如何运行字节bamboo_mixer
1. 安装 Git LFS,在 PowerShell 执行:
git lfs install如果提示没有 git lfs,先安装 Git LFS:
winget install GitHub.GitLFS安装完后重新打开 PowerShell,再执行:
git lfs install2. 在你自己的目录下clone 仓库,不要用 ZIP,Bamboo-Mixer 的 data_oss 目录包含 mono_inference.json.xz、formula_inference.json.xz 等数据文件,但这些文件通过 Git LFS 管理;直接下载 GitHub ZIP 时经常只拿到指针文件。
git clone https://github.com/ByteDance-Seed/bamboo_mixer.git
cd bamboo_mixer
git lfs pull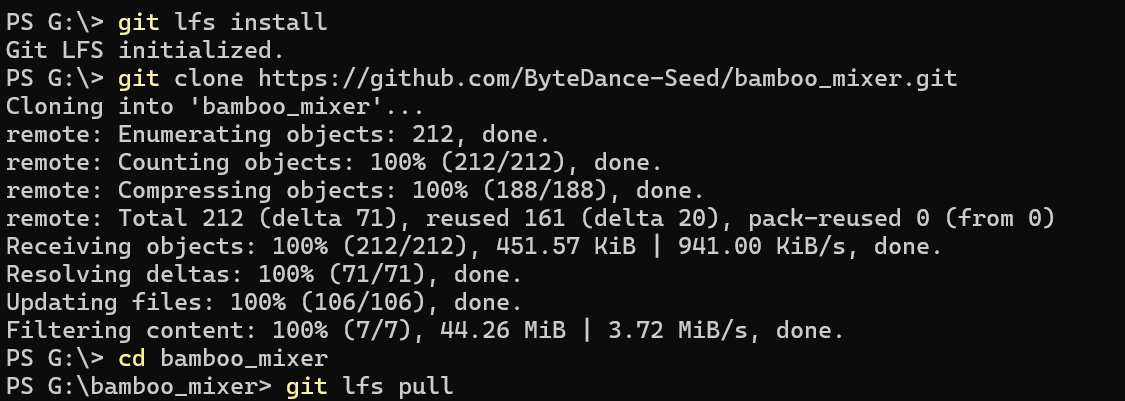 3. 验证文件是否真的下载成功
3. 验证文件是否真的下载成功
在新仓库目录执行:
Get-Content data_oss\mono_inference.json.xz -TotalCount 1
Get-Item data_oss\mono_inference.json.xz | Select-Object Name, Length正确情况下,PowerShell 可能显示乱码,或者看不出文本内容;如果只有几十到几百字节,大概率还是 LFS 指针文件。
 4. 然后再解压数据集
4. 然后再解压数据集
mkdir run -ErrorAction SilentlyContinue
python -c "import lzma, shutil; shutil.copyfileobj(lzma.open(r'data_oss\mono_inference.json.xz', 'rb'), open(r'run\mono_inference.json', 'wb'))"
python -c "import lzma, shutil; shutil.copyfileobj(lzma.open(r'data_oss\formula_inference.json.xz', 'rb'), open(r'run\formula_inference.json', 'wb'))"
python -c "import lzma, shutil; shutil.copyfileobj(lzma.open(r'data_oss\mono_data.json.xz', 'rb'), open(r'run\mono_data.json', 'wb'))"检查一下run目录下是否有数据集文件

5.安装运行环境,如果有就忽略,代码要求python3.9以上的版本支持,如果没有最好创建一个,这里使用conda虚拟环境安装python3.11:
conda create -n bamboo python=3.11 -y
conda activate bamboo如果powershell不支持conda activate bamboo
6.安装完成后这里直接在pycharm里面配置即可
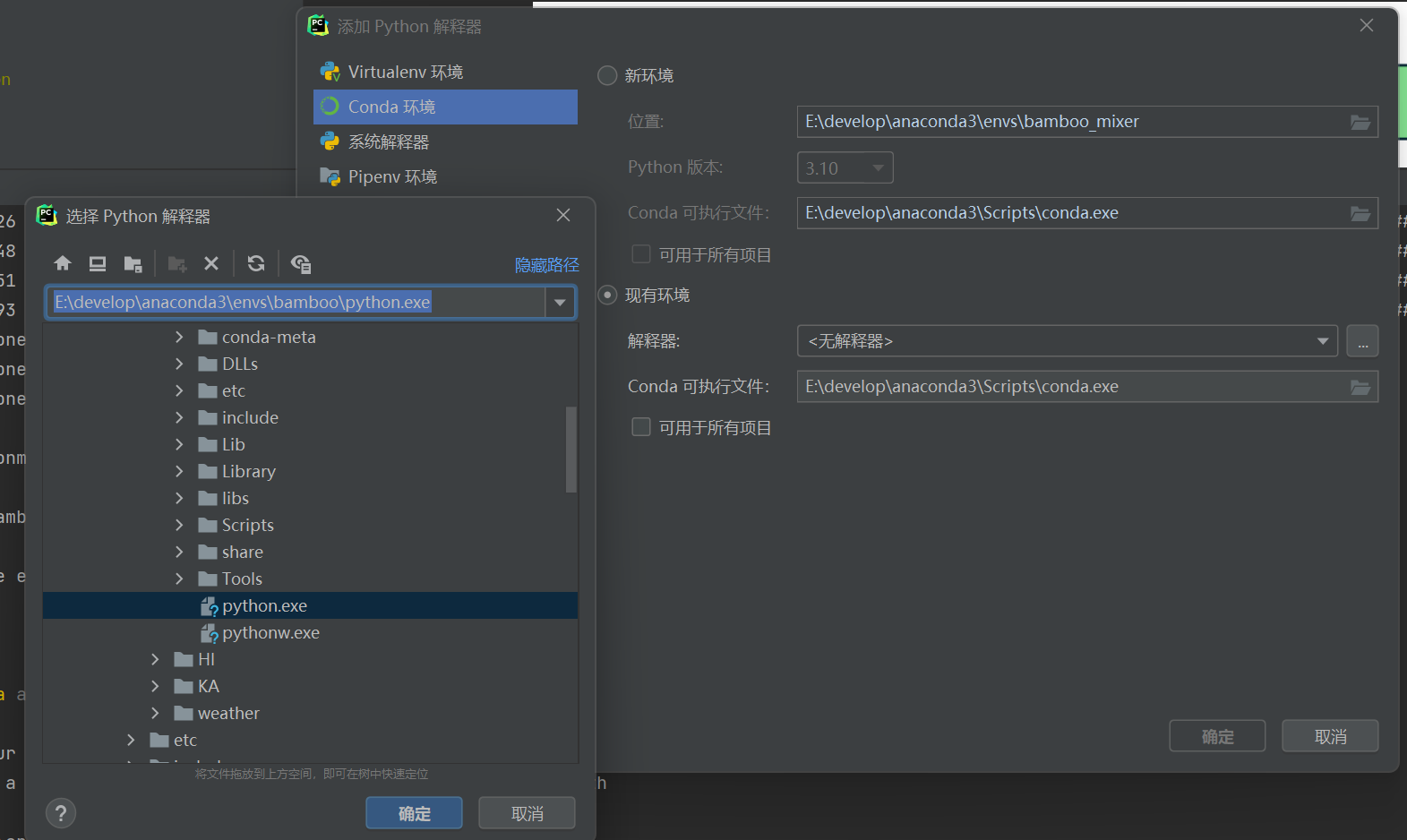
7.然后在新环境里面安装依赖:
先升级 pip:
python -m pip install -U pip setuptools wheel然后装项目依赖:
python -m pip install -r requirements.txt如果 requirements.txt 里 PyTorch 安装很慢或失败,可以先装基础依赖:
python -m pip install ase==3.22.1 einops==0.8.1 h5py==3.10.0 matplotlib==3.8.3 networkx==3.2.1 numpy==1.26.2 packaging==24.0 pandas==2.2.1 Pillow==9.3.0 PyYAML==6.0.1 rdkit==2023.9.6 scikit-learn==1.5.2 tqdm==4.66再装 PyTorch / PyG:
python -m pip install torch~=2.7.0 torch-geometric~=2.7.0这里直接按照requirement安装:

8.直接运行数据预处理:
python scripts/prepare_data/prepare_data.py `
--conf config/prepare_data/train_predictor_mono_config.yaml `
--data_type mono如果出现:
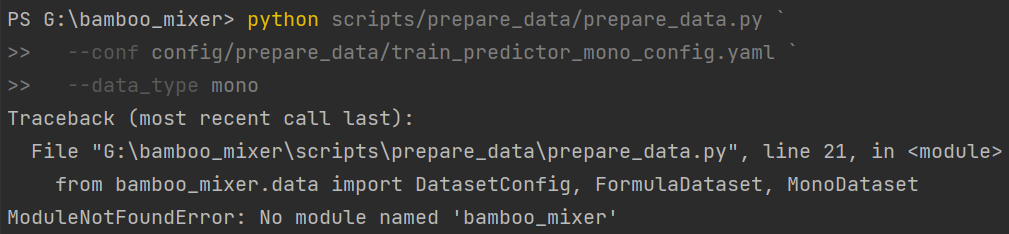
这是标准的导入路径问题:用 python scripts/... 启动脚本,Python 当前搜索路径会偏向 scripts\prepare_data,不会自动把仓库根目录当作包路径
在 同一个 PowerShell 窗口 里,先执行下面这几行:
cd G:\bamboo_mixer
$env:PYTHONPATH = (Get-Location).Path
python -c "import sys, os; print('cwd =', os.getcwd()); print('PYTHONPATH =', os.environ.get('PYTHONPATH')); import bamboo_mixer; print('bamboo_mixer =', bamboo_mixer.__file__)"如果出现:

就成功啦!每次在终端运行前都要加:
$env:PYTHONPATH = (Get-Location).Path
python -c "import sys, os; print('cwd =', os.getcwd()); print('PYTHONPATH =', os.environ.get('PYTHONPATH')); import bamboo_mixer; print('bamboo_mixer =', bamboo_mixer.__file__)"9.继续运行数据预处理:
先跑单分子数据预处理:
python scripts/prepare_data/prepare_data.py `
--conf config/prepare_data/train_predictor_mono_config.yaml `
--data_type mono完成后在run/mono/preprocess目录下应该能看到四个文件

然后跑单分子推理数据预处理:
python scripts/prepare_data/prepare_data.py `
--conf config/prepare_data/inference_predictor_mono_config.yaml `
--data_type mono然后下载 HuggingFace checkpoint:
首先安装下载工具:
python -m pip install -U huggingface_hub -i https://pypi.org/simple
然后下载模型仓库:
$hf = "E:\develop\anaconda3\envs\bamboo\Scripts\hf.exe"
& $hf download ByteDance-Seed/bamboo_mixer ckpts/mono/optimal.pt --repo-type model --local-dir hf_bamboo_mixer
然后复制到项目需要的位置:
mkdir run\mono -ErrorAction SilentlyContinue
Copy-Item hf_bamboo_mixer\ckpts\mono\optimal.pt run\mono\optimal.pt
Test-Path run\mono\optimal.pt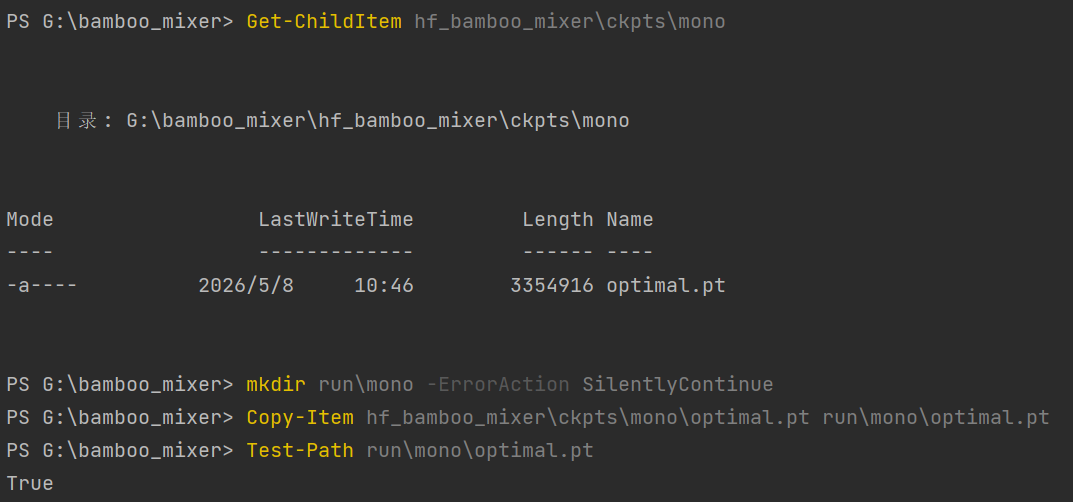
进行预测:
python scripts/test_results/predict_mono.py `
--conf config/test_results/mono_config.yaml预测完成后查看结果:
Get-Content run\mono\test_results\output_mono.json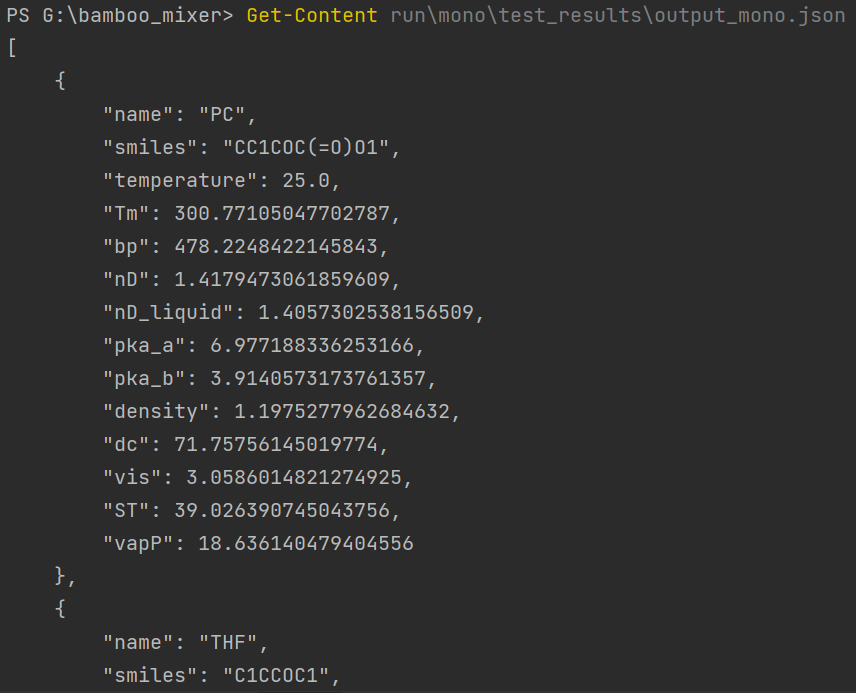
最后跑电解液配方推理数据预处理:
python scripts/prepare_data/prepare_data.py `
--conf config/prepare_data/inference_predictor_formula_config.yaml `
--data_type formula通常会出现:
这是因为官方 config/prepare_data/inference_predictor_formula_config.yaml 当前只包含 json_path、save_dir、key_map,没有 kwargs.include_emb,所以直接报 KeyError。也就是说,这是 配置项缺失,不是数据问题。
解决方法:
用 Python 重新写无 BOM 配置:
$py = "E:\develop\anaconda3\envs\bamboo\python.exe"
$env:PYTHONPATH = "G:\bamboo_mixer"
@'
from pathlib import Path
content = """json_path: run/formula_inference.json
save_dir: run/formula/inference_preprocess
key_map:
concentration: salt_molar_ratio
temperature: temperature
kwargs:
include_emb: false
"""
Path(r"config\prepare_data\inference_predictor_formula_config.yaml").write_text(content, encoding="utf-8")
'@ | & $py -验证 Python 读到的键名:
& $py -c "import yaml; d=yaml.safe_load(open(r'config\prepare_data\inference_predictor_formula_config.yaml', encoding='utf-8')); print(d); print([repr(k) for k in d.keys()])"应该看到:

清理上次失败的配方预处理目录:
Remove-Item run\formula\inference_preprocess -Recurse -Force -ErrorAction SilentlyContinue重新跑配方预处理:
python scripts/prepare_data/prepare_data.py `
--conf config/prepare_data/inference_predictor_formula_config.yaml `
--data_type formula成功后就能看见:

然后创建模型目录:
mkdir run\formula\finetune_wd -ErrorAction SilentlyContinue然后下载模型文件:
& $hf download ByteDance-Seed/bamboo_mixer ckpts/formula/optimal.pt --repo-type model --local-dir hf_bamboo_mixer
Get-ChildItem hf_bamboo_mixer\ckpts\formula
复制到程序需要的位置:
Copy-Item hf_bamboo_mixer\ckpts\formula\optimal.pt run\formula\finetune_wd\optimal.pt运行转换脚本:
@'
import torch
from pathlib import Path
src = Path(r"run\formula\finetune_wd\optimal_original.pt")
dst = Path(r"run\formula\finetune_wd\optimal.pt")
ckpt = torch.load(src, map_location="cpu", weights_only=False)
sd = ckpt["model_state_dict"]
def map_head(rest: str) -> str:
if rest.startswith("sigma."):
return "Asigma0." + rest[len("sigma."):]
if rest.startswith("A."):
return "B." + rest[len("A."):]
if rest.startswith("B."):
return "D." + rest[len("B."):]
return rest
new_sd = {}
for k, v in sd.items():
if k.startswith("readout_conductivity."):
rest = k[len("readout_conductivity."):]
mapped = map_head(rest)
pred_key = "readout_pred." + mapped
ne_key = "readout_ne." + mapped
new_sd[pred_key] = v
new_sd[ne_key] = v
else:
new_sd[k] = v
ckpt["model_state_dict"] = new_sd
torch.save(ckpt, dst)
print("saved:", dst)
print("old keys:", len(sd))
print("new keys:", len(new_sd))
'@ | & $py -然后运行预测:
python scripts/test_results/predict_formula.py `
--conf config/test_results/predict_config.yaml
查看结果:
Get-Content run\formula\inference_output_test.json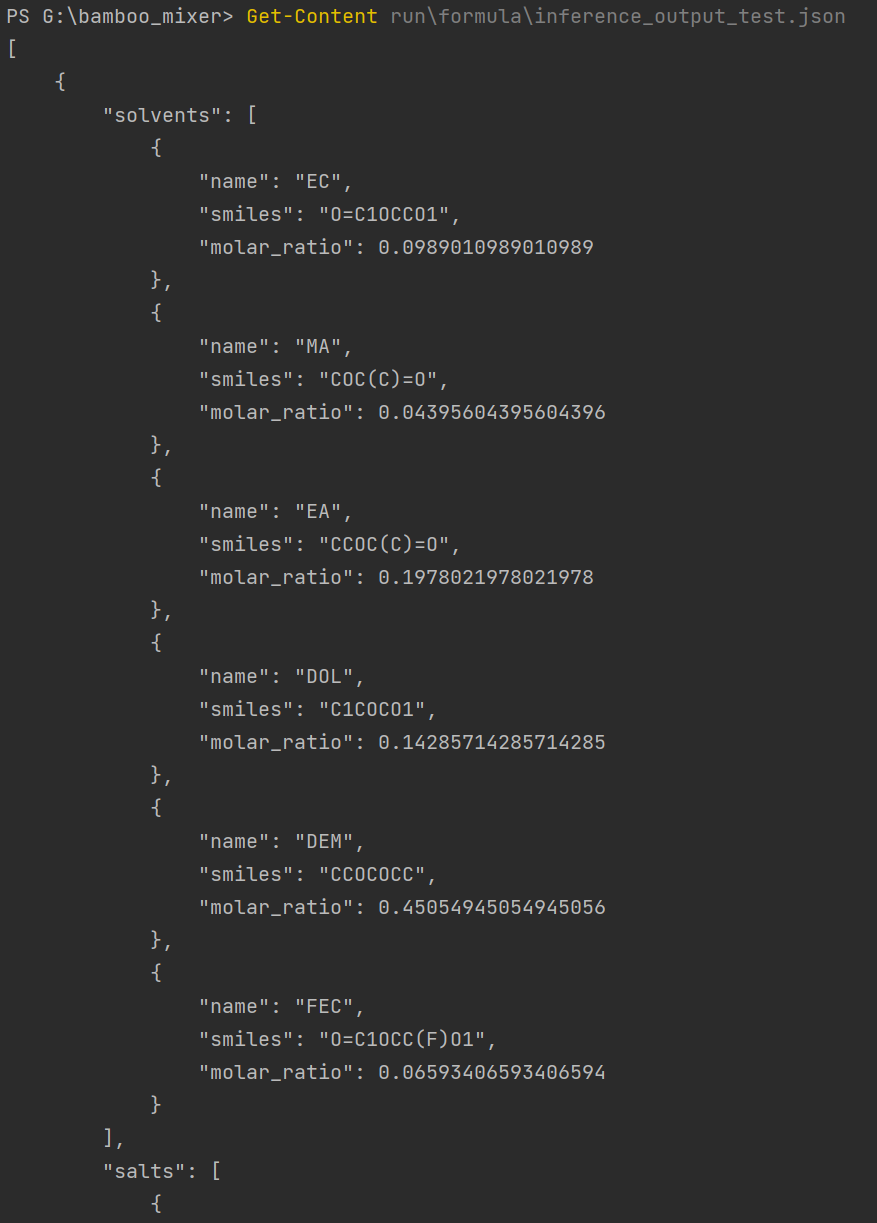
基本的流程就已经完成了
1. 单分子数据预处理
2. 单分子性质预测
3. 配方数据预处理
4. 配方性质预测
最后检查一次输出文件
Test-Path run\mono\test_results\output_mono.json
Test-Path run\formula\inference_output_test.json两个都返回 True 就说明预测结果都生成了。
单分子预测结果:
| 字段 | 含义 |
|---|---|
Tm |
熔点 |
bp |
沸点 |
nD |
折射率 |
nD_liquid |
液相折射率 |
pka_a |
酸性 pKa |
pka_b |
碱性 pKa |
density |
密度 |
dc |
介电常数 |
vis |
黏度 |
ST |
表面张力 |
vapP |
蒸气压 |
配方预测结果:
| 字段 | 含义 |
|---|---|
conductivity_pred |
预测离子电导率 |
anion_ratio_pred |
预测阴离子迁移相关比例 |
vis |
预测黏度相关值 |
sigma0, n1, n2, A, B, T0 |
模型输出的拟合/中间参数 |
按 conductivity_pred 看:
| 排名 | conductivity_pred | 简述 |
|---|---|---|
| 1 | 25.2300 |
MA / EA / DOL / DEM + FSI |
| 2 | 23.3194 |
MA / EA / EGDEE / DEM + FSI |
| 3 | 20.6782 |
MA / EA / DOL / MTFA + PF6 / FSI |
| 4 | 19.1272 |
MA / DEC / EA / EMC + FSI |
| 5 | 18.9492 |
PC / MA / EA / DOL / DEM / DMM + PF6 / FSI |
所以从这 10 个样例里,模型预测电导率最高的是这一组:
solvents:
MA 0.1222
EA 0.4000
DOL 0.3000
DEM 0.1778
salts:
FSI 1.0
temperature: 20.0
salt_molar_ratio: 0.1
conductivity_pred: 25.2300如果想更方便看排序结果,可以执行:
& $py -c "import json, pandas as pd; data=json.load(open(r'run\formula\inference_output_test.json')); rows=[]; [rows.append({'idx':i+1,'temperature':x['temperature'],'salt_molar_ratio':x['salt_molar_ratio'],'conductivity_pred':x['conductivity_pred'],'anion_ratio_pred':x['anion_ratio_pred'],'vis':x['vis'],'solvents':'; '.join([s['name']+':'+str(round(s['molar_ratio'],4)) for s in x['solvents']]),'salts':'; '.join([s['name']+':'+str(round(s['molar_ratio'],4)) for s in x['salts']])}) for i,x in enumerate(data)]; df=pd.DataFrame(rows).sort_values('conductivity_pred', ascending=False); df.to_csv(r'run\formula\formula_results_sorted.csv', index=False, encoding='utf-8-sig'); print(df)"
生成文件:run\formula\formula_results_sorted.csv
后面如果要预测自己的配方,只需要改:run\formula_inference.json
然后重新跑配方预处理和 predict_formula.py

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)