RAID技术概念与实现方式
RAID的概念
当我们电脑有多块硬盘,每块硬盘都存储着不同的文件·,当一块硬盘损坏时,这块硬盘中的文件就彻底没了,那我们把这几块硬盘相互关联,数据相互备份,这样就算有硬盘损坏了,数据也不会丢失,这样的技术我们把他叫做RAID( Redundant Array of Independent Disks)独立冗余磁盘阵列
RAID:独立冗余磁盘阵列,简称磁盘阵列。RAID是按照一定形式和方案组织起来的存储设备,它比单个存储设备在速度,稳定性和存储能力上都有很大提高,并且具备一定的数据安全保护能力。
RAID的主要实现方式
分为硬件RAID方式和软件RAID方式
硬件RAID:利用集成了处理器的硬件RAID适配卡来对RAID任务进行处理,无须占用主机CPU资源。
软件RAID:通过软件技术实现,需要操作系统支持,一般不能对系统磁盘实现RAID功能。
耗费cpu
RAID的数据组织方式
分块:将一个分区分成多个大小相等的,地址相邻的块,这些块称为分块。它是组成条带的元素
条带:同一磁盘阵列中的多个磁盘驱动器上的相同“位置”的分块。
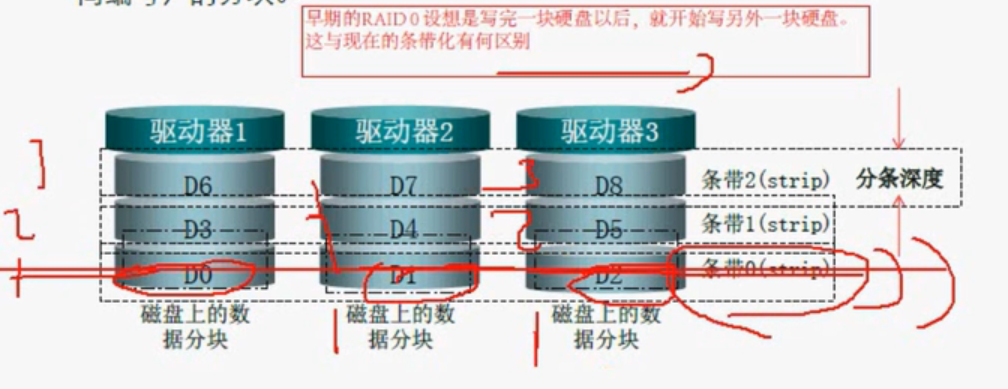
我们把磁盘扇区,几个扇区组成了一个块,这些磁盘组成RAID的时候,他们的参数要一致(同一厂商),每个磁盘有一块数据,然后把他相等的地方组成了条带,我们读写的时候是按条带来看的,我们RO读写类别时类比的就是条带,我们不管RO存储量什么都跟条带有关,这个条带的深度决定了这个条带最大能存储多少数据,这就叫条带深度。比如说D0,D1,D2,都存储了4K,他的条带深度就是12k(RAID0的情况下),存储数据的量就是条带的深度。我们的读写都是基于条带的,那条带就可以理解为在整个RAID阵列中理解为一个扇区。
RAID校验方式
我们RAID是如何保持冗余的,通过异或算法来保持冗余。典型案例RAID3,RAID3里面最少三块盘,两块存数据,一块存校验。通过XOR异或算法来实现校验。相同为假,异或为真。比如说我们驱动器1挂掉了,异或算法可逆,通过校验盘和另一块盘来算出另一块盘的数据,不管这个盘有多少都可以推导,但是只有一块校验数据的话只能推导出一块盘的数据,也就是最多只能损坏一块盘,这是RAID3。RAID的冗余校验都是使用了异或算法

RAID数据保护机制--热备和重构
比方说一块盘挂掉以后,前面说过可以通过校验盘来推导,这很麻烦,我们还有一个热备机制,让热备盘来顶替挂掉的位置,通过校验重构出挂掉盘的数据。
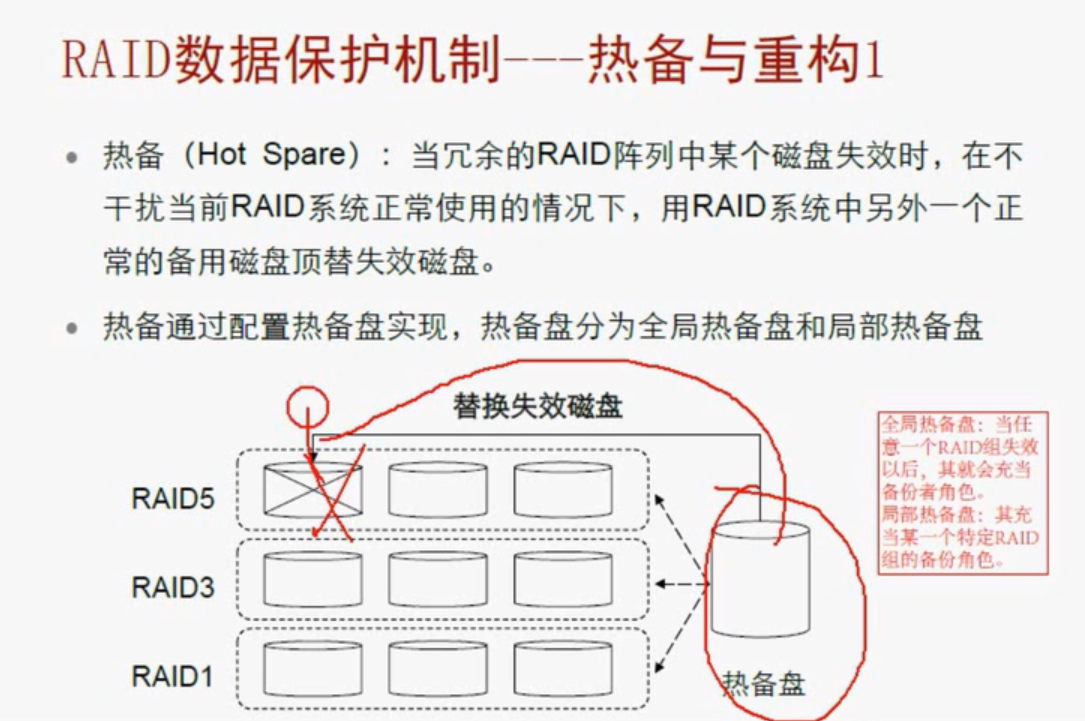
热备盘里面是没有数据的,我们通过校验盘来推道出的数据这个过程叫做重构。重构的前提是要有热备盘。这样就不用每次读写都要通过校验来推道,用热备盘就行。来提高RO的存储量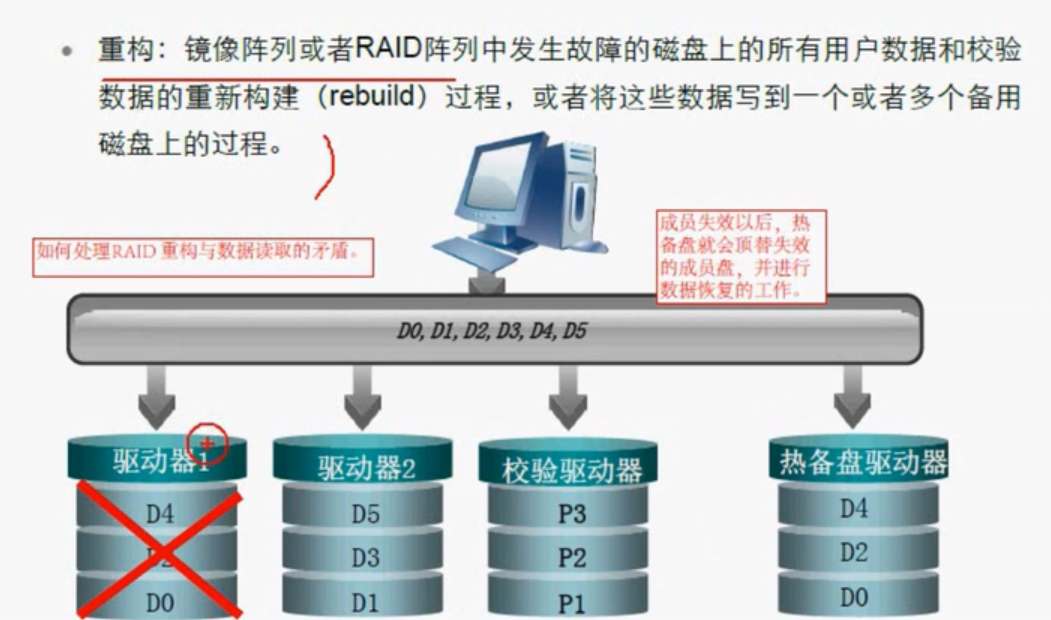
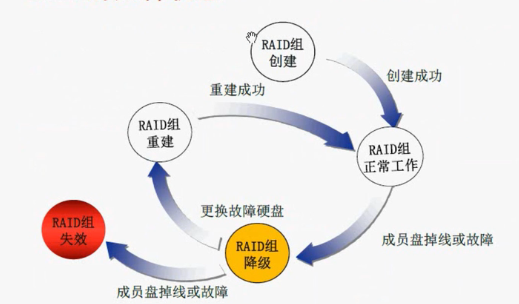
RAID的几种状态
那RAID到底是如何工作的呢,我们创建一个RAID组,成功创建后RAID组正常工作,然后某一块盘掉线故障以后,RAID组降级,然后我们热备盘或者人工更换硬盘,RAID组重建,之后正常工作。如果我们RAID降级运行工作,降级到一定程度的时候,我们不同的RAID有不同的冗余,如果在坏一块盘,可能RAID组就失效了,里面的数据就全部丢失。丢几块盘失效要看RAID的等级
常用RAID级别与分类标准
RAID技术将多个单独的物理硬盘以不同的方式组合成一个逻辑硬盘,提高了硬盘的的读写性能和数据安全性,根据不同的组合方式可以分为不同的RAID等级
| RAID等级 | 描述 |
| RAID0 | 数据条带化,无校验 |
| RAID1 | 数据镜像,无校验 |
| RAID3 | 数据条带化读写,校验心系存放于专用硬盘 |
| RAID5 | 数据条带化,校验信息信息分布式存放 |
| RAID6 | 数据条带化,分布式校验并提供两级冗余 |
| RAID10 | 类似于RAID0+1 ,区别在于先做RAID 1,后做RAID0 |
| RAID50 | 先做RAID5,后做RAID0,能有效提高RAID5的性能 |
RAID 0实现方式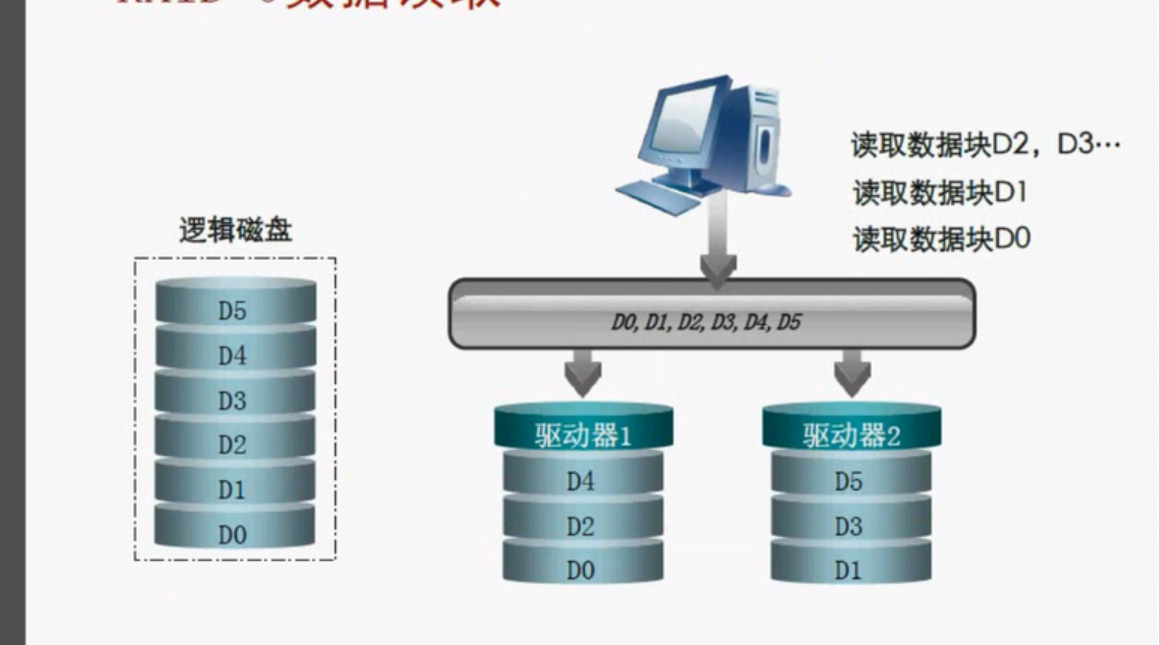
我们RAID是冗余阵列,但是RAID0没有冗余,如果一块盘坏掉,那整个RAID0就丢失,他的容量是几块RAID组成员的叠加,比如说驱动器1有50g数据,驱动器2有50g,那RAID0就能读写100g数据,他的容量是叠加。虽然数据是按条带化处理,但是没有冗余,没有校验。只是容量和IO读写的提升。在可靠性和安全性上没有提升。
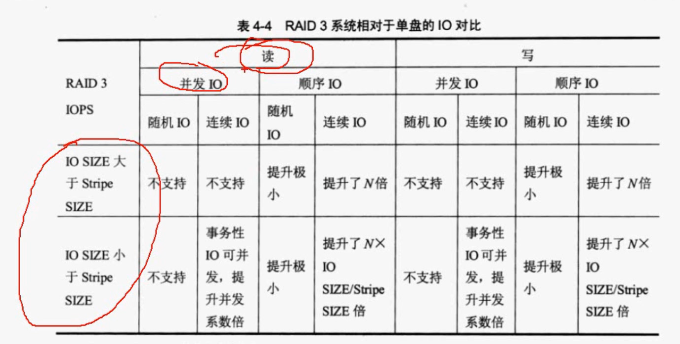
RAID 0对比单盘IO
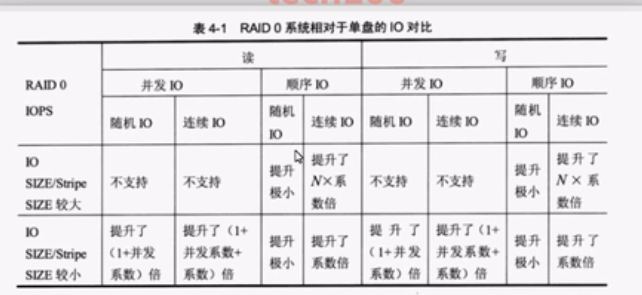
并发IO就是同时有多个IO要写入,多个数据同时写入,叫做并发IO。顺序IO是按1234顺序读写。随机IO是,比如说我们有4个IO读写(1,2,3,4),我们每个IO读写都要寻道,每个IO寻道的差距会非常大,一个可能在1号磁道0,一个可能在10号磁道,每个IO磁道的距离会很远,这叫随机磁道。而连续IO是指按磁道顺序来进行IO操作。
读取性能 (Read)
| IO SIZE/Stripe SIZE | 随机IO (并发IO) | 连续IO (顺序IO) |
|---|---|---|
| 较大 | 不支持 | 提升 N×系数倍 |
| 较小 | 提升 (1+并发系数)倍 | 提升 (1+并发系数)倍 |
写入性能 (Write)
| IO SIZE/Stripe SIZE | 随机IO (并发IO) | 连续IO (顺序IO) |
|---|---|---|
| 较大 | 不支持 | 提升 N×系数倍 |
| 较小 | 提升 (1+并发系数)倍 | 提升 (1+并发系数)倍 |
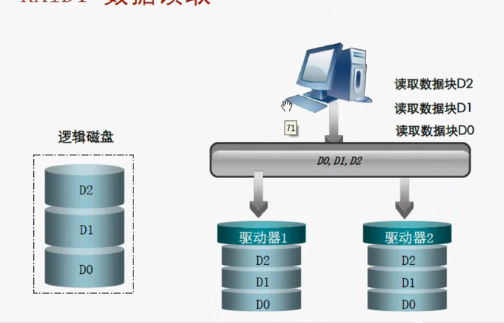
RAID 1工作原理
RAID1简单点来说就是镜像,两块盘互作镜像。我在驱动器1里面写入D0,在驱动器2里面也要写入D0,这样挂一块盘不会整体跨。RAID1没有校验,但是有镜像。他的磁盘容量是(n*单块磁盘的容量)/2。他的磁盘利用率是50%,但可靠性高。挂了一块,该怎么读继续怎么读。冗余度很大。写性能比单块要差,读性能与RAID0相似
对比单盘IO
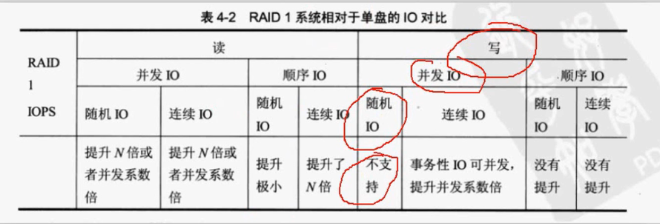
RAID 3工作原理
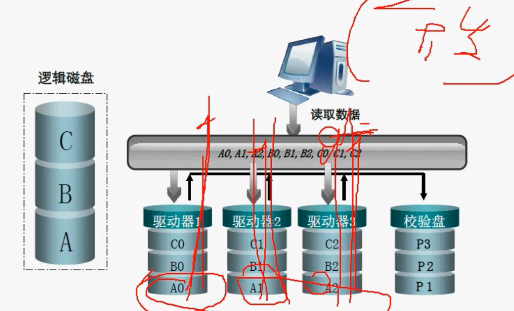
RAID 3开始异或算法。RAID 3有四块盘,但是只有三块可以写数据,另一块盘是校验盘,只存储校验数据,校验盘只有一个。
写入数据,每一次IO写入都必须占用校验盘,所以他的容量是(n-1)* 单块盘的容量,利用率就是(n-1)/n,冗余度就一块盘的冗余度。
如果一块盘挂掉,通过校验盘进行异或操作,依然可以工作。如果挂带两块,那就失效了
对比单盘的IO
RAID 5工作原理
RAID 5(独立磁盘冗余阵列级别 5)是一种结合了数据条带化和分布式奇偶校验的存储技术,旨在提供容错能力和性能提升。
-
数据条带化(Striping):数据被分块并轮流写入多块硬盘,提高读写速度。
-
分布式奇偶校验(Distributed Parity):校验信息(用于数据恢复)分散存储在所有硬盘上,避免单一校验盘的瓶颈。
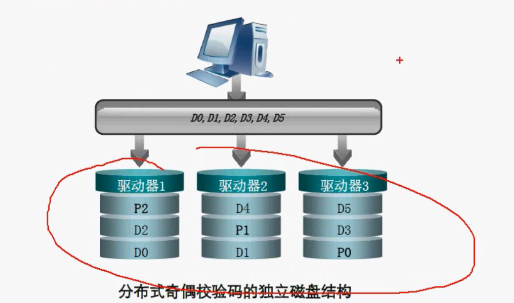
有着比RAID3更大的条件深度,RAID5把他的校验盘打散了,如下图p012为校验数据,RAID5最少要三块硬盘,他的校验的数据量也是占一款盘,他的利用率也是(n-1)/n。他的容量是(n-1)* 单块盘的容量。校验数据存在不同的硬盘上。
最少磁盘需求: 至少需要 3 块硬盘(通常建议 4 块以上以获得更好性能)。
容错能力: 允许 1 块硬盘损坏而不丢失数据(通过奇偶校验恢复)。
存储利用率: 采用分布式奇偶校验,相比 RAID 1 更节省空间。
可用容量 = (磁盘总数 - 1) × (最小磁盘容量)。
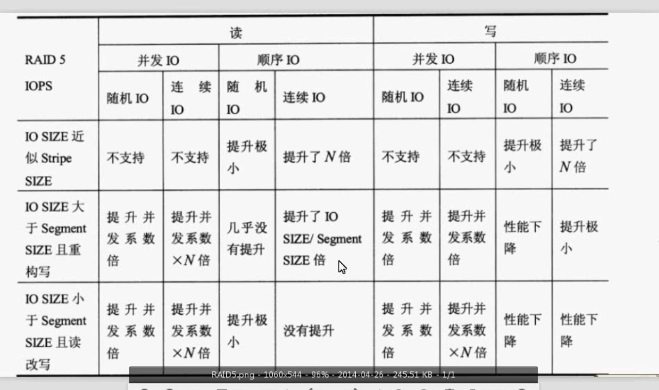
RAID5的读写方式有三种
整条写:当要修改全部的数据的时候,采用全部重新写入,重新计算的方式来实现。
重构写:当写入的数据量超过阵列磁盘数量的一半,将采用这种方式,其读取不需要修改的数据与现在的数据直接进行计算,生成新的校验,直接写入硬盘。
读改写:如果写入的硬盘数目不足磁盘数目的一半,其读取需要修改的数据,以及旧数据校验值,根据这些来生成新的数据,直接写入,校验算法如下:新校验值=(老数据 EOR 新数据)EOR 老数据

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)