从零梳理:多源校园数据下的学生单次考试成绩预测(线性回归 + 决策树 + XGBoost)
1. 项目目标
本项目基于学校多源业务数据,完成学生单次考试成绩预测。不以学生平均分为预测对象,而是以成绩表中的 每一条考试记录 为一个样本,预测该学生在某次考试、某门学科中的真实成绩 mes_Score。
将对比三类回归模型:
- 线性回归 LinearRegression
- 决策树回归 DecisionTreeRegressor
- XGBoost 回归 XGBRegressor
训练结束后为每个模型保存 **.joblib(内含预处理 + 回归器),并自动选择 测试集 RMSE 最低 的模型为 **best_score_model.joblib。
2.数据说明
2.1 七张原始业务表(data/)
| 文件名 | 说明 |
|---|---|
1_teacher.csv |
近五年各班各学科教师信息 |
2_student_info.csv |
当前在校学生基础信息 |
3_kaoqin.csv |
学生考勤记录 |
4_kaoqintype.csv |
考勤类型字典 |
5_chengji.csv |
学生成绩记录 |
6_exam_type.csv |
考试类型字典 |
7_consumption.csv |
学生消费记录 |
核心标签来自成绩表字段 mes_Score。
2.2 异常成绩编码(业务含义)
| 值 | 含义 | 处理方式 |
|---|---|---|
-1 |
作弊 | 过滤(mes_Score >= 0 以外剔除) |
-2 |
缺考 | 同上 |
-3 |
免考 | 同上 |
训练时 仅保留 mes_Score >= 0 的有效分数记录。
2.3 读取优先级
程序 优先 读取:
outputs/cleaned/
中的清洗后 CSV;若该目录为空,则读取 data/ 原始文件。
3. 项目目录结构
项目根目录/
├── data/ # 原始 CSV
├── outputs/
│ ├── cleaned/ # clean.py 产出
│ └── score_prediction_no_avg/
│ ├── model_dataset.csv # 全量建模宽表(特征 + target_mes_Score)
│ ├── model_metrics.csv # 各模型 train/test 指标
│ ├── best_model_predictions.csv
│ ├── model_predictions/ # 各模型测试集预测明细
│ ├── feature_importance/
│ ├── cross_validation/
│ └── figures/
│ ├── global_compare/ # 多模型对比图
│ └── each_model_8plots/ # 各模型单独 8 类图
├── models/
│ ├── LinearRegression_score_model.joblib
│ ├── DecisionTree_score_model.joblib
│ ├── XGBoost_score_model.joblib
│ └── best_score_model.joblib
├── train.py # 实际训练与预测入口
└── clean.py # 生成 outputs/cleaned/
4. 环境依赖
建议 Python 3.8+。
pip install pandas numpy scikit-learn xgboost joblib matplotlib
5. 工作流程
读取多张 CSV(优先 cleaned)
↓
统一字段名和学生 ID(bf_StudentID)
↓
过滤异常成绩(mes_Score >= 0)
↓
成绩表衍生考试年/月/日/星期
↓
按学生聚合考勤特征 → left merge
↓
按学生聚合消费特征 → left merge
↓
合并学生基础信息
↓
合并考试类型维表
↓
教师表去重后合并(班级+学科)
↓
构造特征矩阵 X,标签 y;剔除泄漏列、姓名、时间戳、ID、常数列
↓
保存 model_dataset.csv(可选)
↓
train_test_split(test_size=0.2, random_state=42)
↓
数值:中位数填补 + 标准化;类别:众数填补 + One-Hot
↓
训练 LinearRegression / DecisionTree / XGBoost(Pipeline)
↓
评估 MAE、RMSE、R²;保存 joblib 与预测 CSV
↓
交叉验证(可选)+ 导出 figures/
6. 特征工程说明
6.1 学生基础信息特征
来自学生信息表,例如:性别、民族、出生年份、班级名、住址、政治面貌、宿舍等(以实际列为准)。年龄:
student_age = 2026 - bf_BornDate
6.2 考勤特征(按 bf_StudentID 聚合)
| 特征 | 含义 |
|---|---|
attendance_event_count |
考勤事件总数 |
late_count |
迟到次数 |
early_leave_count |
早退或离校次数 |
uniform_problem_count |
校服相关问题次数 |
avg_attendance_hour |
平均考勤小时 |
active_attendance_months |
有考勤记录的月份数 |
active_attendance_weekdays |
有考勤记录的星期数 |
规则:controler_name 含「迟到」→ 迟到;含「早退」或「离校」→ 早退/离校;含「校服」→ 校服问题。
6.3 消费特征(按 bf_StudentID 聚合)
| 特征 | 含义 |
|---|---|
total_spend |
总消费金额 |
avg_spend |
平均单笔 |
max_spend / min_spend |
最大/最小单笔 |
std_spend |
标准差(单值组填 0) |
consumption_count |
消费笔数 |
active_consume_months |
有消费的月份数 |
avg_consume_hour |
平均消费小时 |
金额:MonDeal 为负时取 **abs(MonDeal)** 作为支出(或直接使用 spend_amount)。
6.4 考试信息特征
来自成绩表及考试类型表,例如:exam_numname、exam_term、exam_type、EXAM_KIND_NAME、exam_year、exam_month、exam_day、exam_dayofweek、mes_sub_name 等。
6.5 教师信息特征
合并键:班级名 cla_Name + 学科名 mes_sub_name(与教师表 cla_Name + sub_Name 对齐)。
必须先按 cla_Name + sub_Name 去重,避免一对多合并导致样本行数膨胀。
7. 数据泄漏处理
训练前从特征中移除:
mes_Score, mes_Z_Score, mes_T_Score, mes_dengdi
并移除姓名、原始日期时间、各类业务 ID 等。
8. 核心实现代码
以下代码均来自项目根目录 `train.py
8.1 读取数据:load_tables
def load_tables():
tables = {}
cleaned_files = {
"teacher": ["clean_teacher.csv"],
"student": ["clean_student_info.csv", "clean_student_profile.csv", "student_profile.csv"],
"attendance": ["clean_attendance.csv"],
"attendance_type": ["clean_attendance_type.csv"],
"score": ["clean_score.csv"],
"exam_type": ["clean_exam_type.csv"],
"consumption": ["clean_consumption.csv"],
}
raw_files = {
"teacher": ["1_teacher.csv"],
"student": ["2_student_info.csv", "2_studentinfo.csv"],
"attendance": ["3_kaoqin.csv"],
"attendance_type": ["4_kaoqintype.csv"],
"score": ["5_chengji.csv"],
"exam_type": ["6_exam_type.csv"],
"consumption": ["7_consumption.csv"],
}
use_cleaned = os.path.exists(CLEANED_DIR) and len(os.listdir(CLEANED_DIR)) > 0
if use_cleaned:
for key, candidates in cleaned_files.items():
path = find_existing_file(CLEANED_DIR, candidates)
if path is None:
tables[key] = None
continue
df = read_csv_smart(path)
df = clean_column_names(df)
df = normalize_student_id(df)
tables[key] = df
else:
for key, candidates in raw_files.items():
path = find_existing_file(DATA_DIR, candidates)
if path is None:
tables[key] = None
continue
if key == "attendance_type":
try:
df = read_csv_smart(path, sep="\t")
except Exception:
df = read_csv_smart(path, sep=",")
else:
df = read_csv_smart(path)
df = clean_column_names(df)
df = normalize_student_id(df)
tables[key] = df
return tables
8.2 考勤聚合:build_attendance_features
def build_attendance_features(attendance):
if attendance is None or attendance.empty:
return pd.DataFrame({"bf_StudentID": []})
df = attendance.copy()
df = clean_column_names(df)
df = normalize_student_id(df)
if "bf_StudentID" not in df.columns:
return pd.DataFrame({"bf_StudentID": []})
if "DataDateTime" in df.columns:
df["DataDateTime"] = safe_to_datetime(df["DataDateTime"])
df["attendance_hour"] = df["DataDateTime"].dt.hour
df["attendance_month"] = df["DataDateTime"].dt.month
df["attendance_dayofweek"] = df["DataDateTime"].dt.dayofweek
else:
df["attendance_hour"] = np.nan
df["attendance_month"] = np.nan
df["attendance_dayofweek"] = np.nan
if "controler_name" not in df.columns:
df["controler_name"] = ""
df["controler_name"] = df["controler_name"].astype(str)
df["is_late"] = df["controler_name"].str.contains("迟到", na=False).astype(int)
df["is_early_leave"] = (
df["controler_name"].str.contains("早退", na=False) |
df["controler_name"].str.contains("离校", na=False)
).astype(int)
df["is_uniform_problem"] = df["controler_name"].str.contains("校服", na=False).astype(int)
agg = df.groupby("bf_StudentID").agg(
attendance_event_count=("bf_StudentID", "count"),
late_count=("is_late", "sum"),
early_leave_count=("is_early_leave", "sum"),
uniform_problem_count=("is_uniform_problem", "sum"),
avg_attendance_hour=("attendance_hour", "mean"),
active_attendance_months=("attendance_month", "nunique"),
active_attendance_weekdays=("attendance_dayofweek", "nunique"),
).reset_index()
return agg
8.3 消费聚合:build_consumption_features
def build_consumption_features(consumption):
if consumption is None or consumption.empty:
return pd.DataFrame({"bf_StudentID": []})
df = consumption.copy()
df = clean_column_names(df)
df = normalize_student_id(df)
if "bf_StudentID" not in df.columns:
return pd.DataFrame({"bf_StudentID": []})
if "DealTime" in df.columns:
df["DealTime"] = safe_to_datetime(df["DealTime"])
df["consume_month"] = df["DealTime"].dt.month
df["consume_hour"] = df["DealTime"].dt.hour
else:
df["consume_month"] = np.nan
df["consume_hour"] = np.nan
if "spend_amount" in df.columns:
df["spend_amount"] = safe_to_numeric(df["spend_amount"])
elif "MonDeal" in df.columns:
df["MonDeal"] = safe_to_numeric(df["MonDeal"])
df["spend_amount"] = df["MonDeal"].apply(
lambda x: abs(x) if pd.notna(x) and x < 0 else x
)
else:
df["spend_amount"] = np.nan
agg = df.groupby("bf_StudentID").agg(
total_spend=("spend_amount", "sum"),
avg_spend=("spend_amount", "mean"),
max_spend=("spend_amount", "max"),
min_spend=("spend_amount", "min"),
std_spend=("spend_amount", "std"),
consumption_count=("spend_amount", "count"),
active_consume_months=("consume_month", "nunique"),
avg_consume_hour=("consume_hour", "mean"),
).reset_index()
agg["std_spend"] = agg["std_spend"].fillna(0)
return agg
8.4 教师表去重:prepare_teacher_table
def prepare_teacher_table(teacher):
"""教师表去重,避免 班级+学科 一对多合并导致样本数量膨胀。"""
if teacher is None or teacher.empty:
return None
df = teacher.copy()
df = clean_column_names(df)
keep_cols = []
for col in ["term", "cla_id", "cla_Name", "gra_Name", "sub_id", "sub_Name", "bas_id", "bas_Name"]:
if col in df.columns:
keep_cols.append(col)
if len(keep_cols) == 0:
return None
df = df[keep_cols].drop_duplicates()
if "cla_Name" in df.columns and "sub_Name" in df.columns:
sort_cols = [c for c in ["term", "cla_Name", "sub_Name"] if c in df.columns]
if len(sort_cols) > 0:
df = df.sort_values(by=sort_cols)
df = df.drop_duplicates(subset=["cla_Name", "sub_Name"], keep="last")
return df
8.5 宽表构建与删列(节选):build_model_dataset
score["mes_Score"] = safe_to_numeric(score["mes_Score"])
score = score[score["mes_Score"] >= 0].copy()
if "exam_sdate" in score.columns:
score["exam_sdate"] = safe_to_datetime(score["exam_sdate"])
score["exam_year"] = score["exam_sdate"].dt.year
score["exam_month"] = score["exam_sdate"].dt.month
score["exam_day"] = score["exam_sdate"].dt.day
score["exam_dayofweek"] = score["exam_sdate"].dt.dayofweek
data = score.copy()
# merge student, attendance_features, consumption_features, exam_type, teacher_prepared ...
y = data["mes_Score"].copy()
leak_cols = ["mes_Score", "mes_Z_Score", "mes_T_Score", "mes_dengdi"]
name_cols = ["bf_Name", "bf_Name_stu", "AccName", "bas_Name"]
raw_time_cols = ["exam_sdate", "DataDateTime", "DealTime"]
id_cols = [
"bf_StudentID", "mes_TestID", "exam_number", "mes_sub_id", "cla_id", "cla_id_teacher",
"sub_id", "bas_id", "EXAM_KIND_ID", "kaoqin_id", "kaoqing_id", "controler_id",
"ControllerID", "control_task_order_id", "bf_classid",
]
drop_cols = leak_cols + name_cols + raw_time_cols + id_cols
X = data.drop(columns=[c for c in drop_cols if c in data.columns], errors="ignore")
X = X.dropna(axis=1, how="all")
nunique = X.nunique(dropna=True)
useless_cols = nunique[nunique <= 1].index.tolist()
X = X.drop(columns=useless_cols, errors="ignore")
if save_dataset:
dataset_save = X.copy()
dataset_save["target_mes_Score"] = y.values
dataset_save.to_csv(os.path.join(RESULT_DIR, "model_dataset.csv"), index=False, encoding="utf-8-sig")
return X, y, data
8.6 预处理与构建模型结构:build_preprocessor、build_models
def build_preprocessor(X):
numeric_features = X.select_dtypes(
include=["int64", "int32", "float64", "float32", "bool"]
).columns.tolist()
categorical_features = [c for c in X.columns if c not in numeric_features]
numeric_transformer = Pipeline(steps=[
("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler()),
])
categorical_transformer = Pipeline(steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("onehot", OneHotEncoder(handle_unknown="ignore")),
])
preprocessor = ColumnTransformer(
transformers=[
("num", numeric_transformer, numeric_features),
("cat", categorical_transformer, categorical_features),
]
)
return preprocessor
def build_models(preprocessor):
models = {}
models["LinearRegression"] = Pipeline(steps=[
("preprocess", preprocessor),
("model", LinearRegression()),
])
models["DecisionTree"] = Pipeline(steps=[
("preprocess", preprocessor),
("model", DecisionTreeRegressor(
max_depth=8,
min_samples_split=20,
min_samples_leaf=10,
random_state=42,
)),
])
from xgboost import XGBRegressor
models["XGBoost"] = Pipeline(steps=[
("preprocess", preprocessor),
("model", XGBRegressor(
n_estimators=300,
max_depth=5,
learning_rate=0.05,
subsample=0.8,
colsample_bytree=0.8,
objective="reg:squarederror",
random_state=42,
n_jobs=-1,
)),
])
return models
8.7 划分数据集、训练、指标:train_models / evaluate_regression_model(节选)
def evaluate_regression_model(model_name, model, X_train, X_test, y_train, y_test):
model.fit(X_train, y_train)
pred_train = model.predict(X_train)
pred_test = model.predict(X_test)
train_mae = mean_absolute_error(y_train, pred_train)
test_mae = mean_absolute_error(y_test, pred_test)
train_rmse = mean_squared_error(y_train, pred_train, squared=False)
test_rmse = mean_squared_error(y_test, pred_test, squared=False)
train_r2 = r2_score(y_train, pred_train)
test_r2 = r2_score(y_test, pred_test)
return {
"model_name": model_name,
"train_mae": train_mae, "test_mae": test_mae,
"train_rmse": train_rmse, "test_rmse": test_rmse,
"train_r2": train_r2, "test_r2": test_r2,
"model": model,
"pred_train": pred_train,
"pred_test": pred_test,
}
def train_models(X, y, cv_folds=5, cv_sample=50000):
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42,
)
preprocessor = build_preprocessor(X)
models = build_models(preprocessor)
# 循环 evaluate → joblib.dump → 保存 test 预测 → 选最佳 RMSE → model_metrics.csv → 绘图 ...
8.8 在其他 Python 文件中调用模型
# -*- coding: utf-8 -*-
import joblib
import pandas as pd
model_path = r"models/best_score_model.joblib"
x_path = r"outputs/score_prediction_no_avg/model_dataset.csv"
model = joblib.load(model_path)
df = pd.read_csv(x_path, encoding="utf-8-sig")
if "target_mes_Score" in df.columns:
X = df.drop(columns=["target_mes_Score"])
else:
X = df.copy()
pred = model.predict(X)
df["predicted_score"] = pred
df.to_csv(r"outputs/score_prediction_no_avg/call_model_result.csv", index=False, encoding="utf-8-sig")
9. 模型训练与命令
python train.py --mode train
训练过程包含:读表、构造 X/y、划分数据集、三套 Pipeline 训练、计算 MAE/RMSE/R²、保存 models/*.joblib、保存 model_metrics.csv 与测试集预测、导出图表。
10.模型评估指标
MAE: 1n∑∣yi−y^i∣\frac{1}{n}\sum |y_i - \hat{y}_i|n1∑∣yi−y^i∣,越小越好。
RMSE: 1n∑(yi−y^i)2\sqrt{\frac{1}{n}\sum (y_i - \hat{y}_i)^2}n1∑(yi−y^i)2,对大误差更敏感。
R²: 越接近 1,相对均值基线的改进越大。
11.实验结果
11.1线性回归模型
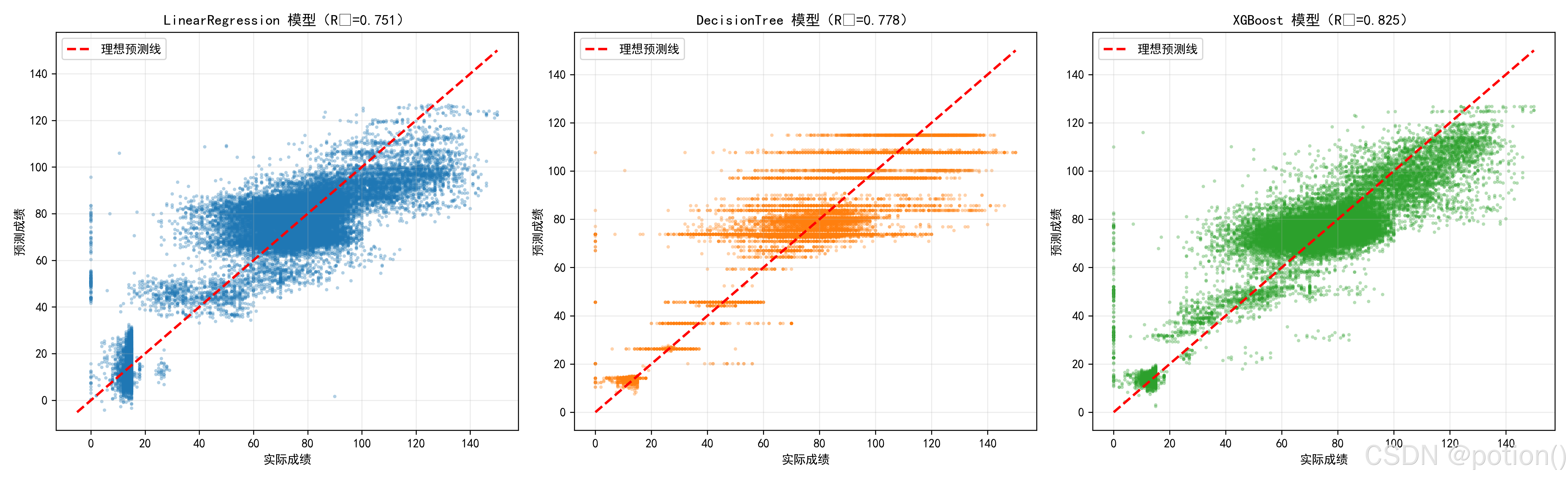
交叉验证箱线图结果表明,该线性回归模型在不同数据划分下的 MAE、RMSE 与 R² 指标分布集中,均值与中位数基本重合,无明显异常波动,说明模型预测误差稳定、泛化能力良好,整体性能具有较强鲁棒性。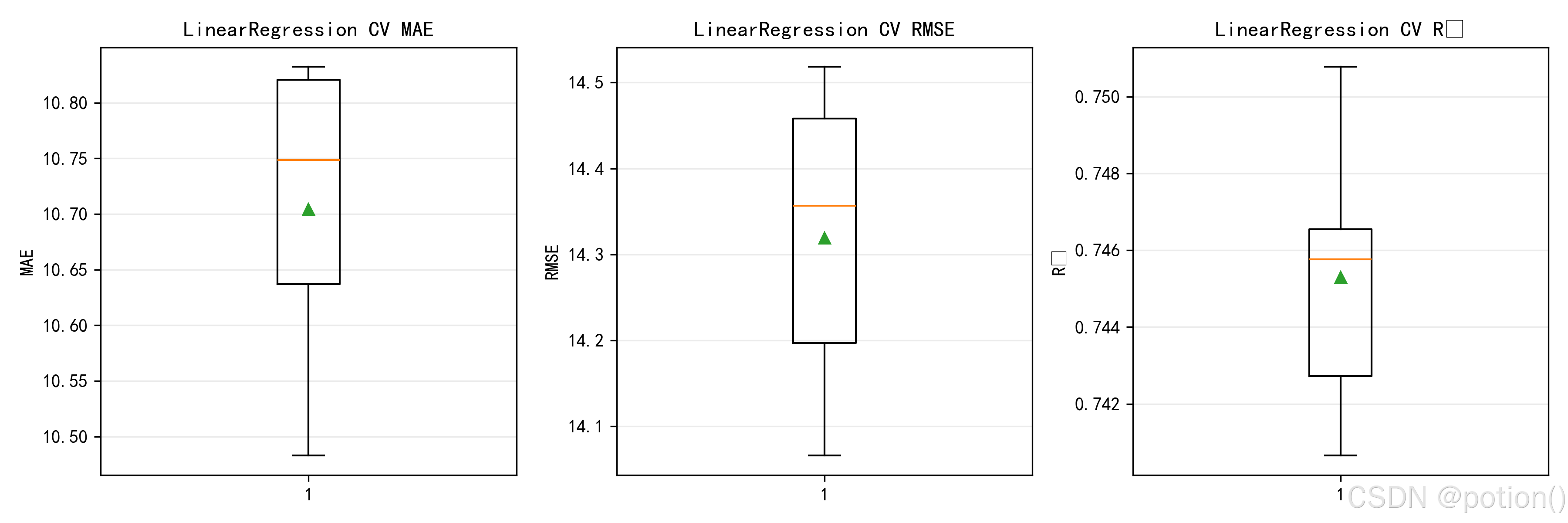
真实值 - 预测值散点图显示,样本点整体沿理想预测线分布,与 R²=0.751 的结果一致,模型对数据的整体解释力较强;但低分段样本存在一定的系统性高估现象,说明模型对低分数据的拟合能力仍有提升空间。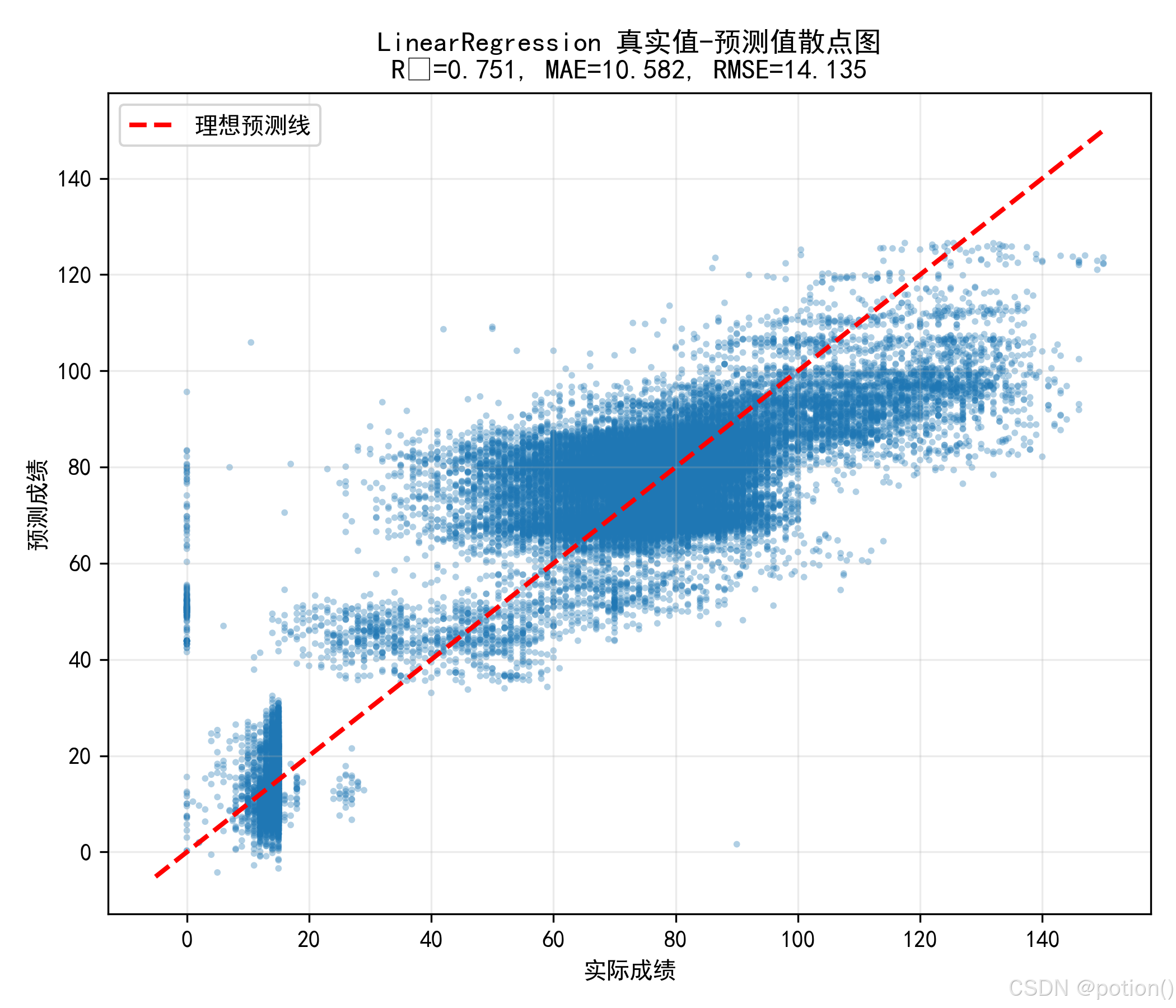
11.2 决策树模型
交叉验证箱线图结果表明,该决策树模型在不同数据划分下的 MAE、RMSE 与 R² 指标分布集中,均值与中位数基本重合,无明显异常波动,模型预测误差稳定、泛化能力良好;与线性回归模型相比,其误差指标更低、R² 更高,整体预测性能更优。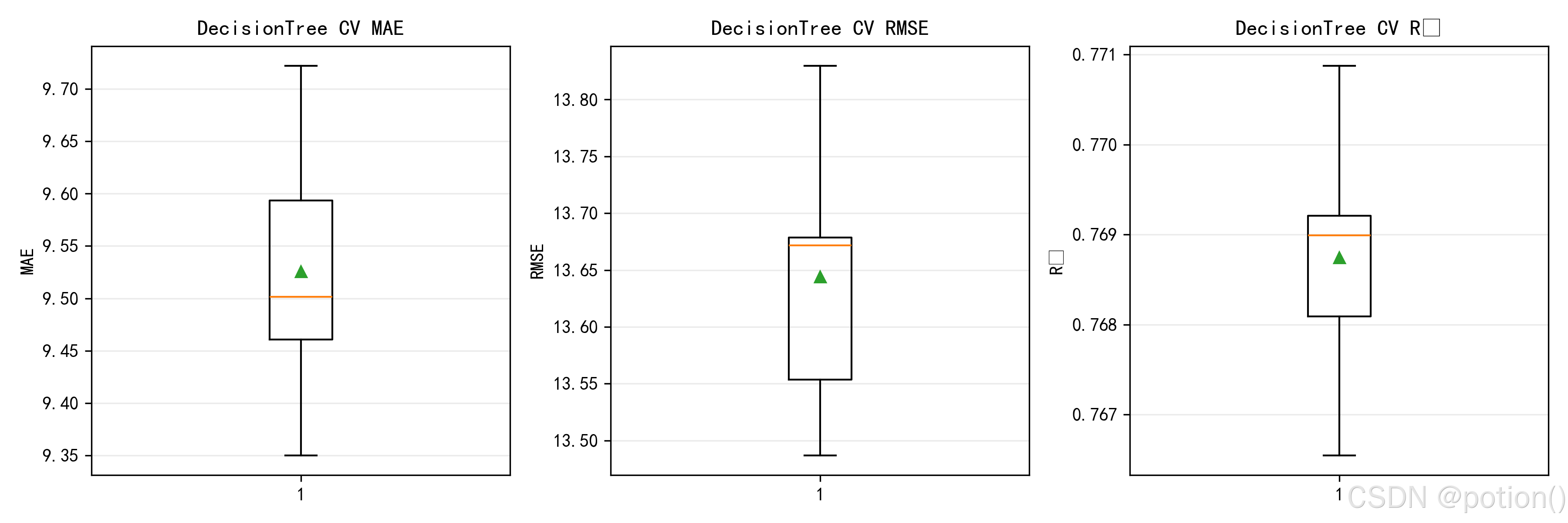
真实值 - 预测值散点图显示,样本点整体沿理想预测线分布,与 R²=0.778 的结果一致,模型对数据的整体解释力较强;但受决策树离散输出特性影响,预测值存在明显的阶梯状分布,对连续成绩的精细化拟合能力仍有提升空间。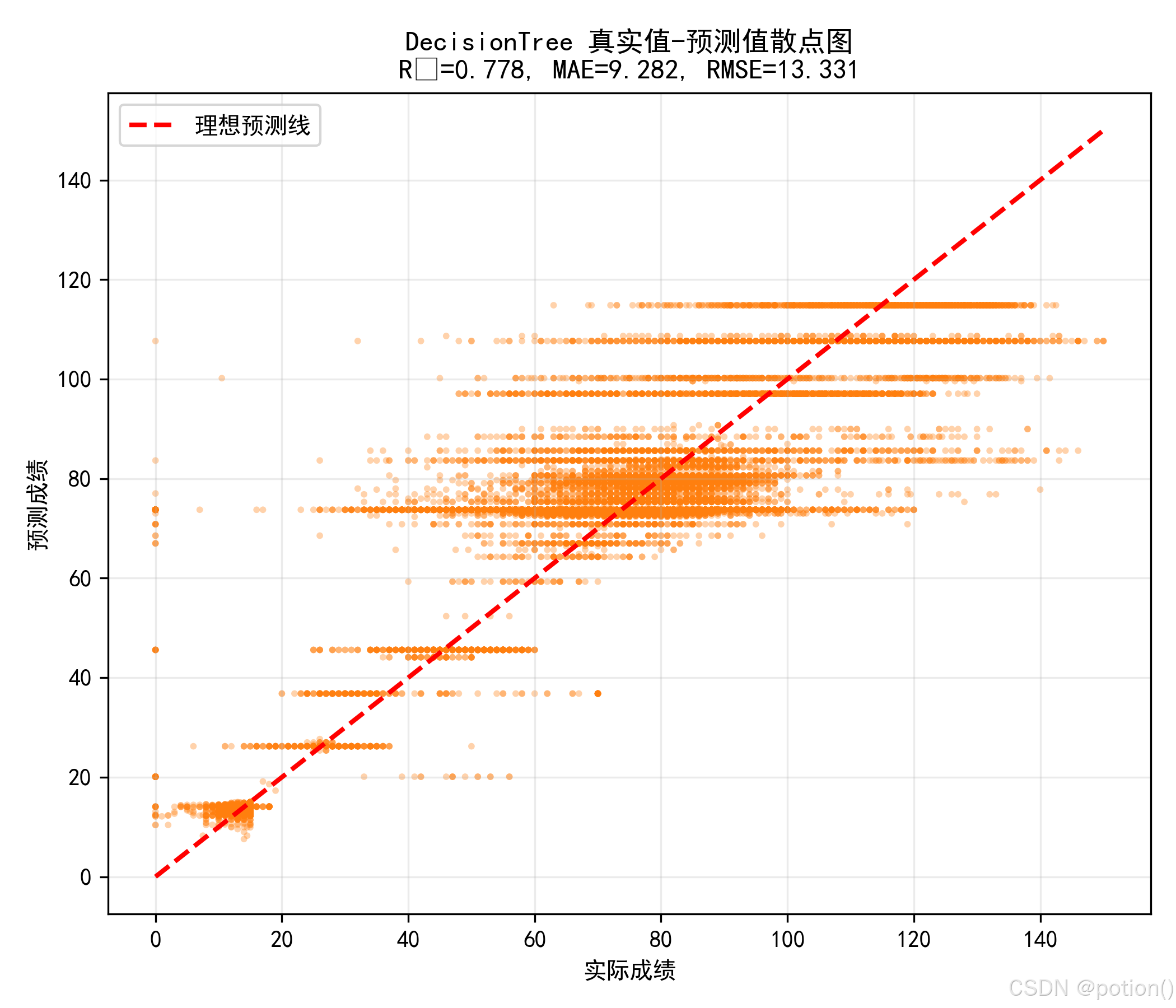
11.3 XGBoos模型
交叉验证箱线图结果表明,该 XGBoost 模型在不同数据划分下的 MAE、RMSE 与 R² 指标分布集中,均值与中位数基本重合,无明显异常波动,模型预测误差稳定、泛化能力良好;与线性回归和决策树模型相比,其误差指标最低、R² 最高,整体预测性能最优。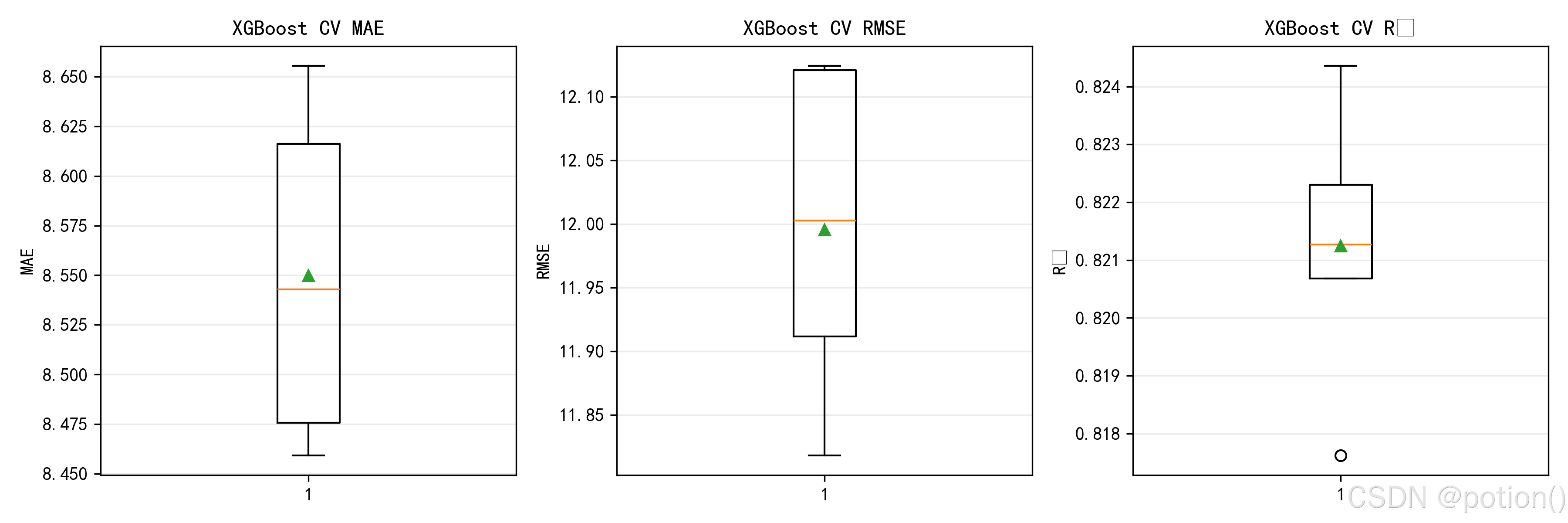
真实值 - 预测值散点图显示,样本点紧密沿理想预测线分布,与 R²=0.822 的结果一致,模型对数据的整体解释力显著提升;同时低分段样本的系统性高估问题得到明显改善,无明显阶梯状分布,对连续成绩的精细化拟合能力在三个模型中表现最佳。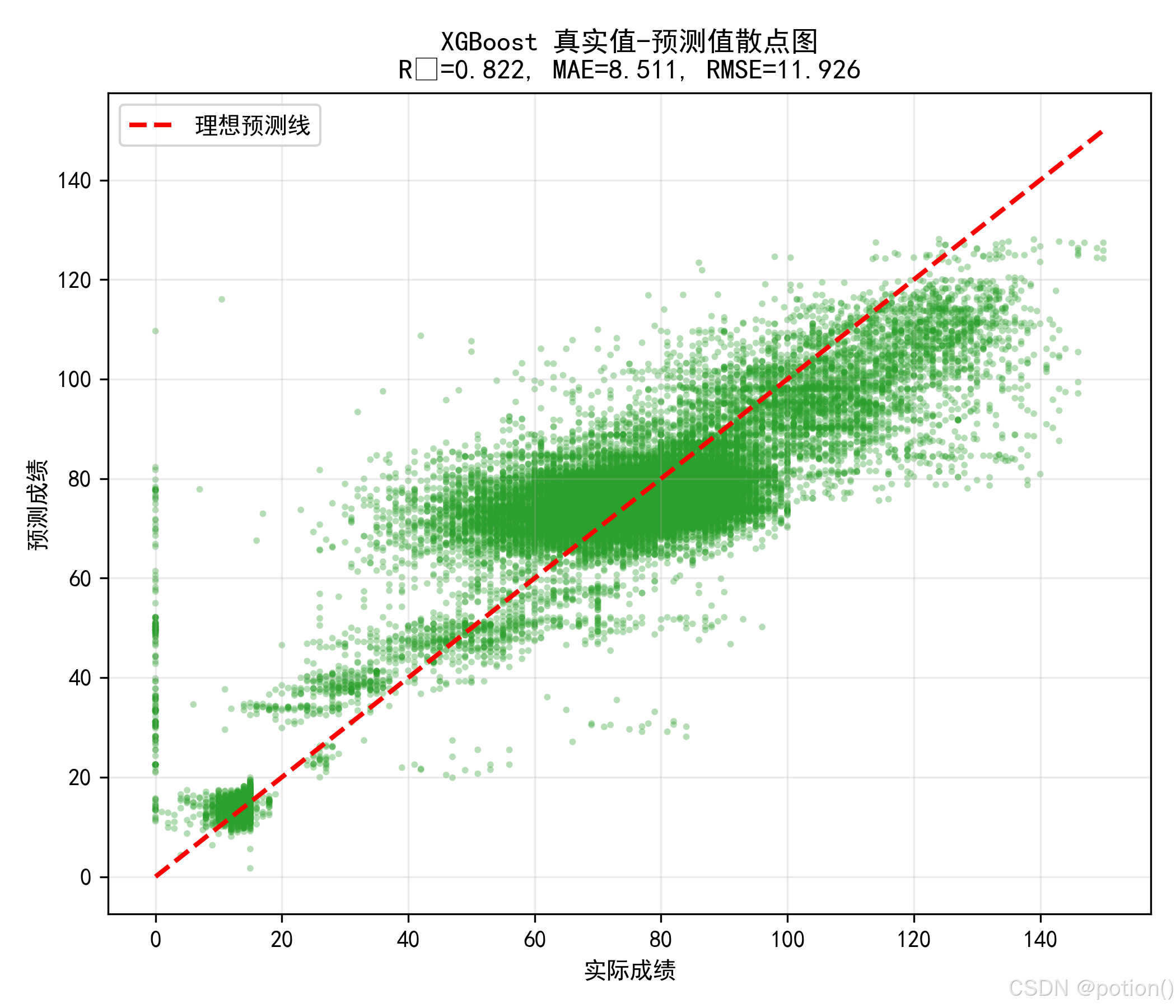
11.4 多模型对比
1. 指标量化分析(基于柱状图)
直接通过数据对比,给出结论。
性能排序: 在 MAE(平均绝对误差)和 RMSE(均方根误差)两项指标上,表现优劣排序一致为:XGBoost > 决策树 > 线性回归。
误差降幅: 重点描述最优模型比基准模型提升了多少。
例如:XGBoost 的 MAE 约为 8.51,相比于线性回归的 10.58,误差降低了约 19.6%。
RMSE 的表现同样证明了 XGBoost 对大误差样本的控制力更强。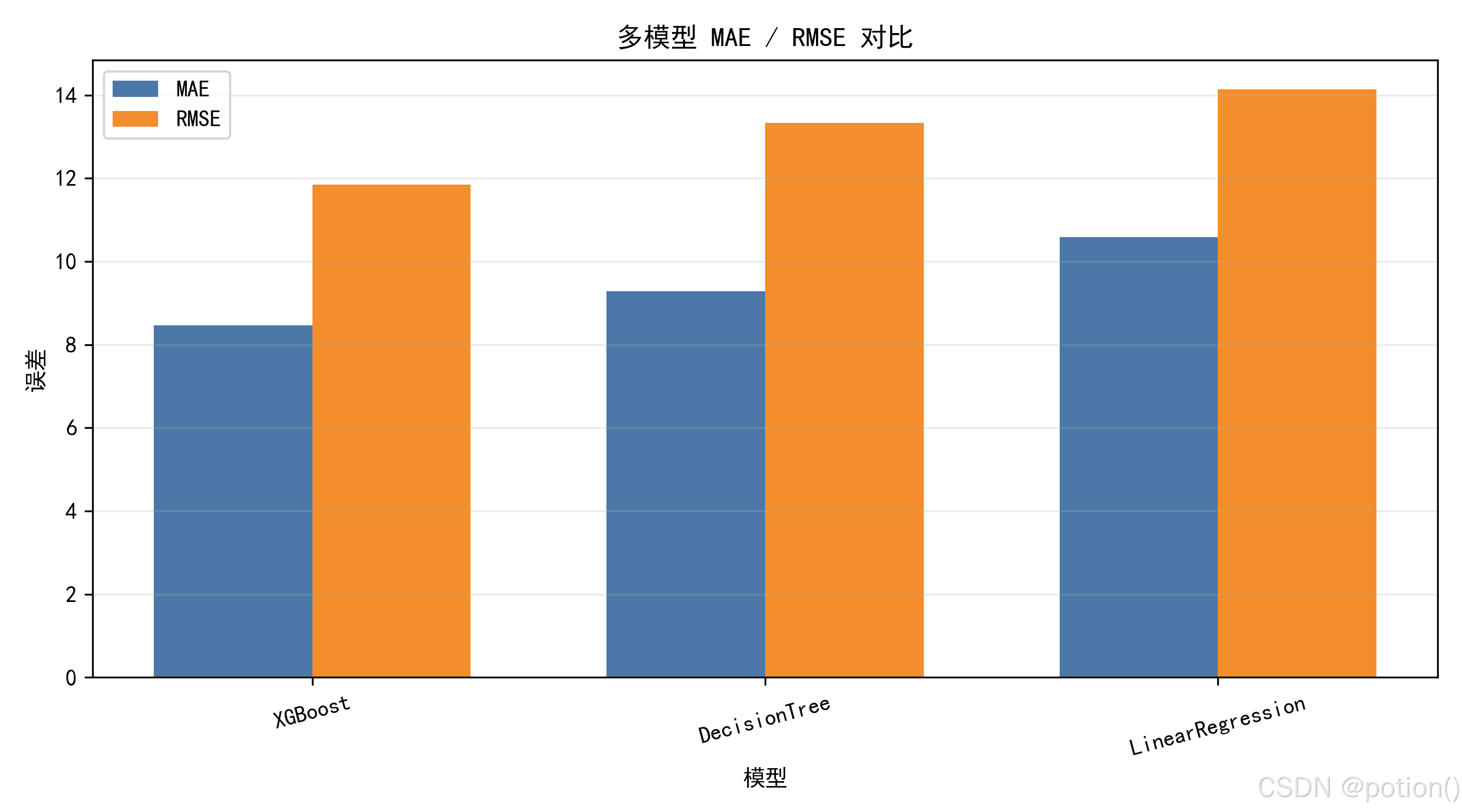
2. 拟合能力与数据特性分析(基于散点图)
通过观察散点图的形态,分析模型对真实成绩的还原度。
线性回归(基准): 散点最为弥散,且在低分段和高分段都有明显的偏离。这说明学生成绩与特征之间并非简单的线性关系,单纯的加权求和无法捕捉复杂的表现规律。
决策树(阶梯效应): 散点呈现明显的横向条纹状(阶梯状)。这是由决策树通过阈值划分导致的离散输出特性引起的。虽然 R²有所提升,但对于连续的成绩预测来说,这种“分段式”预测不够精细。
XGBoost(最优): 散点最紧密地围绕在红色对角线(理想预测线)周围,R²达到了 0.825。它不仅解决了线性回归的欠拟合问题,也通过集成学习克服了单棵决策树的粗糙感,拟合曲线更平滑、更精准。
11.5 最优模型分析
通过对比分析可知,XGBoost模型为本次实验中性能最优模型。
XGBoost 模型的残差分布散点图显示,大部分样本的残差随机分布在零线附近,无明显的异方差现象,模型整体误差分布稳定。但在低分段成绩预测中,残差呈现明显的负向线性趋势,说明模型对低分样本存在系统性高估;同时高分段样本的残差离散度有所增大,预测稳定性略有下降,后续可通过特征优化或针对性数据处理进一步改善。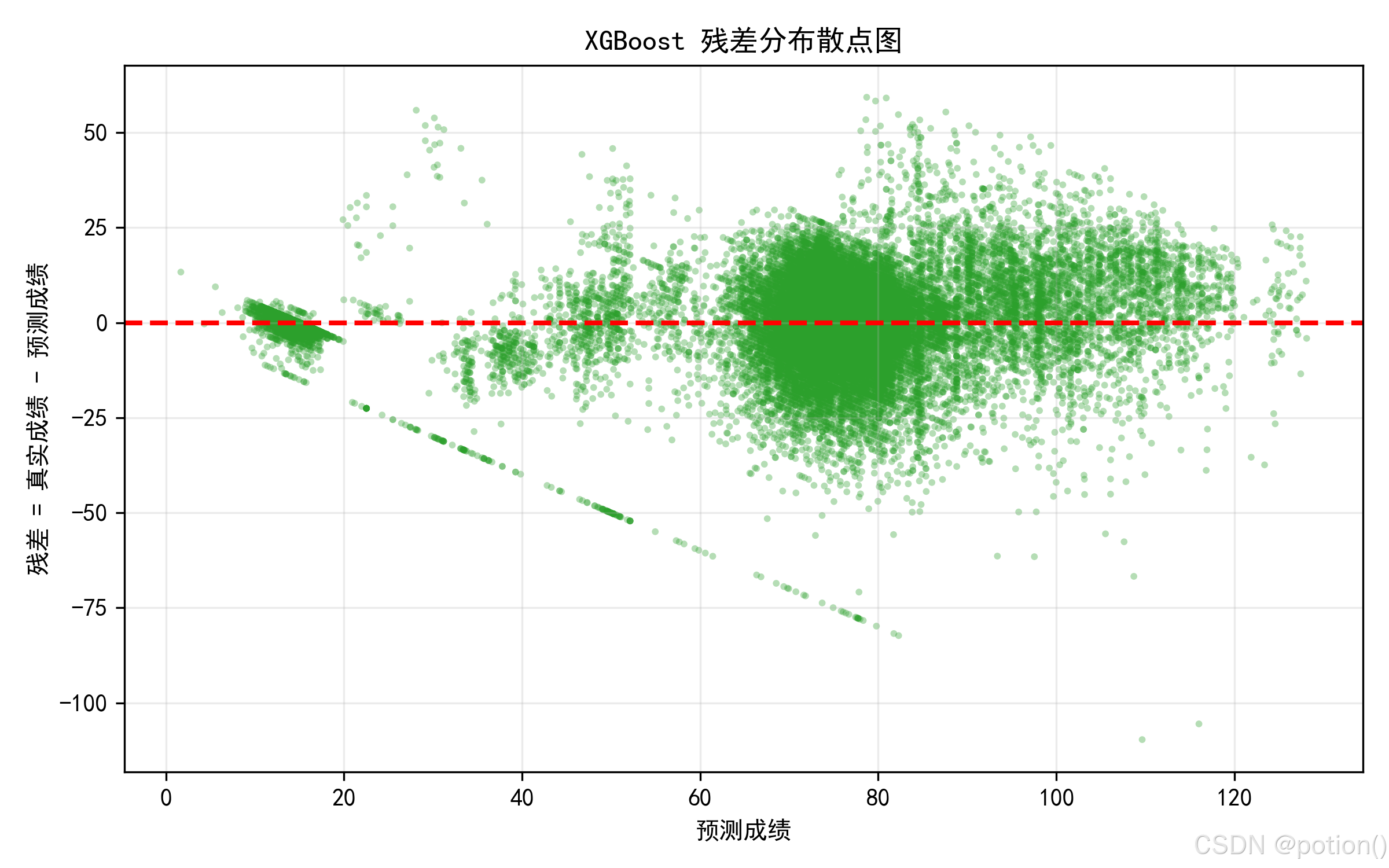
模型残差直方图显示,残差整体呈近似正态分布,峰值集中在 0 附近,说明大部分样本的预测误差较小,整体拟合质量较高;结合残差散点图进一步分析,低分段成绩预测存在明显的系统性高估趋势,而高分段样本的残差离散度有所增大,后续可针对性优化模型对极端样本的拟合能力。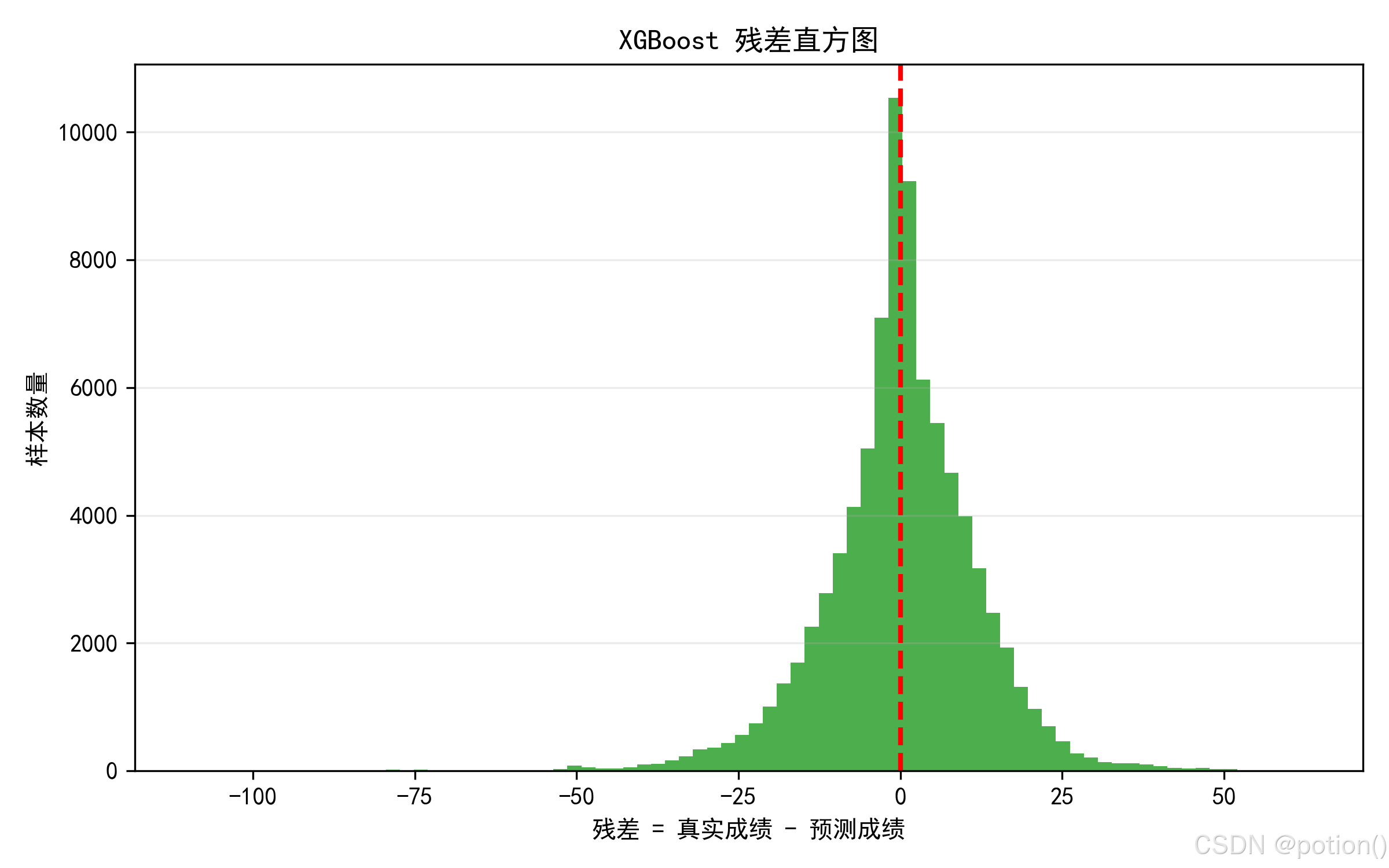
XGBoost 模型特征重要性条形图如下:
从图里能看到,前 4 个特征的重要性占比远超其他所有特征,加起来超过了0.68,是模型预测成绩的核心依据:
TOP1:EXAM_KIND_NAME_平时(总评用)(重要性≈0.198)
TOP2:EXAM_KIND_NAME_平时1(重要性≈0.181)
TOP3:exam_type_4(重要性≈0.158)
TOP4:exam_type_22(重要性≈0.126)
这直接说明:“平时成绩 / 过程性评价” 和 “特定考试类型”,是模型判断学生成绩最关键的信息,远超过单次大型考试(如模拟考、联考)的影响。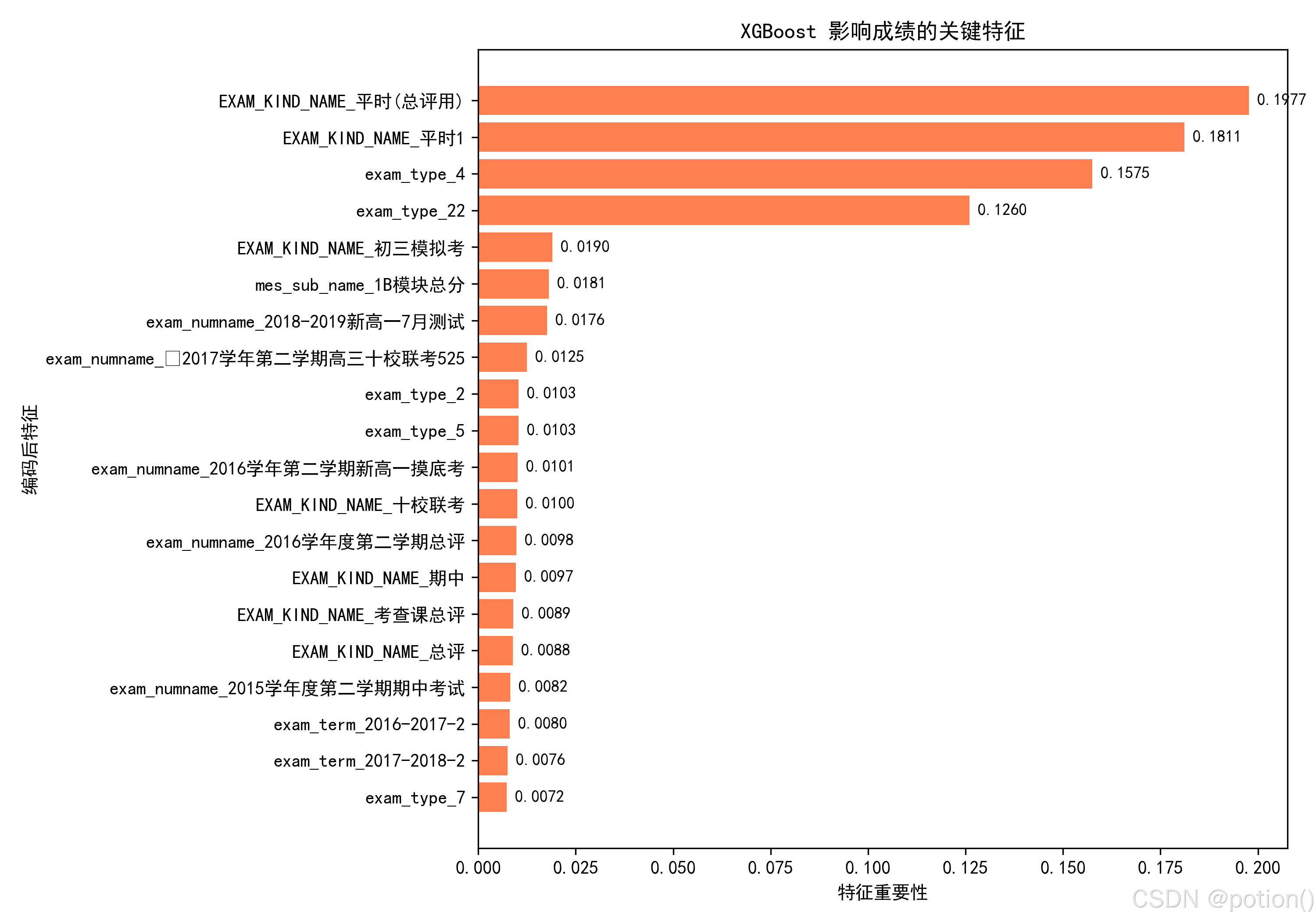
12.关键结论解读
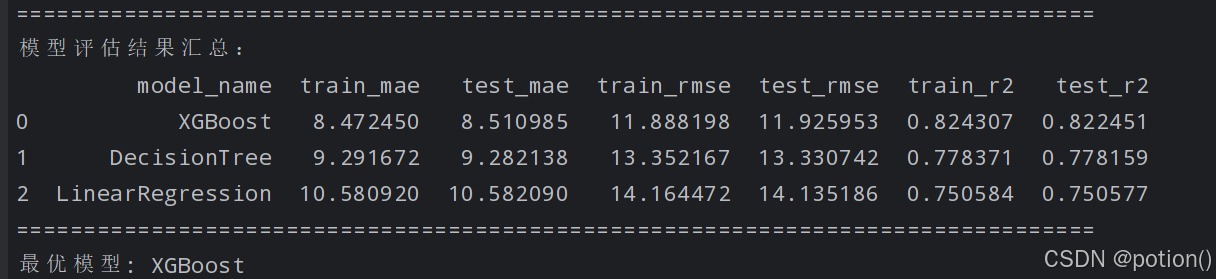
12.1 预测精度:XGBoost 全面领先
XGBoost 在测试集上的 MAE(8.51)、RMSE(11.93)均为三者最低,R²(0.822)最高,相比线性回归,误差降低约 19.6%,R² 提升约 9.5%,说明模型对数据的拟合能力和预测准确性显著优于另外两个模型。
12.2 泛化能力:三个模型均无明显过拟合
三个模型的训练集与测试集指标几乎无差异,例如 XGBoost 的训练 / 测试 R² 仅差 0.002,说明模型未出现过拟合,在 unseen 数据上的表现稳定可靠。
12.3 模型特性差异
线性回归:作为基准模型,性能最弱,说明数据中存在明显的非线性关系,简单线性模型无法充分捕捉。
决策树:性能居中,相比线性回归有提升,但受限于单棵树的表达能力,对复杂模式的捕捉能力弱于集成模型。
XGBoost:通过梯度提升的集成学习方式,有效捕捉了数据中的非线性特征,同时保持了良好的泛化能力,是本次任务的最优模型。
13. 未来优化方向与展望
13.1 特征工程的进一步挖掘
时序特征增强:目前主要使用了静态聚合特征,未来可以引入成绩变化趋势(如前三次考试的斜率)来捕捉学生的进步或退步状态。
细粒度考勤分析:目前的考勤特征较为宏观,未来可以分析特定学科前的考勤表现(例如:英语课前的迟到率是否与英语成绩有更强的关联)。
13.2 模型算法的进阶尝试
深度学习引入:尝试使用 TabNet 或神经网络模型,探索在大规模样本下是否能进一步压低 RMSE。
模型解释性增强:引入 SHAP (SHapley Additive exPlanations) 值分析,为每一位学生的预测分数提供具体的“扣分项”或“加分项”解释,辅助老师进行精准谈话。
13.3 业务场景的落地应用
学业风险预警系统:将模型部署为自动化服务,在每次考试前根据近期的消费和考勤数据,自动推送“潜在成绩下滑风险”名单给班主任。
异常得分检测:利用预测分与真实分的偏差,识别出“发挥超常”或“发挥失常”的学生,帮助学校筛选需要心理疏导或学习方法指导的个案。
13.4 数据质量的闭环优化
解决低分段高估问题:针对目前模型对低分样本预测偏高的问题,计划采集更多关于学生心理状态、家庭背景或课堂表现的维度,以填补这部分信息的空白。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)