(B站TinyML 教程学习笔记)C11 - Edge Impulse 中的特征选择+C12 - 机器学习全流程管道+C13 - 第一模块复习+C14 - 神经网络入门
TinyML / Edge Impulse 特征提取与神经网络 笔记
00:07 - 什么是特征(Feature)
-
机器学习中最重要的任务之一:
-
找出应该提取数据的哪些特征
-
-
特征来源于原始数据:
-
用于模型训练
-
用于后续推理
-
-
现代深度学习:
-
可以直接输入原始数据
-
自动学习特征
-
-
但嵌入式设备存在问题:
-
MCU算力有限
-
RAM有限
-
无法像服务器那样进行大规模计算
-
00:32 - 特征的定义
-
特征:
-
数据中“可测量的属性”
-
例如:
| 数据 | 特征 |
|---|---|
| 加速度 | X/Y/Z轴数值 |
| 音频 | 频率 |
| 图像 | 像素边缘 |
00:44 - 运动检测例子
-
使用10秒加速度数据
-
判断手机在做什么运动
通过:
-
X轴
-
Y轴
-
Z轴
分析运动方向。
例子:
-
X轴变化明显:
-
表示左右运动
-
01:08 - 简单特征向量
某一时刻:
-
X加速度
-
Y加速度
-
Z加速度
组成:
3维特征向量。
模型输入:
[x, y, z]
因此:
-
模型输入维度 = 3
01:52 - 为什么这种特征很差
问题:
它只有:
“某一瞬间的快照”
缺少:
-
时间变化
-
周期信息
-
动态趋势
因此:
模型无法知道:
-
是挥手
-
是摇晃
-
还是旋转
02:20 - 分类的核心思想
如果不同类别的数据:
-
在空间中能分离
-
能形成不同聚类
那么:
机器学习模型就容易分类。
问题:
不同运动在某些时刻:
-
加速度可能非常接近
-
数据会混在一起
导致:
模型难以区分。
03:13 - 时间窗口(Window)
解决方案:
使用:
更长时间的数据窗口
课程中:
-
窗口长度:
-
2秒
-
-
采样率:
-
62.5Hz
-
03:24 - 输入维度暴增
每轴:
2秒 × 62.5Hz = 125样本
三轴:
125 × 3 = 375维
问题:
-
输入维度太大
-
MCU压力巨大
03:52 - 深度学习自动提取特征
深度神经网络可以:
-
自动学习重要特征
-
自动判断哪些信息有用
例如:
-
CNN处理图像
-
自动学习边缘
-
纹理
-
形状
04:32 - 大模型的问题
随着模型增大:
问题也会增加:
| 问题 | 原因 |
|---|---|
| 运算量大 | 参数增多 |
| RAM占用高 | 输入维度高 |
| 推理慢 | 层数更多 |
| 训练数据需求增加 | 更容易过拟合 |
05:21 - TinyML 的核心思想
服务器:
-
可以暴力计算
MCU:
-
不行
因此:
TinyML核心思想:
人工提取高质量特征
目的:
-
降低模型复杂度
-
提高推理速度
-
降低内存需求
05:53 - 手工特征工程
不直接使用原始数据。
而是:
通过数学方法:
-
组合
-
压缩
-
提炼
得到更有意义的特征。
RMS 特征
06:10 - RMS(均方根)
课程中提到:
对125个采样点:
计算RMS。
作用:
-
描述整体能量
-
类似“平均运动强度”
特点:
-
一个轴只输出一个值
-
三轴最终只有3个特征
优点:
-
输入维度大幅降低
-
仍保留时间信息
06:33 - 去除重力影响
Edge Impulse:
会先:
-
去除均值
-
过滤重力分量
再计算RMS。
这样:
模型更关注:
-
动态运动
而不是:
-
手机静止方向
FFT 与 PSD
06:58 - FFT(快速傅里叶变换)
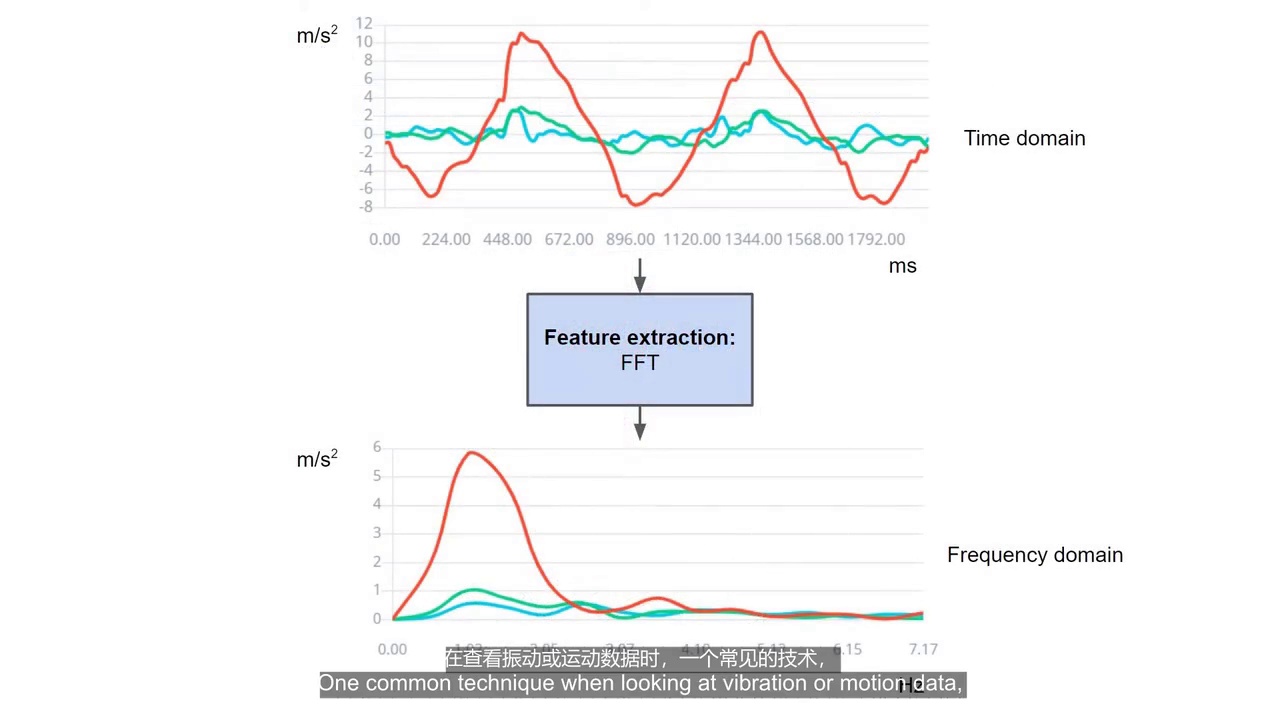
FFT作用:
分析信号中的频率成分
例如:
-
左右摆动1秒一次
那么:
频率:
1Hz
FFT会发现:
-
1Hz位置有峰值
07:51 - 不同频率对应不同运动
例如:
-
3Hz快速晃动
FFT中:
-
3Hz处会出现峰值
因此:
FFT特别适合:
-
振动分析
-
动作识别
08:00 - PSD(功率谱密度)
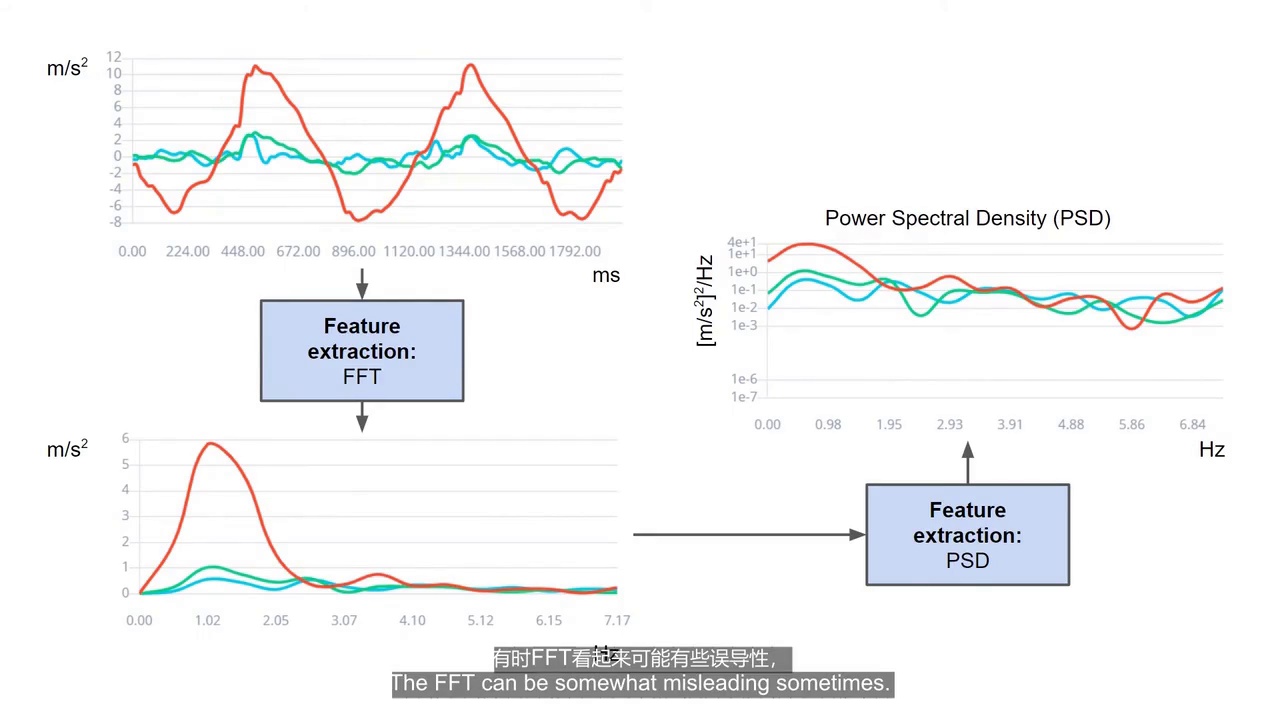
PSD:
是基于FFT进一步处理得到的。
作用:
-
描述不同频率上的能量分布
比FFT更稳定。
08:21 - Edge Impulse 的PSD特征
Edge Impulse不会直接输入完整PSD。
而是提取:
1. 峰值频率
例如:
-
最大峰在3Hz
说明:
-
主要运动频率是3Hz
2. 峰值振幅
表示:
-
该频率强度
3. 频段能量和
统计:
-
某个频率范围内的总能量
用于描述PSD整体形状。
09:10 - 特征降维结果
原始输入:
375维
特征提取后:
33维
效果:
-
模型更小
-
推理更快
-
更适合MCU
滑动窗口
09:54 - Sliding Window(滑动窗口)
10秒数据:
不仅能切5个窗口。
还可以:
-
每次滑动80ms
-
生成更多训练样本
作用:
-
数据增强
-
提高模型泛化能力
10:24 - MCU 推理阶段
部署后:
MCU流程:
采集2秒数据
→ 提取特征
→ 输入模型
→ 输出预测
通常:
-
不使用滑动窗口
机器学习流水线
10:54 - 完整流程
机器学习流程:
数据采集
→ 数据预处理
→ 特征提取
→ 模型训练
→ 推理部署
11:19 - 有监督学习
每个数据:
必须带标签。
例如:
| 数据 | 标签 |
|---|---|
| 挥手动作 | wave |
| 左右晃动 | shake |
12:14 - 训练过程
训练本质:
-
不断更新参数
-
减少预测误差
过程:
前向传播
→ 计算损失
→ 反向传播
→ 更新参数
参数 vs 超参数
12:37 - 参数(Parameter)
参数:
模型内部自动学习的值。
例如:
-
权重
-
偏置
由训练自动得到。
13:10 - 超参数(Hyperparameter)
超参数:
人工设定。
例如:
| 超参数 | 示例 |
|---|---|
| 学习率 | 0.001 |
| Epoch | 100 |
| 网络层数 | 3层 |
| FFT窗口长度 | 2秒 |
记忆技巧:
手动设置的,大概率就是超参数。
推理(Inference)
14:27 - 模型像一个函数
输入:
特征
输出:
预测结果
例如:
输入:
RMS + FFT特征
输出:
“左右晃动”
15:00 - 推理必须重复训练流程
部署时:
必须:
-
使用同样特征提取
-
同样预处理
-
同样数据顺序
否则:
模型会失效。
课程总结
17:55 - 本节重点回顾
学到的核心:
1. 特征工程非常重要
尤其是TinyML。
2. MCU资源有限
因此:
不能盲目使用超大模型。
3. FFT / RMS 是经典运动特征
特别适合:
-
IMU
-
振动
-
动作识别
4. 训练和推理不同
训练:
-
很复杂
-
很耗资源
推理:
-
只负责预测
神经网络部分
21:37 - 密集神经网络(Dense Neural Network)
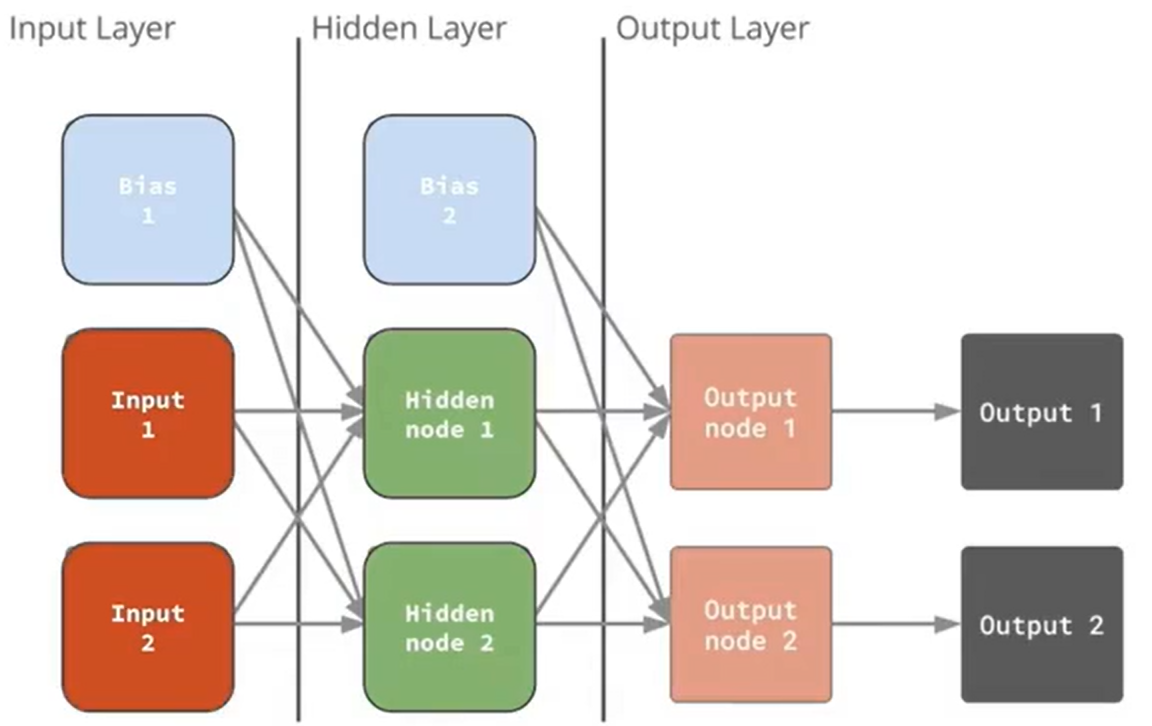
特点:
-
全连接
-
有隐藏层
结构:
→ 输入层(接收数据)
→ 隐藏层(负责学习数据规律)
→ 输出层(给最终分类结果)23:17 - 感知器(Perceptron)
神经网络最基础单元。
本质:
一个数学节点。
24:22 - 图像展开
28×28图像:
展开后:
28 × 28 = 784
输入神经网络:
784维向量。
24:36 - 权重(Weight)
每个输入量:
都有一个权重,每个神经元(感知器)都会对输入的所有数据进行加权求平均
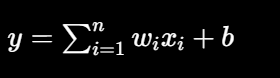
作用:
-
表示重要程度
24:48 - 偏置(Bias)
Bias作用:
-
调整决策边界
-
让模型更灵活
25:15 - 激活函数(Activation Function)

作用:
引入非线性能力
否则:
神经网络本质上:
只是线性回归。
26:15 - ReLU
现代神经网络最常见激活函数:
ReLU
优点:
-
计算简单
-
收敛稳定
-
训练更快
28:07 - 神经网络训练流程
训练步骤:
初始化权重
→ 输入数据
→ 前向传播
→ 计算损失
→ 反向传播
→ 更新权重
→ 重复训练

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)