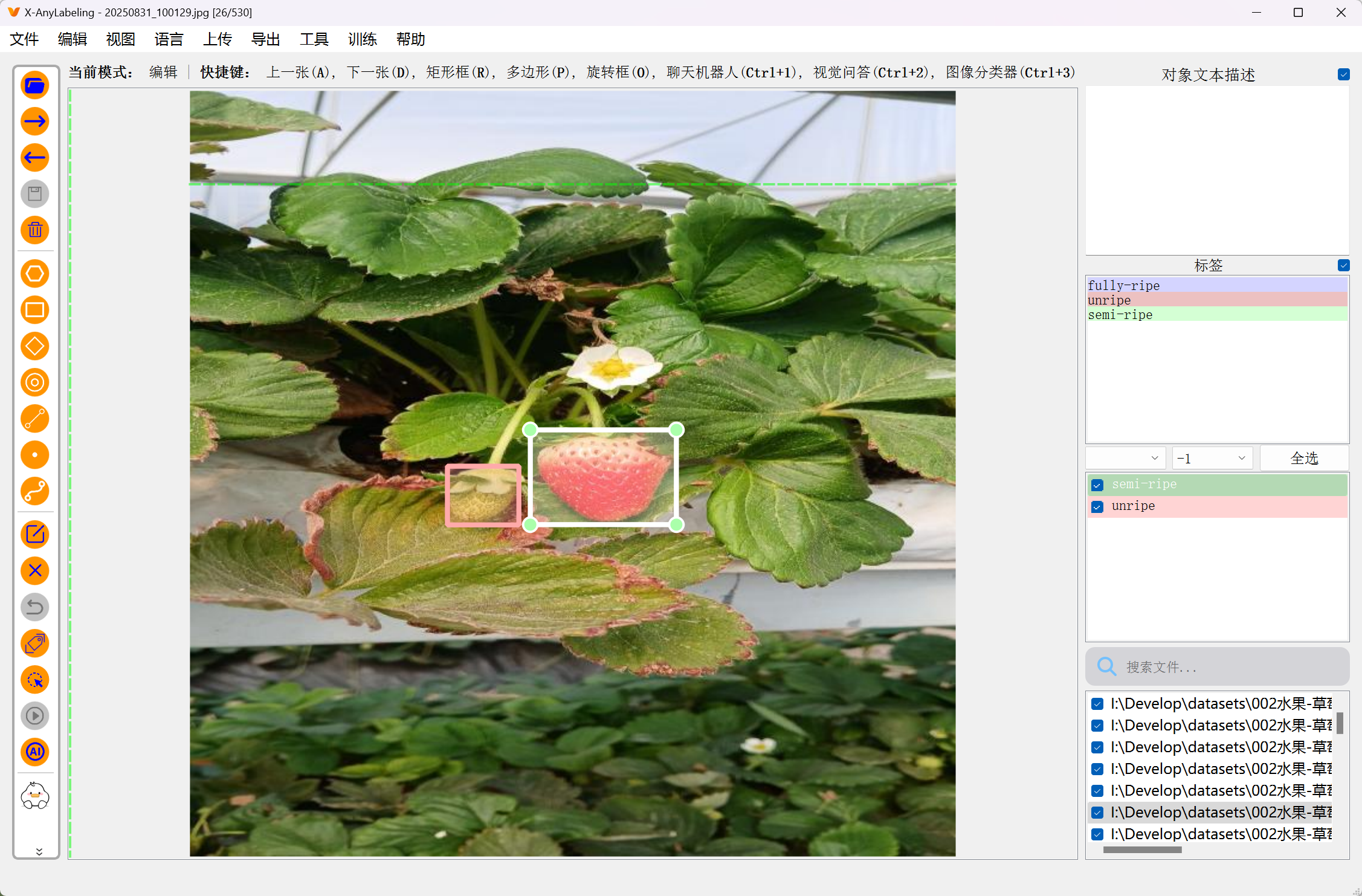
三、标注工具
工具:X-AnyLabeling-CPU.exe
下载地址:https://github.com/CVHub520/X-AnyLabeling/releases
四、数据下载地址
如果有用,请点个三连呗 点赞、关注、收藏。
你的鼓励是我最大的动力

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)