打开AI的黑盒:数百万特征如何自动聚集成可读知识图谱

Domain-Filtered Knowledge Graphs from Sparse Autoencoder Features
摘要
稀疏自编码器能从语言模型中提取数百万个可解释特征,但特征清单本身价值有限。本研究通过对比过滤和多阶段筛选构建严格的领域概念库,并构建两个对齐的图视图:语料库级共现图和跨层机制图,最终将混乱的特征转化为可读的知识图谱,实现了从特征级到全局知识结构的飞跃。
阅读原文或https://t.zsxq.com/wtW46获取原文pdf
一、为什么我们需要重新组织SAE特征
稀疏自编码器(Sparse Autoencoders, SAEs)的出现改变了我们理解语言模型的方式。不同于传统的黑盒神经元表示,SAE将模型内部激活分解为数百万个可解释的特征。如今,Gemma Scope和Llama Scope等开源套件已经将这项技术从小规模演示扩展到大规模公开特征库,跨越多个层级、包含数千至数十万个特征 。
然而,当我们超越简单的特征列表时,问题的本质发生了转变。我们不再仅仅关心有多少个特征,而是关心这些概念如何在模型内部组织和使用。这引出了三个具体问题 :
第一个问题是领域识别:在数万个特征中,哪些特征属于连贯的领域特定区域,而哪些只是反映通用的或根基薄弱的行为?许多高度活跃的特征实际上只是在追踪标点符号、格式化或宽泛的话语模式,而非真正的领域概念 。
第二个问题是全局组织:在确定了领域相关特征之后,这些概念在语料库层面上如何组织?哪些概念聚集在一起,哪些相互分离,哪些在相邻话题之间起桥接作用 ?
第三个问题是局部机制:在处理单个输入时,本地概念邻域如何演变?上游的哪些概念通过隐层机制支撑下游概念?一个句子可能激活跨越残差流的数千个特征,逐个检查它们无法提供有意义的洞察 。
原始的SAE特征库无法有效回答这些问题。语义相关的想法往往分散在多个相邻特征中,这既掩盖了概念在语料库层面的聚类和桥接方式,也使得理解局部概念邻域在下游计算中的实际使用变得困难 。
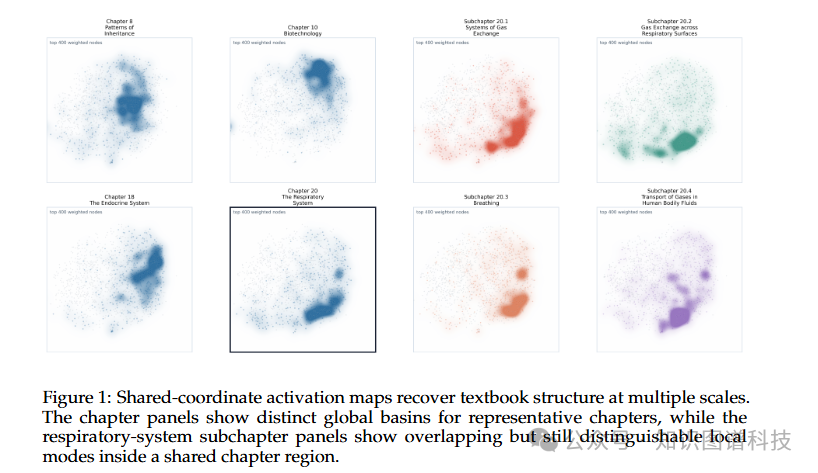
二、解决方案:从特征库到严格概念宇宙
为了解决这些问题,我们的研究构造了一个同时具有选择性和结构性的表示方法 。核心思路分为两个阶段:
第一阶段:对比过滤与候选筛选
我们从定义一个严格的领域特定概念宇宙开始。原始的SAE特征库V包含大量特征,但并非所有特征都与目标领域相关。我们通过与对比语料库的比较,基于三个维度过滤特征 :
首先是支持度(Support):该特征在目标语料库中是否有足够的存在?其次是丰富度(Enrichment):该特征是否比对比语料库中更具特征性?最后是定位性(Localization):该特征是否集中在连贯的章节或小节区域,而非随处散布?这些统计指标旨在移除明显的样板特征(如语法和句法特征),同时保持高召回率,但它们本身还不足以决定语义相关性 。
让我们用V表示候选库,V★表示保留的严格概念宇宙。本文中的所有后续图都建立在V★而非原始库V之上 。
第二阶段:证据包验证与语义确认
对于进入候选集合的每个特征,我们将其转换为证据包,并确定该特征是否对应于一个可见的、领域相关的、对比区分的概念。这一步骤确保了最终概念宇宙中的每个节点都经过了严格的验证 。
三、双图视图:结构与机制的统一表示
在严格概念宇宙的基础上,我们构建了两个对齐的图视图,分别捕捉全局结构和局部机制 。
第一个视图:多粒度共现图
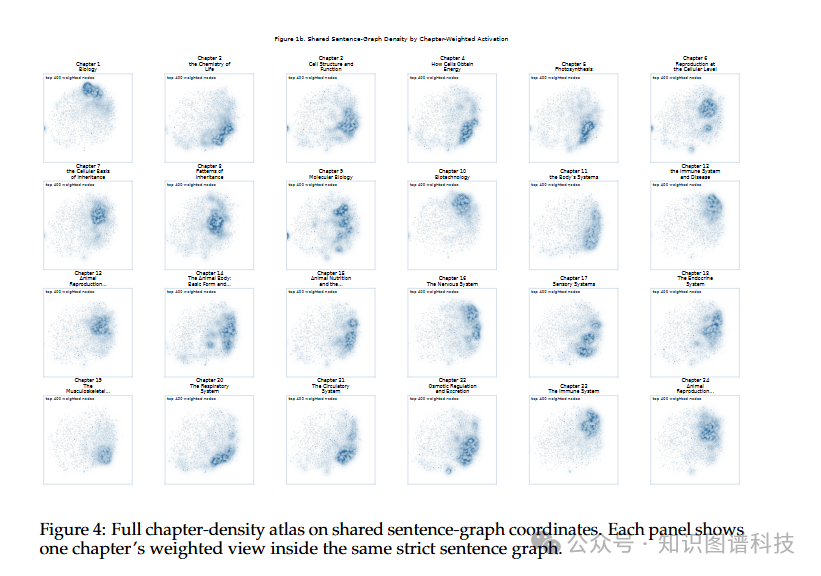
共现图在语料库层面揭示概念的组织方式。这个图不是简单的无标签布局,而是经过分层压缩组织的多粒度结构。概念根据在语料库中的共现模式自然聚集,形成不同层级的组织:从细粒度的子章节级概念关系,到中粒度的主题级聚类,再到粗粒度的整体领域结构。这种多尺度组织使得我们既能看到森林,也能看到树木 。
第二个视图:转录器机制图
机制图建立在转录器(Transcoder)基础上,连接源层和目标层的特征。转录器是一个特殊的架构,它通过稀疏潜层通路将一个层的激活转换为另一个层的激活。通过这个视角,我们可以追踪概念如何在层间流动和转化,理解上游概念如何支撑下游推理 。这与电路追踪和转录器机制工作的精神接近,但我们的目标不同。电路追踪论文寻求特定提示的因果或准因果图;而我们构建的是一个可重用的、领域过滤的图框架,其可见的源到目标边是潜层中介结构的可读投影 。
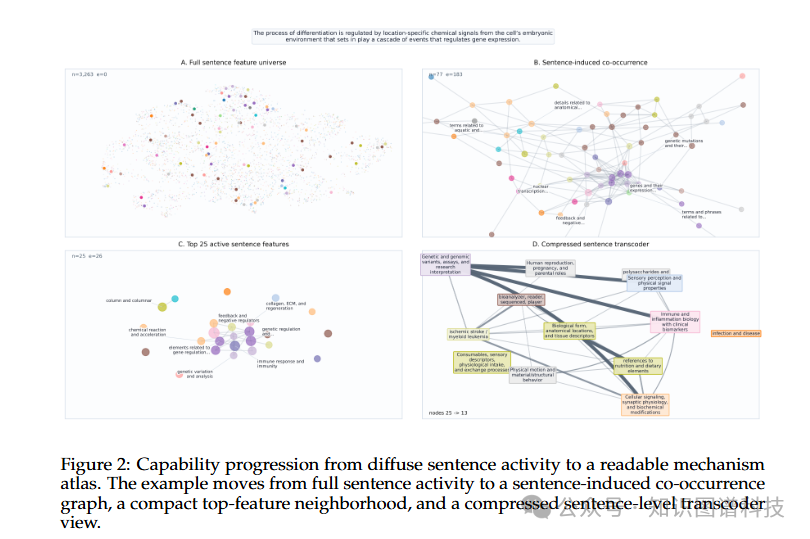
四、边标注:从无标签图到可读知识图谱
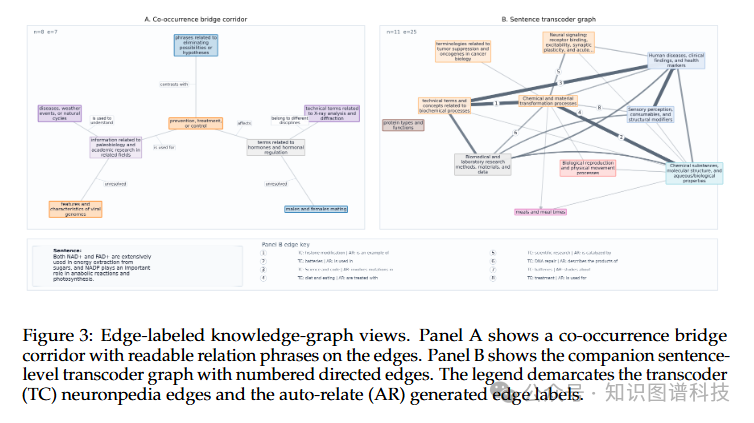
仅有结构还不够。我们进一步为这两个图的边自动添加标签,将其转化为真正的知识图谱而非单纯的拓扑布局 。
这一步骤的灵感来自传统知识图谱和关系抽取研究。经典知识图谱如Freebase、NELL和Wikidata将信息表示为由关系三元组连接的实体,激发了从文本中进行知识库填充的广泛研究 。但我们的设置不同——我们不是从命名实体或文档级事实中提取外部世界知识图谱,而是在SAE特征上诱导内部图,然后为机制诱导边附加证据支持的标签 。
边标注包括多个维度的信息:关系类型、机制解释、证据支持等。这使得最终的知识图谱不仅展示了特征之间的结构关系,还说明了这些关系的机制基础。
五、多层次压缩:从混乱活动到可读地图
实践中的一个关键挑战是密度。在生物学教科书的案例研究中,一个句子可能激活跨越残差流的数千个特征。直接呈现这个活动模式对人类理解毫无帮助。因此,我们提出了分层压缩策略 。
通过这种压缩,我们可以将句子级的混乱激活转化为紧凑、可读的机制图谱,清晰地说明模型在该输入上的局部活动。这个过程类似于从显微镜级别的细胞活动升级到器官级别的功能视图——我们既保留了机制细节,又获得了可理解的整体图景。
六、案例研究:生物学教科书的应用
我们在生物学教科书上测试了整个框架 。结果展现了系统的三个关键能力:
章节结构恢复:共现图成功恢复了教科书的章节和小节级结构。这不是通过外部元数据导入实现的,而是从语言模型对文本的内部特征激活中自然浮现的。这表明模型确实在某种程度上"学习"了教科书的组织原理。
概念桥接识别:系统识别了那些在相邻主题之间起桥接作用的概念。这些概念可能比其他概念更有趣,因为它们展示了看似不同领域之间的联系。
机制图谱生成:对于单个句子的激活,系统生成了紧凑、可读的机制图谱,清晰展示了数千个特征如何通过相对较少的关键概念节点有效传输推理。
七、深层意义:从特征可解释性到模型知识审计
这项工作的核心贡献超越了技术层面。它将特征级的可解释性转化为全局知识结构的地图 。
从研究的角度,这意味着我们可以进行模型知识和推理忠实性的审计。我们不再只是知道某个特征是什么,而是知道它在模型整体概念架构中的位置,它与其他概念的关系,它如何参与推理流程。这种层次上的理解对于我们评估模型在特定领域的理解深度、识别潜在的知识盲点或推理缺陷至关重要。
从实践的角度,这个框架为多个应用场景打开了可能:
首先是模型审计和风险评估。对于部署在关键应用中的模型,我们需要理解它对特定领域的真实理解程度。通过知识图谱的显式结构,我们可以检查模型是否遗漏了关键概念、是否存在错误的概念关联、是否在推理链中存在薄弱环节。
其次是模型对比和选择。当面对多个候选模型时,我们可以比较它们的知识图谱。哪个模型拥有更完整的概念覆盖?哪个模型的概念之间关系更正确?这提供了比单纯性能指标更深层的对比维度。
第三是针对性改进。知识图谱的显式结构帮助我们识别模型中的特定薄弱点。我们可以针对性地进行数据增强、微调或其他改进,而不是盲目地优化整体性能。
八、与现有工作的关系与创新点
这项工作建立在多个研究领域的基础之上,但有显著的创新 。
与SAE几何工作的关系:先前的SAE几何研究展示了特征空间具有有意义的几何结构 。但仅仅理解几何是不够的。我们的贡献在于,我们不仅研究几何,还首先为特定语料库定义严格的保留概念宇宙,然后在其上构建多个图视图。这将结构化组织与机制关系连接起来,而单纯的几何或主题模型都无法提供这种连接。
与电路追踪工作的关系:机制工作和转录器研究已经将特征发现推向解释性图谱 。电路追踪通常寻求特定提示的因果或准因果图。我们的方法不同——我们构建的是可重用的、领域过滤的框架,其可见边是潜层结构的可读投影,而非特定提示的原因追踪。
与知识图谱工作的关系:传统知识图谱从文本中提取实体和关系。我们的设置相关但根本不同——我们在SAE特征上诱导内部图,而非从外部知识中提取。关系抽取工作主要影响了我们的边标注层,而节点宇宙和候选边来自激活结构和转录器中介特征流 。
九、实现挑战与解决方案
整个框架的实现涉及多个技术挑战:
第一个挑战是规模。我们处理的是数十万级的特征。构建和可视化这么大的图,并确保其可读性,需要精心设计的数据结构和可视化策略。
第二个挑战是验证。如何确保我们的概念过滤和边标注是准确的?这需要可靠的评估指标和人类验证流程。
第三个挑战是可解释性。最终的知识图谱应该能够被人类理解和信任。这意味着我们需要为每条边提供清晰的证据,使用清晰的概念标签,提供多层次的视图供不同深度的检查。
十、对企业和机构的实践意义
对于关注模型可解释性和安全性的企业和研究机构,这项工作提供了切实的应用价值:
第一,用于合规和监管。随着AI监管日益严格,企业需要展示模型行为的可解释性。知识图谱提供了一种结构化的方式来展示模型的知识和推理过程。
第二,用于质量保证。在部署关键应用前,企业可以使用这个框架审计模型的领域知识覆盖和推理质量。
第三,用于定向改进。通过识别知识图谱中的缺陷,企业可以有针对性地改进模型,而不是在模糊的整体指标上进行优化。
第四,用于模型选择。当评估多个候选模型时,知识图谱提供了比单纯准确率更全面的对比维度。
十一、未来方向与局限
这项工作虽然显著推进了我们对模型内部结构的理解,但也存在局限和未来方向:
一个局限是方法的语料库特异性。当前框架针对特定语料库(生物学教科书)构建。如何扩展到多个领域、处理领域交界处的概念,需要进一步研究。
另一个局限是人工验证的需求。虽然我们进行了自动过滤和标注,但最终的验证仍需人类专家参与。这限制了方法的规模化应用。
未来的一个重要方向是动态图维护。随着模型训练数据的更新或模型本身的改进,知识图谱也需要动态更新。如何高效地维护和演进这些图是一个开放问题。
另一个重要方向是跨模型的知识图谱对比。不同的模型可能学到不同的概念组织方式。比较这些图可能揭示模型架构或训练数据对内部知识组织的影响。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)