4年了!终于证明:人类第一视角数据,才真正打开了机器人规模化的通道

为什么说人类第一视角,才是机器人智能的终极答案?
——机器人操作的规模化之路
目录
过去几年,Egocentric(第一人称)数据研究在机器人学习领域取得了系统性突破:从基础奠基到规模化落地、从视觉感知到精细交互的系统性演进,其技术路线已从新兴方向发展为行业共识。
这一进程始于2022年CMU、Meta、Google等13家机构联合发布的Ego4D数据集,首次为第一人称视角收集的日常活动视频建立了统一的采集规范和标注框架;
随后,EgoScale等研究工作证实了规模化路径的可行性:基于超过两万小时人类第一人称视频训练的VLA模型,重新定义机器人操作上限;
EgoHumanoid 实现无机器人演示的野外移动操控,EgoTouch 与 TouchAnything 突破视觉‑触觉双模态精细交互感知,EgoVerse 构建全球协同的标准化数据平台……
这条演进之路,不仅是数据采集技术的进步,更是我们对“智能如何产生”这一根本问题的认知重构。
因此,本文将系统梳理Egocentric数据路线四年间的关键技术突破。
01 被误解的视角:为什么机器人永远学不会像人一样干活
在Egocentric数据真正成熟之前,机器人学习始终陷入一个死循环:
投入越多的动捕和遥操作数据,性能提升越缓慢。
直至今年,才终于意识到,我们从一开始就用错了数据。
旁观者视角的天生缺陷
第三人称数据本质上是“旁观者的智能”。当我们用固定摄像头拍摄人类操作时,看到的只是动作的外在形态,却看不到执行者的内心决策:
他为什么选择从这个角度伸手?他如何感知物体的重量?他在遇到阻力时如何调整力度?
这些隐藏在动作背后的智能,才是机器人真正需要学习的。

▲第三人称与第一人称
上海交通大学穆尧曾用一个经典实验解释这种差异:
两只小猫,一只可以自由行走探索世界,另一只被绑在椅子上只能被动观察;最终,被动观察的小猫完全失去了行走能力。
这就是具身智能的本质:智能不是通过观察获得的,而是通过与世界的主动交互获得的。
而第一人称数据,正是记录这种“主动交互”的唯一载体。

▲第一视角下的人类动作
五大顽疾困住第一人称数据
尽管第一人称数据的价值早已被认知,但在2022年之前,它始终无法真正落地到机器人领域,核心在于五大无法解决的“顽疾”:
- 标准缺失:不同团队使用的设备、视角、标注规范千差万别,数据无法互通,导致研究成果难以复现和对比。
- 人机鸿沟:人类与机器人在关节数量、运动范围、身体结构上存在巨大差异,人类动作无法直接映射到机器人本体。
- 成本高昂:专业头戴设备和动捕系统动辄数万元,采集流程复杂,难以实现大规模分布式采集。
- 模态单一:几乎所有早期第一人称数据集都只包含视觉信息,缺少触觉、力觉、惯性等关键物理交互信号。
- 时序断裂:数据多为几秒到几十秒的短片段,缺乏完整的任务因果链,无法支撑长时序、多步骤的复杂任务。
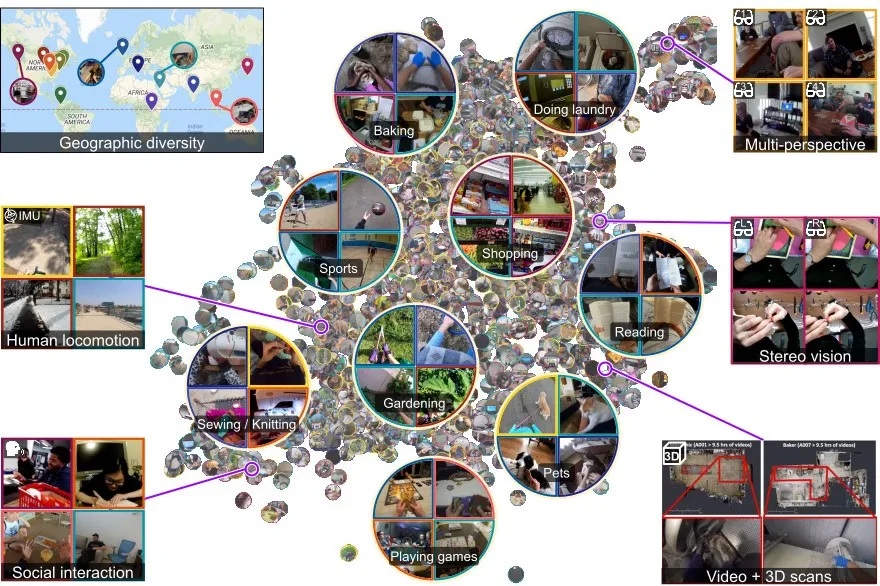
▲Ego4D数据集
这些问题让第一人称数据长期停留在学术研究层面,直到Ego4D的出现。
02 Ego4D与第一人称数据的标准化
2022年2月,由CMU、Meta、Google等全球13家顶尖机构联合发布的Ego4D数据集,成为了Egocentric领域的第一个里程碑。
它的意义不在于数据量有多大,而在于它首次为第一人称数据建立了完整的行业标准。

重新定义第一人称数据
Ego4D采用了统一的采集规范:
使用消费级头戴相机,统一帧率和分辨率,在全球74个国家和地区采集了超过3000小时的日常视频。
更重要的是,它定义了第一人称数据的多维度标注体系,包括视线追踪、手部关键点、物体交互、时序行为等,让零散的视频素材变成了可训练、可对比的标准化数据。
很多人质疑Ego4D包含了太多无关的日常场景,比如散步、聊天、吃饭,不适合直接训练机器人。
但这恰恰是它最有价值的地方——
“Ego4D的采集是无约束的,它帮AI建立了最基础的宏观物理常识。比如杯子掉在地上会碎,水会往低处流,这些常识是所有灵巧操作的基础。”
标准化带来的连锁反应
Ego4D的出现,彻底改变了第一人称研究的生态。
在此之前,每个团队都需要自己采集数据、自己定义标注规则,大量精力浪费在重复劳动上。
Ego4D之后,全球研究者有了统一的基准,可以专注于算法创新,而不是数据采集。

▲Ego4D基准测试套件围绕第一人称视觉体验展开一一从回忆过去、分析现在到预测未来
更重要的是,Ego4D证明了一个关键结论:
人类的日常行为中蕴含着通用的物理智能。
不需要专门设计的实验场景,不需要专业的操作人员,普通人的日常操作就足以训练AI理解物理世界的运行规律。
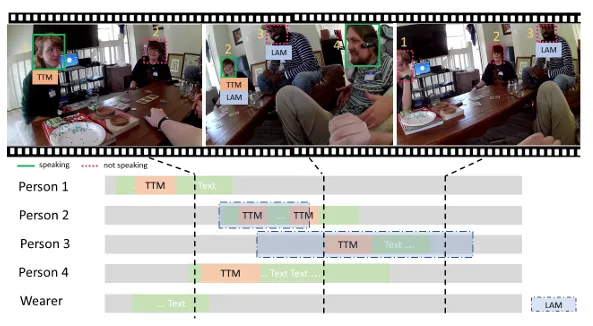
▲视听与社交基准注释
这个结论,为后来EgoScale的爆发埋下了伏笔。
03 EgoScale与对数线性定律的发现
如果说Ego4D解决了“有没有数据”的问题,那么2026年2月NVIDIA发布的EgoScale,则解决了“数据能不能用在机器人上”的核心问题。

2万小时视频背后的惊人发现
EgoScale发现了人类数据规模与机器人操控性能之间的对数线性关系。
研究团队在1k到20k小时的不同数据量上训练模型,发现随着数据量的增加,模型的验证损失呈完美的对数线性下降(R²=0.9983),而这种损失直接对应下游真实机器人的性能提升。

在此之前,机器人学习的性能提升是不可预测的,很多时候投入大量数据却看不到明显效果。
而EgoScale证明,只要数据是高质量的第一人称人类数据,机器人的性能就可以像大语言模型一样,通过增加数据量来稳定提升。
这给了行业一个明确的、可执行的路线图:只要不断扩大第一人称数据的规模,就能不断提升机器人的通用能力。
两阶段范式
EgoScale的另一个核心贡献,是提出了“大规模人类预训练+轻量人机对齐中训”的两阶段迁移范式。
研究团队发现,只需要在2万小时人类视频预训练的基础上,用极少量的人机对齐数据进行微调,就能让机器人掌握复杂的灵巧操作。

▲EgoScale:两阶段人到机器人学习框架
相比无预训练的基线模型,EgoScale将22自由度灵巧手的平均任务成功率提升了54%。
此外,这个模型还能很好地迁移到三指手等低自由度机器人上,证明了大规模人类数据可以学习到与具体本体无关的通用运动先验。
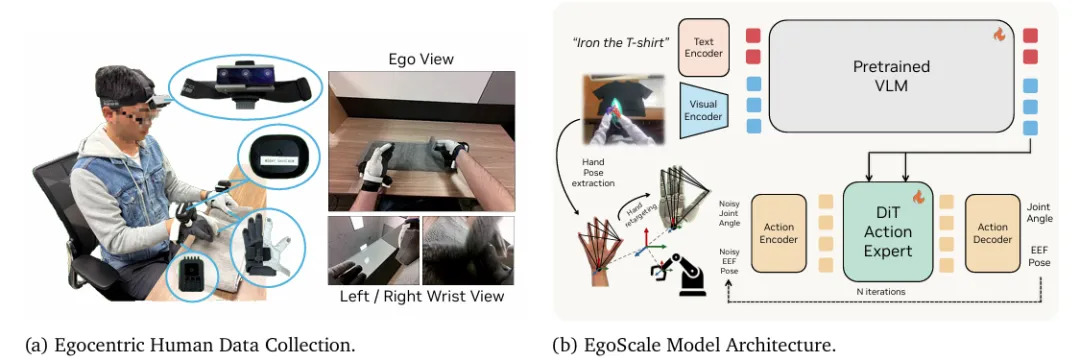
▲EgoScal的数据收集与模型架构
EgoScale证明,我们可以先在海量人类数据上训练一个通用的运动模型,然后只需要少量数据就能适配到不同的机器人本体上。这极大地降低了机器人开发的成本和周期。
04 从实验室到百万级众包
EgoScale的成功,让整个行业看到了第一人称数据的巨大价值。
但要实现产业落地,还需要解决一个最现实的问题:成本。
实验室里的专业设备虽然精度高,但无法大规模推广。
2026年3月,一系列低成本采集方案的出现,让第一人称数据真正从实验室走向了产业界。
20美元的采集革命:手机就能做的事
蚂蚁数科天玑实验室发布的AoE系统,重新定义了“规模化采集”的门槛。它不需要任何专业设备,只需要一部手机和一个20美元的颈挂式支架,就能实现全天候、非侵入式的第一人称数据采集。
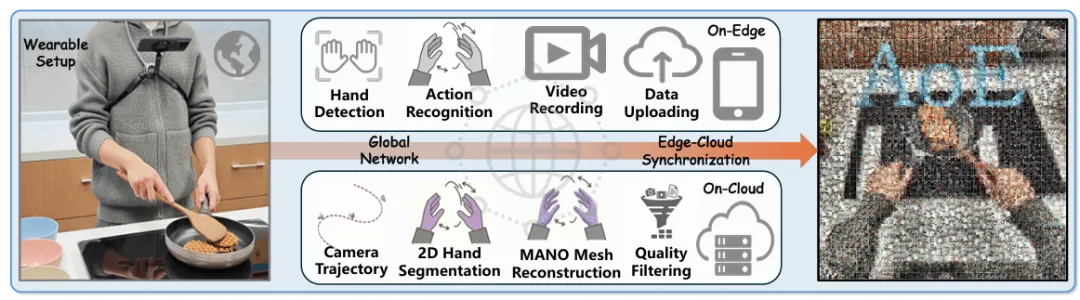
▲AoE系统概述
AoE采用了端云协同的架构:
端侧AI实时检测手-物交互,只有在有有效操作时才启动录制,大幅降低了存储和传输开销;
云端则通过自动化流水线完成数据的校正、分割、手部重建和质量控制。
整个过程几乎不需要人工干预,单用户每天可以采集数小时的高质量数据。
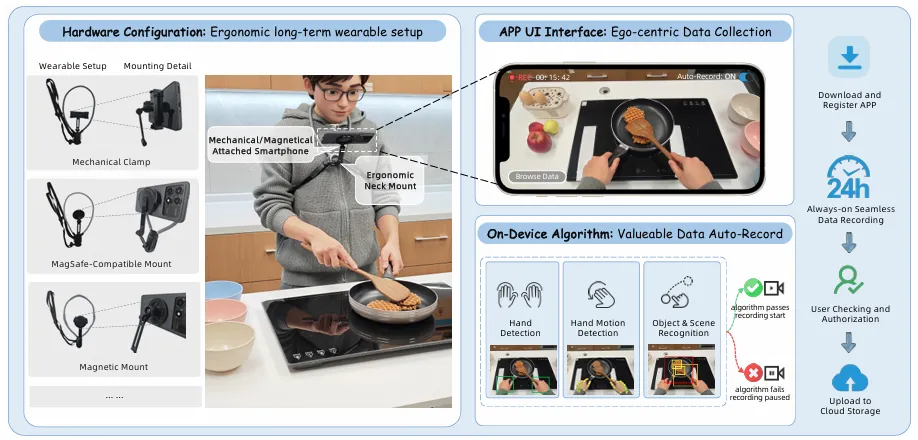
▲AoE硬件与移动应用概述
这种极致低成本的方案,让百万级众包采集成为可能。任何人、在任何时间、任何地点,都可以成为数据采集者。这不仅解决了数据规模的问题,还极大地丰富了数据的场景多样性。
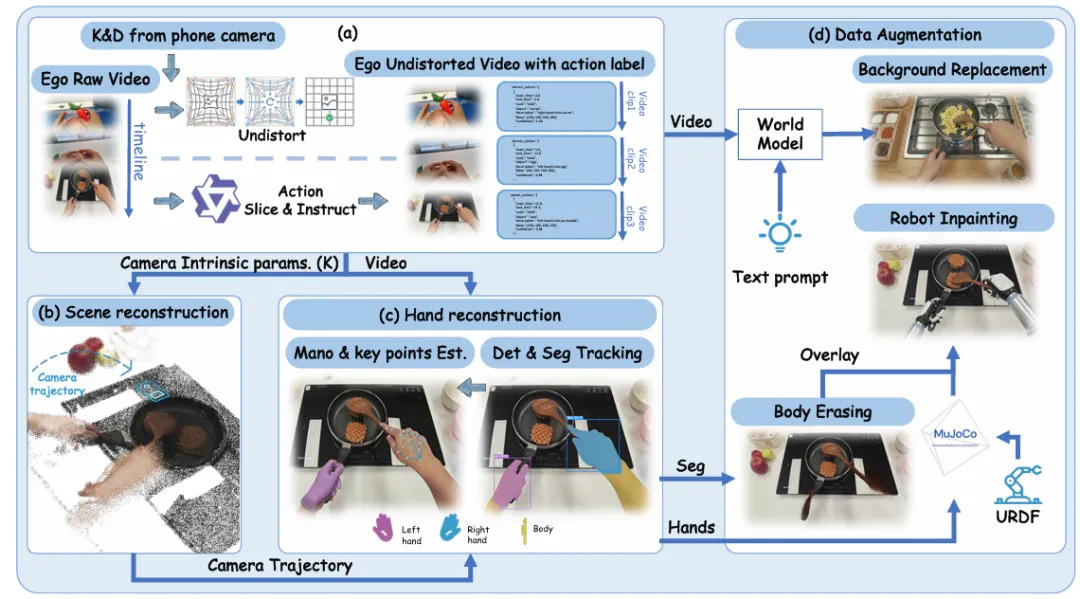
▲Egocentric 数据自动化标注与增强流水线
从量到质:全模态无遮挡采集
在解决了“量”的问题之后,行业开始追求“质”的提升。Gen Ego Data采集系统,解决了传统头戴设备的两大痛点:手部遮挡和模态单一。
它采用了6路高分辨率RGB-IR相机,实现了270°水平视野和150°垂直视野的全身覆盖,配合“头+手”协同硬同步技术,彻底消除了手部遮挡。
同时,它还集成了触觉、力觉、惯性等多模态传感器,实现了微秒级的时空同步,完整记录了物理交互的全过程。

这种全模态、无遮挡的采集方案,让第一人称数据从“视频片段”升级为可支撑世界模型训练的高质量基础设施。
它不仅记录了“人做了什么”,还记录了“人为什么这么做”以及“这么做产生了什么结果”,完整保留了动作的因果链。
05 从“看”到“摸”的精细交互突破
2026年4月,随着EgoTouch等视觉-触觉双模态方案的出现,第一人称数据终于进入了精细交互的新时代。
被忽视的触觉
人类的手部有超过17000个触觉感受器,我们通过触觉感知物体的材质、重量、温度和硬度,通过触觉反馈调整抓握力度和操作方式。
没有触觉,机器人永远无法实现类人级别的灵巧操作。
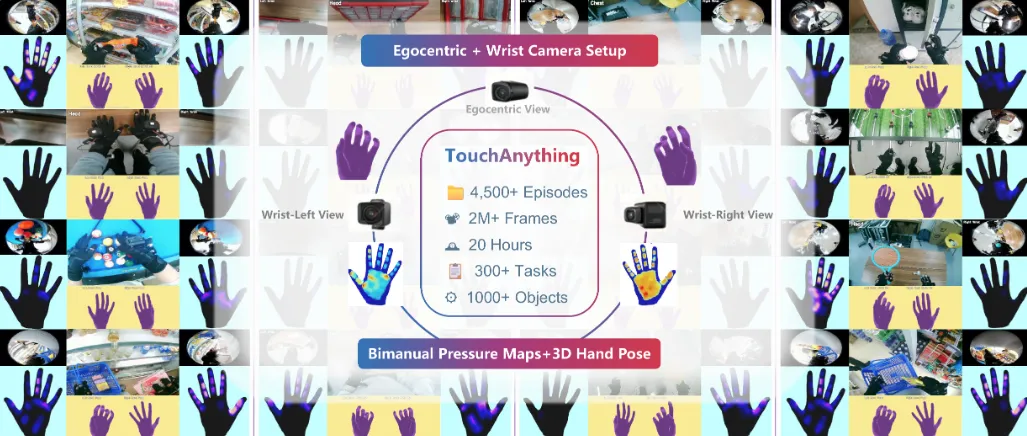
哈尔滨工业大学发布的EgoTouch系统,是业内首个实现视觉与触觉时空精准对齐的第一人称采集方案。
它采用“头戴主相机+双腕局部相机+全掌触觉手套”的组合,同步记录视觉图像和全掌压力分布、接触区域、实时力觉等触觉信号。
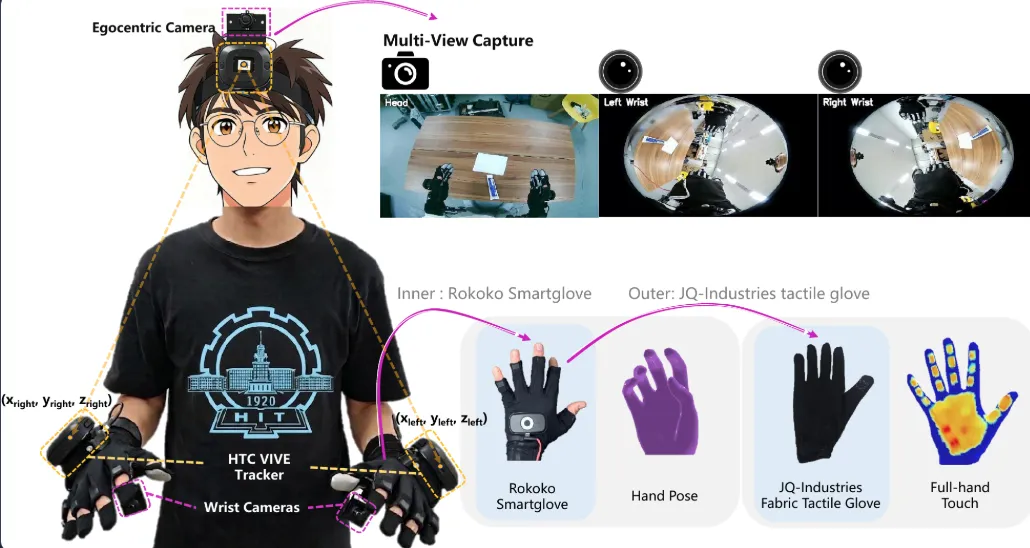
▲多传感器数据收集系统,配备头戴式自我中心摄像头、双腕摄像头和压力感应手套
EgoTouch覆盖了300多项双手精细操作任务,包括拧螺丝、插插头、系鞋带、包饺子等。这些数据为灵巧手提供了最稀缺的力控先验,让机器人不仅能“看到”动作,还能“感受到”接触。
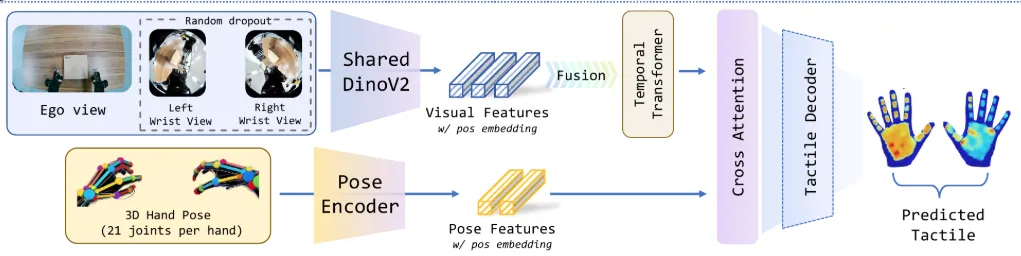
▲多视角触觉预测架构,具备共享视觉编码、交叉视角注意力和姿态感知融合
全球共享的通用语料库
与此同时,斯坦福大学等机构联合发布的EgoVerse数据集,构建了全球最大的标准化第一人称人类演示语料库。
它采用全球分布式众包模式,采集了超过1000小时的高质量人类操作视频,覆盖近2000项任务和数百个场景。

EgoVerse建立了统一的采集、标注和评测标准,所有数据都可以直接用于VLA模型的预训练和泛化性评测。
06 Egocentric的本质与未来
回顾2022-2026这四年的发展历程,我们可以清晰地看到,Egocentric数据从“教机器人做动作”,转向“让机器人像人一样学习”。
数据金字塔的重新定义
- 基座:EGO数据,体量最大、获取最便捷,提供通用的物理智能和运动先验。
- 中层:仿真数据和UMI数据,补充特定场景和特定本体的数据。
- 顶端:真机数据,保真度最高,但最难规模化,用于最终的微调与验证。
这个金字塔结构告诉我们,未来的具身智能,是建立在海量EGO数据的基础之上的。
谁能掌握高质量、大规模的EGO数据采集与处理技术,谁就能在具身智能的竞赛中占据先机。
下一个三年:从数据基建到世界模型
当前,第一人称数据已经解决了标准化、迁移性、规模化和多模态四大核心问题,但依然面临一些挑战:
多模态物理精度不足、跨本体迁移仍需少量适配、长尾场景覆盖有限、因果与动力学标注不够完备。

未来,第一人称数据或将沿着四个方向演进:
- 全模态轻量化:采集设备将更加轻便、集成化,实现视觉、触觉、力觉、惯性信息的端侧硬同步。
- 生成式闭环:真实数据与生成式AI深度结合,用真实数据校准生成模型,用生成数据突破规模天花板。
- 跨本体通用:数据将彻底与具体机器人本体解耦,实现“一次采集,全平台通用”。
- 因果化升级:数据将从记录动作,转向记录完整的“感知-决策-动作-结果”因果链,直接支撑世界模型的训练。
Egocentric数据已经改变了机器人学习的底层逻辑。
它让我们第一次真正理解了智能的本质:智能不是存在于大脑中的抽象符号,而是存在于与世界的交互之中。
人类的每一个动作、每一次触摸、每一个决策,都是智能的体现。
Ref
1、Ego4D: Around the World in 3,000 Hours of Egocentric Video(CVPR2022)https://arxiv.org/abs/2110.07058
2、EgoScale: Scaling Dexterous Manipulation with Diverse Egocentric Human Data
https://arxiv.org/abs/2602.16710狂“刷”2万小时人类视频,重新定义机器人操作上限,星海图助力实证英伟达EgoScale!
3、EgoHumanoid: Unlocking In-the-Wild Loco-Manipulation with Robot-Free Egocentric Demonstration:https://arxiv.org/abs/2602.10106
4、AoE: Always-on Egocentric Human Video Collection for Embodied AI:https://arxiv.org/pdf/2602.23893
5、TouchAnything: A Dataset and Framework for Bimanual Tactile Estimation from Egocentric Video:https://jianyi2004.github.io/TouchAnything-Website/
6、EgoVerse: An Egocentric Human Dataset for Robot Learning from Around the World:https://arxiv.org/abs/2604.07607

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)