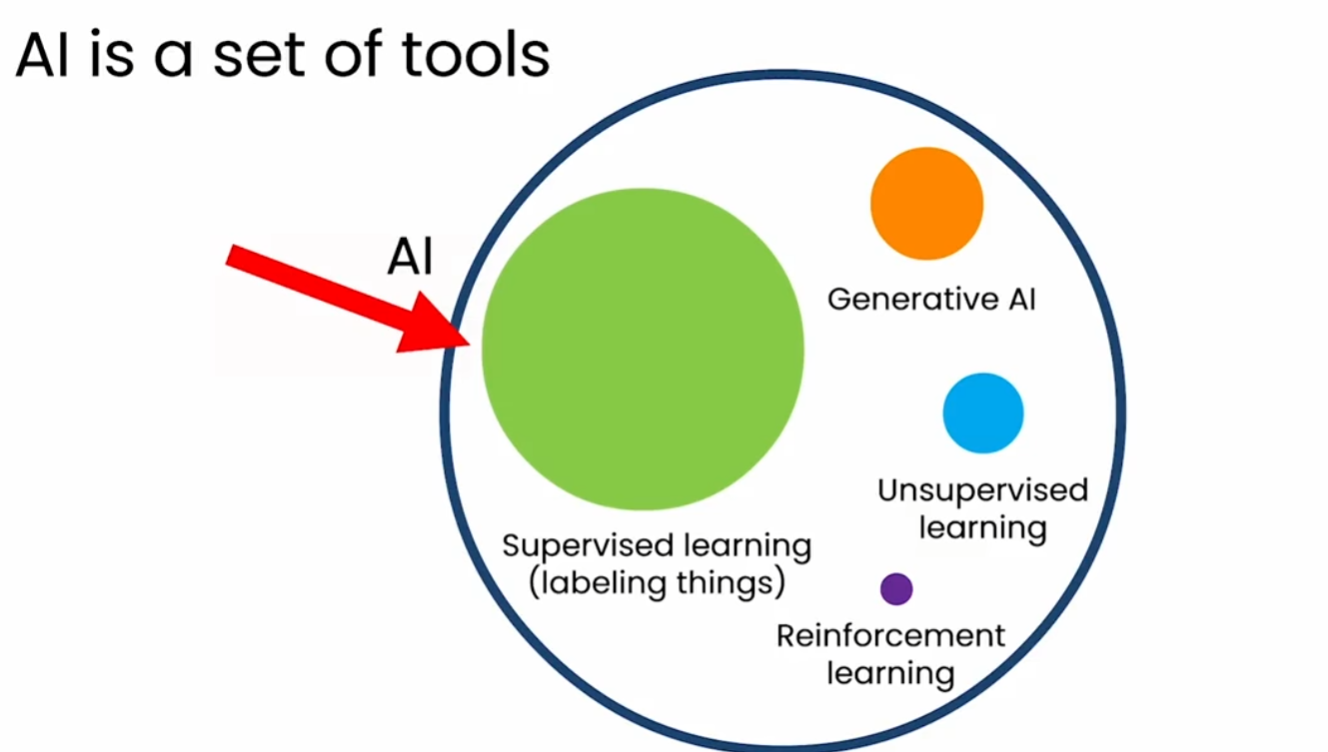
Generative Ai for Everyone
生成式AI
能够自动生成高质量内容(文本、图像、音频)的人工智能系统,如chatgpt。生成式AI除了面向消费者的应用,从长远来看,人工智能用作开发者工具更具有影响力。
大语言模型(LLM)
用海量文本数据训练出来的、能够理解和生成人类语言的巨型神经网络。
1. 工作原理
模型通过分析大量文本,学习词语之间的统计规律。给定一段上文,模型会计算下一个最可能出现的词或子词,并逐次生成完整的句子或段落。这种“逐词预测”的方式被称为自回归生成。
2. “大”的含义
-
参数规模大:参数可视为模型内部的记忆与知识节点,现代大语言模型的参数通常达到数百亿甚至万亿级别。
-
训练数据大:训练数据覆盖书籍、网页、代码、论文等广泛的公开文本,总量可达数万亿字符。
3. 核心能力
当模型规模超过一定阈值后,会“涌现”出许多未被显式训练的能力,例如:
-
上下文学习:根据几个示例就能完成同类任务;
-
推理与思考:在数学或逻辑问题上能给出分步推导;
-
多任务通用性:同一个模型可完成翻译、写作、摘要、编程等多种任务。
4. 主要局限
-
事实性不可靠:模型可能生成看似合理但实际错误的内容(称为“幻觉”)。
-
缺乏真实理解:模型没有意识、感知或真实世界体验,其输出仅是统计模式匹配的结果。
-
可能放大偏见:训练数据中的偏见可能被模型继承或强化。
5. 典型应用
ChatGPT、文心一言、DeepSeek 等对话产品,以及代码生成、智能客服、文本摘要等场景,背后均依赖大语言模型技术。
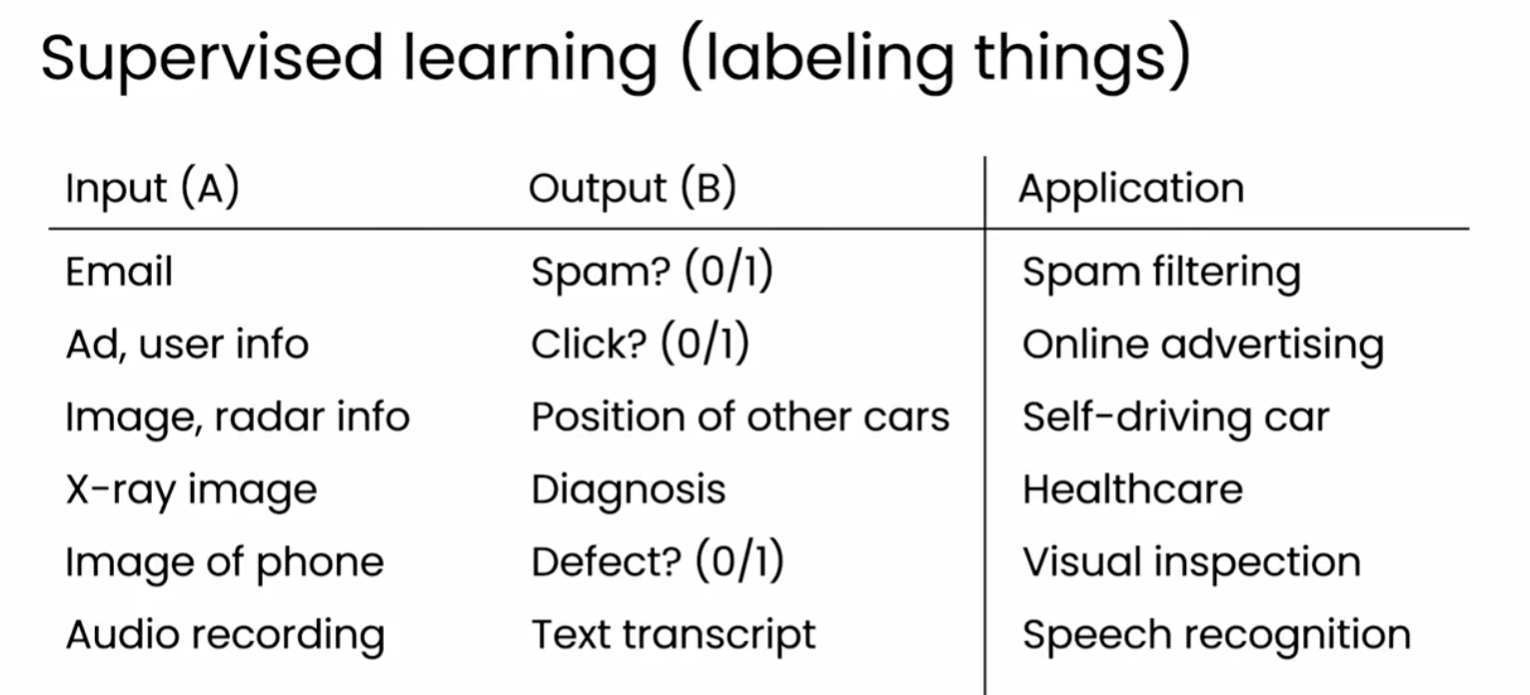
监督学习
监督学习是一种技术,能够根据输入生成对应的输出。
监督学习过程:
-
前向传播:模型根据输入前缀,计算出对下一个词的概率分布。
-
计算损失:比较模型预测的概率分布与“真实下一个词”的差距(例如用交叉熵)。
-
反向传播:根据损失值,计算每个参数的梯度。
-
更新参数:优化器(如Adam)微调模型参数,使下次预测更接近真实词。
举例:
第一步:分词
训练LLM时,通常不按单个汉字切分,而是按词或子词(比如用BPE、WordPiece等算法)。
假设分词结果是:["我", "最", "喜欢", "的", "食物", "是", "奶油", "贝果"]
第二步:构建所有“前缀 → 下一个词”对
对每一个“从第一个词到某个位置”的前缀,预测紧跟着的下一个词。
| 输入前缀(已看到的词) | 目标输出(下一个词) |
|---|---|
[我] |
最 |
[我, 最] |
喜欢 |
[我, 最, 喜欢] |
的 |
[我, 最, 喜欢, 的] |
食物 |
[我, 最, 喜欢, 的, 食物] |
是 |
[我, 最, 喜欢, 的, 食物, 是] |
奶油 |
[我, 最, 喜欢, 的, 食物, 是, 奶油] |
贝果 |
一共得到 7 个数据点(因为8个词,可预测7次)。
第三步:模型如何利用这些数据点训练
-
每个数据点独立送入模型:模型看输入前缀,输出一个概率分布;然后与目标词计算损失;反向传播更新参数。
-
模型既学会
“我” → “最”这样的极短程依赖,也学会“我最喜欢的食物是” → “奶油”这样的较长依赖。 -
即使句子只有短短一句话,也会贡献多个样本,大大增加了训练信号的丰富度。
第四步:“大量”从何而来?
单个句子产生若干个数据点,而训练LLM的互联网文本包含万亿级别的句子,每个句子又裂变成几十、几百个数据点。最终训练数据的总条目数 = 所有句子的总词数(约等于数十万亿个“前缀→下一个词”对)。
这正是LLM能够学会复杂语言规律的基础:无数个这样微小的预测任务,共同塑造了模型的参数。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)