【全网最全】2026数维杯C题 | 思路+代码python和matlab+文献 优化算法+ 第一问到第四问 我国碳排放数据分析与研究
·
2026年数维杯今天开赛了,学长为大家提供了最新的c题资料
Python和matlab代码都有!!

| 数维杯C题代码思路文献 |
基于附件 1、2 碳排放数据,分析各省碳排放核心指标是否存在显著空间差异;结合碳排放规模、效率、经济关联度,构建多维度分类分级指标体系,对省份进行分类分级。
一、分析目标
- 空间差异分析:确定各省碳排放核心指标(总量、强度、效率等)在空间上的差异是否显著。
- 指标体系构建:整合碳排放规模、效率及经济关联度,形成多维度指标体系。
- 省份分类分级:基于指标体系对省份进行分群或分级,实现科学分类。
二、数据处理与指标提取
1. 数据整理
- 附件 1:2019–2025 年各省碳排放数据(总量、分能源排放等)。
- 附件 2:2022 年 30 个省份排放清单(核查各省分项数据准确性)。
- 额外数据:统计年鉴中 GDP、人口、能源结构等指标,用于经济关联度分析。
数据标准化

2. 核心指标选择
根据题目要求和能源碳排放研究经验,可选择以下核心指标:

三、空间差异分析
空间差异分析可以使用统计检验或空间统计量:
1. 方差分析(ANOVA)

2. 空间自相关分析

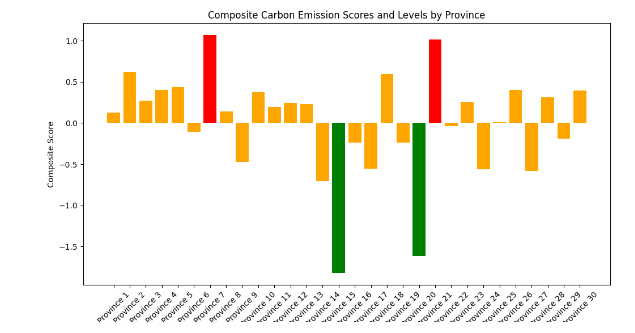
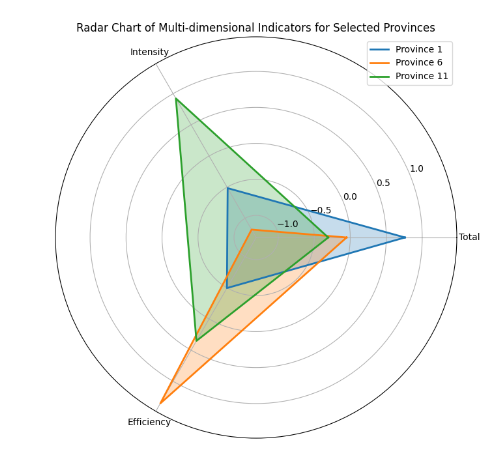
四、多维度分类分级指标体系构建
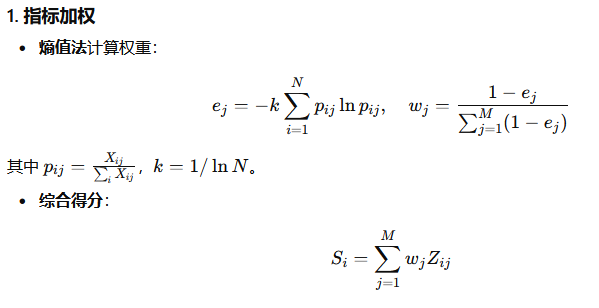

五、可视化与验证
- 空间分布图:用中国地图展示省份分类结果。
- 箱线图/小提琴图:展示各类指标的省份分布。
- 敏感性分析:尝试不同加权方式和聚类方法,验证分类稳健性。
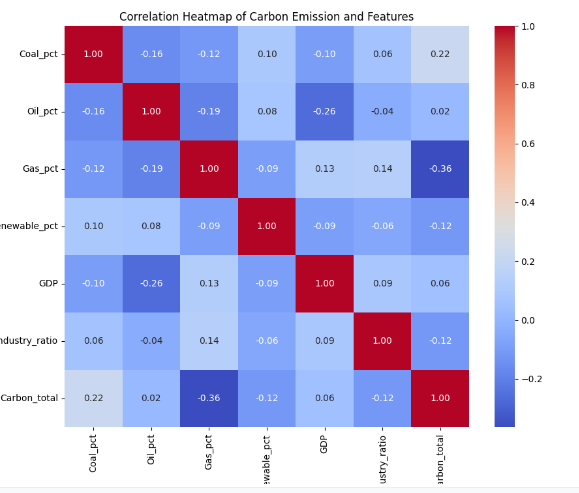
结合中国统计年鉴中的能源结构数据,识别影响碳排放的基本因素,建立碳排放的预测模型。
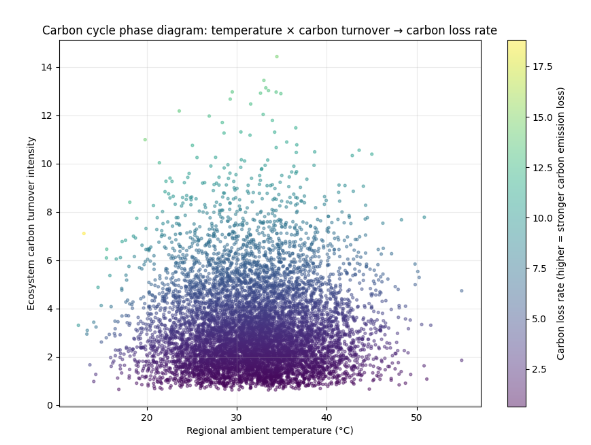
一、分析目标
- 影响因素识别:找出影响各省碳排放的关键因素(能源结构、GDP、人口、工业结构等)。
- 预测模型建立:构建可以预测碳排放总量或碳强度的模型。
- 模型评价与选择:评估预测精度,选择最优模型。
二、数据准备与处理
1. 数据来源
- 碳排放数据:附件 1(2019–2025 年各省碳排放总量、分能源排放)
- 能源结构数据:统计年鉴(煤炭、石油、天然气、水电、核电、风电、光伏等各类能源占比)
- 经济社会数据:各省 GDP、人口、工业比重、城镇化率等

三、影响因素识别

3. 降维或特征选择

四、碳排放预测模型选择

3. 机器学习方法
- 决策树/随机森林:可以处理非线性关系和交互效应
- XGBoost/LightGBM:可做特征重要性分析,预测精度高
- 神经网络(LSTM/GRU):适合长时间序列预测(年度碳排放)
五、模型训练与评价
1. 数据划分
- 训练集:2019–2023 年
- 测试集:2024–2025 年
3. 模型选择
- 比较不同模型预测误差,选择最优模型作为后续问题 3 的预测基础。
- 对机器学习模型,可用 交叉验证 调整参数(如 RF 树数、XGBoost 学习率等)。
Third Question: Future Carbon Emission Projection under Multiple Scenarios
1. Scenario Definition and Assumptions
未来碳排放取决于能源结构、经济发展和政策约束。设三种情景:
- Baseline Scenario (BS):经济和能源结构延续历史趋势
- Low-Carbon Scenario (LCS):新能源比例提升,煤炭下降,能源效率适度提高
- Enhanced Low-Carbon Scenario (ELCS):政策强化,新能源占比大幅提高,碳强度快速下降

2. Model Integration

3. Projection Method

4. Peak Detection and Analysis

5. Visualization and Interpretation


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)