拆解大语言模型的“慢思考”——从思维链到思维树的技术演进
引言:当“脱口而出”遇上“需要算一算”
想象你问一个大模型:“一个农场有鸡和兔子共35个头、94只脚,鸡和兔各几只?”如果让模型直接给出答案,它可能会在一秒内吐出一个错误数字。但如果你允许它“先想一想”,它会自己列出方程、代入求解,最后得出正确的23只鸡和12只兔。
这个差异揭示了大型语言模型的一个核心张力:它们的底层架构是为了“快速生成下一个token”而优化的,擅长模式匹配和语感直觉,却不擅长需要多步逻辑推导的系统化推理。让模型“慢下来”,把隐式的、压缩在一次前向传播中的思考过程,展开为显式的、可审视、可纠错的符号化推理链条——这就是思维链(Chain-of-Thought,CoT)技术的出发点,也是近年来大模型推理能力跃升的关键引擎。
一、标准提示的困境:为什么“直接回答”不够用
在CoT出现之前,想让大模型解决推理问题,主流方法只有两种:
1. 零样本直接回答:直接给出问题,期望模型输出答案。这种方式在简单任务上表现尚可,但面对多步推理时,模型本质上是在“猜”一个看起来合理的答案。它没有机会将问题拆解、检验中间步骤,一旦某一步的逻辑隐含错误,整个答案就崩塌了。
2. 少样本标准提示:提供几个“问题→答案”的示例对,让模型照猫画虎。比如:
text
问题:罗杰有5个网球,又买了2罐网球,每罐3个。他有多少个网球? 答案:11 问题:食堂有23个苹果,用了20个做午餐,又买了6个,现在有多少个? 答案:9
然后再接上目标问题。这种方式的局限在于,示例只展示了“输入-输出”的模式映射,并没有展示从输入走到输出所需的推理过程。模型学到的只是“给出一个数字作为答案”的格式,而不是“如何一步步推导出这个数字”。
实验数据显示,在需要多步推理的GSM8K数学题集上,即便用上了少样本标准提示,当时最大的语言模型PaLM 540B的准确率也仅徘徊在33%左右——比随机猜好一些,但远称不上可靠。
二、少样本思维链:展示“解题草稿纸”的力量
2022年,Google Research的Wei等人在论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中做出了一个看似简单却深具启发的改变:在少样本示例中,不仅给出最终答案,更给出详细的、一步一步的推理过程。
不再是“问题→答案”,而是“问题→推理过程→答案”。一个典型的CoT示例长这样:
text
问题:罗杰有5个网球,又买了2罐网球,每罐3个。他有多少个网球?
推理:罗杰一开始有5个网球。
他买了2罐,每罐3个,所以买了2×3=6个网球。
5+6=11。
所以罗杰现在有11个网球。
答案:11
当提示中包含了数个这样的“带解题步骤”的示例,模型在面对新问题时,会自然地沿用这一模式:先输出推理步骤,再在最后给出答案。
效果有多惊人? 在GSM8K上,仅用8个CoT示例,PaLM 540B的准确率从标准少样本的约33%跃升至58%。而在更复杂的数学题集MATH上,准确率从标准提示的个位数百分比跃升到两位数,实现了质的跨越。更重要的是,这种提升并非渐进式的,而是从某个模型规模开始突然涌现——只有当参数量超过约100B时,CoT的效果才显著显现;在小模型上,加入推理步骤几乎没有帮助,甚至有时反而有害。
为什么展示“解题草稿”会如此有效? 有几种解释:
-
工作记忆外化:模型在生成推理步骤时,将中间计算结果以token的形式“写”在了上下文窗口中,后续步骤可以“看到”并利用这些中间结果。这相当于把模型的隐式记忆扩展到了显式的上下文窗口,有效扩大了可操作的计算空间。
-
路径约束:生成推理链的过程约束了最终答案的生成路径,迫使模型沿着更合理、更结构化的方向推进解码过程,减少了“跳跃到错误结论”的可能性。
-
模式诱导:大量预训练语料中本就包含人类写下的推导过程(数学题解、论坛讨论、代码注释),CoT提示激活了这些内化在参数中的推理模式表征。
三、零样本思维链:一句魔法咒语的诞生
少样本CoT有一个显著的局限性:必须为每类任务手动编写带推理步骤的示例。这不仅耗时,而且很难覆盖所有场景——你不可能为每一种可能的提问方式准备好示例。
2022年底,东京大学和Google的Kojima等人提出了一个极简方案,被称为零样本思维链(Zero-shot CoT)。做法出奇简单:不提供任何示例,只需在问题末尾追加一句触发语——“Let's think step by step”(让我们一步步思考)——其余一切不变。
就这简单一句话,让模型在没有看到任何解题示范的情况下,自主生成了多步推理链条,并在多个推理任务上取得了与少样本CoT相近甚至更优的表现。
随后研究发现,不同的触发语效果各异。像“Let's work this out in a step-by-step way”或“Before giving the answer, let's reason through this”等变体同样有效。它们的共同点是:在语义上暗示了一个“先拆解、再综合”的思维节奏,改变了模型输出序列的解码概率分布。
零样本CoT的内在机制:有分析认为,这种触发语并非让模型“学会了推理”,而是激活了预训练数据中大量存在的“分步解答”格式。模型在训练时见过无数的“Step 1, Step 2...”、“首先...其次...最后...”这样的结构化表达,触发语将这些模式从参数记忆的“暗处”拉到了“亮处”,改变了下一个token的生成偏好——从“直接跳到结论”转向“遵循分步展开的模式”。
当然,零样本思维链并非完美。它的主要缺陷包括:
-
推理幻觉:模型可能生成看似合理、实则错误的推理步骤,一步错则步步错。因为它只是在“模拟”推理的形式,而非真正检验每一步的正确性。
-
过度自信:模型对推理过程和最终答案的置信度无法自我校准,即使半途已出现逻辑矛盾,仍会坚持走向错误结论。
-
敏感脆弱:同一问题换个表述,推理质量可能剧烈波动,缺乏推理策略本身的鲁棒性。
四、自洽性:让多条推理链“投票”
单一推理链的不可靠性促使研究者寻找鲁棒性方案。直觉很朴素:既然一条推理链可能走偏,那生成了多条不同的链,让它们“民主投票”不就行了?
2023年初,Wang等人提出的自洽性(Self-Consistency)方法正是这一思想的体现。它的操作流程分三步:
-
采样多条推理链:对同一问题,用非零的温度参数(如0.7)多次调用模型,每次获得一条不同的推理路径及对应答案。
-
提取最终答案:从每条推理链的末尾提取出最终答案(通常是一个选项、一个数字或一个短句)。
-
多数投票:统计所有答案的出现频率,选择出现次数最多的那个作为最终输出。
自洽性的精髓在于一个关键洞察:对于正确的推理任务,虽然到达正确答案的“推理路径”可以有多条,但正确答案本身是唯一的。而错误推理往往导向分散的、不一致的答案。 多数投票自然地压低了偶然性错觉被采信的概率。
实验效果显著:在GSM8K上,自洽性将CoT的准确率进一步推高了5-10个百分点。在策略推理任务中(如国际象棋走子预测),提升更为明显。更重要的是,自洽性的效果随采样链数的增加而单调递增(尽管边际收益递减),为推理可靠性提供了可控的、可计算的提升路径。
自洽性也有它的变体:
-
加权投票:不只看答案频次,还对每条推理链的整体连贯性进行评估,赋予高连贯性链路更高的投票权重。
-
对比解码:同时运行标准提示和CoT提示,选取二者差异最大的部分作为可信度判断的依据。
五、思维树:从线性链到分支探索
上述方法都遵循一个前提:推理是一条“直线”——从问题出发,顺着一条路径走到结论。但真正的人类推理并非总是线性的。我们会在关键节点产生多个可能的思路,评估各自的可行性,选择最有希望的一个深入探索;如果发现走入死胡同,会回溯到上一个决策点换条路走。这是一种树状搜索的结构。
2023年,Yao等人将这一洞察系统化为思维树(Tree of Thoughts, ToT)框架,让LLM的推理从“单行道”升级为“立交桥”。ToT的工作机制包含四个核心循环:
1. 思维生成:在当前状态节点,模型生成多个候选的“下一步想法”。例如,在解决“如何用4个数字通过四则运算得到24”的24点游戏时,当前有数字[4, 9, 8, 2],模型可能生成这样的候选思维:
-
“先用8+4=12,还剩下9和2”
-
“先用9-2=7,还剩下4和8”
-
“先用4×2=8,还剩下9和8”
2. 状态评估:对每个候选思维进行评分,判断其未来走向成功的潜力。评估可以由模型自己完成(让模型给出“可能/不可能/很可能”的判断),也可以借助外部启发式函数。
3. 搜索策略选择:根据评估结果,决定下一步探索哪个节点。可采用广度优先搜索(同时探索多个分支)、深度优先搜索(沿一条路走到底再回溯),或更复杂的束搜索(每一层只保留评分最高的k个候选)。
4. 回溯与终止:如果到达某个节点后,所有后续候选思维都被评估为“无望”,则回溯到上一个决策点;如果某条路径达到了预设目标(如24点游戏中得到24),则终止搜索,输出该路径。
思维树在24点游戏上的表现堪称惊艳:GPT-4 + ToT的成功率达到74%,而仅用CoT提示的GPT-4只有不到4%。在创意写作任务中,ToT也让模型的规划能力、一致性和多步铺垫能力获得了可量化的大幅提升。
思维树的扩展还催生了思维图(Graph of Thoughts),即允许不同思维分支之间相互连接、融合成网状拓扑,思维不仅分叉,还能“汇合”与“重组”,探索效率进一步提高。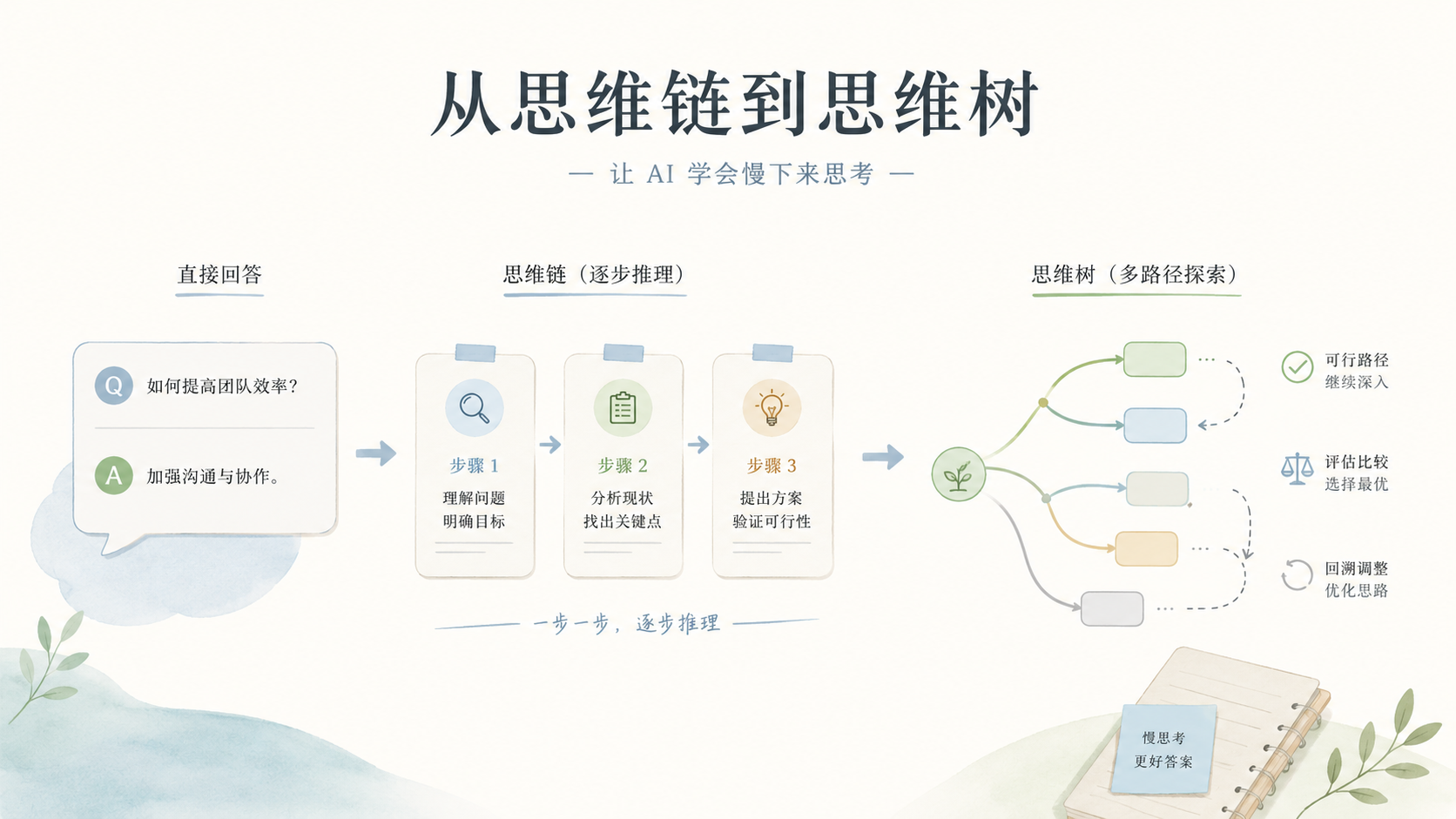
六、技术局限与现实困境
尽管思维链系列让LLM的推理能力经历了质的飞跃,但必须认识到其局限之深:
1. 模拟而非理解。CoT生成的推理“看起来像真的”,但模型并不理解符号背后的语义。它是在做统计模仿,而非逻辑演绎。这在涉及严格递归、精确计数、复杂集合运算的问题上暴露无遗——模型会写出令人啼笑皆非的完美推导过程,并在最后得出一个荒谬答案。
2. 推理幻觉的放大效应。在多步推理中,前一步的输出是后一步的输入。一个小的不准确在一连串放大后,最终偏差可以大到离谱。模型缺乏任何一步的“自我验算”能力——除非显式调用外部工具。
3. 高昂的计算开销。生成推理链需要大量自回归步骤,每一步都积累延迟与成本。思维树更进一步让推理成本与分支数、深度呈指数级膨胀。在实际应用中,对所有查询都启动CoT或ToT并不经济,必须引入一个“路由机制”来判断问题的复杂度,再决定是否启动“慢思考”模块。
4. 泛化边界模糊。CoT在数学、逻辑、规划等结构化领域效果好,在情感判断、审美评价等非结构领域效果有限甚至无益。推理策略的跨场景迁移仍是难题。
七、未来方向:走向可执行的推理
思维链技术的演进方向正在清晰浮现:让大模型不再是独自“想象”推理,而是能动手“执行”推理。
-
工具增强推理(Tool-Augmented Reasoning):模型在推理过程中主动调用计算器、代码解释器、搜索引擎等外部工具来验证中间步骤。这等于把最容易出错的“纯脑算”环节外包给了精确的外部系统。
-
形式化验证对接:让模型生成的推理链可以直接输入到定理证明器(如Lean、Coq)中进行形式化验证,实现“生成-验证-修正”的闭环。这是通往严格可信推理最具前景的路径之一。
-
过程奖励模型(Process Reward Model, PRM):OpenAI等机构正在研究的方案——不仅对最终答案打分,还对每一步中间推理步骤的正确性进行监督训练。这好比给推理过程的每一环都配上“质检员”,从根本上提升推理链的可靠性。
从“脱口而出”到“三思而行”,大模型的推理之旅才刚刚起步。而这场“慢思考”革命真正的终局,或许不是让AI学会像人一样思考,而是让AI学会如何调度一切可用的符号化、工具化和形式化资源,以远超人类精度的方式完成系统性推理。这过程中,思维链与其各项变体,正扮演着探路者的角色。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)