虚拟数字人项目心得
因为机缘巧合,参加了比赛,选择了这个赛题。因为我能力不足,这个项目给我出了很多难题,在这里做一个记录分享。
一.首次大框架梳理
1.1.题目需求大体分析
我们选的命题是基于 AI 大语言模型的情感陪护虚拟数字人系统,首先剖析题目要求。
要做一个大模型,能够为需要的群体提供情绪价值,还要做出一个3D或者2D的数字人形象同步语言输出。并且词错率和句错率有限制。在交的时候要打包dacker或者上传云端留个接口。明确规定只有大模型能够直接调用API,但是其他的,语音识别、数字人面部驱动需要将开源模型下载到本地部署并做一些微调。赛题还提供了一些数据,包括训练数据等。
这就需要,两个的大的模块。
1.1.1数字人外部表现
要有一个得体美观的2D或者3D的数字人形象,在聊天时要有语言输出,语言输出时不能卡顿,数字人的面部表情要自然贴合情绪,嘴部口型要和话语对应。要支持用户打字和语音的两种输入模式,要获得用户的摄像头和麦克风权限,根据用户的微表情和语言输出最合适的话。
1.1.2数字人内部大脑
主要是用户的情绪识别和数字人的温暖回应。通过用户表情、语言、语音语调来判断用户的情绪是伤心、开心、焦虑等等,并给出情绪分级,比如说悲伤三级。数字人根据心里数据库和大模型调用合适的话语作为回答,安抚用户情绪。
1.2技术路线分析
语言识别,通过用户的语音将其转成文字,接着调用大模型。这里的大模型不需要自己从头构建,我们可以调用现成的大模型,将它们部署到本地,也可以直接调用大模型的API进行使用。在大模型中我们要放入一些温暖语录等等。接着要驱动数字人,让数字人口型和输出话语一直,还要将数字人即将输出的文字合成一条语音,然后由数字人“说出来”。还要做情绪识别,能够从用户的输入语句中识别出用户情绪。
1.3小demo试验
遇到新的东西,先跑一边,保证完整性,接着再去优化细节和性能。因此先根据上面的技术路线将步骤搞清楚,搞明白,再优化细化项目。
1.3.1语音识别
和标题字面意思是一样的,将用户的语音转成文字。这一步的专业术语叫做ASR,自动语音识别。这里题目要求词错率和句错率都不能太高。我们直接先使用开源的模型,这里先用Whisper模型,因为是使用开源模型,第一次我直接将模型加载到本地,并没有调用API。
这里就是我第一个运行的结果,这里录一段音频,主要要存成.wav的格式。
1.3.2情绪识别
有了用户的语句输入,我们要通过文本识别出用户的情绪,为下一步大模型的安慰做准备。这里因为我们只是为了了解流程,想要先跑通这个小demo,因此我们还是使用开源的模型,并且直接加载到本地。

在代码运行过程中,出现了网络问题,因为要将模型下载部署到本地,但是国内网无法访问Hugging Face 的模型仓库并下载模型。这时我们就选择将模型先下载下来,然后让代码直接访问下载好的文件。
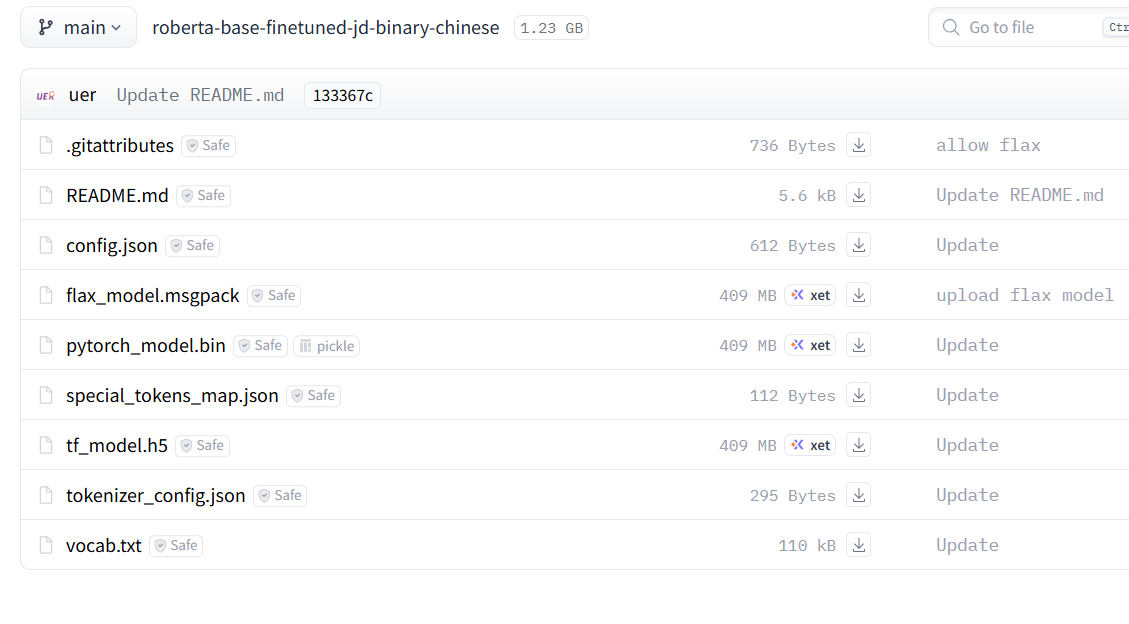
接着找到链接https://huggingface.co/uer/roberta-base-finetuned-jd-binary-chinese,就开始下载文件。一开始,本来是要下载config.json、pytorch_model.bin、tokenizer.json、tokenizer_config.json、vocab.txt这5个核心文件的,但是最后只下载了4个,因为没有找到tokenizer.json这个文件,但是因为已经下载了tokenizer_config.json 和 vocab.txt,这两个文件就已经足够完成分词,因此就不用在意。
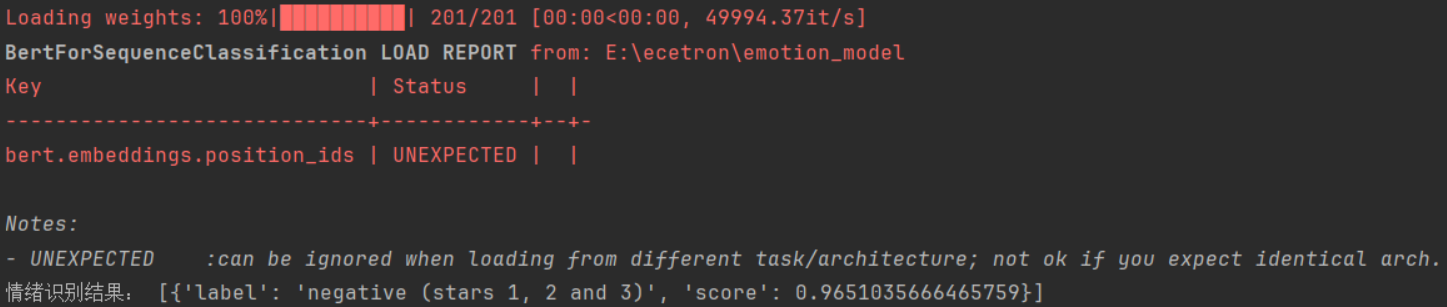
这样运行,果然成功了。虽然有UNEXPECTED提示,但是可以先忽略。在我们输入文本为“我今天心情很差,很焦虑”时,输出negative (stars 1, 2 and 3)表示这条文本是负面情绪,最后的score是置信度,达到了0.96多,效果已经算是很好了。
1.3.3大模型回复
判断好了用户当前的情绪,就可以调用大模型直接回复了。因为也有开源的模型,因此,直接想要部署到本地。这里我们使用的是Qwen-7B-Chat(阿里通义千问)。
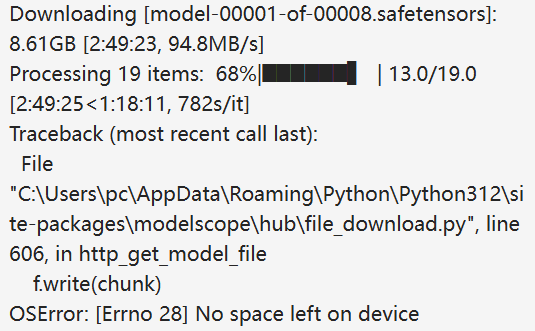
因为前面我直接部署到本地,因此就开始下载相关的文件,但是因为第一次部署大模型,我不知道原来不规定下载地址,就会直接下载到C盘。本来C盘东西就多,现在还没下载完,C盘就爆满了,磁盘空间不足,又报错了。于是我先是把前面已经下载到C盘的文件删掉了,接着规定了下载路径为E盘。

下载完成了,没有报错,但是在运行过程中,因为python和库,与大模型的版本不兼容,又报错了。因此我打开了Anaconda Prompt创建了新环境,在新环境中,下载了版本适配的库,并在提示面板运行代码。但是尽管如此,还是没有成功,仍然有不兼容问题。
更糟糕的是,当我试图再次运行我的有关情绪识别的代码时,我发现它也出现了版本不兼容的问题。这时我意识到环境出问题了,因此,我开始找问题。
环境问题:
为了搞明白到底是怎么回事,我先复盘了我的环境安装流程。我发现问题很多,因此我特意又开了一篇专门写这个,叫做“关于代码运行的环境污染与工具混淆问题总结”。这里我就不做过多说明了,感兴趣的同学可以去看那一篇。
这也让我知道,将大模型部署到本地有些困难,那么下次我将用API直接调用,虽然这里没有跑通,但是我们可以继续,这个demo主要是为了熟悉流程。
1.3.4 TTS语音合成
这步就是将大模型给出的回应用TTS合成,输出给用户。这次也是把需要的语音合成临时文件下载到本地,因为上次默认下载到了C盘,所以这次长记性了,直接给它下载到E盘。

这次也出现了版本问题,但是经过上次环境问题的深刻反思后,这已经不算问题了,很快就能够修复,最后保存到本地一个MP3的文件。
1.3.5 数字人驱动
有了语音回应之后,就是驱动数字人,让数字人的面部表情动作、口型,都和语音相符合。这一步就先不做了,因为前段时间调式导致进度有些缓慢,这个小demo我们就到这里。
二.已有数据分析
前面的梳理,让我们已经大体了解了项目的思路,现在开始研究手中已有的数据。对于主办方提供的数据,他们给了一个说明指南。因为数据量很大,并且种类也很多,因此对于数据的理解我也花了一些时间。

数据主要是这四个文件夹,每个文件夹里面又都有两个文件夹,对应两组数据集。我先是打开了每一个文件夹,看了数据类型,里面有视频,有音频,有npy文件等等,因为数据量太大,说实话我有点蒙。
想要理解每个文件夹的作用,还得返回到我们的技术路线分析。
刚开始,我对于项目的定位是,用户语音输入->ASR语音转文字->文本情感识别->LLM生成回复->TTS语音合成->数字人面部口型驱动。
在真正理解数据之前,我一直认为项目的核心重点在于ASR、LLM、TTS。但是提供的数据让我没办法应用到这三个地方去,也就是说,如果以这三块作为项目核心,主办方提供的数据我感觉用不到。于是,我发现我的项目定位有问题。
文件中的数据有参数、有视频、有音频,更像是要训练模型。最后,发现,项目的两大核心点,是情感识别和数字人面部驱动。
2.1原始数据解析
在细说之前,我们先来总的说一下这四个文件夹中都有什么。
Emotion文件夹中是面部情感特征数据。
3D_FV_files文件夹中是3D面部参数数据。
Audio_files文件夹中是语音音频数据。
video_files文件夹中是原始视频数据。
2.2情感识别
前面我的项目定位是文本情感识别,但是主办方想要的应该是多模态情感识别。也就是从文本、语音、视觉多个角度达到情感识别,因此就涉及到三个文件夹,分别是Emotion、Audio_files、video_files,也就呼应了我们多模态的这个概念。
2.3数字人驱动
前期,我对于数字人驱动,没有一个很具象化的理解,知道看到数据集。数据集中有面部参数数据,这58维的特征数据,就是驱动数字人面部的关键。可以形象化的理解一下,这58维特征用来调动数字人面部每一块肌肉,以让它做出合适的表情。
三.再次大框架梳理
3.1反思总结
因为前面通过看数据集,发现我对于项目的理解有很多地方不完善,因此在下次项目中,如果有数据集,应该题目解读和数据集同步进行,防止理解不到位。
3.2再试demo
这次我们修改完善了思路,也有了第一次小demo的错误经验,我们再来跑一下。
3.2.1流程整体梳理

将这个项目分解成六个模块。其实大体流程就是,用户输入->模型推理->数字人输出。细分的话就是六块,其中模块2和模块5就是核心模块,需要模型训练。模块3需要自建心理数据库。其他的ASR、TTS、LLM,都不用自建,有开源模型。
自建心理数据库:
这里是配合LLM使用的,主要就是给LLM一个限制,让大模型的回复更加人性化,更能让人感受到温暖,回应不再是一些万能话术,而是更贴切的话语。
3.2.2demo运行感受
比起理论梳理,代码运行调式更能让我理清思路,因此我打算先试跑,再梳理。
为了防止出现上次版本不兼容问题,我们先创建一个新环境,叫做mydemo。这里就是,当你在命令行需要输入“y”时,就是要创建成功了,成功后先激活。

这里从base变成mydemo就是激活成功了。接下来就可以安装需要的所有库了。看了我的另一篇文章的同学们就知道,这里用pip和conda命令都可以。
库安装好之后,一定要将我们的环境切换到自建环境。
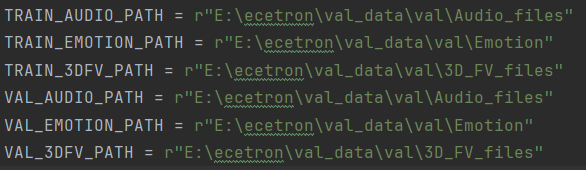
接着我们将文件路径都放到一起,因为数据太多,这样后续修改也方便。
然后定义我们的两个核心模型,情感识别模型和数字人驱动模型。然后生成我们的心理数据库。接着定义LLM、TTS、数字人渲染。并且根据主办方要求,给出ASR测试接口。
很不幸的是,在这次代码运行的过程中,虽然我一直在有意的规避第一次运行出现过的错误,但是还是出现了阻力。自建环境的python版本过高,出现库安装的各种问题。甚至出现了返工情况,将所有环境清理掉重新来过。
但是这种库和自建环境中python版本冲突的问题,很难提前避免,能想到的最好办法就是把要安装的库所匹配的python环境查清楚,因此请同学们不要气馁。
人生不就是白干加白干,在经历过返工之后,环境的问题终于解决了,代码开始正常运行。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)