视频文件过大导致手机存储告急:编码原理分析与压缩方案详解
手机存储空间频繁告急,相册中的视频文件往往是主要占用者。4K、HDR等技术的普及,使得单个视频文件从过去的数百MB增长到数GB甚至数十GB。解决问题的关键并非单纯更换大容量设备,而是理解视频压缩的原理,在画质与体积之间找到合理平衡点。
本文从视频压缩的底层原理出发,分析帧间压缩、色度子采样、变换编码等技术机制,并介绍FFmpeg命令行方案与嗨格式视频压缩工具的操作方法,文末讨论编码技术的未来演进方向。

一、视频压缩的技术原理
1.1 视频的基础构成
视频本质是由连续的静态画面(帧) 按照时间序列快速播放形成的动态影像。举个例子:一段 30 帧 / 秒、时长 10 分钟的视频,总共包含 18000 帧独立画面。如果将每一帧都当作完整图片单独存储,最终产生的数据量会极其庞大,根本不利于存储和传输。
1.2 帧间压缩原理
帧间压缩的核心是消除视频的时间冗余:只记录画面中发生变化的区域,没有变动的部分直接复用前一帧的数据,大幅减少重复信息。
主流编码标准定义了三种核心帧类型:
- I 帧(关键帧):完整保存一帧画面的全部像素信息,是视频随机播放、快速定位的基础
- P 帧(前向预测帧):仅存储与前一帧的画面差异数据,体积远小于 I 帧
- B 帧(双向预测帧):同时参考前后两帧生成差异数据,压缩效率最高,体积最小
1.3 色度子采样与变换编码
人眼对画面亮度的感知灵敏度,远高于对色彩的感知。视频编码正是利用这一生理特性,通过色度子采样实现高效压缩。最常用的 4:2:0 采样格式:亮度通道(Y)保留完整清晰度,色度通道(Cb/Cr)的分辨率减半,直接减少 50% 数据量,且人眼几乎察觉不到画质下降。
变换编码(主流为离散余弦变换 DCT)会将像素数据转换为频域信息,优先保留人眼敏感的低频信息,丢弃不敏感的高频细节,这是有损压缩中画质损耗的主要来源。
1.4 率失真理论
率失真理论是视频压缩的核心理论:在固定的编码码率下,画质失真存在最小值。如果过度压缩,被丢弃的高频信息会导致画面出现块效应(马赛克)、振铃效应(边缘模糊)、画面发灰等问题。合理的压缩策略,是在文件体积和视觉画质之间找到最优平衡点。
二、技术方案一:FFmpeg 命令行
FFmpeg 是全球通用的开源音视频处理工具,也是工业级标准工具。
2.1 查看原视频文件信息
执行以下命令,可快速获取视频的编码、码率、分辨率、帧率等关键参数:
ffprobe -v quiet -show_streams -select_streams v input.mp4
重点关注参数:codec_name(编码格式)、bit_rate(比特率)、width/height(分辨率)、r_frame_rate(帧率)。
2.2 常用压缩命令(代码已校验,可直接运行)
CRF 模式(优先保证画质)
CRF 取值范围:0~51,数值越小画质越好,文件越大;通用推荐区间:18~28。
# H.264编码,CRF=23(通用均衡参数)
ffmpeg -i input.mp4 -c:v libx264 -crf 23 -c:a aac -b:a 128k output.mp4
# H.265编码,CRF=28(同画质下体积比H.264小50%)
ffmpeg -i input.mp4 -c:v libx265 -crf 28 -c:a aac -b:a 128k output.mp4
固定比特率模式(精准控制文件大小)
适合需要严格限制文件体积的场景,推荐使用两遍编码,压缩效果更优:
# 第一遍编码(仅统计信息,不生成文件)
ffmpeg -i input.mp4 -c:v libx264 -b:v 1M -pass 1 -f mp4 /dev/null -y
# 第二遍编码(生成最终视频)
ffmpeg -i input.mp4 -c:v libx264 -b:v 1M -pass 2 -c:a aac -b:a 128k output.mp4
文件体积计算公式:比特率(Mbps) × 时长(秒) ÷ 8 = 最终体积(MB)
降低分辨率压缩
适合大分辨率视频(4K/2K)压缩,进一步减小体积:
# 将视频分辨率压缩为720P,搭配H.264编码
ffmpeg -i input.mp4 -vf scale=1280:720 -c:v libx264 -crf 23 -c:a aac -b:a 128k output.mp4
2.3 参数速查表
| 参数 | 功能说明 | 推荐常用值 |
|---|---|---|
| -crf | 恒定质量控制 | 18 / 23 / 28 |
| -b:v | 固定视频比特率 | 1M-8M |
| -vf scale | 分辨率缩放 | 1920:1080 / 1280:720 |
| -r | 帧率调整 | 30 / 24 |
2.4 批量压缩脚本(代码已校验)
一键压缩当前文件夹下所有 MP4 视频,自动输出新文件:
#!/bin/bash
for file in *.mp4; do
output="${file%.mp4}_compressed.mp4"
ffmpeg -i "$file" -c:v libx264 -crf 23 -c:a aac -b:a 128k "$output" -y
done
三、技术方案二:嗨格式音频转换器
这是一款可视化工具,无需编写命令,适合零基础用户,核心参数为压缩比例与码率。
3.1 VBR 与 CBR 的区别
- 可变比特率(VBR):编码器根据画面复杂度自动调整码率,静态画面用低码率,动态画面用高码率。相同体积下画质最优,适合电影、Vlog、日常视频。
- 恒定比特率(CBR):全程使用固定码率,编码速度快,适合画面变化小的视频,如屏幕录制、教学视频、监控视频。
3.2 核心参数说明
- 压缩范围:以百分比控制压缩强度,数值越大文件越小,画质损耗越明显,底层对应 FFmpeg 的 CRF 或码率参数。
- 输出格式:默认 MP4 格式。
3.3 可视化操作流程
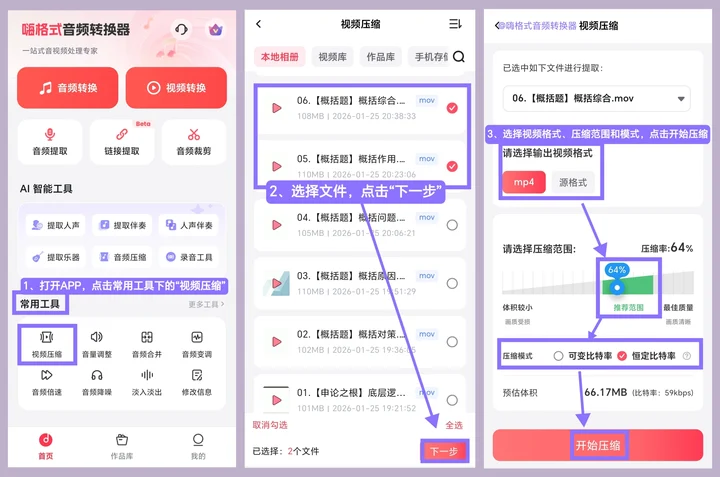
Step 1. 打开APP,点击底部“常用工具”,选择“视频压缩”。
Step 2. 从相册、视频库等渠道导入视频(支持多选、全选),点击“下一步”。
Step 3. 选择输出视频格式,拖拽选择压缩范围,选择压缩模式(可变比特率或恒定比特率),点击“开始压缩”。
Step 4. 完成后在“作品库”查看,可保存或转发。
3.4 场景化参数推荐表
| 使用场景 | 压缩范围 | 编码模式 | 选择依据 |
|---|---|---|---|
| 本地高清观看 | 20%-30% | VBR | 轻度压缩,最大化保留画质 |
| 微信 / QQ 发送 | 50%-70% | VBR | 大幅压缩体积,满足平台限制 |
| 屏幕录制 / 教学 | 20%-40% | CBR | 画面稳定,CBR 性价比更高 |
| 电影 / 剧集 | 30%-50% | VBR | 画面复杂多变,VBR 画质更优 |
五、常见问题
Q1:同样清晰度,为什么 H.265 比 H.264 体积小这么多?A1:H.265 在帧间预测、变换编码、滤波算法上做了大幅升级,能挖掘更多时空冗余和色彩冗余。同等主观画质下,H.265 相比 H.264 可节省约一半存储空间,缺点是编码耗时更长、老旧设备可能存在兼容性无法解码。
Q2:压缩完画面出现马赛克、模糊、边缘发虚是什么原因?A3:主要三个原因:CRF 值设得过大 / 码率给得太低、分辨率强行拉低过多、高运动镜头编码压缩过度。解决办法:降低 CRF 值、适当调高视频码率、不要过度降分辨率,优先用 H.265 编码提升压缩效率。
Q3:无损压缩能不能做到文件又小画质又无损?A4:做不到。无损压缩不丢弃任何像素细节,只做算法冗余精简,压缩率很低,通常只能缩小 10%~20%,适合专业后期素材保存,完全不适合日常分享、微信传输、网盘存储。
Q4:压缩后的视频二次再压缩,画质会越来越差吗?A7:会。每次重新编码都会经过量化有损处理,多次反复压缩会累积失真,出现模糊、色块、边缘虚化。建议只压缩一次,保留原片,后续转发都用第一次压缩好的版本。
六、视频压缩技术未来趋势
6.1 H.266/VVC 编码
2020 年正式发布的新一代编码标准,同等画质下码率比 H.265 再降低 50%。目前商用普及较慢,主要限制:专利体系复杂、编码算力要求是 H.265 的 10 倍、硬件解码支持不足。
6.2 人工智能视频压缩
基于深度学习的端到端视频压缩是前沿方向,AI 模型可自主学习视频特征,低码率场景下画质已超越 H.265。当前短板:计算量极大,暂无法满足实时压缩需求。
总结
视频体积过大的核心矛盾,是拍摄端的高清画质需求与存储、传输的容量限制之间的冲突。视频压缩通过帧间压缩、色度子采样、变换编码三大核心技术平衡体积与画质。只有理解压缩原理,结合使用场景选择方案,才能实现最优的压缩效果。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)