ArXiv 2507 | Franca: Nested Matryoshka Clustering for Scalable Visual Representation Learning

计算机视觉领域的视觉基础模型正处于神仙打架的阶段。例如 DINOv2, SEER, billion-scale MAE, and SigLIP 2 展示了强大的特征提取能力。但这些顶级模型都**严重依赖海量的闭源专有数据,且往往不公开关键或完整的训练代码和中间权重。**这种“黑盒”状态让开源社区无法复现,无法剔除数据偏差,更无法知道模型强大的真正原因到底是算法好,还是仅仅因为数据多。
本文提出了 Franca(发音 Fran-ka,意为“自由的”)不仅在模型权重、训练代码和训练数据(纯公开的 LAION 和 ImageNet)上实现了 100% 完全开源,更在多项任务上超越了 DINOv2-G。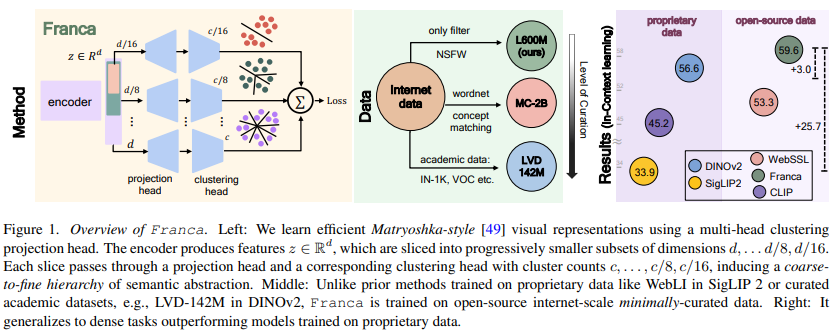
Franca 能够做到“花小钱办大事”,并没有依靠暴力的算力堆叠,而是凭借其在自监督学习(SSL)算法底层的三层设计:嵌套套娃聚类(Nested Matryoshka Clustering)、绝对空间属性剥离(RASA)以及循环掩码(CyclicMask)。

预备知识
Franca本身架构延续DINOv2的设计,没有registers、没有蒸馏直接预训练。
Franca 采用了 DINO 的多裁剪(multi-crop)训练策略。
- 输入图像被转换为多个增强视图(全局和局部裁剪)。
- 每个视图 x x x 被分割成 n n n 个互不重叠的 patch,这些被嵌入到 R d \mathbb{R}^d Rd 空间中,并在序列最前方附加一个分类标记 [CLS] ∈ R d \in \mathbb{R}^d ∈Rd 以构成输入序列。
- 视觉骨干ViT处理该序列,生成 n + 1 n+1 n+1 个嵌入( n n n 个patch嵌入和一个 [CLS] 嵌入)。
整体基于均值教师的方案训练。学生网络 f θ f_\theta fθ 和教师网络 f θ ˉ f_{\bar{\theta}} fθˉ 共享相同的 ViT 架构,分别产生 Z s = f θ ( x ) ∈ R ( n + 1 ) × d Z_s = f_\theta(x) \in \mathbb{R}^{(n+1) \times d} Zs=fθ(x)∈R(n+1)×d 和 Z t = f θ ˉ ( x ) ∈ R ( n + 1 ) × d Z_t = f_{\bar{\theta}}(x) \in \mathbb{R}^{(n+1) \times d} Zt=fθˉ(x)∈R(n+1)×d,其中 Z s Z_s Zs 代表学生的输出嵌入, Z t Z_t Zt 代表教师的嵌入。教师网络的参数 θ ˉ \bar{\theta} θˉ 通过学生网络参数的指数移动平均(EMA)进行更新。
为了进行监督学习,投影头(projection heads)用于学生特征嵌入 Z s Z_s Zs。
- [CLS] 嵌入通过一个 DINO 风格的投影头(一个包含在原型上计算 softmax 的三层 MLP)处理,产生图像级别的原型分数。
- patch 嵌入则由一个 iBOT 风格的投影头处理,产生patch级别的原型分数。为简便起见,学生网络和教师网络的这两个投影头分别记作 h θ h_\theta hθ 和 h θ ˉ h_{\bar{\theta}} hθˉ(两者架构相同,教师端通过 EMA 更新)。
- 教师网络的投影输出使用 Sinkhorn-Knopp 算法 (Sinkhorn distances: Lightspeed computation
of optimal transport) 进行聚类,从而生成平衡的目标分布。 - 学生网络通过交叉熵损失(记为 L \mathcal{L} L)进行训练,以匹配这些目标分布。
Franca论文将聚类和掩码图像建模结合,核心在于用聚类算法充当MIM的“语义字典”,让模型预测被掩盖区域的聚类类别而非还原底层RGB像素。具体流程:
- 教师网络首先接收完整图像,利用多头套娃聚类器和Sinkhorn-Knopp算法为每个图像块生成拥有上帝视角的“高级语义答案”(软伪标签);
- 学生网络接收经过CyclicMask循环掩码处理的残缺图像,通过观察可见上下文来进行MIM“完形填空”。与传统MAE不同,学生网络在此输出的是聚类概率分布,并与教师预测的真实分布计算交叉熵损失,这有效避免了模型将算力浪费在重构草地纹理、水面波纹等无意义的底层细节上,迫使其真正从逻辑上理解诸如“车头与车尾之间是车身”的高级抽象语义。
框架将MIM作为逼迫模型看局部猜整体的“任务形式”,将聚类作为剥离底层细节的“目标内容”,再辅以套娃聚类带来的多粒度语义和循环掩码对空间连续性的打破,成功通过这种极度困难的预测逼出了模型极其强大表征能力。
预训练聚类的语义模糊性
像 DINOv2 这样的主流自监督模型,其核心思想是“聚类”:让模型自己把长得像的图片分到一组(伪标签)。但在高维空间(比如 1024 维)中进行聚类,存在一个致命的语义模糊性难题: 假设有一张“红色丰田卡罗拉”的照片,它到底应该和“红色法拉利”(颜色相似)聚在一起,还是和“白色卡罗拉”(品牌相似)聚在一起? 如果聚类的维度和簇(Cluster)的数量是固定的,模型就只能在某一个固定的粒度上学习,要么只能学到宏观的轮廓,要么只能死抠微观的纹理。
Franca 的采用了嵌套套娃聚类 (Nested Matryoshka Clustering)的方案。既然不知道哪个粒度好,那我就全都要,并且把它们像“俄罗斯套娃”一样嵌套起来:
- 物理切片与“维度-簇数”双重递减。Franca 不去增加额外的网络层,而是直接对 ViT 输出的 1024 维特征向量进行物理切片,整体损失使用所有嵌套头的整体等权重加和得到:
- 最低维切片(如前 64 维):分配一个极少簇数(如 c / 16 c/16 c/16)的聚类头。
- 中等维切片(如前 128 维):分配一个中等簇数(如 c / 8 c/8 c/8)的聚类头。
- 全维度(1024 维):分配一个海量簇数(如 c c c)的聚类头。
- 无监督下的“层级涌现”真相:SK 算法与过度聚类。全都是无标签图像,模型怎么知道什么是宏观,什么是微观? 这得益于过度聚类 (Overclustering) 与 Sinkhorn-Knopp (SK) 算法的效果。在现代 SSL 中,簇(Cluster)并不是算出来的平均值,而是高维超球面上的可学习的锚点方向(Prototypes)。为了捕捉细微特征,会把总簇数设得极大(比如 6.5 万个)。SK 算法是一个“铁面无私的裁判”,它的唯一任务是施加均分约束:强迫一个 Batch 内的所有图像,必须尽可能均匀地分配给所有可用的簇,不准模型偷懒(把所有图塞进一个簇)。
- 当这两者与套娃设计结合时:
- 对于低维部分(对应 4096 个簇):因为簇少,为了完成 SK 算法的均分任务,模型被迫只能去抓取最宏观的特征(比如区分“室内”、“动物”、“车辆”)。
- 对于完整维度(对应 65536 个簇):因为簇极多,模型拥有了充足的容量,自然会去细分微观纹理(比如区分“柴犬”和“柯基”)。
- 由于低维向量物理上就包含在高维向量的最前面,这种联合训练强迫模型将最核心、最宏观的全局语义压缩在特征的头部,而将细节纹理排布在特征的尾部。一颗“从宏观到微观”的语义决策树,就这样在没有任何人工标签的情况下,自发地“涌现”出来。
- 当这两者与套娃设计结合时:
标准的套娃(Matryoshka)方法(Matryoshka representation learning)沿着特征维度对整个编码器的输出进行切片,并对每个子嵌入应用相同的投影头。相比之下,Franca 保持骨干网络不变,并通过为每个子空间附加专用的投影头和聚类目标来扩展这一设置。这允许每个切片产生不同的原型和原型分配,从而在整个训练步骤中鼓励特征在不同表示粒度上的专业化。
Franca 框架支持层次化学习:粗粒度的投影头捕获全局语义,而细粒度的投影头则专注于局部结构,这类似于早期的聚类研究,而不同于大多数仅优化单一特征空间的近期表示学习研究。
从图3中可以看到,Franca不同维度特征的PCA可视化展现出了一致的部件结构。
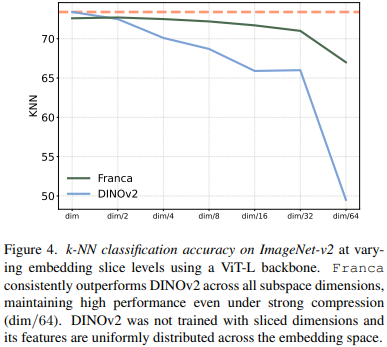
从图4中可以看到,Franca在不同嵌入维度上,超越了DINOv2的表现。不过这里也需要注意一点,就是DINOv2并没有为维度截断来训练,其中的信息均匀扩散在特征空间中。
对高范数 token 的抑制作用
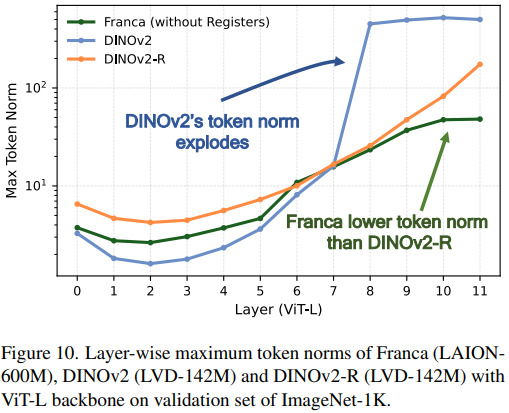
值得注意的是,Franca的嵌套的套娃聚类这种多尺度语义结构本身有效的缓解了特征伪影(DINOv2中存在一些高范数的异常token)。从途中的分析可以看到,Franca甚至比试用了register token的 DINO-R的token范数还要低,所以对于Franca而言,添加register意义不大,部分实验展示还会降低性能。
register token本身主要促进DINOv2的密集预测表现,而不会改善分类性能。
预训练掩码策略的局部惰性

掩码图像建模(MIM)是当前许多自监督视觉框架的核心组件。其中会将部分输入patch屏蔽掉,来让模型学习去预测内容。常用的可能是随机掩码和块掩码。尽管简单且随机,但是往往会导致视觉区域变得零碎,只提供有限的上下文连贯性,例如图5的a和b所展示的。另外常规的块状掩码容易导致可见补丁集中在某个角落,模型不用去理解语义,光靠“补全边缘”就能混过去。

所以Franca采用了循环掩码 (CyclicMask)方案。这里提出了一种极其简单的巧思:在生成常规块状掩码后,在 X 轴和 Y 轴上进行循环平移 (Circular Shift / torch.roll)。 原本在左上角的可见块,被切成两半,分别循环移动到了图像的右下角和左下角。这种空间上被彻底打碎、但逻辑上仍保持连贯的掩码策略,使得模型无法再依靠“这里是图像边界”的作弊手段,它被逼着去深度理解散落在各处的纹理和语义片段。
预训练特征的空间纠缠
作者们通过对ViT模型patch embedding进行聚类从而揭示了当前ViT模型(如DINOv2)在特征学习中的一种隐蔽缺陷,即在处理密集特征时,往往会将图像的“绝对位置”与“语义内容”错误地纠缠在一起:ViT models often develop unintended spatial biases from their fixed patch layouts and positional embeddings, entangling location with semantic content.
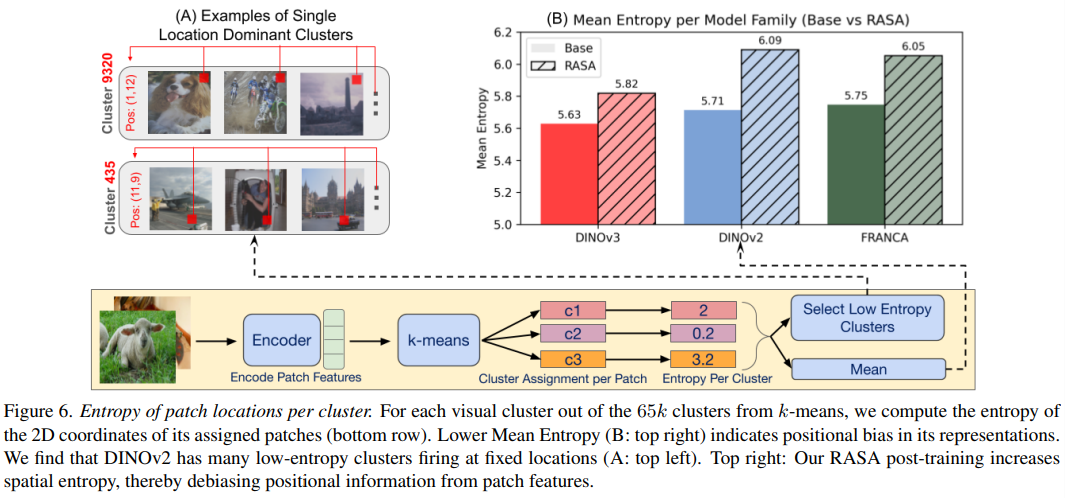
图中试验针对冻结模型的token 嵌入进行聚类分析。通过计算每个聚类簇中图像块来源坐标的“空间熵”,发现某些特定的簇(如Cluster 9320和435)空间熵极低,这意味着它们无论面对狗、飞机还是建筑,都只对图像的固定位置(如右上角或正下方)有反应,说明模型在“偷懒”,把这些特征变成了纯粹的“位置探测器”而非真正的语义识别器。
为了解决这一痛点,作者引入了 RASA (Removal of Absolute Spatial Attributes)。B图展示了在应用RASA之后,各个模型(包括DINOv3、DINOv2和Franca)的平均空间熵均出现了显著上升。这证实了RASA成功剔除了特征向量中的绝对位置信息,彻底打破了位置与语义的纠缠,迫使模型停止“走捷径”,去学习真正纯粹且泛化能力更强的视觉语义。
RASA 提供了一个零推理成本 (Zero Inference Overhead) 的纯线性代数解决方案。
- 定位位置子空间 首先,冻结预训练模型,用少量图像(大概10K)训练一个极轻量的线性探测器 W ∈ R 2 × d W \in \mathbb{R}^{2 \times d} W∈R2×d。用patch i i i的嵌入 Z i Z_i Zi ,通过sigmoid去预测它在图像中的归一化patch坐标,并通过MSE损失约束。这个探测器的两行权重向量,在 d d d 维空间中张成了一个二维平面。这个平面的物理意义是:在这个平面内的任何变化,都只代表纯粹的空间位置变化,不包含任何语义变化。
- 提取正交基 (使用 Gram-Schmidt 正交化方法) 为了进行严谨的数学投影,需要将这两行权重提取为标准正交基 u r u_r ur 和 u c u_c uc。 尽管求解正交基有 SVD、Householder 等诸多方法,但 Franca 选择的是最朴素的 GS 正交化。因为这里的权重只有 2 行。在仅处理两个向量时,GS 方法只需要进行一次简单的减法,不仅避开了大规模矩阵带来的浮点误差累积,更是确保了计算效率
- 正交投影与特征剥离。
- 对于任何一个特征向量 Z i Z_i Zi,计算它在 u r u_r ur 和 u c u_c uc 上的投影 p i p_i pi,这个 p i p_i pi 就是特征中纯粹代表坐标的“杂质分量”: p i = ⟨ Z i , u r ⟩ u r + ⟨ Z i , u c ⟩ u c p_i = \langle Z_i, u_r \rangle u_r + \langle Z_i, u_c \rangle u_c pi=⟨Zi,ur⟩ur+⟨Zi,uc⟩uc
- 我们直接用原特征减去它: Z i ( n e w ) = Z i − p i Z_i^{(new)} = Z_i - p_i Zi(new)=Zi−pi
- 根据几何原理, Z i ( n e w ) Z_i^{(new)} Zi(new) 必定垂直于位置子空间,线性分类器再也无法从中读出任何位置信息。特征被纯化。
- 多轮迭代到矩阵吸收。
- 由于位置偏差在神经网络中往往是深层交织的,第一轮剥离可能只会去除最明显的绝对位置信息。因此,RASA 会像“剥洋葱”一样进行多轮迭代(论文表明约 8 轮收敛),每轮都会生成一个新的正交投影变换矩阵 L ( t ) L^{(t)} L(t),连续迭代之后,可以有效移除线性可预测的空间偏置并保留语义内容。具体的推导过程如下:
- 第 1 轮剥离后:特征变为 Z ( 1 ) = L ( 1 ) ⋅ Z Z^{(1)} = L^{(1)} \cdot Z Z(1)=L(1)⋅Z
- 第 2 轮剥离后:在更新后的特征上继续剥离残存位置信息,即 Z ( 2 ) = L ( 2 ) ⋅ Z ( 1 ) = L ( 2 ) ⋅ ( L ( 1 ) ⋅ Z ) Z^{(2)} = L^{(2)} \cdot Z^{(1)} = L^{(2)} \cdot (L^{(1)} \cdot Z) Z(2)=L(2)⋅Z(1)=L(2)⋅(L(1)⋅Z)
- 第 3 轮剥离后:同理可得 Z ( 3 ) = L ( 3 ) ⋅ Z ( 2 ) = L ( 3 ) ⋅ ( L ( 2 ) ⋅ L ( 1 ) ⋅ Z ) Z^{(3)} = L^{(3)} \cdot Z^{(2)} = L^{(3)} \cdot (L^{(2)} \cdot L^{(1)} \cdot Z) Z(3)=L(3)⋅Z(2)=L(3)⋅(L(2)⋅L(1)⋅Z)
- 如果在模型推理时每次都跑 T T T 轮矩阵乘法,将会极大拖慢速度。由于矩阵乘法满足结合律,可以改变运算顺序,先将所有 T T T 轮的投影矩阵提前累乘,融合成一个单一的最终矩阵 L f i n a l L_{final} Lfinal,有了这个最终矩阵,经过 T T T 轮迭代后的纯净特征就可以直接一次性计算: Z ( T ) = L f i n a l ⋅ Z Z^{(T)} = L_{final} \cdot Z Z(T)=Lfinal⋅Z:
L f i n a l = L ( T ) ⋅ L ( T − 1 ) ⋯ L ( 2 ) ⋅ L ( 1 ) = ∏ t = 1 T L ( t ) L_{final} = L^{(T)} \cdot L^{(T-1)} \cdots L^{(2)} \cdot L^{(1)} = \prod_{t=1}^{T} L^{(t)} Lfinal=L(T)⋅L(T−1)⋯L(2)⋅L(1)=t=1∏TL(t) - 因为 ViT 的最后一层本身就是一个线性权重矩阵 W v i t W_{vit} Wvit,在部署模型前,直接在内存中把这个剥离位置属性的矩阵 L f i n a l L_{final} Lfinal 吸收进模型原本权重。在线上推理时,模型不需要增加任何一层网络,没有任何额外的计算开销,就直接拥有了剔除空间偏差的超能力: W n e w = L f i n a l ⋅ W v i t W_{new} = L_{final} \cdot W_{vit} Wnew=Lfinal⋅Wvit。
- 由于位置偏差在神经网络中往往是深层交织的,第一轮剥离可能只会去除最明显的绝对位置信息。因此,RASA 会像“剥洋葱”一样进行多轮迭代(论文表明约 8 轮收敛),每轮都会生成一个新的正交投影变换矩阵 L ( t ) L^{(t)} L(t),连续迭代之后,可以有效移除线性可预测的空间偏置并保留语义内容。具体的推导过程如下:
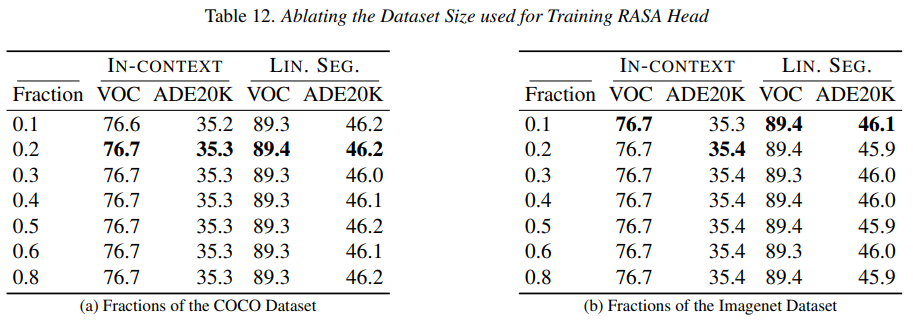
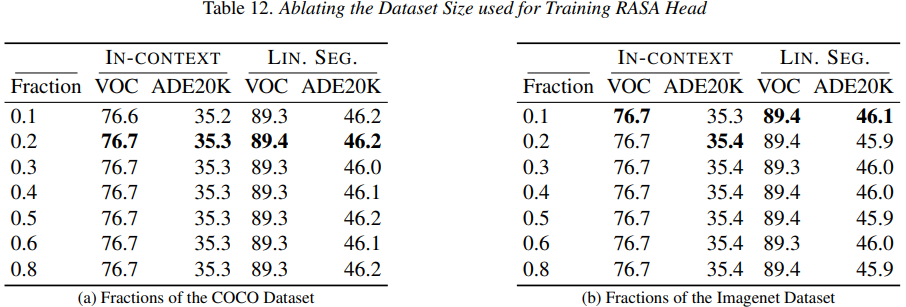
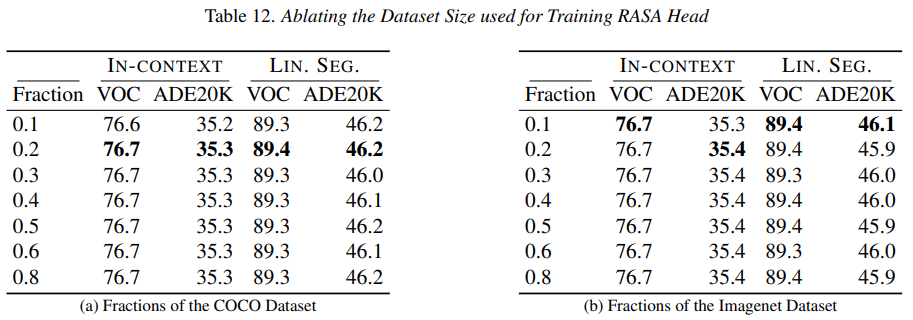
这里基于COCO和ImageNEt-100的实验证明了两个关键点:
- 训练 RASA 头的数据效率极高:大约 1 万张图像就足以实现强大的特征解耦。
- 数据集的类型——COCO(偏向场景)与 IMAGENET100(偏向物体)——并不会对下游任务的性能产生实质性影响。
这表明,RASA 在很大程度上不受训练数据分布语义偏差的影响,并且仅需极少的数据即可进行可靠的训练。基于这些观察,作者们采用 PASCAL VOC 作为训练 RASA 头的默认选择,因为它不仅体量小巧,而且足以达到最佳性能。
在这种设置下,在多个基准测试中都取得了强劲的结果(表 13)。这证实了,像 Pascal VOC 这样的轻量级数据集完全足以进行有效的训练,同时还能在各种不同任务上保持极具竞争力的性能。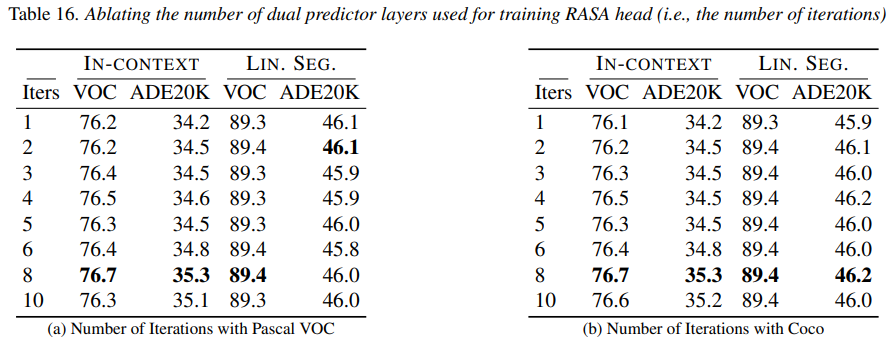
实验结果
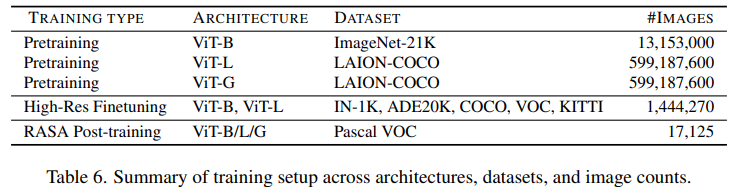
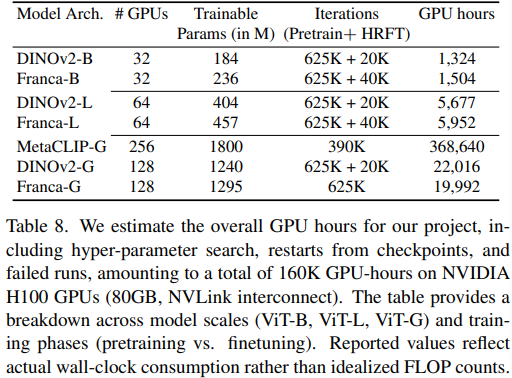
数据规模和训练规模
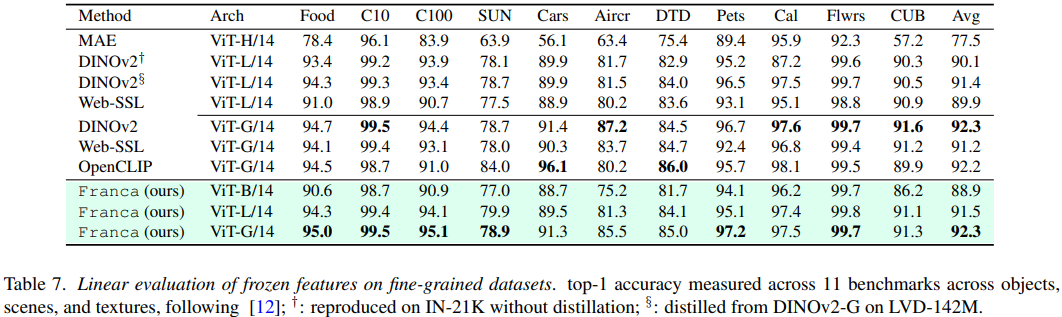
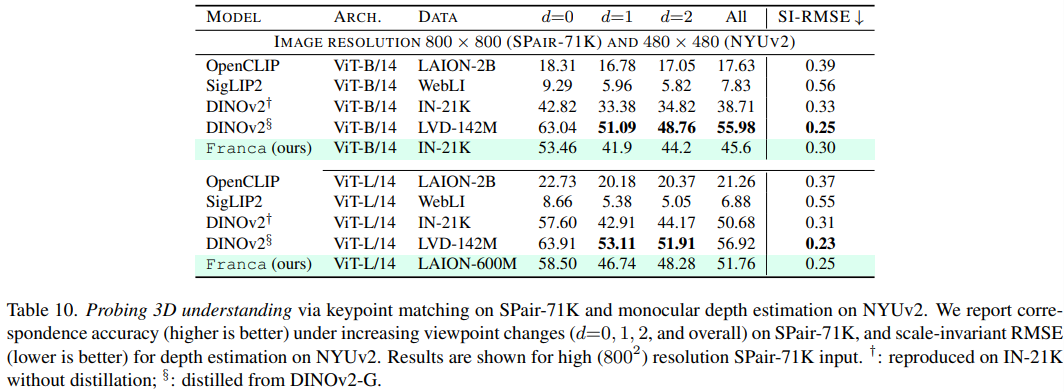
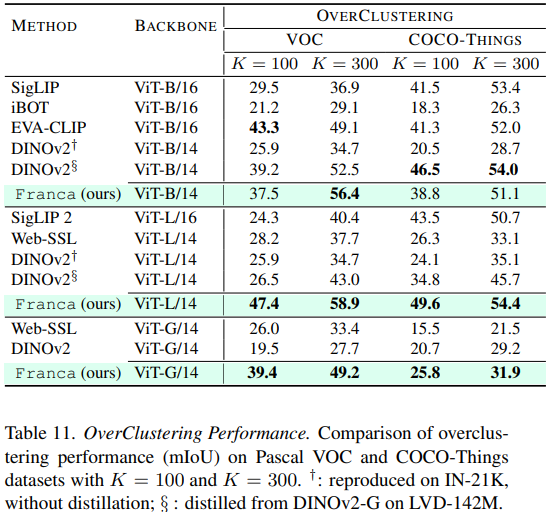
下游表现
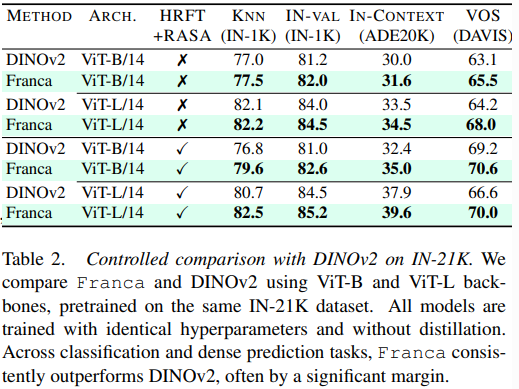
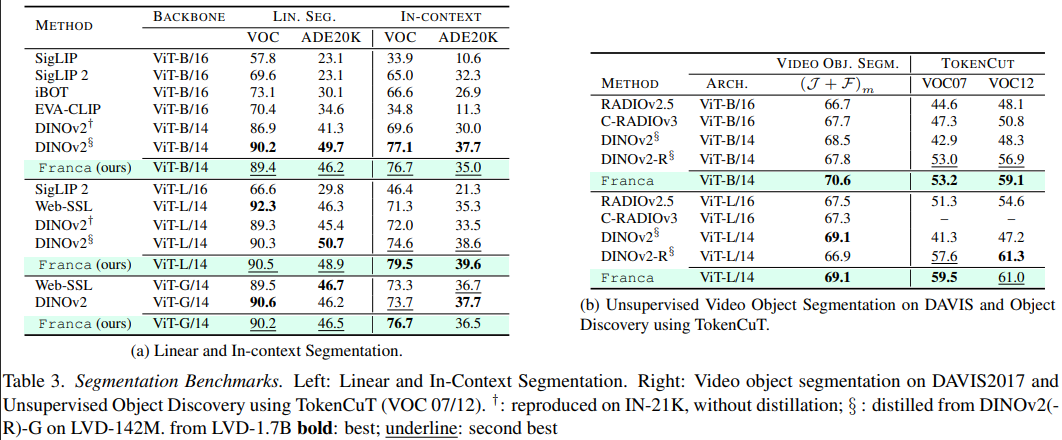
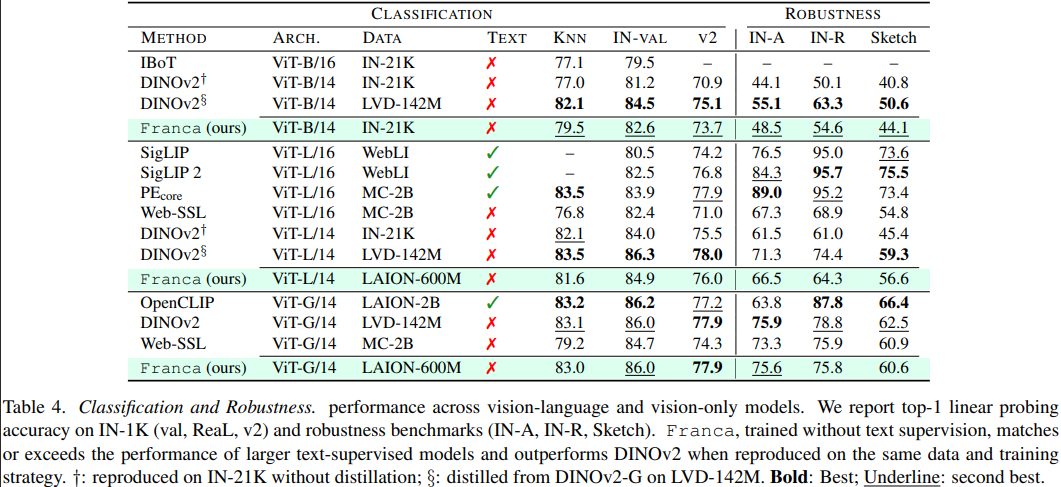
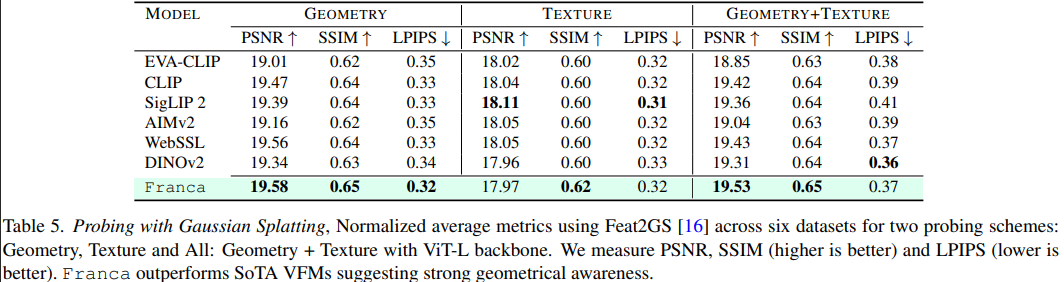
小结
通过嵌套套娃聚类、RASA 和 CyclicMask,Franca 在完全不使用知识蒸馏(无需庞大的 Teacher 模型带着跑)、完全使用开源数据的情况下,其 ViT-B 和 ViT-L 版本在语义分割、视频目标追踪、零样本分类等任务上,全面超越甚至碾压同期专有数据模型。这也证明了在算力与数据的暴力美学之外,对底层数学原理的洞察(如 RASA 的矩阵吸收)和对信息论的巧妙运用(如套娃聚类的多粒度绑定),依然是推动发展的重要视角。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)