《基于 QLoRA 的垂直领域轻量化微调实战》
一、前言:为什么要学 QLoRA 垂直微调?
1. 传统大模型微调痛点:全量微调显存占用高、算力成本昂贵、普通设备无法落地。
2. LoRA 微调局限:常规LoRA仍需一定显存,大参数量模型微调门槛高。
3. QLoRA核心优势:4/8位量化 + 低秩适配,极致压缩显存,单消费级显卡即可微调7B/13B大模型。
4. 垂直领域微调价值:通用大模型专业度不足,微调后适配医疗、金融、教育、工业等细分场景。 5. 本文实战目标:从零搭建QLoRA微调流程,跑通垂直领域数据集训练、推理、模型合并全流程。
二、核心原理:通俗读懂 QLoRA 底层逻辑
2.1 什么是 LoRA?低秩适配核心原理
1. 大模型权重特性:高维矩阵存在大量冗余信息。
2. LoRA核心思想:冻结预训练模型权重,仅训练低秩矩阵A、B,大幅减少参数量 。
3. 基础公式与参数更新逻辑,无梯度回传原模型权重。
4. LoRA优势与短板:轻量化、高效,但无法解决大模型浮点权重显存占用问题。
LoRA核心结构原理图
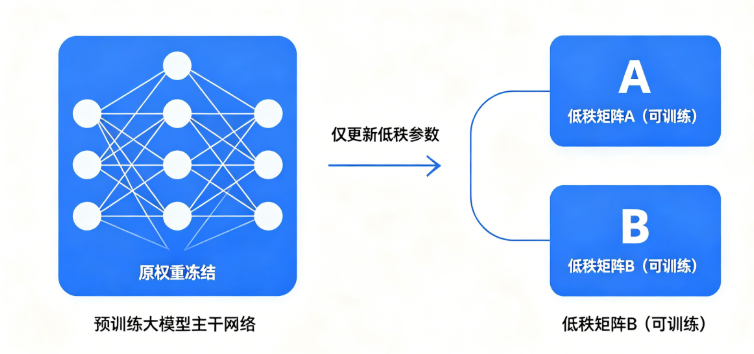
上图清晰展示了LoRA核心工作机制:预训练大模型原始高维权重矩阵全程冻结,不参与梯度更新,仅新增小规模低秩A、B矩阵参与训练,用极少参数量实现模型能力增量学习,从根源降低训练算力开销。
2.2 什么是 QLoRA?量化+LoRA双重优化
1. 量化原理:FP16/32权重压缩为INT4/INT8,降低显存占用。
2. QLoRA创新点:量化冻结权重 + LoRA增量训练,兼顾极低显存和微调精度。
3. 双量化机制:权重量化、计算量化,全程低精度运算不损失垂直领域效果 。
4. 核心对比:全量微调 VS 普通LoRA VS QLoRA(显存、速度、精度、算力门槛对比)。
QLoRA整体工作原理图

相较于传统微调方案,QLoRA创新性融合INT4/INT8量化技术与LoRA低秩微调,先对原始大模型权重做极致压缩并冻结,仅通过低秩矩阵学习垂直领域知识,完美解决了普通LoRA显存占用高、全量微调成本昂贵的行业痛点。
2.3 垂直领域微调适配原理
1. 通用模型缺陷:垂直领域专业知识缺失、回答不精准、术语错误。
2. QLoRA微调适配逻辑:通过领域数据集激活模型隐性知识,增量学习专业场景能力 。
3. 微调不遗忘:冻结原模型能力,仅新增垂直领域适配能力。
垂直领域微调适配原理图
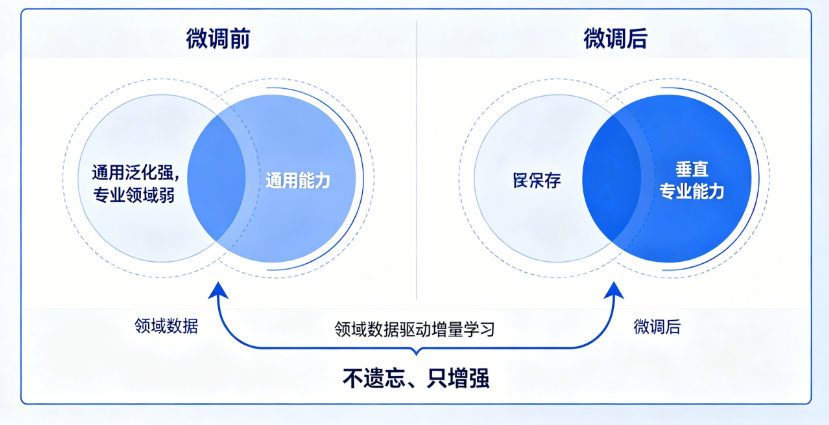
从图中可以直观看到,QLoRA垂直微调属于增量学习范式,全程保留大模型通用对话、逻辑推理能力,仅针对医疗、金融、工业等细分领域,通过专属数据集补充专业知识,不会出现灾难性遗忘问题。
三、实战环境与项目准备(可直接复刻)
3.1 硬件与环境要求
1. 硬件门槛:单卡3060/3090/4060等消费级显卡即可(最低8G显存)。
2. 核心依赖库版本:Transformers、PEFT、Bitsandbytes、TRL、Accelerate 3. 环境安装命令:一键安装全套依赖。
3.2 项目整体流程梳理
数据集制作 → 模型量化加载 → QLoRA参数配置 → 训练微调 → 模型评估 → 权重合并 → 推理部署。
3.3 基础模型与垂直数据集准备
1. 开源基础模型选择:Llama2、Qwen、ChatGLM等轻量主流大模型选型建议。
2. 垂直领域数据集格式要求:对话式JSON数据集规范 。
3. 数据集清洗、预处理标准(规避训练报错、过拟合问题)。
4. 开源垂直数据集获取渠道 + 自定义数据集制作方法。
四、核心实战:QLoRA垂直领域微调完整实现
4.1 模型量化加载配置(核心代码)
1. 4/8位量化参数设置、双量化开启、显存优化配置。
2. 模型自动设备映射、梯度累积配置 。
3. 冻结原模型权重,仅开启LoRA训练。
4.2 QLoRA超参数配置详解
1. LoRA核心参数:秩、alpha、dropout、目标层设置 。
2. 训练参数:学习率、batch_size、epoch、梯度累积步数 。
3. 量化参数、正则化参数调优逻辑(适配垂直小数据集)。
4.3 数据集加载与训练流程代码
1. 自定义数据集加载、分词器配置、数据预处理代码 。
2. 训练器初始化、训练监控、日志保存配置 。
3. 断点续训功能实现(避免训练中断重头开始)。
4.4 模型训练、保存与权重合并
1. 启动训练、损失曲线查看、训练效果监控 。
2. 单独保存LoRA增量权重(体积极小)。
3. LoRA权重与原量化模型合并,生成可部署完整模型。
4.5 微调后模型推理测试
1. 垂直领域场景问答推理代码。
2. 微调前后效果对比(专业度、准确率、逻辑性差异)。
五、完整可运行代码示例(整合版)
1. 全套整合代码(环境初始化+量化配置+训练+推理+合并)。
2. 代码逐段注释,关键参数标注说明 。
3. 适配Windows/Linux系统,可直接复制运行。
4. 自定义修改指南:替换数据集、更换模型、调整超参数。
六、微调常见问题与踩坑解决方案(高频避坑)
6.1 显存相关问题
1. 显存溢出OOM报错解决方案 。
2. 量化失效、显存占用过高问题修复 。
3. 小显卡显存极致优化技巧
6.2 训练效果问题
1. 训练损失不降、过拟合、欠拟合解决方案 。
2. 微调后模型回答错乱、重复、无专业度问题 。
3. 垂直领域适配效果差、泛化能力弱优化方法。
6.3 代码报错与环境问题
1. Bitsandbytes量化报错、版本不兼容问题。
2. 模型加载失败、权重不匹配报错 。
3. 数据集格式错误、分词异常修复方案。
6.4 部署适配问题
1. 合并后模型推理速度慢、占用高问题 。
2. LoRA权重无法加载、微调效果不生效问题。
七、模型调优与进阶优化技巧
1. 垂直小数据集微调专属调参策略 。
2. 分层LoRA微调、动态秩值优化 。
3. 结合SFT监督微调、提升对话规整度 。
4. 模型压缩、推理加速二次优化方案。
八、总结与落地展望
1. QLoRA轻量化微调核心优势总结。
2. 普通开发者落地垂直大模型的最佳实践 。
3. 适用落地场景:企业知识库、行业问答、专属AI助手等。
4. 后续优化方向:多轮微调、RLHF对齐、批量部署。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)