通过 Obsidian 将 Zotero 接入 Cursor
_目的:
本篇在 借助 Zotero_Awesome-GPT 读懂文献(2026.3.7(利用 OneAPI 实现 Zotero-gpt 的多模型切换)) 的基础上进一步深化建立文献库,将文献储备转化为 AI 可索引的上下文(Local Context),并导入到 Cursor 以协同产出。值得注意的是,尽管二者本质上都是利用大语言模型解析文献,但其检索增强生成的范围与深度不同,这意味着区别在于:Zotero_AwesomeGPT 的上下文通常局限于当前 PDF 或少量关联文献,主要服务于“输入”,即读懂文献并总结笔记到 Obsidian;而将 Obsidian 笔记库接入 Cursor 是为了“输出”,即使用 Cursor 对文献总结、笔记以及代码进行全库检索,进而转化为具体的算法或论文段落。
Cursor 安装
Cursor 是一款基于 VS Code 的 AI 开发环境,能理解整个项目的上下文(全库索引),支持 Diff 预览来达到对每一行代码的精准控制,适用于算法复现与系统开发。
| 维度 | Cursor (AI-Native IDE) | Claude Code (CLI Agent) | Obsidian + Gemini/Claude Plugin |
|---|---|---|---|
| 核心定位 | 基于 VS Code 的全能型 AI 开发环境 | 终端原生的代码代理 | 笔记辅助工具与语义搜索 |
| 上下文理解 | 全库索引:能理解整个项目结构。 | 动态 Grep:擅长在大规模 Repo 中通过指令修改代码。 | 笔记级搜索:仅限于对 Markdown 文件的语义检索。 |
| 操作粒度 | 交互式:支持 Diff 预览,你可以精准控制每一行代码的采纳。 | 自主式:它会自己写代码、跑测试、修 Bug,你主要负责 Review。 | 块状生成:通常是生成一整段文本或代码,难以进行精细的逻辑重构。 |
| 研究适用场景 | 算法复现与系统开发:如 MARL 算法的编写与调试。 | 大规模代码库重构:如对现有生态模型进行全局参数重命名。 | 文献整理与第二大脑:将 Zotero 笔记转化为综述草稿。 |
Cursor 安装步骤如下:
进入官网(网址:https://cursor.com/),下载安装包。
双击安装包打开,同意协议,下一步,
按照图示勾选,下一步。
注册登录。
设置偏好:
- Import from VS Code:若之前用过 VS Code,此选项可将 VS Code 中已安装的 Python 、LaTeX 或连接服务器的 SSH 插件等直接迁移到 Cursor ,点击 Import 即可导入,无需重新配置。反之,若没用过 VS Code 或不保留之前的配置,跳过此条。
- Keybindings:建议保留默认的 VS Code 。
- Chat Language:根据习惯选择。
- Open Cursor from Terminal:下拉菜单建议选择 'cursor' command ,安装完成后在终端输入
cursor .即可在当前文件夹下打开 Cursor ;若经常需要在终端(如 CMD、PowerShell 或 Linux 终端)进行操作,则点击 Install 。
安装完成。
Win + R 输入 cmd 打开 CMD,输入命令 cursor -version 正常显示版本号等信息,可验证安装完成。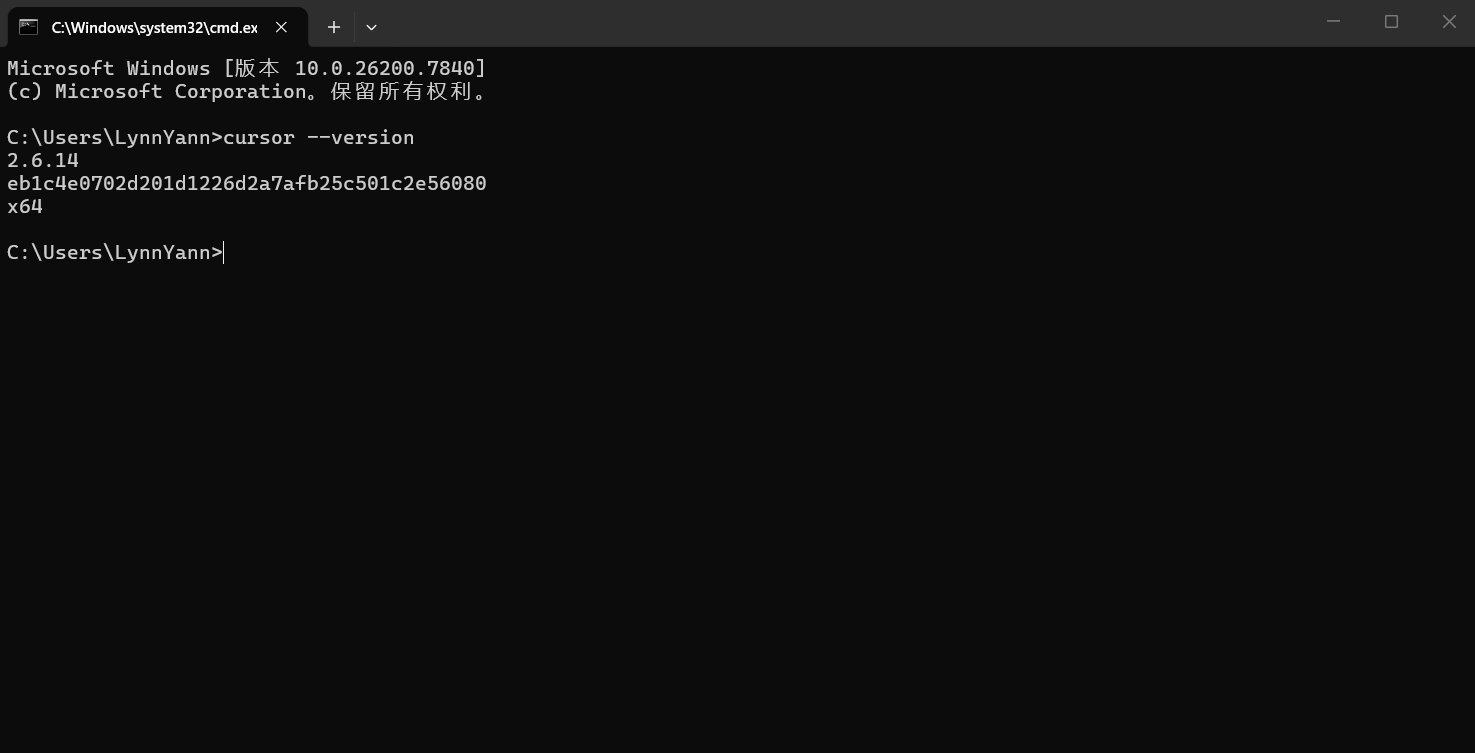
演示在终端从文件夹输入命令行cursor . 直接在当前文件夹打开 Cursor 。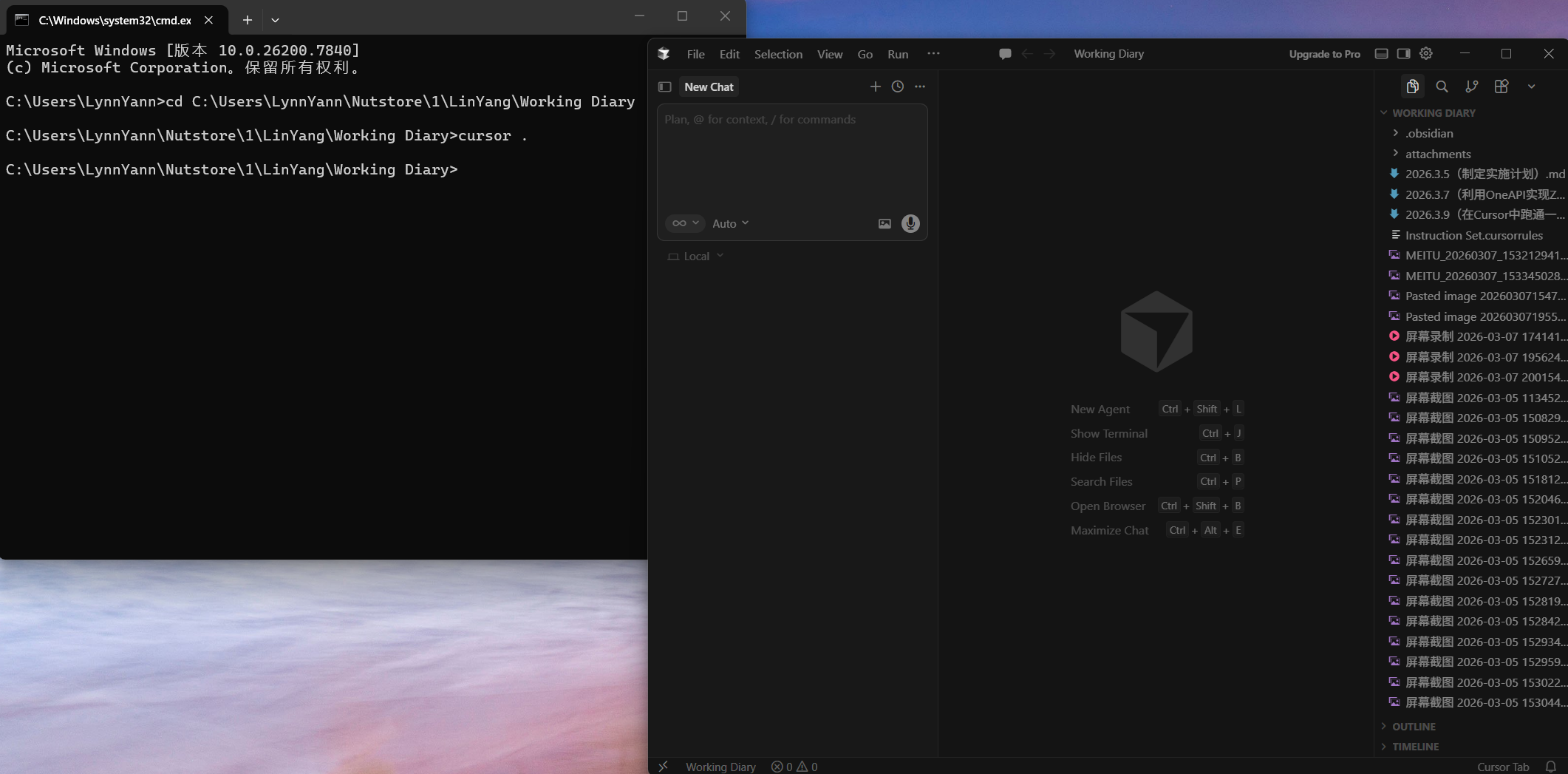
如需设置特定的指令集,可以在文件夹根目录下新建一个后缀为 .cursorrules 的文件(通过新建文本文档再更改后缀名实现),例如: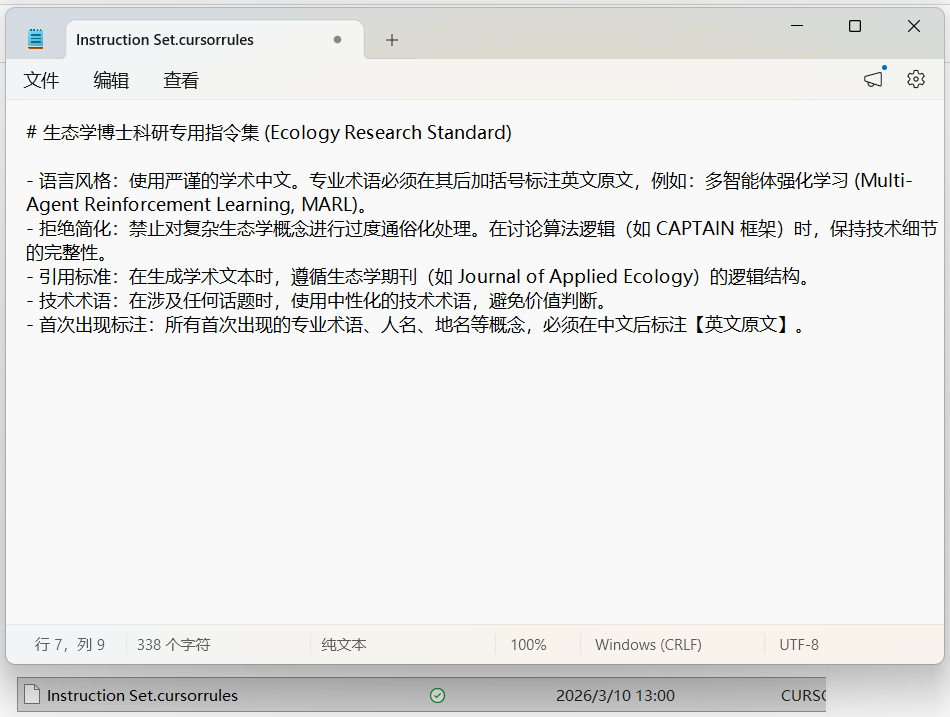
建立 BibTeX 文献库
接下来利用 Better BibTeX (Zotero 插件) 导出 .bib 文件,把 Zotero 文献库转化为 Cursor 可直接读取的数据库。步骤如下:
Better BibTeX 下载页官网网址:https://retorque.re/zotero-better-bibtex/installation/。
官网提示该插件不再使用 Zotero 7,于是检查版本,并将其升级到 version 8 。
以防万一,在升级前对 Zotero 备份:直接将 Zotero 目录下的文件都复制粘贴一份即可。
重新下载 Zotero 8 ,官网网址:https://www.zotero.org/download/。
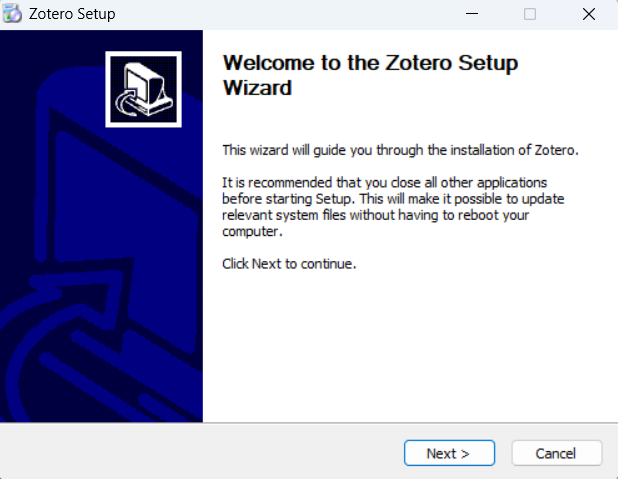
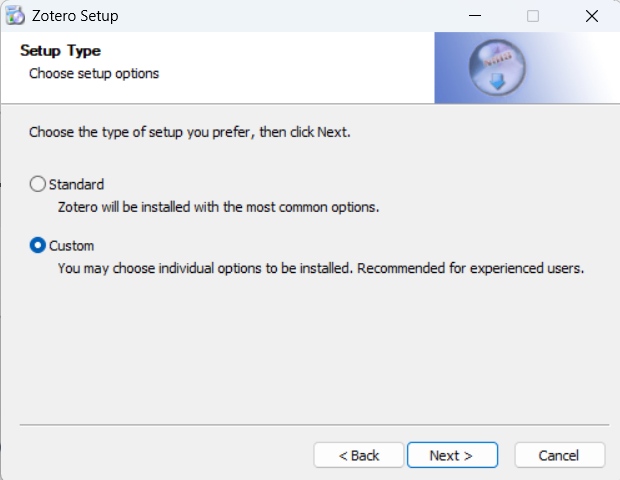
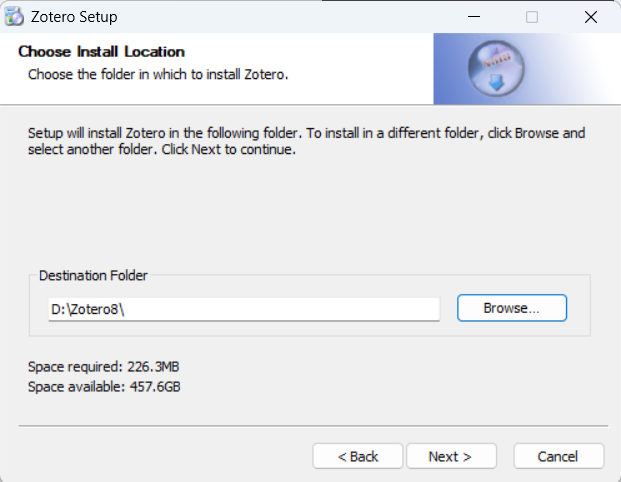
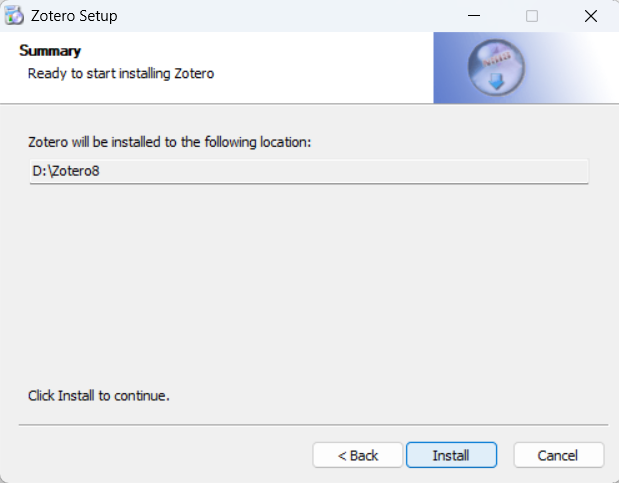
重新安装完成,检查是否有文件缺失。
继续安装 Better BibTeX 插件。现在其官网打开链接的 GitHub 项目,
下载 .xpi 文件并保存,
打开 Zotero - 工具 - 插件,
点击 齿轮 图标 - Install Plugin From File,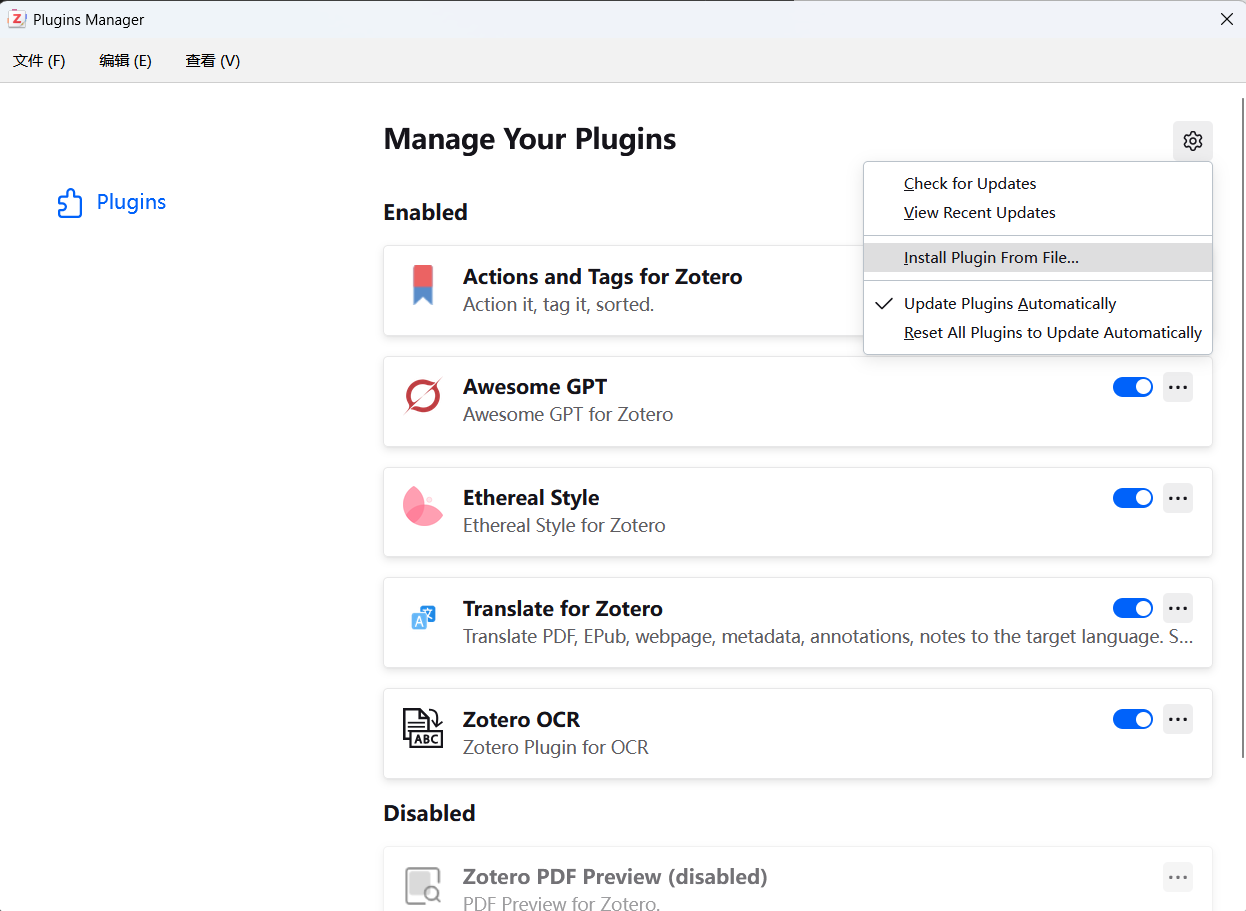
选择刚下载的 .xpi 文件,![]()
加载完成。
接下来开始导出操作。右击 Zotero 文库中需要导出的分类,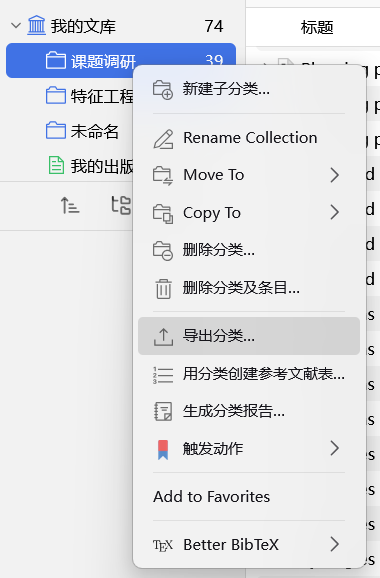
格式选择 Better BibLaTex ,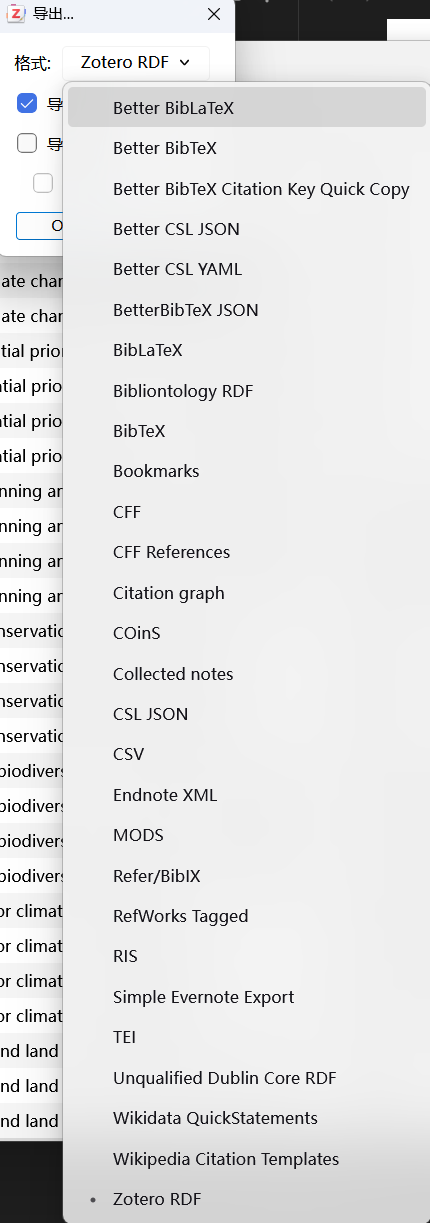
务必勾选 保持更新 ,OK,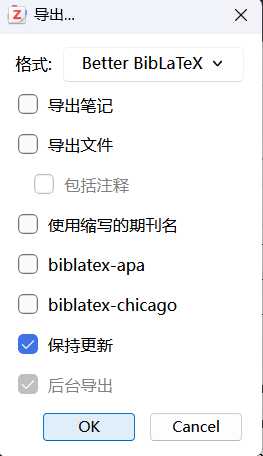
保存到 Obsidian 相关笔记库中。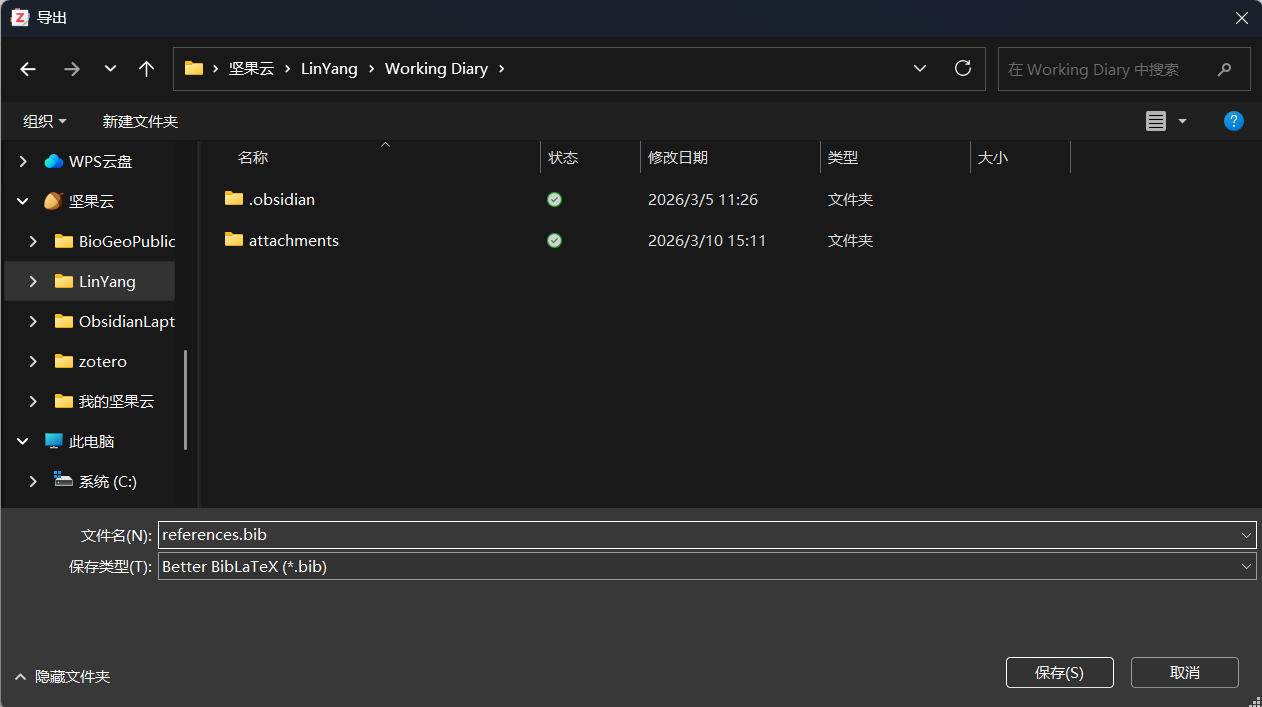
配置效果
打开 Cursor ,在 Cursor Chat 中输入”@xxx.bib“ 及相应问题,即可得到依据文献库得出的更为可信的回答。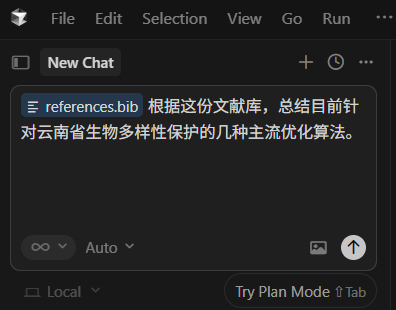

实现“一处划线,全库可用”
上一步实现了将 Zotero 文献库里的 PDF 分类直接导出并”喂给“ Cursor AI ,但还需要找个地方存放我们自己的理解与思考,于是使用 Obsidian Integration 插件将阅读过程中的划线、批注等转化为 AI 可读取的数据库。
打开 Obsidian ,左下角点击对应库的 齿轮 图标,![]()
点击 第三方插件 - 关闭安全模式,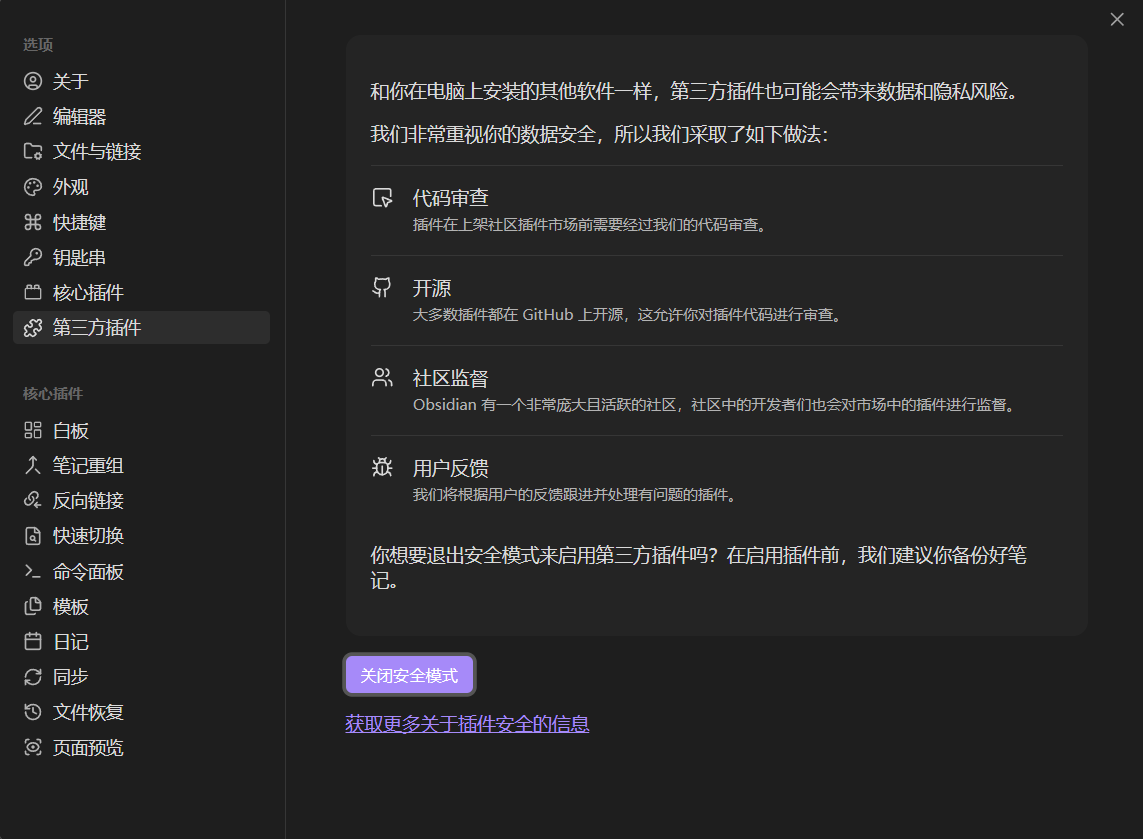
搜索该插件并点击安装,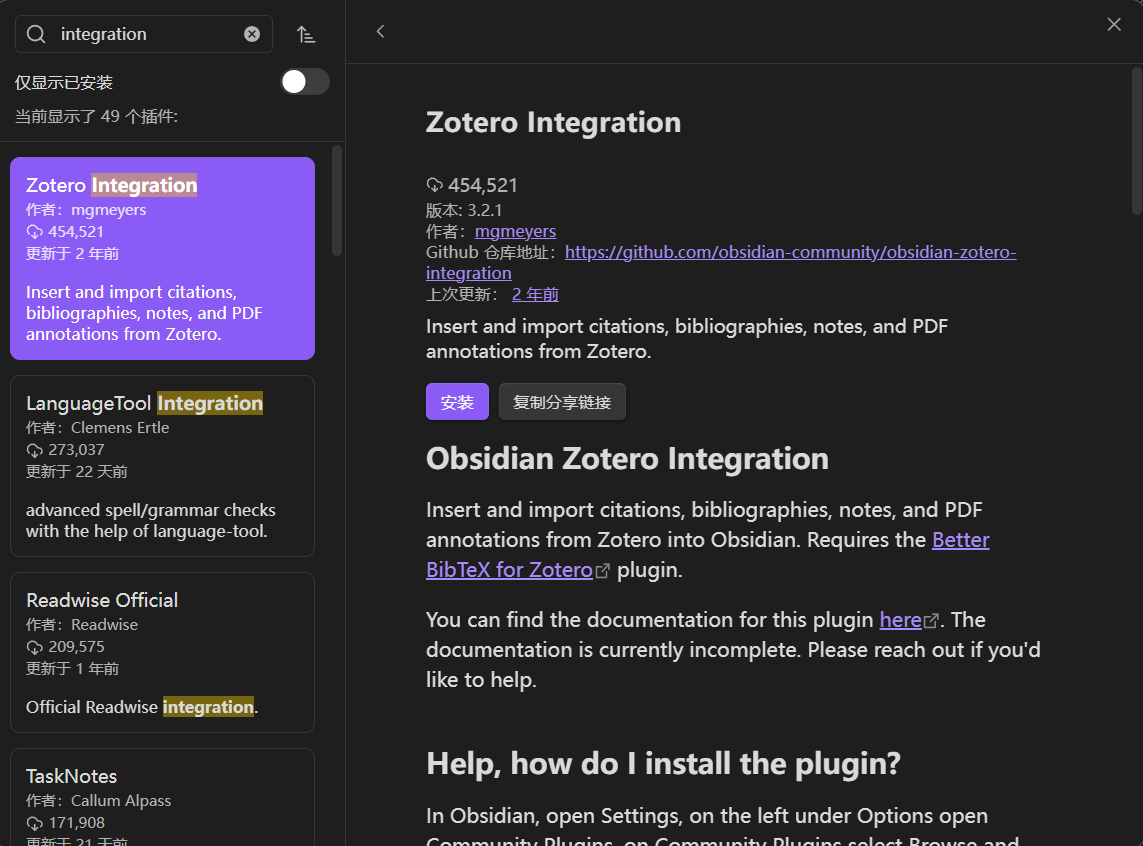
如果搜不到可以到 GitHub 下载(官方网址:https://github.com/obsidian-community/obsidian-zotero-integration)。
安装后,点击 齿轮 图标设置该插件,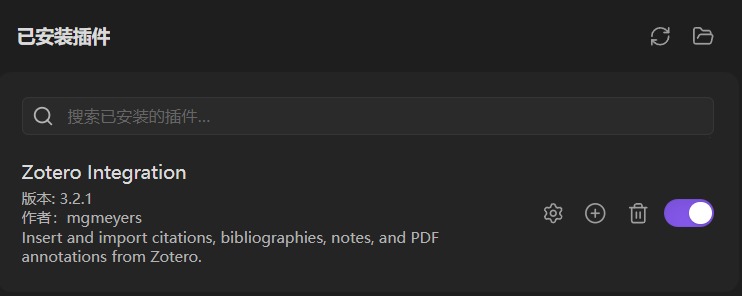
进行如下设置:
-
General Settings(通用设置)
- PDF Utility 点击 download ,该插件依赖 pdfannots2json 这一外部工具来提取 PDF 中的标注);

- PDF Utility Path Override 点击 Download the executable here ,
自动打开该项目,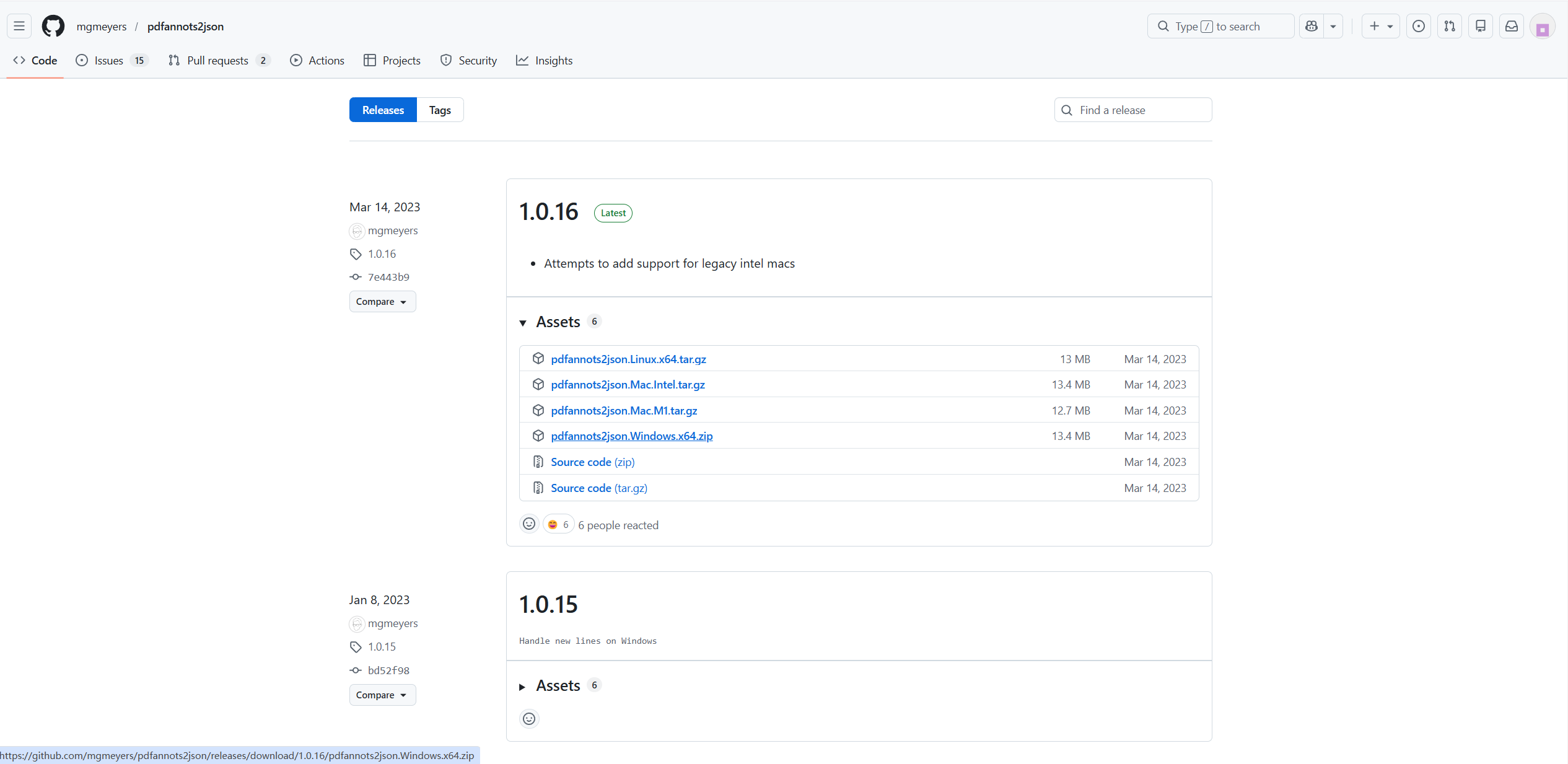
下载对应电脑版本的文件到 Obsidian 笔记文件夹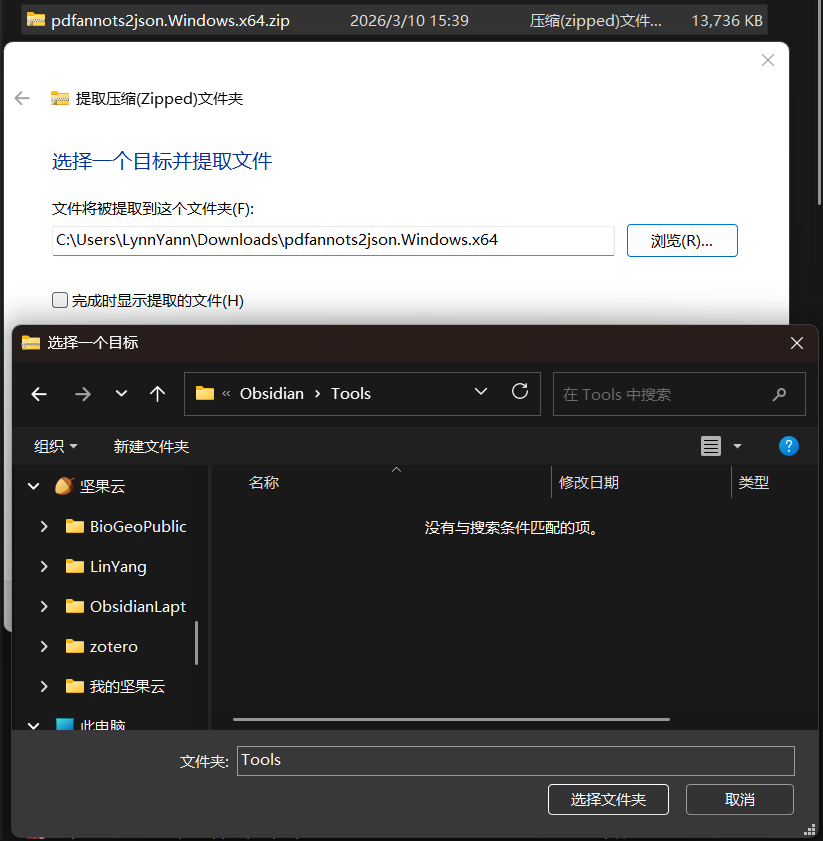
( .zip 文件需解压后保存);
- Database 保持 Zotero 选项;

- Note Import Location 输入工作目录下的新建文件名(无需手动新建,建议存放于当前 Obsidian 库下的一个子文件夹,专门存放从 Zotero 同步过来的 Markdown 文件);

- Ooen the created or updated note(s) after import 建议开启,用于检查实时同步效果;

- Which notes to open after import 根据个人喜好选择,建议选择 First imported note ,这样每次同步完都能立刻看到结果并二次润色;

- Enable Annotation Concatenation

- PDF Utility 点击 download ,该插件依赖 pdfannots2json 这一外部工具来提取 PDF 中的标注);
-
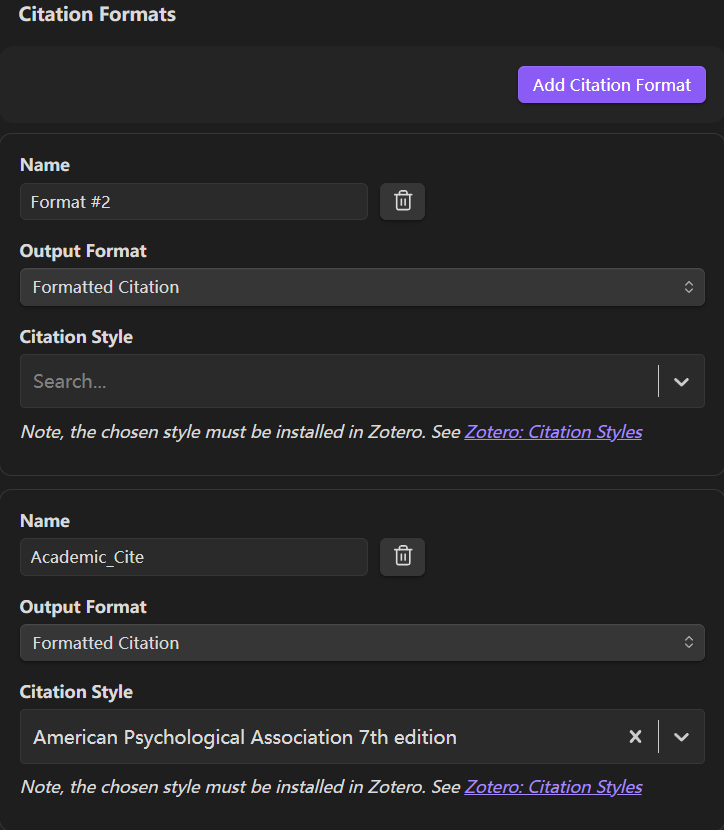
Citation Formats(关键步骤)定义文献中笔记中唯一识别符(如 [@wang2026Spatial] ),方便在处理多篇文献笔记时,清晰地区分哪些观点来自哪篇论文,避免 AI 出现幻觉。
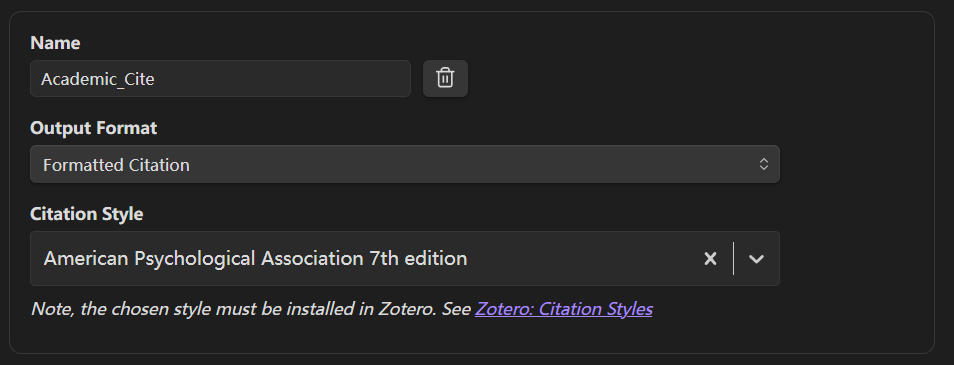
按照图示填写,每完成一个 引用模板 点击 Add Citation Format 添加改模板。- Name 自定义;
- Output Format 保持 Formatted Citation;
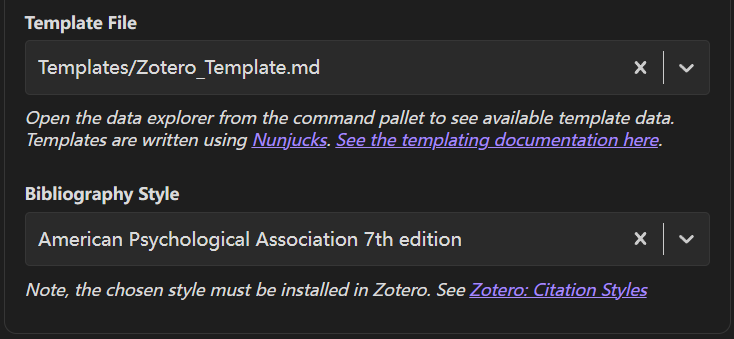
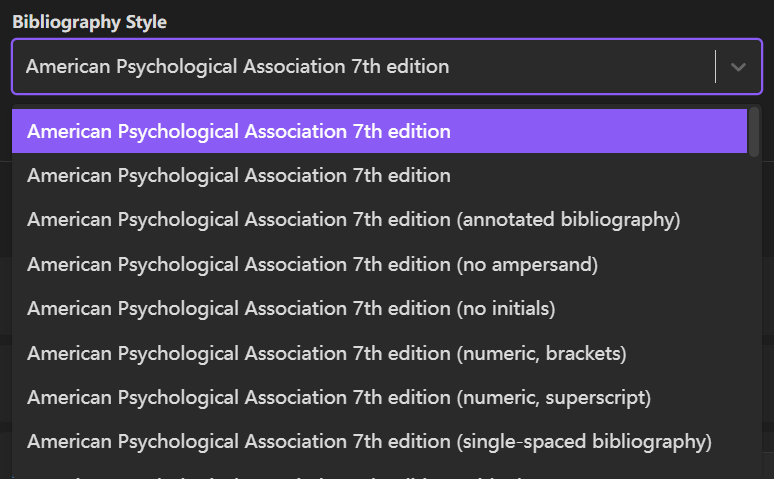
- Citation Style 建议在下拉列表中搜索选择 American Psychological Association 7th edition(APA 7th),该格式包含文献“作者-年份“信息。
-
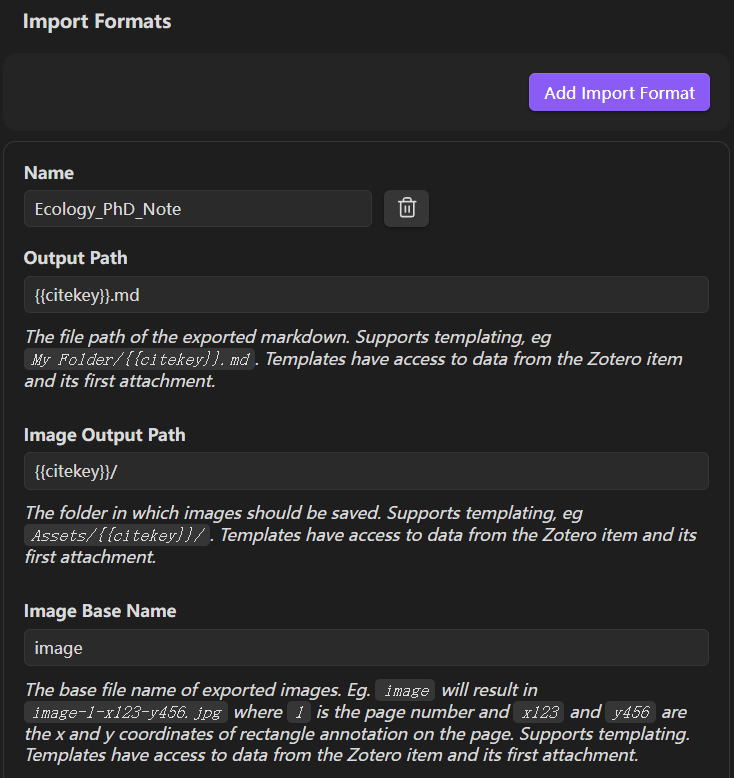
Import Formats(关键步骤)规定 Markdown 笔记的排版,包括标题、摘要、标注、评论等,可以将原始摘录与学术理解区分开。
按照图示填写,每完成一个 导入模板 点击 Add Import Format 添加该模板。其中:- Name 自定义;
- Output Path 建议设置为 ”子文件夹名/{{citekey}}.md“ ,这样会在 Obsidian 当前库下创建该子文件夹,并将所输出的 Markdown 笔记存于该文件夹下,避免根目录太混乱;
- Image Output Path 建议保持 {{citekey}}/;
- Image Base Name 建议保持 image;
- Template File 需要现在 Obsidian 的模板文件夹里先创建一个 .md 文件(这里命名为 Zotero_Template.md),然后在下拉菜单中选中它。
创建模板具体步骤:回到 设置 - 模板 , 输入自定义的模板文件夹名(以 Templates 为例),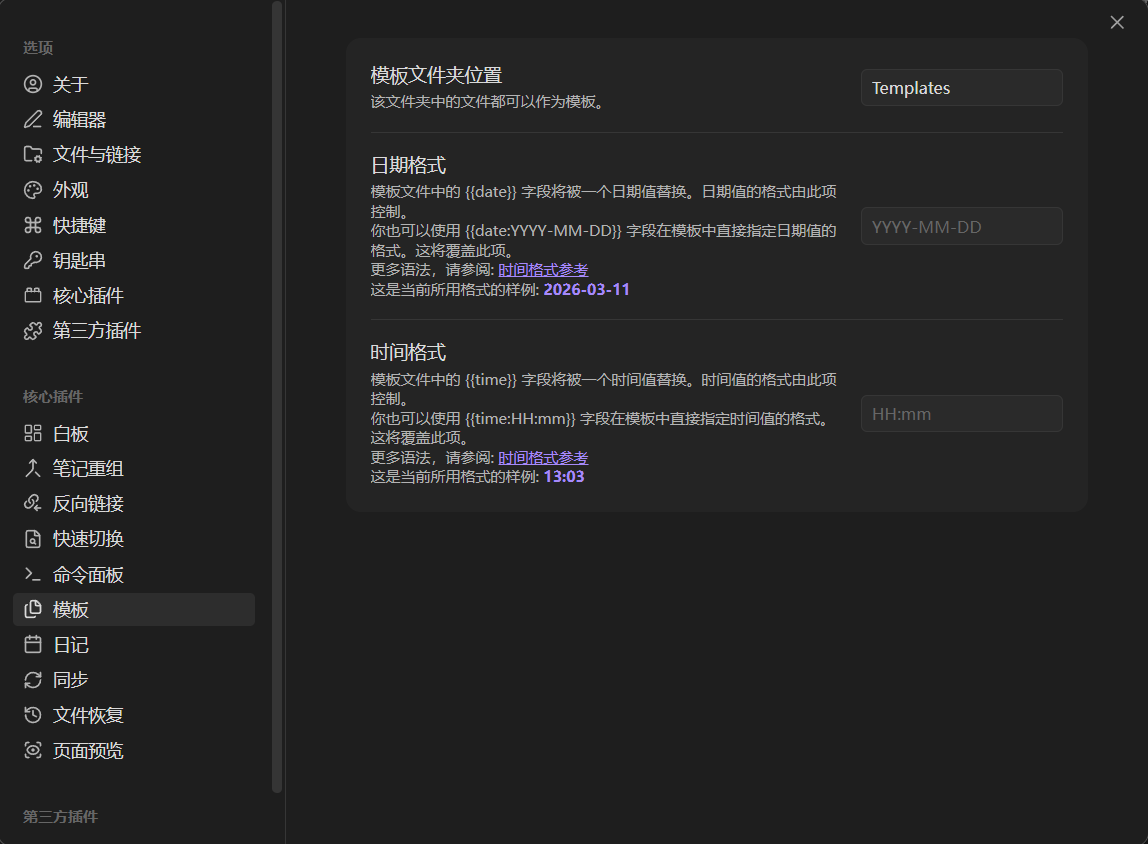
在 Templates 模板文件夹下新建笔记并命名,输入自定义的格式。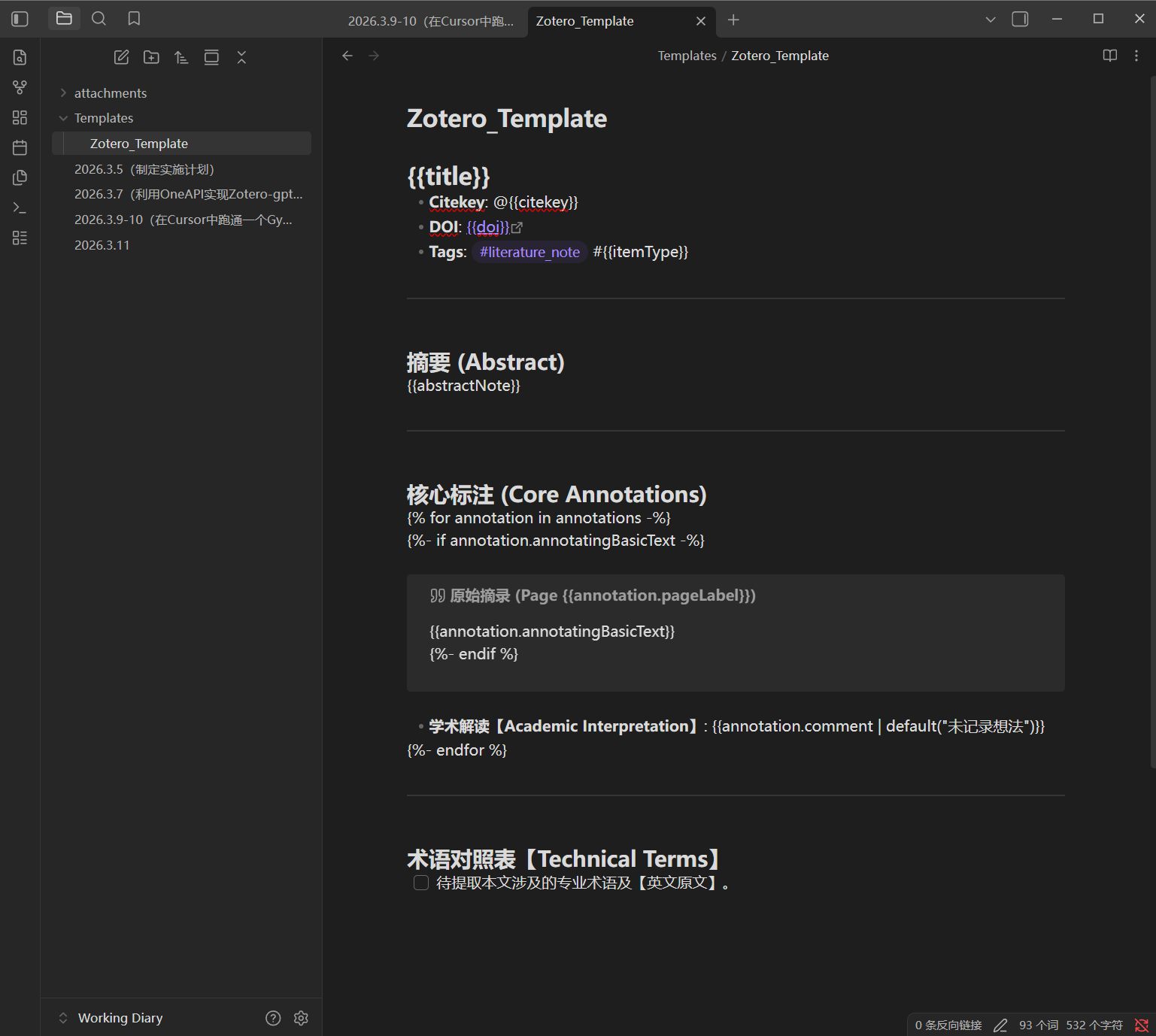
- Bibliography Style 仍建议选择 APA 7th 。
这部分内容较长,别忘了划回去添加上述设置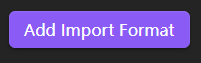 。
。
-
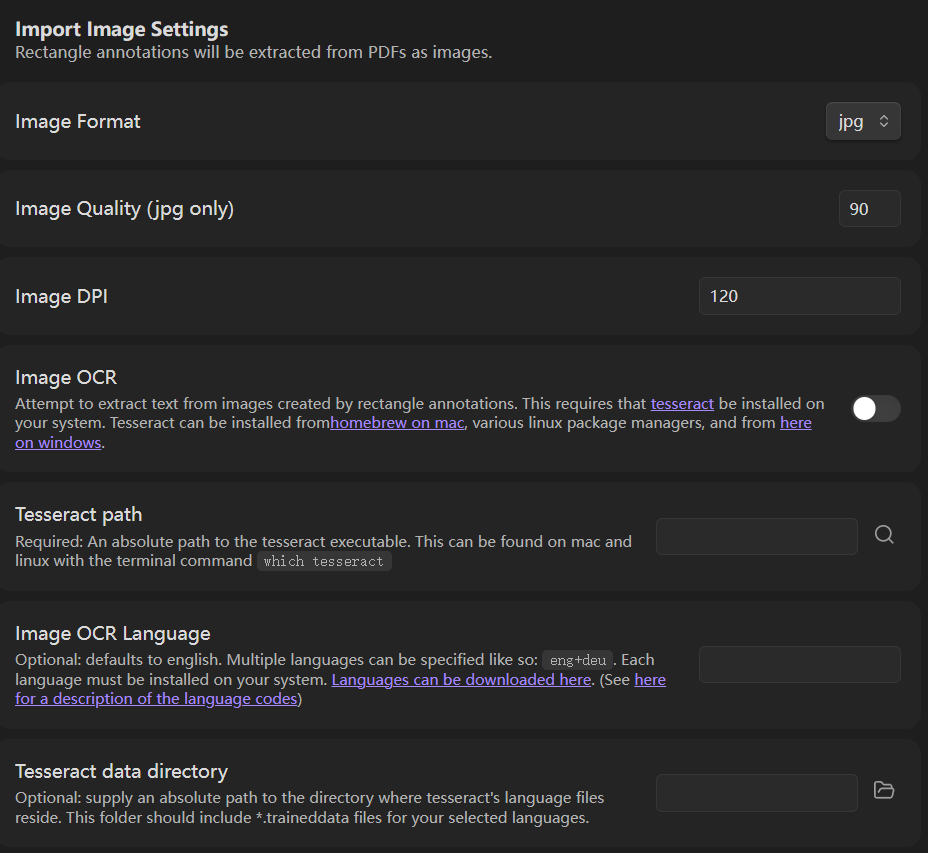
Import Image Settings
- Image Format / Quality:保持默认。
- Image OCR:建议暂时关闭。由于处理的大多是现代电子版 PDF ,而不是大量的扫描版文献,无需开启,开启 OCR 需要安装额外的 Tesseract 引擎。
配置效果
配置完成,使用时可在 Obsidian 直接拉起 Zotero 的单篇文献,并将其按照刚才自定义的模板格式总结为 .md 文件存于指定路径。
使用操作步骤如下:
点击左侧栏打开 命令面板 或按 Ctrl + P ,
搜索 导入模板名 (以 Zotero Integration:Ecology_PhD_Note 为例),即可实现从 Zotero 到 Obsidian 的知识迁移。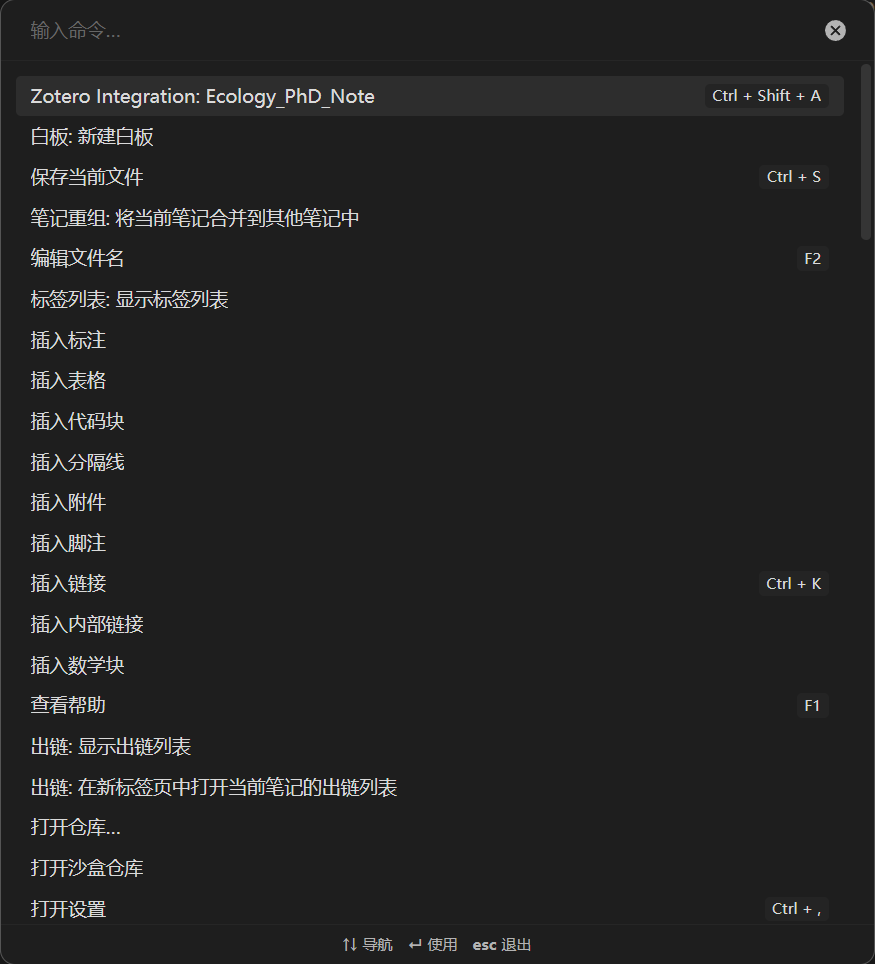
也可设置为常用快捷键,即可一键实现该命令:
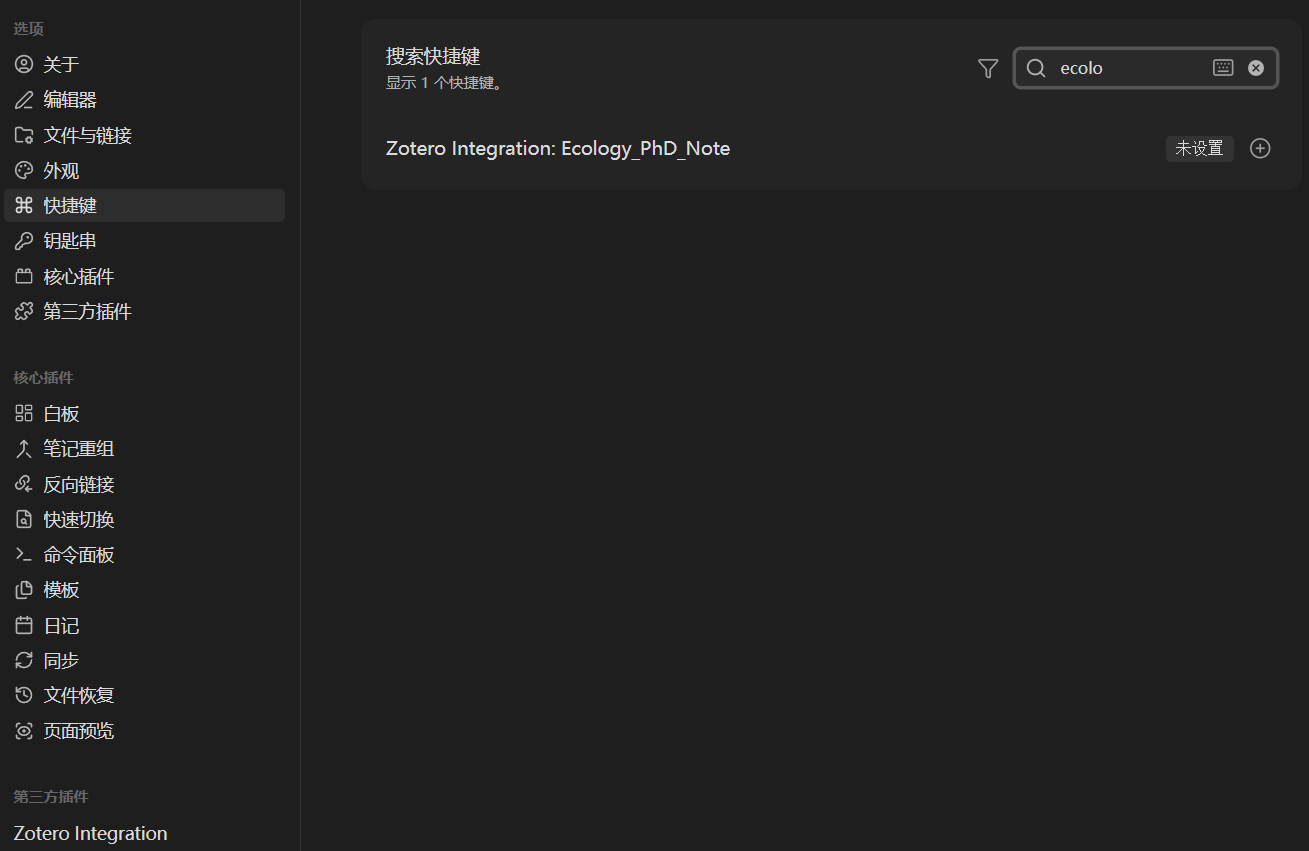

等待响应,
点击单篇或多篇文献,点击 右箭头 图标,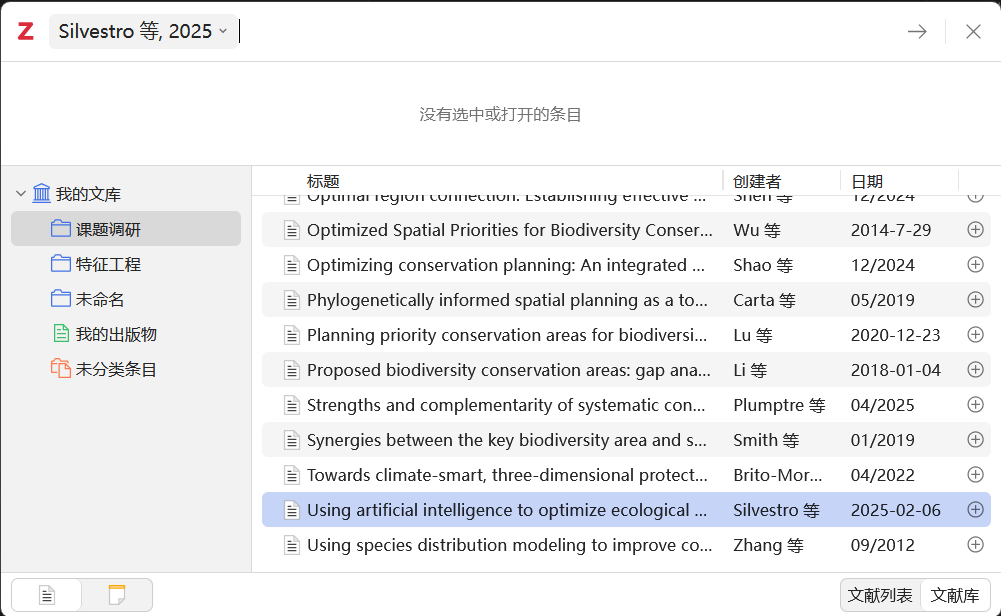
生成结果如图。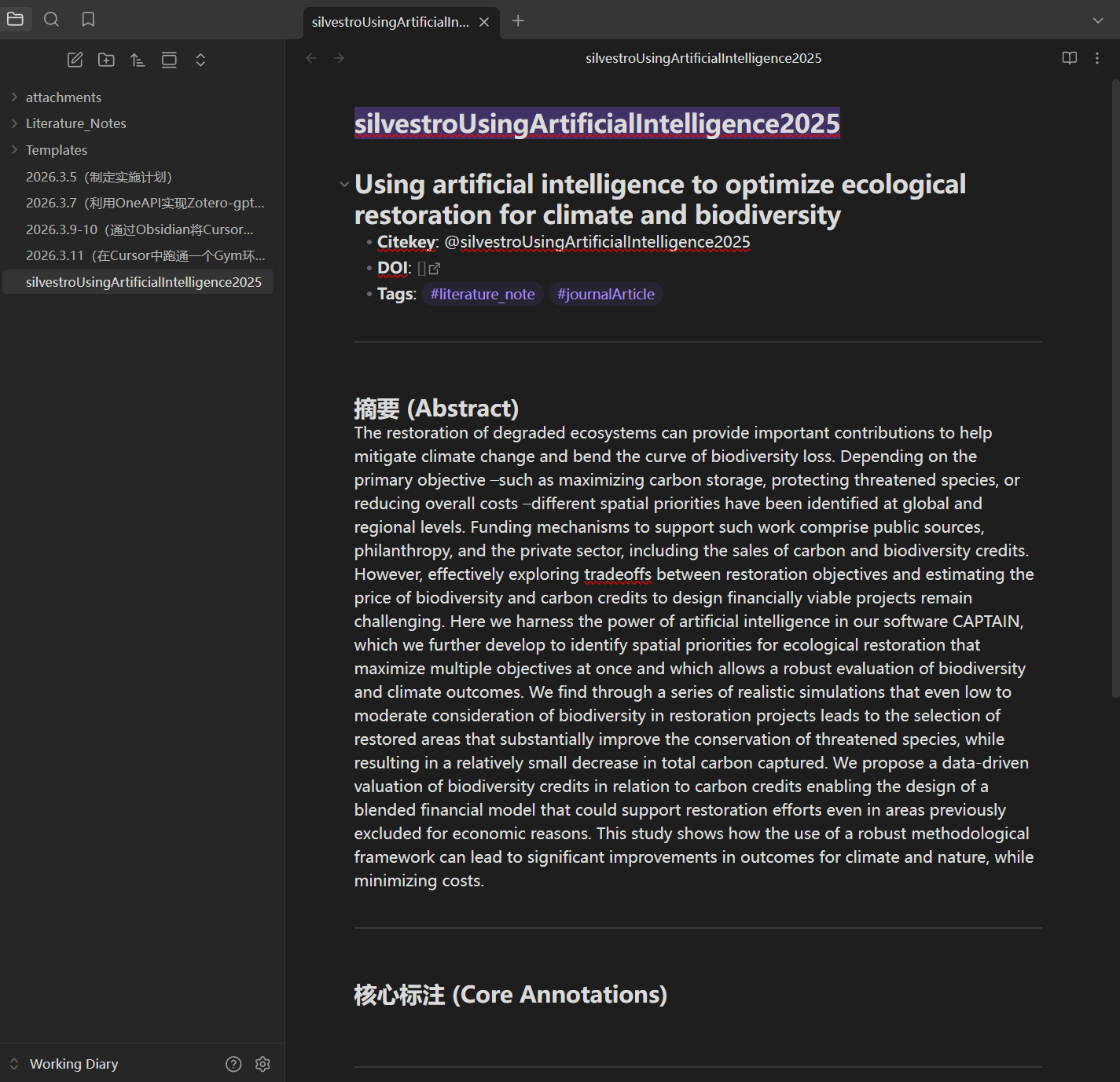
同样地,该文件也可以被 Cursor AI 索引和分析。
提示
-
合并重复条目
如果出现 Error retrieving item data: duplicates found: .... 的报错,
在 Zotero 左侧面板找到”重复条目“类,选中重复文献并点击右侧的 merge x items 合并条目,再次操作即可解决报错。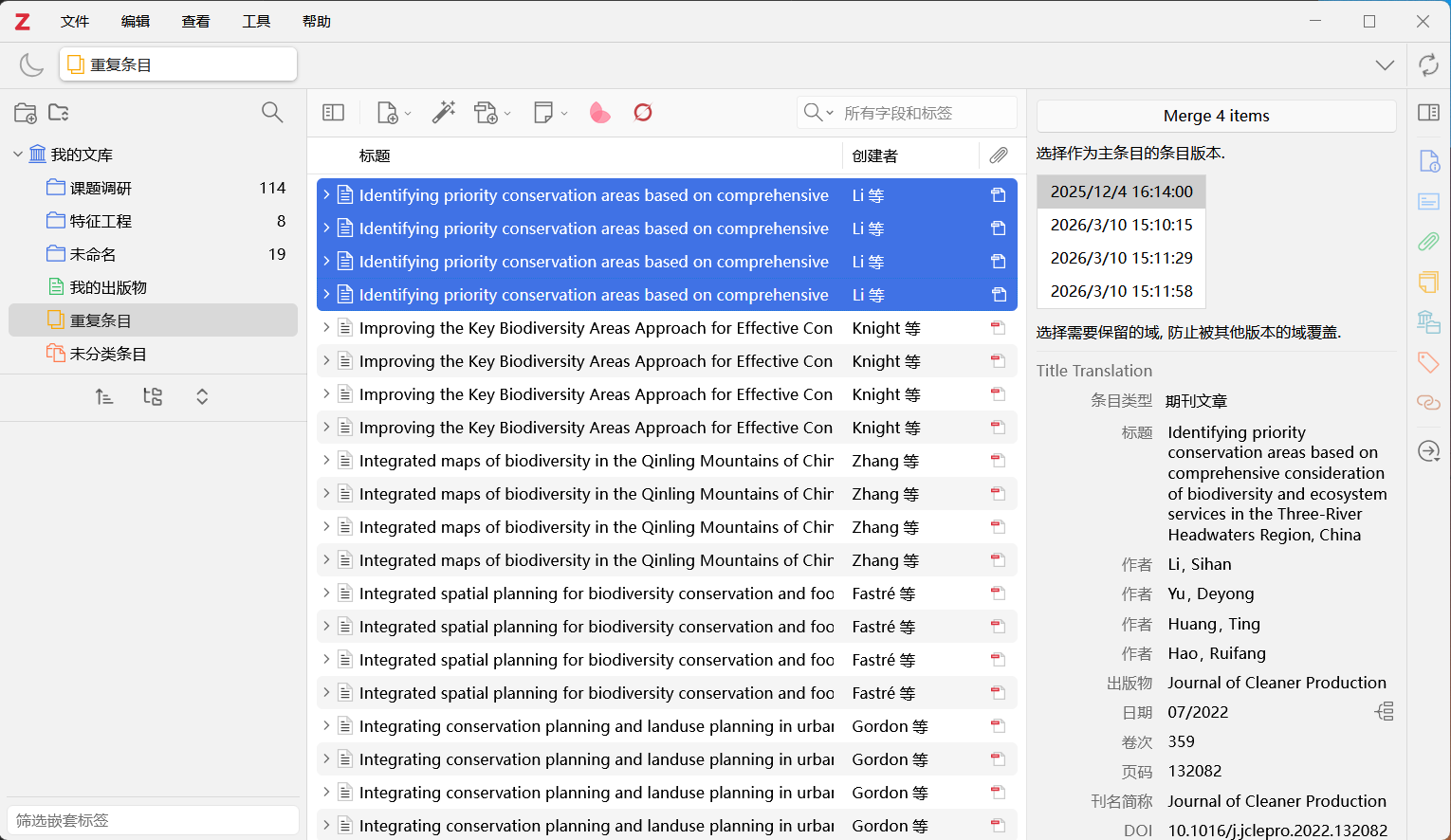
-
CSL 样式缺失
如果出现 Error converting formatted bibliography markdown: Error: CSL style "..." not found ,应回到 ”Citation Formats“”Import Formats“模块检查是否正确选择下拉列表中的选项,手动输入的名称无法正确加载。检查完毕,关闭 Zotero 和 Obsidian ,先重启 Zotero,确保其后台加载了样式库,再重启 Obsidian 运行命令重试。
小结
本篇主要利用 Zotero 的插件 Better BibTeX 、Obsidian 的插件 Obsidian Integration 分别将原始文献、学术解读转化为可供 AI 读取的数据库,并采用 Cursor 作为集成二者的 AI 介质。
Better BibTeX 插件直接导出的 .bib 文件是整个知识图谱的”骨架“,存储着包含所有文献的元数据,让 Cursor AI 建立对全部文献的整体感知,同时定位引用来源;Obsidian Integration 插件根据文献批注和自定义模板生成的 .md 文件是知识图谱的”灵魂“,存储着学术解读切片,供 Cursor 理解逻辑论证、公式推导等批判性思考,同时针对具体问题协作修改论文或代码片段。
综上,Zotero 作为原始数据源,负责存储 PDF 文件及个人批注;Obsidian 是格式化存储库,将 Zotero 二进制数据库里的”死数据“转化为 Cursor 能读懂的”活文本“,这是实现检索增强生成的前置条件;Cursor 是核心的计算与逻辑推演中心,利用前面生成的笔记给出准确而有针对性的建议。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)