VAD 与流式 ASR 踩坑复盘及完整解决方案
大家好,我是语音算法与端侧AI开发的工程师。近期一直在维护自研会议产品熙瑾会悟的离线转记模块。本以为接入开源流式ASR模型就能快速上线,结果在实测阶段接连踩坑:人声截断、静音幻觉、断句错乱、推理卡顿。
一、摘要
针对熙瑾会悟离线会议转记项目开发过程中,遇到的WebRTC VAD人声检测不准、流式ASR静音幻觉、音频分片错位、端侧推理卡顿四大问题进行深度复盘。结合Qwen-ASR离线流式模型、WebRTC VAD、FFmpeg音频处理技术,给出可落地的工程优化方案。通过防抖帧校验、静音阻断输入、固定分片时长、异步队列解耦等优化方式,大幅度提升离线转写的流畅度与准确率。本文所有方案均已落地生产,适合端侧离线ASR开发人员收藏参考。
二、项目背景与技术栈
2.1 业务背景
熙瑾会悟主打轻量化会议记录,其中离线转记是核心刚需。很多会议室、涉密场景无法联网,必须做到:断网可用、低延迟、人声识别干净、无多余杂音。
最初我对项目预估过于乐观,直接套用开源流式ASR模板,结果实测翻车严重。下面我直白讲一下开发真实遇到的痛点。
2.2 核心技术栈与模型选型
本次项目全部采用开源轻量化技术栈,适配低配终端设备,技术清单如下:
-
语音识别模型:通义千问 Qwen-ASR 离线流式模型,中文识别率高、支持增量流式推理、适合端侧部署。
-
人声检测VAD:WebRTC VAD,业界轻量型人声切分工具,占用CPU极低。
-
音频处理工具:FFmpeg,统一音频采样率、位深、声道格式。
-
架构设计:采集 → 预处理 → VAD检测 → 分片 → 异步推理 → 文本输出。
-
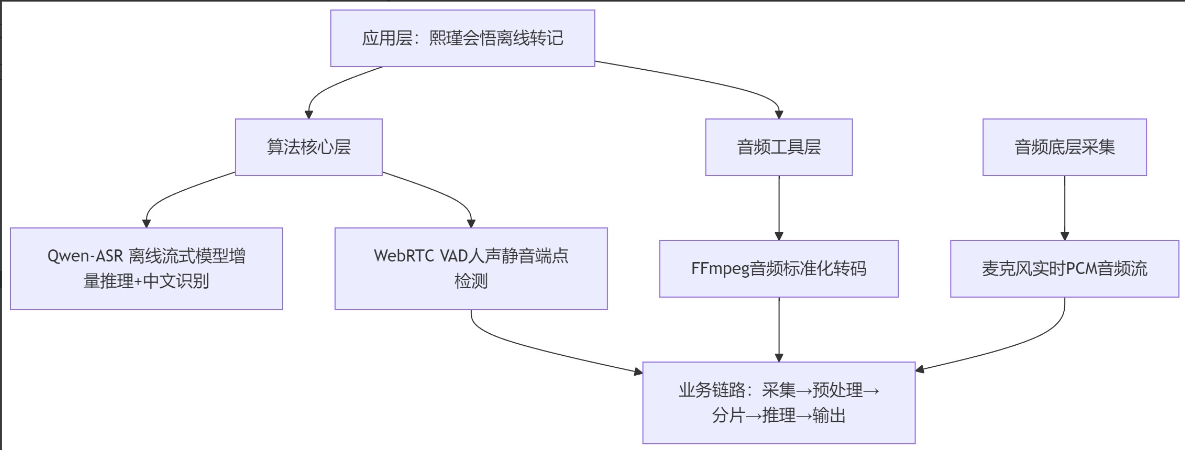
2.3 原始业务流程图(优化前)

三、开发过程遇到的核心问题
实话实说,一开始没做音频预处理优化,直接裸跑模型,问题暴露非常明显。
3.1 WebRTC VAD 误判严重
WebRTC原生默认参数非常粗糙,实测出现两种极端情况:
-
轻微环境噪音、键盘敲击声被判定为人声,大量无效音频送入ASR;
-
说话人短暂换气、停顿,直接判定静音,一句话被强行切分成好几段。
本质原因:原生VAD没有防抖机制,单帧判断结果不可靠。
3.2 流式ASR出现严重静音幻觉
我相信做过ASR的同行都遇到过:明明没人说话,模型凭空吐出乱码、重复语句、语气词。行业内称为静音幻觉。
排查后定位原因:静音段音频仍然持续送入模型,模型缓存残留导致随机生成文字。
3.3 音频分片不统一,出现吞字漏字
优化前我采用动态分片,人声长就多分、人声短就少分。结果出现:时间轴错乱、上下文拼接失败、部分语音帧丢失,转写严重断层。
3.4 低端设备推理阻塞、延迟堆积
早期代码为同步执行:采集→处理→推理串行执行。在低配终端上,CPU占用率飙升,音频流不断堆积,延迟最高达到5s以上,完全达不到会议实时记录标准。
四、工程级优化解决方案(重点)
4.1 VAD双层防抖过滤优化
放弃原生粗暴判定逻辑,我新增连续帧校验机制,也是本次优化最关键的一步。
-
固定音频帧:严格约束为16k、20ms、单声道PCM;
-
人声判定规则:连续5帧判定人声,才正式开启收音;
-
静音截断规则:连续8帧静音,才判定结束语音段;
-
敏感度调至中间档位,避免过于灵敏或过于迟钝。
优化之后,环境噪音过滤干净,自然停顿不会切断语句,效果肉眼可见。
4.2 静音阻断,彻底消除ASR幻觉
既然静音段会产生幻觉,最简单粗暴且有效的方案:静音区间禁止送入音频。
-
VAD判定持续静音 → 暂停ASR输入、清空模型临时缓存;
-
重新检测人声 → 恢复流式推送;
该改动极小,但直接根除静音幻觉问题,强烈建议所有流式ASR开发者照搬。
4.3 固定时间分片,对齐音频时间轴
废弃动态分片策略,全局统一300ms固定长度分片。无论是否停顿,都严格按照时间切片,保证送入模型的音频流时序绝对连贯。
改动之后,漏字、吞字、断句错乱问题基本清零。
5.4 生产者消费者队列,异步解耦
为了解决卡顿,我重构线程模型:
-
音频采集、VAD处理:生产者线程,不阻塞、不等待;
-
ASR推理:独立消费者线程,匀速拉取队列数据;
-
设置队列上限,防止内存溢出。
优化后低配设备CPU占用下降30%,延迟稳定在800ms以内,满足会议实时性要求。
五、最终优化架构图(可直接插图CSDN)


六、开发总结与个人感悟
做完本次熙瑾会悟离线转记优化,我最大的感悟就是:端侧离线ASR,算法永远不在于模型,而在于链路。
很多新手包括我一开始,都以为导入预训练模型就能直接商用。实际上VAD切分、音频标准化、分片策略、线程调度,每一个环节都决定最终效果。模型再好,预处理垃圾,输出一定垃圾。
给同行总结3条实用经验:
-
不要信任原生VAD,一定要做防抖+帧校验;
-
流式ASR必须做静音阻断,防止幻觉文本;
-
端侧务必异步解耦,不要串行同步推理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)