OpenAI语音革命:GPT-5级推理开口,同传速记成本直降90%
OpenAI语音革命:GPT-5级推理开口,同传速记成本直降90%

以前我们打客服电话,最怕听到那句“对不起,我没听清,请再说一遍”。更让人抓狂的是,当你耐着性子跟它绕了三分钟,终于转到人工,结果对方第一句话是:“您好,请问有什么可以帮您?”——你刚才对着机器白说了。
这就是传统语音助手的死穴:只会接话,不会办事;只会单轮问答,记不住多轮上下文。但OpenAI这次发布的GPT-Realtime-2,终于让语音AI长出了“GPT-5级的大脑”。

GPT-Realtime-2最狠的升级,是把上下文窗口从32K直接拉到128K,翻了整整4倍。这参数看着枯燥,实际体验却是天壤之别。你打电话给房产中介,一口气说完“我要找离地铁近、不要临街、预算300万以内、最好带学区、周六下午能看房”——传统语音助手聊到第三轮就开始“失忆”,你得反复重复条件。而128K上下文意味着,模型能记住你最初提出的所有限制条件,在长达几十分钟的通话中维持逻辑一致性,不会聊着聊着就忘了你养狗、怕吵、还恐高。
更精妙的是可调推理强度设计。OpenAI给了5档选择:minimal、low、medium、high、xhigh。问天气用low秒回,丢给它一个商业分析大题用xhigh慢慢推演。这解决了语音交互最致命的矛盾——推理越深延迟越大,但用户最怕停顿。开发者现在可以根据场景紧急程度动态切换,在“快问快答”和“深思熟虑”之间自如游走。还有一个细节值得玩味:GPT-Realtime-2学会了说“稍等片刻”。后台拉数据时,它会先来一句“让我核实一下”——这种看似废话的Preambles设计,最大程度缓解了等待焦虑。人在思考时也会说“呃让我想想”,现在AI也学会了。
技术参数再漂亮,落地效果才是硬道理。美国房地产巨头Zillow的实测数据相当震撼:在最难的对抗性测试中,经过Prompt优化后,通话任务成功率从69%飙升至95%,提升了26个百分点。更关键的是,GPT-Realtime-2在处理Fair Housing(公平住房法)合规审查时表现稳定,有效规避了基于种族、性别等敏感因素的歧视风险。在美国这种法律合规极其严格的市场,这一点比准确率更重要。
全球旅行平台Priceline的案例同样值得关注。旅游预订链条极长,涉及航班查询、酒店比价、改签处理、延误补偿等多个环节。传统语音助手面对跨部门复杂指令往往直接宕机,而集成GPT-Realtime-2后,系统能流畅处理多步骤任务,大幅降低用户重复描述需求的可能性。这些案例指向同一个趋势:语音AI不再只是“接电话的”,而是真的能处理高价值、高合规要求的业务场景。从“能说”到“能办”,这道坎终于跨过去了。
二、 击穿地板价的“同传”与“速记”:语言与记录壁垒的崩塌
如果说 GPT-Realtime-2 赋予了机器“会思考的大脑”,那么同期发布的 GPT-Realtime-Translate 和 GPT-Realtime-Whisper 则是极致工程化的“嘴巴”与“耳朵”。OpenAI 用两套按分钟计费、价格低到尘埃里的 API,将曾经昂贵如奢侈品的企业级服务,变成了打开水龙头就能接的“自来水”。
2.1 实时翻译:支持70种语言,每分钟成本仅0.034美元,传统人工同传市场面临冲击
GPT-Realtime-Translate 真正的杀手锏不在于翻译准确度本身,而在于**“连续口译”的流畅感**。
传统语音翻译最反人性的地方,是要求说话者必须停顿、等待整句话结束后才能获得反馈。这种生硬的割裂感,在紧张的商务谈判或深度交流中,足以摧毁对话的节奏与信任。新模型实现了说话人开口即译,翻译输出紧随其后,节奏紧凑到几乎与正常对话无异。
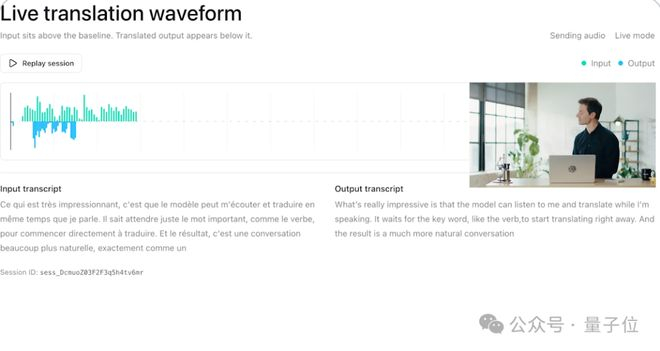
它支持 70多种输入语言向13种输出语言的实时互译,对口音和方言的包容度同样惊人。印度 AI 公司 BolnaAI 使用印地语、泰米尔语等口音浓重的语言进行实测,词错误率比其他模型低 12.5%,延迟依然维持在自然对话水平。
但真正引发行业地震的,是定价:每分钟 0.034 美元,折合人民币约两毛五。
算一笔账就清楚了。一场需要人工同声传译的会议,英语语种一天收费在 1.2 万到 2.1 万元之间,非英语语种 1.8 万起步,且通常需要 2 到 3 名译员轮换。这还不算同传间、耳机、接收器等专业设备租金。折算下来,每小时成本高达数千至上万元。
而按新定价,连续翻译 8 小时的总成本不到 120 块,还不及人工同传两分钟的价钱,成本差距约 66 倍。
这意味着,同传不再是国际峰会或跨国董事会的特权。一个出海电商客服系统、一个跨国视频会议工具、甚至一个浏览器插件,都能瞬间拥有实时多语言能力。
当然,人类同传的价值不会消失,而是向上迁移——文化语境拿捏、创意表达转化、法律条款的绝对精确,这些依然是机器的盲区。但基础、高频、标准化的翻译需求,正在被 API 大规模吞掉。
2.2 流式转录:Whisper模型每分钟0.017美元,会议纪要实时生成将成为标配
GPT-Realtime-Whisper 将“实时流式转写”推向了极致:说话人开口,文字同步生成,几乎没有可感知的延迟。而它的定价更加激进——每分钟 0.017 美元,折合人民币约一毛钱,一小时连续转写不到 6 块钱。
这个价格击穿了什么?过去需要专人整理、隔天才能拿到的会议纪要,现在可以实时投屏、即时存档、自动流入工作流。客服通话记录、课堂笔记、视频字幕——所有需要“把声音变成文字”的场景,商业门槛被直接清零。
三款模型的定价策略,体现了 OpenAI 的精细化商业布局:GPT-Realtime-2 按 Token 计费,体现通用智能体的算力消耗;Translate 和 Whisper 按分钟计费,更符合企业用户对时长控制的直觉。这种差异化体系,实际上在引导开发者根据场景选择最优组合——翻译需求用 Translate,记录需求用 Whisper,复杂推理场景才调用 Realtime-2。
对于跨国企业的日常运营而言,语言障碍和记录滞后,正从“效率绊脚石”变成“可忽略的边际成本”。

三、 语音AI下半场:从卷“音色拟真”到卷“实时推理”的军备竞赛
过去两年,语音AI的竞争锚点一直锁定在“像不像真人”上。ElevenLabs凭此逻辑估值飙至110亿美元,年化收入破5亿,证明市场愿意为“好声音”买单。
但现在,风向变了。
3.1 赛道变天:ElevenLabs、Deepgram等对手环伺,低延迟与全栈能力成竞争新高地
企业需求正从“声音像不像”转向更务实的三角验证:反应快不快、逻辑对不对、链路通不通。

延迟成为第一战场。Deepgram的Aura-2模型将流式延迟压至200毫秒以内,Cartesia的Sonic系列更是宣称达到90毫秒——这个数字已低于人类对话的平均反应间隔,意味着语音交互的“卡顿感”正在消失。它们还在结构化数据朗读、42种语言情绪控制等细节上构筑壁垒。
但OpenAI真正的护城河不在单项指标,而在全栈模型能力。
语音Agent的落地链路极长:识别、翻译、推理、合成,任一环节断裂都会导致体验崩塌。传统方案需要集成多家供应商,延迟叠加、运维割裂、数据安全策略难以统一。OpenAI将这条链路整合在同一平台,对开发者而言,少接一个供应商,就是少一层延迟、省一笔运维成本、少一个合规漏洞。
当然,这并不意味着通吃。ElevenLabs在配音和情感化对话领域的积累,Deepgram在联络中心基础设施的渗透,Cartesia在极致低延迟上的技术偏执,都构成了细分护城河。OpenAI的全栈优势能否跨越不同地区的数据隐私法规和硬件差异,仍是待解之题。
3.2 OpenAI的商业阳谋:按Token与按分钟的差异化定价,意在通吃开发者与企业全场景
三款模型,两套计价体系,暴露了OpenAI的精细化运营逻辑。
GPT-Realtime-2按Token计费——音频输入$32/百万token,输出$64/百万token——这本质上是为“算力消耗”定价,适用于需要复杂推理和工具调用的智能体场景。而Translate和Whisper按分钟计费,分别为$0.034/分钟和$0.017/分钟,更贴合企业对时长控制的直觉。
差异化定价的真正目的,是引导开发者按场景匹配模型组合,而非一锅端。
深层逻辑更值得关注:这套定价体系正在把语音AI从“尝鲜品”变成“日用品”。同声传译一小时成本不到15元人民币,实时转录一小时不到6元——这个价格足以让任何出海电商、跨国会议、在线教育平台无痛接入。
这不是简单的“低价铺量”。当语音能实时理解、翻译、执行,它会成为连接物理世界与数字世界最高效的接口。OpenAI的定价策略,本质上是在为这个“语音互联网”的未来抢占入口——先让企业用起来,再让它们离不开。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)