LangChain RAG技术解析:构建高效知识库(加载与拆分)
写在最前面:关于本文所使用的数据集以及代码可以参考这个链接获取
https://github.com/visionlmlm/LangChain_test_agent_rag
经过前面的I/O、Chain、Memory、Tool、Agent等的了解,现在该进入最后一个环节,也就是Retrieval的学习。他常常被用于构建一个“企业/私人的知识库”,提升大模型的整体能力。
1、Retrieval模块的设计意义
1.1 大模型的两大难题之一
在一些专业领域中,LLM无法获取所有的专业知识的细节,因此在用户的使用中就会无法给出准确的答案,甚至会杜撰一些虚假的信息,这种现象就是LLM的“幻觉”问题,这也是大模型存在的两个摆脱不掉的难题,当前还没有百分之百解决的方案。
但是还是有方法能够缓解这种困境的,那就是RAG:
首先,为大模型提供一定的上下文信息,让其输出变得更加稳定;其次,利用RAG技术将检索出来的文档和提示词再输送给大模型,生成更加可靠的答案。
1.2 RAG的解决方案
当应用需求集中在利用大模型去回答特定私有领域的知识,并且知识库足够大,那么除了微调大模型之外,RAG就是非常有效的缓解大模型推理“幻觉”问题的解决方案。
当前已经出现了非常多的产品使用到了RAG,包括客服系统、基于大模型的数据分析。
1.3 RAG的优缺点
优点:
- 相较提示词工程,RAG有更丰富的上下文和数据样本,可以不需要用户提供过多的背景描述,就能够生成比较符合用户预期的答案;
- 相比于模型微调,RAG可以提升问答内容的时效性(一定程度上缓解“知识冻结”问题)以及可靠性;
- 在一定程度上保护了业务数据的隐私性。
缺点:
- 由于每次问答都会涉及外部系统数据检索,因此RAG的响应时延相对较高;
- 引用的外部知识数据会消耗大量的模型Token资源。
2、文档加载器 Document Loaders
2.0 总述
(1)不同的文档使用不同的文档加载器
txt文档:TextLoader
pdf文档:PyPDFLoader
csv文档:CSVLoader
json文档:JSONLoader
html文档:UnstructuredHTMLLoader
md文档:UnstructuredMarkdownLoader
文件目录:DirectoryLoader
(2)当创建好XXLoader的实例之后,都要调用load(),此时会在内存中返回一个list[Document]
2.1 加载Txt文档
from langchain_community.document_loaders import TextLoader, PythonLoader
# 指明txt文档路径
file_path = "./asset/load/01-langchain-utf-8.txt"
# 创建一个TextLoader的实例
text_loader = TextLoader(
file_path = file_path,
encoding = "utf-8" # 解码集要与存储时的编码集相同
)
# 调用load(),返回一个list[Document]
docs = text_loader.load()在Document对象中有两个重要属性:
①page_content:真实的文档内容;②metadata:文档内容的元数据
print(docs[0].metadata) # 显示Document对象的元数据
print(docs[0].page_content) # 显示文档中的内容信息
2.2 加载Pdf文档
from langchain_community.document_loaders import PyPDFLoader
pdf_loader = PyPDFLoader(
file_path = "./asset/load/02-load.pdf"
)
docs = pdf_loader.load()
print(docs)
如果将file_path换成在线网址就能够加载网络文件:
from langchain_community.document_loaders import PyPDFLoader
pdf_loader = PyPDFLoader(
file_path = "https://arxiv.org/pdf/2302.03803"
)
docs = pdf_loader.load()
print(docs)
print(len(docs))2.3 加载CSV文档
from langchain_community.document_loaders import CSVLoader
csv_loader = CSVLoader(
file_path = "./asset/load/03-load.csv"
)
docs = csv_loader.load()
print(docs)
print(len(docs))使用source_column参数指定文件加载的列,并且保存在source变量中:
from langchain_community.document_loaders import CSVLoader
csv_loader = CSVLoader(
file_path = "./asset/load/03-load.csv",
source_column="author"
)
docs = csv_loader.load()
for doc in docs:
print(doc)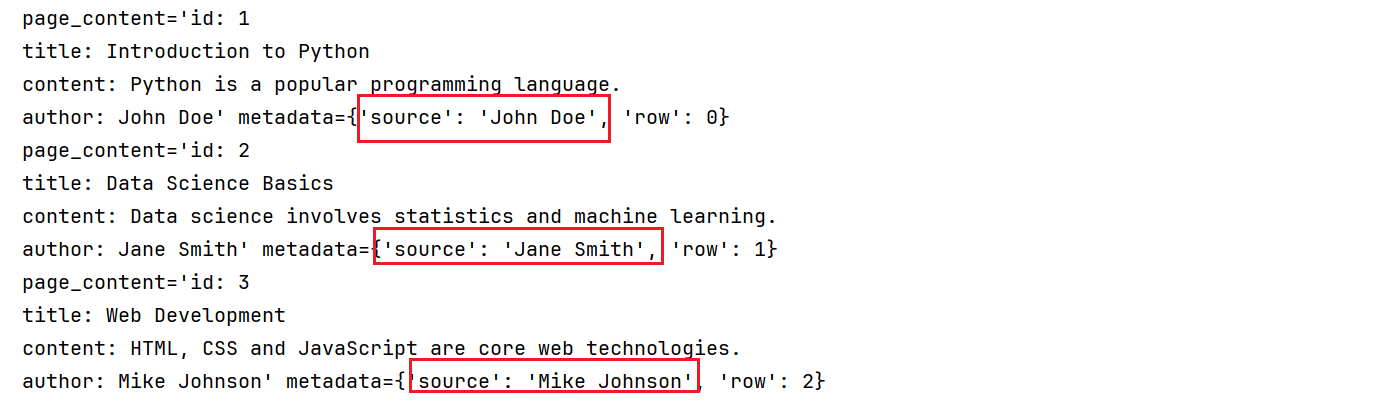
2.4 加载JSON文档
示例1:加载所有数据
from langchain_community.document_loaders import JSONLoader
json_loader = JSONLoader(
file_path = "./asset/load/04-load.json",
jq_schema = "." ,#表示加载所有的字段
text_content = False # 将加载的json对象转换为json字符串
)
docs = json_loader.load()
print(docs)
示例2:加载content字段内容
from langchain_community.document_loaders import JSONLoader
json_loader = JSONLoader(
file_path = "./asset/load/04-load.json",
jq_schema = ".messages[].content" ,
# text_content = False # content字段本身就是字符串格式,无需转换
)
docs = json_loader.load()
for doc in docs:
print(doc.page_content)
示例3:提取04-response.json文件中嵌套在 data.items[].content 的文本
from langchain_community.document_loaders import JSONLoader
# 方式1
# json_loader = JSONLoader(
# file_path = "./asset/load/04-response.json",
# jq_schema = ".data.items[].content" ,
# )
# 方式2
json_loader = JSONLoader(
file_path = "./asset/load/04-response.json",
jq_schema = ".data.items[]" ,
content_key=".content",
is_content_key_jq_parsable=True #使用jq解析content_key
)
docs = json_loader.load()
for doc in docs:
print(doc.page_content)
示例4:提取04-response.json文件中嵌套在 data.items[] 里的 title、content 和 其文本
# 1.导入相关依赖
from langchain_community.document_loaders import JSONLoader
from pprint import pprint
# 2.定义json文件的路径
file_path = 'asset/load/04-response.json'
# 3.定义JSONLoader对象
loader = JSONLoader(
file_path=file_path,
# jq_schema=".data.items[] | {id, author, text: (.title + '\n' + .content)}",
jq_schema=".data.items[]",
content_key='.title + "\\n\\n" + .content',
is_content_key_jq_parsable=True # 用jq解析content_key
)
# 4.加载
data = loader.load()
for doc in data:
print(doc.page_content)
2.5 加载HTML文档
from langchain_community.document_loaders import UnstructuredHTMLLoader
html_loader = UnstructuredHTMLLoader(
file_path = "./asset/load/05-load.html",
mode = "elements",
strategy="fast" # 加载策略
)
docs = html_loader.load()
print(len(docs))
for doc in docs:
print(doc)
2.6 加载Markdown文档
from langchain_community.document_loaders import UnstructuredMarkdownLoader
markdown_loader = UnstructuredMarkdownLoader(
file_path = "./asset/load/06-load.md",
strategy="fast"
)
docs = markdown_loader.load()
print(len(docs))
for doc in docs:
print(doc)
2.7 加载File Directory文档
批量加载一个文件夹内的所有文件:
from langchain_community.document_loaders import DirectoryLoader,PythonLoader
fd_load = DirectoryLoader(
path="./asset/load",
glob = "*.py",
use_multithreading=True, # 是否使用多线程
show_progress=True,
loader_cls=PythonLoader
)
docs = fd_load.load()
print(len(docs))
for doc in docs:
pprint(doc)
3、文档拆分器 Text Splitters
3.0 为什么要拆分文档
对于传入的文档,如果作为一个整体使用,会存在以下问题:
- 如果用户的问题Query的答案仅出现在某一个Document对象中,那么将检索到的所有Document对象直接放入prompt中并不是最优的选择,因为这一定会包含很多无关的信息,无关的信息越多,对大模型后续的推理影响越大;
- 任何一款大模型都存在最大输入的Token限制,如果一个Document很大,例如是几百兆的PDF文件,大模型肯定无法容纳如此多的信息。
基于上述信息,我们必须对完整的Document对象进行分块处理。无论是在存储还是检索的时候都将以块(chunks)为基本单位,这样就会有效的避免内容不相关问题和超出最大输入限制问题。
3.1 Chunking拆分的策略
- 根据句子切分:按照自然句子边界进行切分,以保持语义的完整性;
- 按照固定字符数切分:根据特定的字符数量来划分文本,但可能会在不适合的位置切断句子;
- 按固定字符数来切分,结合重叠窗口:在方法2的基础上通过重叠窗口技术避免切分关键内容,保证信息的连贯性;
- 递归字符切分方法:通过递归字符方法动态确定切分点,可以根据文档的复杂性与内容的密度来调整块的大小;
- 根据语义内容切分:属于(高级策略)依据文本的语义内容来划分块,旨在保持相关信息的集中和完整,适合于需要高度语义保持的应用场景。
以上的方法没有说是有绝对好的一种,各有优势和局限。
3.2 TextSplitter使用
内部定义的一些常用方法:
情况一:按照字符串进行切分
- split_text():传入参数是字符串类型,返回值的类型是List[str];
- create_documents():传入参数类型是List[str],返回值类型是List[Document];
情况二:按照Document对象进行切分
- split_documents():传入参数类型是List[Document],返回值类型是List[Document]。
3.3 具体实现
3.3.1 具体的拆分器之 CharacterTextSplitter:Split by character
示例1:体会参数chunk_size以及chunk_overlap
# 1.导入相关依赖
from langchain_text_splitters import CharacterTextSplitter
# 2.示例文本
text = """
LangChain 是一个用于开发由语言模型驱动的应用程序的框架的。它提供了一套工具和抽象,使开发者能够更容易地构建复杂的应用程序。
"""
# 3.定义字符分割器
splitter = CharacterTextSplitter(
chunk_size=50, # 每块大小
chunk_overlap=5,# 块与块之间的重复字符数
#length_function=len,
separator="" # 设置为空字符串时,表示禁用分隔符优先
)
# 4.分割文本
texts = splitter.split_text(text)
# 5.打印结果
for i, chunk in enumerate(texts):
print(f"块 {i+1}:长度:{len(chunk)}")
print(chunk)
print("-"* 50)
示例2:体会参数separator
# 1.导入相关依赖
from langchain_text_splitters import CharacterTextSplitter
# 2.定义要分割的文本
text = "这是一个示例文本啊。我们将使用CharacterTextSplitter将其分割成小块。分割基于字符数。"
# text = """
# LangChain 是一个用于开发由语言模型。驱动的应用程序的框架的。它提供了一套工具和抽象。使开发者能够更容易地构建复杂的应用程序。
# """
# 3.定义分割器实例
text_splitter = CharacterTextSplitter(
chunk_size=30, # 每个块的最大字符数
chunk_overlap=5, # 块之间的重叠字符数
separator="。", # 按句号分割 分隔符优先
)
# 4.开始分割
chunks = text_splitter.split_text(text)
# 5.打印效果
for i,chunk in enumerate(chunks):
print(f"块 {i + 1}:长度:{len(chunk)}")
print(chunk)
print("-"*50)
3.3.2 具体的拆分器之RecursiveCharacterTextSplitter:最常用
这种方式在遇到特定字符时进行分割,默认情况下尝试切割的字符包括“\n\n”,“\n”,“ ”,“”
根据第一个字符进行切块,但如果任何切块太大,则会继续移动到下一个字符继续切块。
示例1:使用split_text()方法
# 1.导入相关依赖
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 2.定义RecursiveCharacterTextSplitter分割器对象
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=10,
chunk_overlap=0,
add_start_index=True,
)
# 3.定义拆分的内容
text="LangChain框架特性\n\n多模型集成(GPT/Claude)\n记忆管理功能\n链式调用设计。文档分析场景示例:需要处理PDF/Word等格式。"
# 4.拆分器分割
paragraphs = text_splitter.split_text(text)
for para in paragraphs:
print(para)
print('-------')
示例2:使用create_documents()方法演示,传入字符串列表,返回Document对象列表
# 1.导入相关依赖
# 2.定义RecursiveCharacterTextSplitter分割器对象
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=10,
chunk_overlap=0,
add_start_index=True,
)
# 3.定义分割的内容
# text="LangChain框架特性\n\n多模型集成(GPT/Claude)\n记忆管理功能\n链式调用设计。文档分析场景示例:需要处理PDF/Word等格式。"
list=["LangChain框架特性\n\n多模型集成(GPT/Claude)\n记忆管理功能\n链式调用设计。文档分析场景示例:需要处理PDF/Word等格式。"]
# 4.分割器分割
# create_documents():形参是字符串列表,返回值是Document的列表
paragraphs = text_splitter.create_documents(list)
for para in paragraphs:
print(para)
print('-------')
示例3:使用create_documents()方法演示,将本地文件内容加载成字符串,进行拆分
# 1.导入相关依赖
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 2.打开.txt文件
with open(
"asset/load/08-ai.txt",
encoding="utf-8"
) as f:state_of_the_union = f.read() #返回的是字符串
# 3.定义RecursiveCharacterTextSplitter(递归字符分割器)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,#chunk_overlap=0,
length_function=len
)
# 4.分割文本
texts = text_splitter.create_documents([state_of_the_union])
# 5.打印分割文本
for text in texts:
print(f"🔥{text.page_content}")
示例4:使用split_documents()方法演示,利用PDFLoader加载文档,对文档的内容用递归切割器切割
# 1.导入相关依赖
from langchain_community.document_loaders import PyPDFLoader
# 2.定义PyPDFLoader加载器
loader = PyPDFLoader("./asset/load/02-load.pdf")
# 3.加载和切割文档对象
docs = loader.load()
# 返回Document对象构成的list
# print(f"第0页:\n{docs[0]}")
# 4.定义切割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200,#chunk_size=120,
chunk_overlap=0,# chunk_overlap=100,
length_function=len,
add_start_index=True,
)
# 5.对pdf内容进行切割得到文档对象
paragraphs = text_splitter.split_documents(docs)
#paragraphs = text_splitter.create_documents([text])
for para in paragraphs:
print(para.page_content)
print('-------')
3.3.3 具体的拆分器之 TokenTextSplitter/CharacterTextSplitter:Split by tokens
示例1:使用TokenTextSplitter
# 1.导入相关依赖
from langchain_text_splitters import TokenTextSplitter
# 2.初始化 TokenTextSplitter
text_splitter = TokenTextSplitter(
chunk_size=33,#最大 token 数为 32
chunk_overlap=0,#重叠 token 数为 0
encoding_name="cl100k_base",# 使用 OpenAI 的编码器,将文本转换为 token 序列
)
# 3.定义文本
text ="人工智能是一个强大的开发框架。它支持多种语言模型和工具链。人工智能是指通过计算机程序模拟人类智能的一门科学。自20世纪50年代诞生以来,人工智能经历了多次起伏。"
# 4.开始切割
texts = text_splitter.split_text(text)
# 打印分割结果
print(f"原始文本被分割成了 {len(texts)} 个块:")
for i, chunk in enumerate(texts):
print(f"块 {i+1}: 长度:{len(chunk)} 内容:{chunk}")
print("-" * 50)
示例2:使用CharacterTextSplitter
# 1.导入相关依赖
from langchain_text_splitters import CharacterTextSplitter
import tiktoken
# 用于计算Token数量
# 2.定义通过Token切割器
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", # 使用 OpenAI 的编码器
chunk_size=18,
chunk_overlap=0,
separator="。", # 指定中文句号为分隔符
keep_separator=False, # chunk中是否保留分隔符
)
# 3.定义文本
text = "人工智能是一个强大的开发框架。它支持多种语言模型和工具链。今天天气很好,想出去踏青。但是又比较懒不想出去,怎么办"
# 4.开始切割
texts = text_splitter.split_text(text)
print(f"分割后的块数: {len(texts)}")
# 5.初始化tiktoken编码器(用于Token计数)
encoder = tiktoken.get_encoding("cl100k_base") # 确保与CharacterTextSplitter的encoding_name一致
# 6.打印每个块的Token数和内容
for i, chunk in enumerate(texts):
tokens = encoder.encode(chunk) # 现在encoder已定义
print(f"块 {i + 1}: {len(tokens)} Token\n内容: {chunk}\n")
3.3.4 具体拆分器之SemanticChunker:语义分块
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
import os
import dotenv
dotenv.load_dotenv()
# 加载文本
with open("asset/load/09-ai1.txt", encoding="utf-8") as f:
state_of_the_union = f.read()#返回字符串
# 获取嵌入模型
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
embed_model = OpenAIEmbeddings(
model="text-embedding-3-large" )
# 获取切割器
text_splitter = SemanticChunker(
embeddings=embed_model,
breakpoint_threshold_type="percentile",#断点阈值类型:字面值["百分位数", "标准差", "四分位距", "梯度"] 选其一
breakpoint_threshold_amount=65.0 #断点阈值数量 (极低阈值 → 高分割敏感度)
)
# 切分文档
docs = text_splitter.create_documents(texts = [state_of_the_union])
print(len(docs))
for doc in docs:
print(f"🔍 文档 {doc}:")
剩余的部分(嵌入模型、向量数据库、检索器)的内容在下次的博客进行说明。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)