一套可视化流程,带你看懂OCR如何识别文字(二)
第三步:把每一块文字“切出来”
经过前两步的处理,目前我们已经拿到了很多文本框,但此时模型还没真正“读字”。接下来要做的事情就是裁剪出框里的内容。
这一步在流程里对应的是:轮廓裁剪(ContourCrop)
不过这里有一个很关键、但很多人容易忽略的细节:不是简单裁剪,而是“矫正之后再裁
现实中的文本,很少是规规矩矩水平摆放的,比如:
-
拍照角度倾斜
-
文本本身是斜的
-
扫描时有透视变形
所以在裁剪之前,通常会做一步:
透视矫正(rectify)
简单理解就是:
-
把一个“歪的四边形”
-
拉成一个“规整的矩形”
这样做的好处是:
后面的识别模型看到的是“摆正的文字”,识别准确率会高很多
处理后,图片被切分、输出为很多小的、已经摆正的文本图片。
第四步:模型开始“逐块读字”
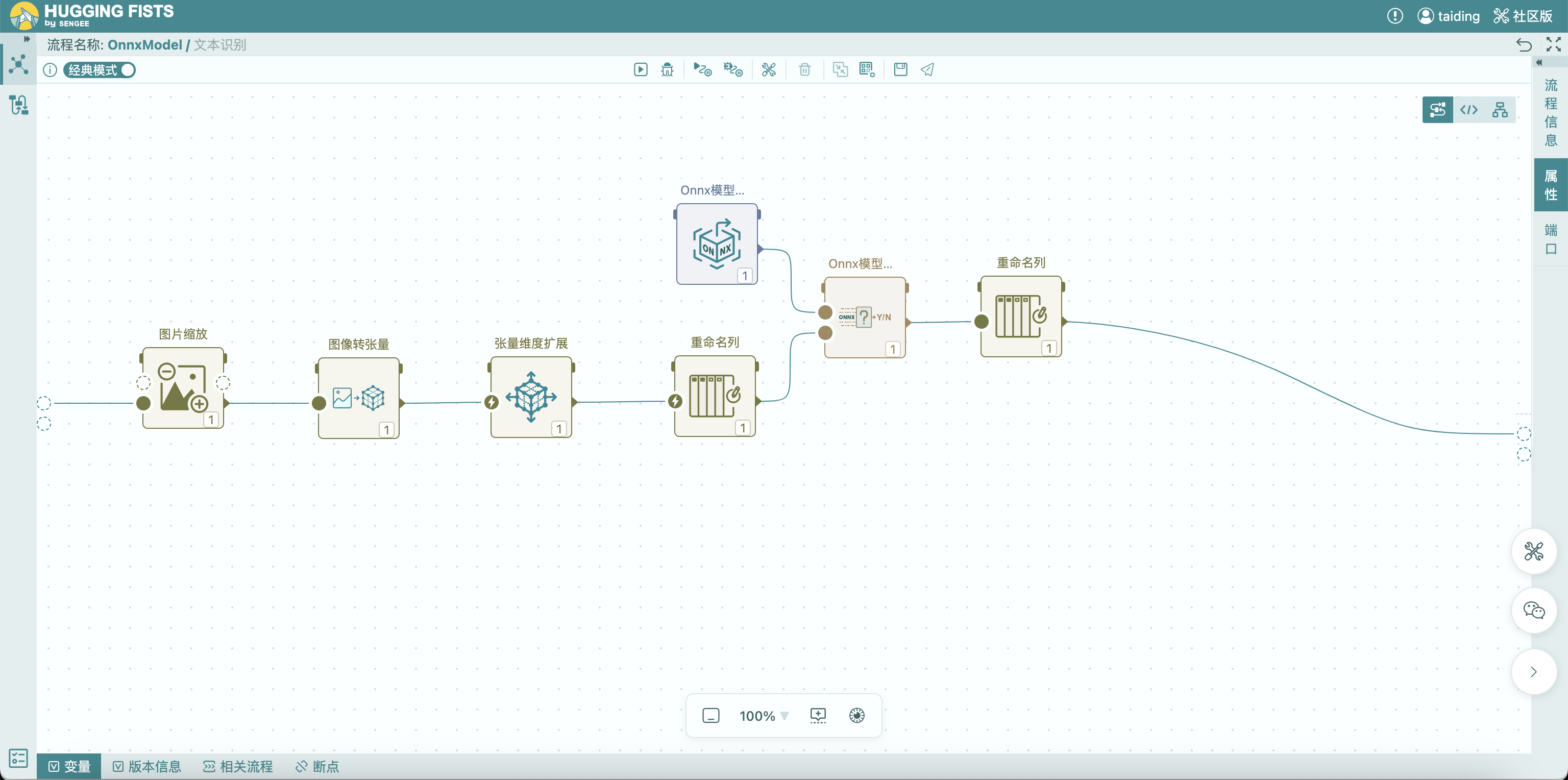
有了这些小图之后,才真正进入 OCR 的第二个核心任务:
文字识别(Recognition)
这一部分的处理逻辑,其实和前面的检测有点类似,也是:
-
先做预处理
-
再送进模型
1. 图片统一尺寸
不同文本块的尺寸差异会很大,比如:
-
“你好”很短
-
一整行句子很长
但模型一般要求输入尺寸相对固定,所以会做一个处理:把图片高度统一(比如48),宽度按比例缩放。这样可以做到:
-
保持文字形状不变
-
同时适配模型输入
2. 图像转张量
和前面一样,会把图片转换成模型能处理的数据格式:
-
HWC → CHW
-
数据类型转成 float32
并且补上 batch 维度:
[C, H, W] → [1, C, H, W]
3. 识别模型输出的,其实不是“文字”
这一点很多人第一次接触会觉得有点反直觉:
模型不会直接输出“你好世界”
它输出的是一串“字符概率分布”。可以理解为:
每个位置,最可能是哪个字?”
第五步:把“概率序列”变成真正的文字
接下来,将这串“概率”翻译成“人能读的文字”。
1. 先选出每一步“最可能的字符”
流程里会做一个操作:取最大概率(ArgMax)。也就是,每个位置选一个最可能的字符索引,得到一串类似:
[你, 你, -, 好, -, 世, 世, 界]
的字符索引。(这里的 - 可以理解为“空白符”,字符索引为整数值,这里为了举例方便,转换为了具体字符。)
2. CTC解码:去重 + 去空
接下来会做一个经典操作:CTC解码。它主要干两件事:
-
合并重复字符
-
去掉空白符
所以刚才那串会变成:
[你, 好, 世, 界]
3. 字典映射:从“编号”变成“真正的字”
模型内部处理的其实是“字符索引”,比如:
-
0 → blank
-
1 → “你”
-
2 → “好” …
所以最后还需要一步:根据字典,把索引映射成文字。这一步之后,才会真正得到文本串:
“你好世界”
写在最后
本文用一条可视化流程,把典型OCR的内部工作方式做了一次尽量直观的拆解。
在实际运行这套流程做文字识别时,可以明显感觉到: 它与成熟的OCR工具相比,效果上仍然存在差距。
这也意味着,如果希望达到工业级的识别效果,仅仅搭建主流程还不够,还有很多细节需要进一步打磨,例如:
-
不同场景下的适配(票据、表格、自然场景等)
-
多语言与字符集扩展
-
倾斜、模糊、低质量图像的鲁棒性
-
版面分析(段落、表格结构)
-
性能与吞吐优化(批处理、并发)
-
……
这些问题往往不会直接体现在主流程中,但却决定了一套OCR系统在真实场景中的表现。
如果你对这些细节感兴趣,不妨沿着这条流程继续往下拆——你会发现:
OCR真正复杂、也更有意思的部分,往往就藏在这些“没有被展开”的地方。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)