基于 MCFCTransformer-DD 的 CPU 调度策略识别方法
1. 研究背景
CPU 调度的目标是根据系统当前状态选择合适的进程执行顺序,从而平衡吞吐量、响应时间和资源利用率。传统调度算法通常依赖固定规则,例如 FCFS 关注到达顺序,SJF 关注运行时间,PSA 关注优先级,RR 关注时间片轮转。
但是,不同调度算法适合不同负载。当任务运行时间差异明显时,SJF 或 SRTF 可能更有优势;当任务优先级差异明显时,PSA 可能更合理;当系统更强调公平性时,RR 更适合。因此,问题不再是“哪一种调度算法永远最好”,而是“给定当前任务集,哪一种调度算法最合适”。
2. 核心任务
本文的核心任务是实现 CPU 调度策略的智能识别与决策支持。模型并不是直接替代操作系统调度器,也不是重新提出一种固定调度规则,而是根据当前任务集中的进程特征,判断 FCFS、SJF、SRTF、PSA 和 RR 五种候选调度算法中哪一种更适合当前场景。
具体来说,本文将调度策略选择建模为一个监督学习五分类问题。每个样本对应一个完整任务集,模型输入为该任务集的进程特征,输出为一个候选调度算法。标签由仿真过程自动生成:对同一任务集分别运行五种调度算法,计算各自的平均周转时间,并将平均周转时间最小的算法作为最优标签。
3. 数据构造
数据构造是理解本文的关键。一个样本并不是单个进程,而是一个包含 5 个进程的任务集。每个进程由 4 个调度属性描述,分别是到达时间、运行时间、优先级和时间片。因此,一个任务集最终可以展平为一个 20 维输入向量。
也就是说,模型看到的不是“某一个进程应该选择什么算法”,而是“这 5 个进程共同组成的任务集适合哪种调度算法”。
| 进程 | 到达时间 at | 运行时间 bt | 优先级 pr | 时间片 tq |
|---|---|---|---|---|
| P1 | at1 | bt1 | pr1 | tq1 |
| P2 | at2 | bt2 | pr2 | tq2 |
| P3 | at3 | bt3 | pr3 | tq3 |
| P4 | at4 | bt4 | pr4 | tq4 |
| P5 | at5 | bt5 | pr5 | tq5 |
表 1 一个任务集的特征结构
4. 标签生成
对于同一个任务集,系统分别运行 FCFS、SJF、SRTF、PSA 和 RR 五种调度算法。每种算法都会产生一组完成时间,并进一步计算每个进程的周转时间。最后,对 5 个进程的周转时间求平均,得到该算法的平均周转时间 avgTAT。
首先,第 i个进程的周转时间定义为:
其中,表示第 i个进程的周转时间,
表示第 i 个进程的完成时间,
表示第 i 个进程的到达时间。周转时间反映的是一个进程从进入系统到最终执行完成所经历的总时间。
对于某一种调度算法 a,其在当前任务集上的平均周转时间为:
其中,a表示候选调度算法,且 a∈{FCFS,SJF,SRTF,PSA,RR}。 表示在调度算法 a下,第 i个进程的完成时间。由于不同调度算法会产生不同的执行顺序,因此同一个进程在不同算法下的完成时间可能不同,最终得到的
也不同。
因此,当前任务集的标签定义为:
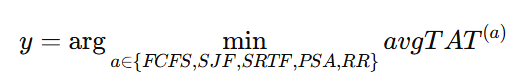
其中,y 表示当前任务集的标签,也就是该任务集对应的最优调度算法。argmin 表示选择使 avgTAT最小的调度算法。平均周转时间越小,说明该算法能使进程从到达到完成的平均耗时更短。因此,本文将 avgTAT最小的算法作为该任务集的监督学习标签。
5. 方法框架
在完成 数据和标签的构造后,问题就变成了一个标准监督学习任务:如何从 20 维任务集特征中预测最优调度算法。
MCFCTransformer-DD 的设计思路是分层完成的。多尺度卷积先从原始输入中提取局部组合模式;频域增强进一步补充波动和频谱信息;双分支自注意力同时建模原始多尺度特征和频域增强特征的全局依赖;最后,DD 树突判别器根据原始特征和 Transformer 表征进行可解释的非线性分类。
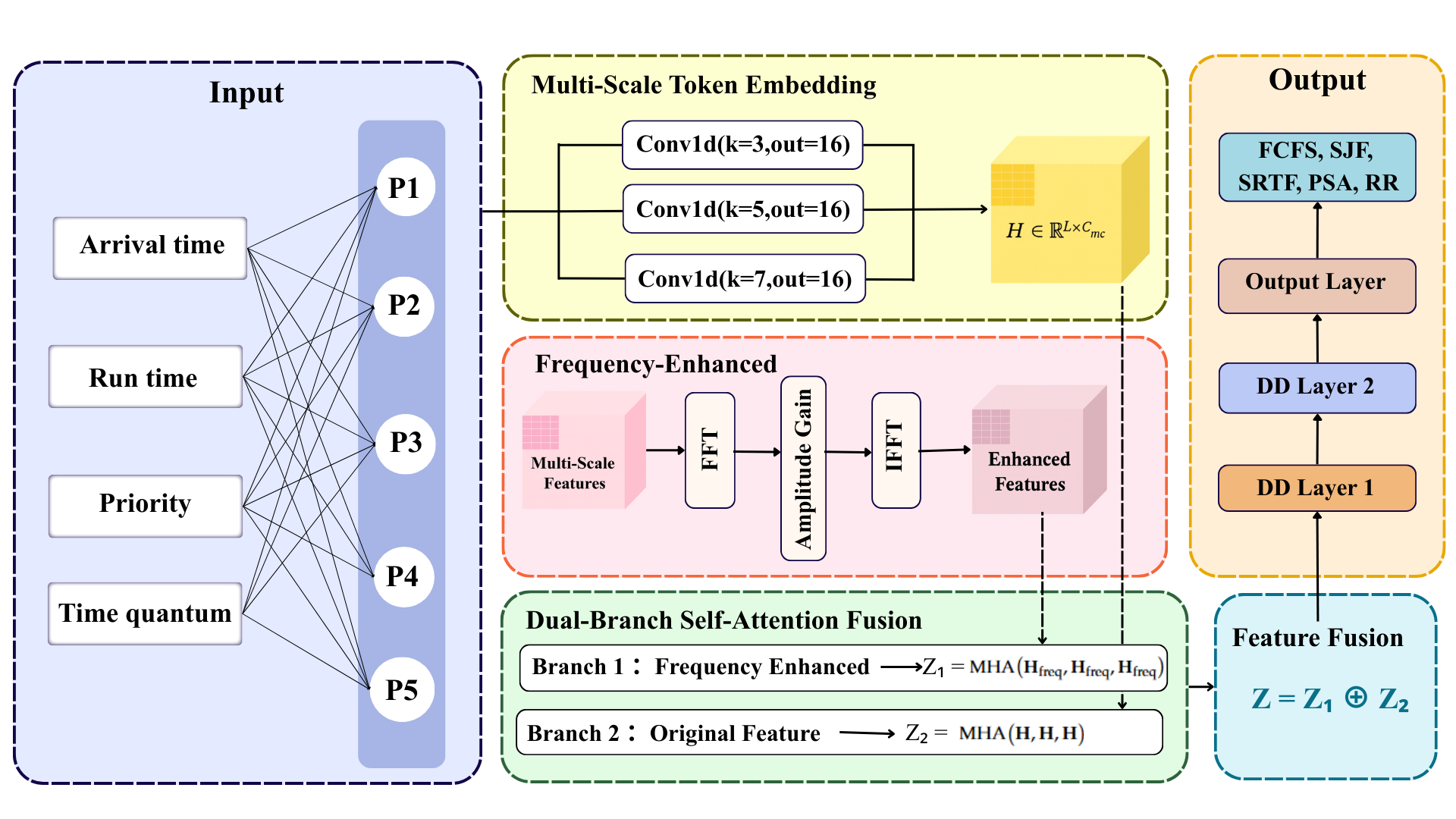
图 1 MCFCTransformer-DD 整体模型框架
模型将输入编码为短序列,经过 kernel size 为 3、5、7 的并行 1D 卷积,再进行 FFT-based frequency branch、双分支自注意力融合,并最终送入 DD 和 softmax 输出五种调度策略。
6. 模块解析
6.1 多尺度卷积:捕捉局部调度模式
原始输入虽然已经包含到达时间、运行时间、优先级和时间片,但这些只是基础字段。调度策略选择依赖的不是单个字段,而是多个进程和多个属性之间的组合关系。
因此,模型首先使用多尺度卷积提取局部模式。不同卷积核对应不同感受野,可以从短范围、中范围和较长范围捕捉进程特征之间的局部依赖。
原始特征告诉模型“有什么数据”,多尺度卷积学习“这些数据之间有什么局部模式”。
6.2 频域增强:补充波动和频谱信息
卷积主要在原始序列空间中提取局部关系,但任务集中的变化模式不只体现在局部数值上,也可能体现在整体波动结构上。例如,运行时间是否忽长忽短、优先级是否差异明显、到达时间是否集中,都可能影响哪种算法更优。
因此,模型将多尺度特征转换到频域,增强频域响应后再转回时域。这样做的目的不是替代原始特征,而是在保留序列结构的同时引入频谱和波动信息。
卷积看局部组合,频域增强看变化规律。
6.3 双分支自注意力:融合原始特征与频域特征
频域增强后,模型同时拥有两类特征:原始多尺度特征 H 和频域增强特征 Hfreq。直接拼接这两类特征虽然简单,但无法显式学习特征之间的依赖关系。
因此,论文设计了双分支自注意力。一条分支对 H 建模,保留原始多尺度结构;另一条分支对 Hfreq 建模,捕捉频域增强后的全局依赖。最后将两条分支融合,得到更完整的任务集表示。
拼接只是把特征放在一起,自注意力是先学习谁和谁有关,再融合。
6.4 DD 树突判别器:实现可解释非线性分类
Transformer 可以提取复杂特征,但如果最后只使用普通全连接分类器,模型的决策过程仍然较难解释。为此,论文引入 DD 树突判别器作为最终分类头。
DD 通过类似树突结构的门控计算和 Hadamard product 建模高阶特征交互,使模型不仅能处理非线性决策边界,还能提供一定的决策可追踪性。
Transformer 负责提取特征,DD 负责基于这些特征做可解释的非线性决策。
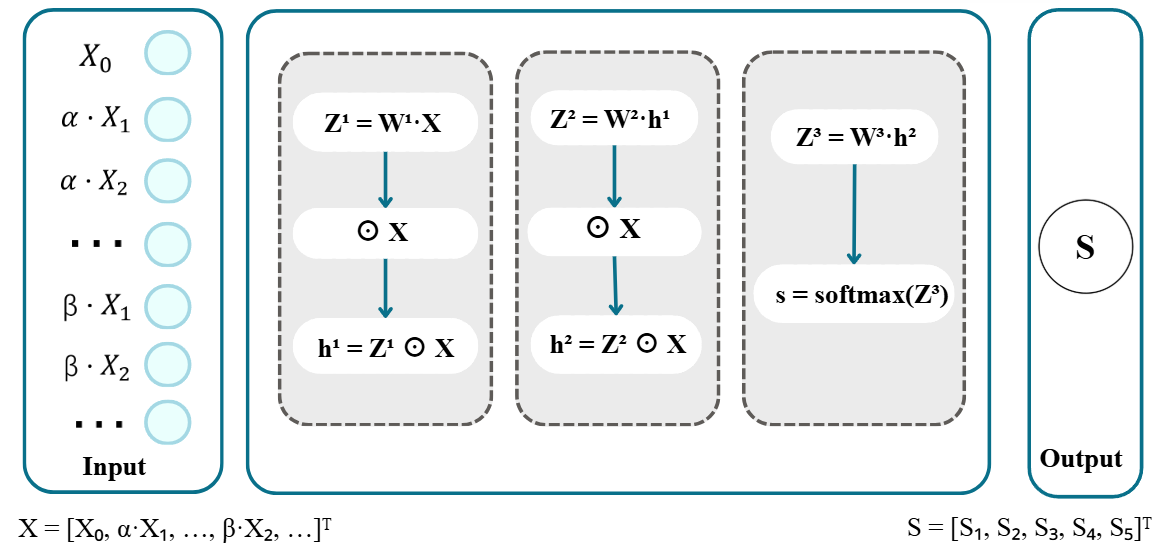
图2 DDNet算法流程图
7. 训练策略
MCFCTransformer-DD 采用两阶段训练策略。第一阶段训练 MCFCTransformer backbone,使其能够从 20 维输入中提取对分类有用的表征。第二阶段冻结 backbone,提取 Transformer 表征,并与原始调度特征一起送入 DD 判别器,训练最终分类边界。
这种设计将“特征学习”和“可解释分类”分开处理。backbone 负责学习复杂表征,DD 负责最终判别。
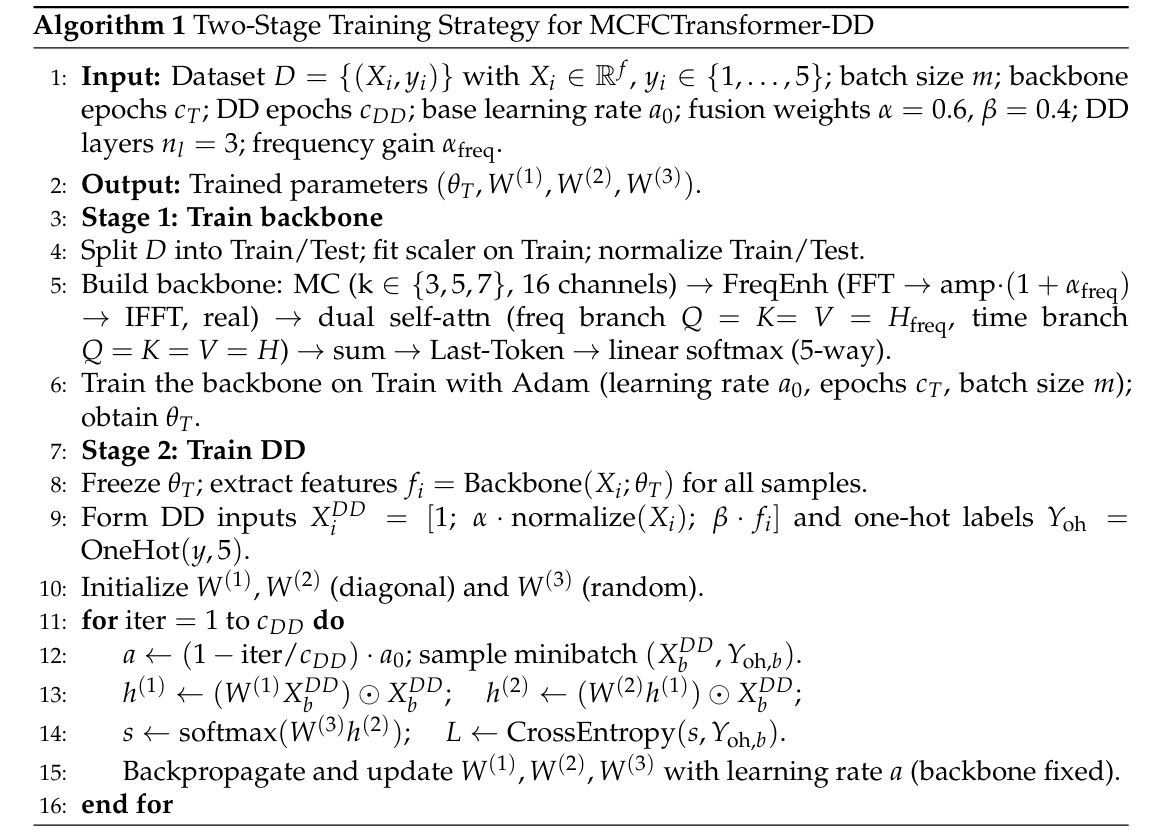 图3 训练算法图
图3 训练算法图
8. 实验结果
8.1 消融实验
消融实验从普通 Transformer 开始,逐步加入多尺度卷积、频域增强、双分支自注意力和 DD 判别器。结果显示,模型性能随着模块逐步加入而持续提升,说明这些模块不是简单堆叠,而是分别对分类性能有贡献。
| Model | Accuracy (%) | F1 (%) | AUROC |
|---|---|---|---|
| Transformer | 84.00 | 83.78 | 0.96 |
| MCTransformer | 87.40 | 87.53 | 0.98 |
| MCFTransformer | 89.30 | 89.40 | 0.98 |
| MCFCTransformer | 90.50 | 90.67 | 0.99 |
| MCFCTransformer-DD | 94.50 | 94.65 | 1.00 |
表 2 消融实验结果
从结果可以看出,多尺度卷积带来了第一阶段提升,说明局部调度模式有效;频域增强进一步提升性能,说明波动和频谱信息有助于区分不同调度策略;双分支自注意力继续提升结果,说明原始特征与频域特征之间的融合是有意义的;最后加入 DD 后性能提升最明显,说明可解释非线性判别器对最终分类具有重要作用。
9. 总结
本文的核心价值在于,它没有继续从人工规则角度设计一种新的 CPU 调度算法,而是将 CPU 调度策略选择转化为一个数据驱动的分类问题。对于同一个任务集,系统分别运行不同调度算法,并以平均周转时间最小的算法作为标签。这样,模型学习的不是某一种固定调度规则,而是学习“在当前任务集特征下,哪一种调度策略更合适”。
不过,该方法仍然存在一定局限。首先,当前数据主要来自仿真合成,而不是直接来自真实操作系统日志,因此实验结果更适合说明模型在受控仿真环境下的有效性。其次,每个任务集固定包含 5 个进程,输入维度固定为 20,这与真实操作系统中动态变化的就绪队列仍有差距。再次,当前任务主要面向单处理器调度策略识别,尚未充分覆盖多核心调度、进程迁移、缓存局部性、NUMA 结构和真实内核调度开销等系统级因素。最后,本文模型更准确地说是 CPU 调度策略识别与决策支持模型,而不是已经直接部署到操作系统内核中的完整调度器。
总体来看,MCFCTransformer-DD 为 CPU 调度策略选择提供了一种新的数据驱动思路。它通过仿真生成任务集,以平均周转时间构造监督标签,并利用多尺度卷积、频域增强、双分支自注意力和 DD 判别器学习从进程特征到最优调度策略的映射关系。该方法的意义在于,将传统操作系统调度问题与深度学习分类建模结合起来,为智能调度决策提供了一个可解释的建模框架。未来工作可以进一步引入真实 workload trace、变长任务集建模、多核心调度环境以及 Linux CFS 等实际调度器对比,从而提升方法的工程适用性和系统验证价值。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)