2026最新,后端程序员转型AI:掌握这5项技能,轻松拿高薪AI岗!月薪30K+不是梦!
本文为后端程序员提供AI时代转型指南,核心优势在于工程能力可直接迁移至AI开发。文章系统梳理了从Python强化到模型API化的基础能力筑基阶段,再到RAG、Agent与提示工程的技能突破阶段,最后到微调部署与领域定制的拓展阶段。通过工程化实战案例与持续学习路径规划,帮助后端程序员高效掌握AI技术,实现职业跃迁,抓住AI风口下的高薪就业机会。
一、转型优势与认知重塑:为什么后端程序员是AI时代的最佳转型者?
1.1 工程能力的降维打击
后端程序员固有的系统架构设计、高并发处理及运维部署经验可直接迁移至AI应用开发:
- 大模型服务的API化本质与微服务架构高度契合(如模型推理的异步队列设计)
- 分布式系统经验可直接应用于模型训练集群管理(GPU资源调度、故障转移)
- 容器化技术栈(Docker/K8s)无缝衔接大模型部署场景

1.2 工具链的快速适配
后端开发者的技术栈与大模型开发工具链存在天然交集:
- Python生态主导地位:FastAPI构建模型服务接口 vs Flask/Django后端开发经验
- 数据库技能迁移:关系型数据库优化 → 向量数据库(Chroma/Qdrant)索引设计
- Git协作流程可直接复用至模型版本管理(MLflow/W&B)
1.3 业务抽象能力的复用
后端业务逻辑设计经验可转化为AI场景定义能力:
- 用户需求分析 → Prompt设计范式(角色+任务+约束)
- 工单系统流程 → Agent任务编排(ReAct框架)
- 支付风控规则 → 大模型输出安全过滤机制(敏感词正则+规则引擎)
关键认知转变:从“造模型”转向“用模型”,聚焦工程落地最后一公里问题。
二、基础能力筑基阶段(1-2个月):从Python强化到模型API化
2.1 Python生态深度强化
| 学习重点 | 实战案例 | 资源推荐 |
|---|---|---|
| 异步编程(async/await) | 构建流式大模型响应接口 | 《Effective Python》第7章 |
| 数据处理(Pandas) | 医疗对话数据清洗(MedDialog) | Kaggle医疗文本分析竞赛数据集 |
| 类型提示(Type Hints) | 增强Prompt工程函数可读性 | Python官方typing文档 |
2.2 开发框架速成路径
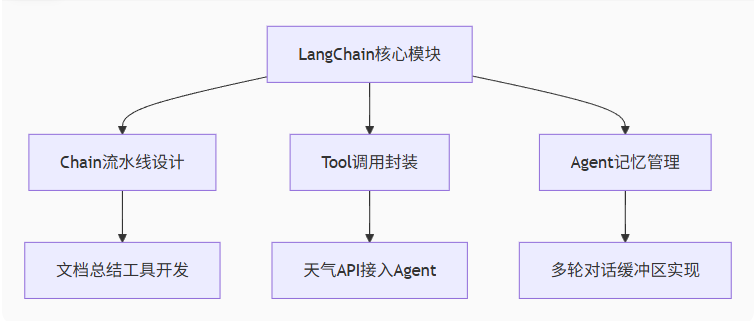
2.3 API工程化实战
-
主流API调用:OpenAI流式响应处理 + 通义千问计费策略优化
-
高可用设计:
# 模型API服务降级方案 def model_inference(prompt): try: return openai.ChatCompletion.create(model="gpt-4", messages=prompt) except RateLimitError: return local_llm.inference(prompt) # 切换到本地开源模型 -
成本监控:Token消耗实时分析仪表盘(Prometheus+Grafana)
三、核心技能突破阶段(2-3个月):RAG、Agent与提示工程
3.1 RAG系统开发黄金法则
文档处理三阶优化:
- 切分策略:滑动窗口算法(128 token窗口+32 token重叠)
- 向量化方案:text2vec-large-chinese嵌入模型 + Qdrant聚类索引
- 混合检索:BM25关键词召回 + 余弦相似度排序
3.2 Agent开发实战框架
1. **工具层设计**
- 天气查询:WorldWeatherOnline API封装
- 邮件发送:SMTP协议+附件解析
- 业务系统接入:企业ERP API鉴权
2. **推理引擎实现**
```python
# ReAct框架伪代码
def react_agent(question):
thought = "我需要查询北京天气"
tool = WeatherTool(query="北京")
observation = tool.execute()
return f"{thought} 结果:{observation}"
-
记忆管理
- 短期记忆:ConversationBufferWindow
- 长期记忆:Redis向量存储用户历史
**3.3 提示工程工业级实践**
- **结构化模板**:
```text
[角色]资深法律顾问
[任务]生成合同审查报告
[约束]引用《民法典》第500条|禁用专业术语缩写|输出Markdown表格
-
少样本学习:医疗诊断Prompt注入示例:
输入:患者男,45岁,持续咳嗽2周,体温37.8℃
输出:<诊断建议>支气管炎可能性大,建议胸片检查</诊断建议>
四、高阶能力拓展阶段(3-6个月):微调部署与领域定制
4.1 低成本微调技术栈
| 工具 | 适用场景 | 硬件要求 |
|---|---|---|
| LlamaFactory | 多任务指令微调 | 单卡RTX 4090 |
| Unsloth | 训练速度提升40% | 云实例T4 GPU |
| GPT-4合成数据 | 解决标注数据匮乏 | 无GPU要求 |
4.2 垂直领域适配策略
-
法律行业:裁判文书Prompt优化(法条引用+严谨性约束)
-
医疗场景:
# 药品说明生成安全过滤器 def medical_filter(text): if "剂量" in text and not contains_number(text): return "【警告】未检测到明确剂量信息" return text
五、工程化实战:从原型到企业级应用
5.1 项目架构设计范式
1. **流量治理层**
- API网关:鉴权+限流(200 QPS/租户)
- 降级策略:CPU>80%时关闭长文本生成
2. **模型服务层**
- 动态加载器:HuggingFace模型热切换
- 缓存机制:Redis存储重复Query结果
3. **业务适配层**
- 规则引擎:合规性检查(金融敏感词过滤)
- 日志审计:Token消耗追踪+用户行为分析:cite[3]:cite[8]
5.2 典型项目闭环开发
-
智能客服系统:
- 知识库:企业PDF手册向量化(LangChain + Chroma)
- 工单对接:自动创建ServiceNow工单
-
金融报表生成:
- 数据层:SQL查询 → 向量检索 → 图表生成
- 审核流:GPT-4生成 → 风控规则过滤 → 人工复核
六、持续学习与职业发展
6.1 技术演进追踪矩阵
| 领域 | 2025关键技术 | 学习资源 |
|---|---|---|
| 多模态 | LLaVA-v2视觉问答 | arXiv:2304.08485 |
| 推理优化 | FlashAttention-3 | NVIDIA技术博客 |
| 轻量化 | MobileLLM 2B | Hugging Face模型库 |
6.2 职业跃迁路径
1. **岗位选择优先级**
- ✅ AI应用开发工程师(年薪50W+)
- ✅ 大模型产品经理(技术+场景双背景)
- ⚠️ 慎选算法研究员(需PhD学历+顶会论文):cite[2]
2. **简历黄金项目描述**
> “搭建医疗政策问答系统:
> - 实现RAG召回率92%+(HyDE优化)
> - 通过微调降低幻觉率37%
> - 承载三甲医院日均3000+查询”:cite[6]
结语:工程师转型的终极法则
“用已有的工程化能力解决AI落地最后一公里问题,而非重复造轮子” —— 深耕场景而非模型26
结语:抓住大模型时代的职业机遇
AI大模型的发展不是“替代人类”,而是“重塑职业价值”——它淘汰的是重复性、低附加值的工作,却催生了更多需要“技术+业务”交叉能力的高端岗位。对于求职者而言,想要在这波浪潮中立足,不仅需要掌握Python、TensorFlow/PyTorch等技术工具,更要深入理解目标行业的业务逻辑(如金融的风险控制、医疗的临床需求),成为“懂技术、懂业务”的复合型人才。
无论是技术研发岗(如算法工程师、研究员),还是业务落地岗(如产品经理、应用工程师),大模型都为不同背景的职场人提供了广阔的发展空间。只要保持学习热情,紧跟技术趋势,就能在AI大模型时代找到属于自己的职业新蓝海。
最近两年大模型发展很迅速,在理论研究方面得到很大的拓展,基础模型的能力也取得重大突破,大模型现在正在积极探索落地的方向,如果与各行各业结合起来是未来落地的一个重大研究方向
大模型应用工程师年包50w+属于中等水平,如果想要入门大模型,那现在正是最佳时机
2025年Agent的元年,2026年将会百花齐放,相应的应用将覆盖文本,视频,语音,图像等全模态
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

给大家推荐一个大模型应用学习路线
这个学习路线的具体内容如下:
第一节:提示词工程
提示词是用于与AI模型沟通交流的,这一部分主要介绍基本概念和相应的实践,高级的提示词工程来实现模型最佳效果,以现实案例为基础进行案例讲解,在企业中除了微调之外,最喜欢的就是用提示词工程技术来实现模型性能的提升

第二节:检索增强生成(RAG)
可能大家经常会看见RAG这个名词,这个就是将向量数据库与大模型结合的技术,通过外部知识来增强改进提升大模型的回答结果,这一部分主要介绍RAG架构与组件,从零开始搭建RAG系统,生成部署RAG,性能优化等

第三节:微调
预训练之后的模型想要在具体任务上进行适配,那就需要通过微调来提升模型的性能,能满足定制化的需求,这一部分主要介绍微调的基础,模型适配技术,最佳实践的案例,以及资源优化等内容

第四节:模型部署
想要把预训练或者微调之后的模型应用于生产实践,那就需要部署,模型部署分为云端部署和本地部署,部署的过程中需要考虑硬件支持,服务器性能,以及对性能进行优化,使用过程中的监控维护等

第五节:人工智能系统和项目
这一部分主要介绍自主人工智能系统,包括代理框架,决策框架,多智能体系统,以及实际应用,然后通过实践项目应用前面学习到的知识,包括端到端的实现,行业相关情景等

学完上面的大模型应用技术,就可以去做一些开源的项目,大模型领域现在非常注重项目的落地,后续可以学习一些Agent框架等内容
上面的资料做了一些整理,有需要的同学可以下方添加二维码获取(仅供学习使用)


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献116条内容
已为社区贡献116条内容

所有评论(0)