【PyTorch 从入门到实战】第 2 篇:搞懂自动求导,才算真正入门 PyTorch
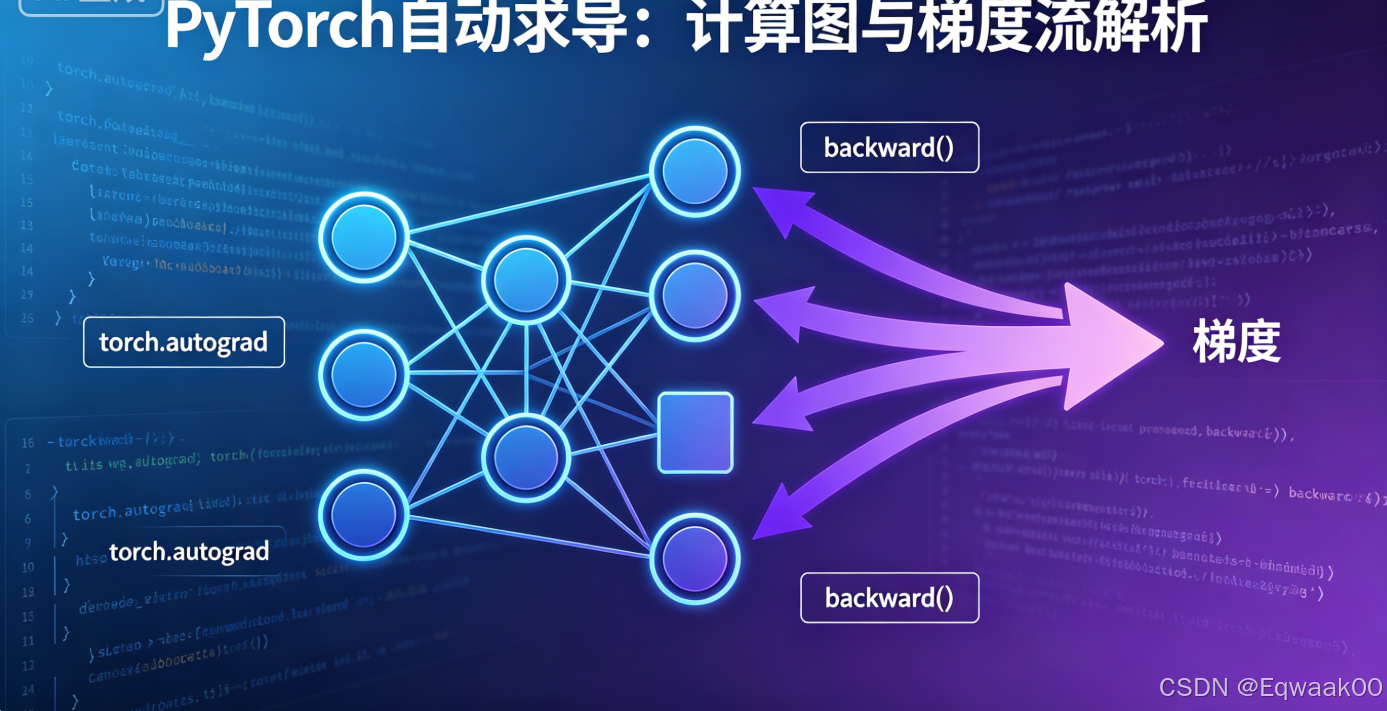
上一篇文章我们熟悉了张量(Tensor)的各种玩法。从这一篇开始,我们将触碰到 PyTorch 真正的灵魂——自动微分(autograd)。
常有人说:“PyTorch 用起来就像写普通 Python 代码,调试起来太舒服了。” 这种体验的核心,正是它的动态计算图和自动求导机制。不过,backward() 里面的 梯度累加、叶子节点、in-place 操作 等细节,也让无数新手踩坑。
本文将用最直白的例子,帮你一步步拆解这些概念,让你彻底搞懂 PyTorch 的梯度系统。
一、什么是自动求导,它解决了什么?
想象你定义了一个复杂的数学函数,然后手动去推导它的导数,再写成代码——既容易出错,又极其繁琐。
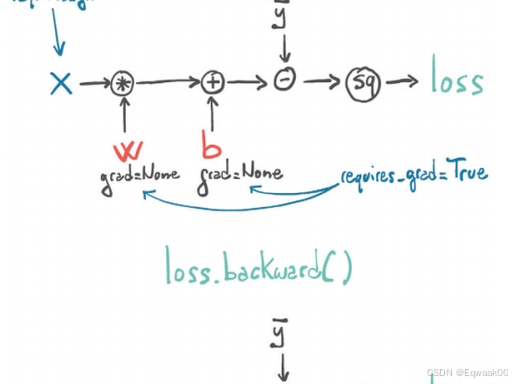
PyTorch 的 autograd 会自动为你计算导数。你只需要:
-
创建张量时设置
requires_grad=True -
用这些张量进行一系列运算,构建计算图
-
对最终的标量结果调用
backward() -
所有中间张量的梯度会自动存入
.grad属性
就这么简单。
二、一个例子直观感受自动求导
import torch
# 1. 创建带梯度的张量
x = torch.tensor([2.0, 3.0], requires_grad=True)
w = torch.tensor([0.5, 1.0], requires_grad=True)
b = torch.tensor([1.0], requires_grad=True)
# 2. 构建计算:y = x · w + b
y = (x * w).sum() + b # y 是一个标量
# 3. 反向传播
y.backward()
# 4. 查看梯度
print(x.grad) # tensor([0.5000, 1.0000])
print(w.grad) # tensor([2.0000, 3.0000])
print(b.grad) # tensor([1.0000])我们可以手动验证一下:
-
y = x1*w1 + x2*w2 + b -
∂y/∂x1 = w1 = 0.5,匹配
x.grad[0] -
∂y/∂w1 = x1 = 2.0,匹配
w.grad[0] -
∂y/∂b = 1,匹配
b.grad
简单得令人发指。下面我们深入细节。
三、计算图:动态的魔法
PyTorch 采用的是 动态计算图,即图是在你执行代码的过程中实时构建的。
a = torch.tensor(2.0, requires_grad=True)
b = a ** 2
c = b ** 0.5
c.backward()
print(a.grad) # 0.5 * (a^2)^(-0.5) * 2a = 1当你调用 c.backward() 时,PyTorch 会沿着计算图反向传播,自动算出 a.grad。
关键特性:
-
图在每次前向计算时重新构建,因此你可以使用 Python 原生的控制流(if、for、while),梯度依然能正确传递。
-
这让你写代码时完全不需要预先定义静态图,极大地提升了灵活度。
四、为什么 backward() 必须是标量?
PyTorch 规定,只有标量(0 维张量)才能直接调用 backward()。如果你想对一个张量求导,需要先把它转换成标量(比如求平均、求和)。
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
y = x ** 2
# y.backward() # 直接报错!因为 y 不是标量
y = y.sum() # 转成标量
y.backward()
print(x.grad) # tensor([2., 4., 6.])原理:
backward()计算的是向量-雅可比积,需要传入一个与输出同形状的gradient张量。如果你不传,就默认是标量 1,因此要求输出必须是标量。
五、梯度累加与 zero_grad() ——最常见错误
看下面这段代码:
w = torch.tensor([1.0], requires_grad=True)
for epoch in range(3):
y = w ** 2
y.backward()
print(f"epoch {epoch}: w.grad = {w.grad}")
# w.grad 每次都会累加!输出:
epoch 0: w.grad = tensor([2.]) epoch 1: w.grad = tensor([4.]) epoch 2: w.grad = tensor([6.])
为什么梯度会累加? 因为 PyTorch 的 .backward() 会把新计算出的梯度累加到 .grad 中,而不是覆盖。这样设计是为了方便在 RNN 等场景中共享梯度。
解决方法:每次反向传播前手动清零。
for epoch in range(3):
if w.grad is not None:
w.grad.zero_() # 手动清零
y = w ** 2
y.backward()
print(f"epoch {epoch}: w.grad = {w.grad}") # 每次都是 2.0在训练代码中,我们通常用 optimizer.zero_grad() 一次性清零所有参数的梯度。
六、叶子节点与非叶子节点
在计算图中,用户直接创建的张量被称为 叶子节点。只有叶子节点的 .grad 会被保存,非叶子节点的梯度默认会被释放以节省内存。
a = torch.tensor(2.0, requires_grad=True)
b = a ** 2 # b 是非叶子节点
c = b * 3
c.backward()
print(a.grad) # 叶子节点,有梯度
print(b.grad) # None!非叶子节点,梯度已被释放如果你想保留非叶子节点的梯度,可以在创建它们时用 .retain_grad() 方法。
a = torch.tensor(2.0, requires_grad=True)
b = a ** 2
b.retain_grad() # 要求保留梯度
c = b * 3
c.backward()
print(b.grad) # tensor(3.)实用建议:一般不需要关心中间节点的梯度,让框架自己管理即可。
七、no_grad() 与 detach():冻结计算的两种方式
7.1 torch.no_grad()
在模型评估或推理时,我们需要关闭梯度计算以节省内存和加速。torch.no_grad() 上下文管理器可以做到。
x = torch.tensor([1.0, 2.0], requires_grad=True)
with torch.no_grad():
y = x * 2
print(y.requires_grad) # False7.2 detach()
detach() 会返回一个与原张量同数据但脱离计算图的新张量,常用于截断梯度流动。
x = torch.tensor([1.0, 2.0], requires_grad=True)
y = x ** 2
z = y.detach() * 3 # z 不再与 x 有关联
z.sum().backward()
print(x.grad) # None,梯度被截断了常见场景:需要提取模型中间层的输出用于可视化或保存,但不希望这些操作影响训练。
八、in-place 操作的地雷区
对 requires_grad=True 的叶子节点执行 in-place 操作(如 +=、fill_、zero_ 等)会直接报错,因为这会破坏计算图的反向追踪。
x = torch.tensor([1.0, 2.0], requires_grad=True)
x += 1 # 报错 RuntimeError: a leaf Variable that requires grad has been used in an in-place operation为什么这么严格? 因为 in-place 操作会覆盖掉原始数据,导致反向传播时无法正确恢复中间值。
注意:对非叶子节点,也不建议随意 in-place 操作,容易导致反向传播结果错误。
九、高阶梯度与 create_graph
PyTorch 还可以计算梯度的梯度(二阶导数),只需在 backward() 中设置 create_graph=True。
x = torch.tensor([2.0], requires_grad=True)
y = x ** 3
grad1 = torch.autograd.grad(y, x, create_graph=True)[0] # 一阶导 dy/dx = 3x^2
print(grad1) # tensor([12.])
grad2 = torch.autograd.grad(grad1, x)[0] # 二阶导 d2y/dx2 = 6x
print(grad2) # tensor([12.])虽然日常用到的机会不多,但在诸如梯度惩罚、元学习等任务中很重要。
十、一个完整的训练微流程:把 autograd 串起来
现在你已经理解了自动求导的原理,我们把它放到一个极简的训练循环中看看:
# 一个简单的线性回归 y = 2x + 1
x = torch.tensor([[1.0], [2.0], [3.0], [4.0]])
y = torch.tensor([[3.0], [5.0], [7.0], [9.0]])
w = torch.tensor([[0.0]], requires_grad=True)
b = torch.tensor([[0.0]], requires_grad=True)
lr = 0.01
for epoch in range(100):
# 前向
y_pred = x @ w + b
loss = ((y_pred - y) ** 2).mean()
# 反向
loss.backward()
# 手动更新参数
with torch.no_grad():
w -= lr * w.grad
b -= lr * b.grad
# 清零梯度
w.grad.zero_()
b.grad.zero_()
if epoch % 20 == 0:
print(f"Epoch {epoch}: loss = {loss.item():.4f}")
print("训练完成:w ≈", w.item(), "b ≈", b.item())输出:
Epoch 0: loss = 58.0000 Epoch 20: loss = 0.0313 Epoch 40: loss = 0.0005 Epoch 60: loss = 0.0000 ... 训练完成:w ≈ 2.0000 b ≈ 1.0000
完美拟合!这就是自动求导 + 手动梯度下降的朴素实现。虽然我们未来会使用 torch.optim 和 nn.Module 封装这些细节,但底层原理就是如此。
十一、本篇小结
今天我们彻底掰开了 PyTorch 的自动求导机制:
-
requires_grad标记需要梯度的张量 -
backward()自动计算梯度,要求目标为标量 -
梯度会累加,必须每次清零
-
叶子节点才有
.grad保留 -
no_grad()与detach()用来冻结/截断梯度 -
避免对叶子节点进行 in-place 操作
掌握这些,你就拿到了深度理解 PyTorch 训练过程的钥匙。
我们下篇见,继续死磕 PyTorch。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)