从分钟级到小时级:SoulX-LiveAct 如何用 Neighbor Forcing+ConvKV 实现实时生成
本文深度解析 Soul AI Lab 2026 年最新论文《SoulX-LiveAct: Towards Hour-Scale Real-Time Human Animation with Neighbor Forcing and ConvKV Memory》,从核心问题拆解到技术原理,再到工程落地,一步步带你看懂如何用双 H100 GPU 实现 20 FPS 小时级实时数字人生成。
前言:数字人行业的卡脖子难题
随着 AIGC 技术的爆发,实时数字人已经成为直播、客服、教育等领域的刚需。但直到 2025 年底,行业主流方案仍面临两个无法突破的瓶颈:
- 时长限制:最多只能生成分钟级视频,超过 10 分钟就会出现严重的身份漂移、配饰丢失、动作卡顿
- 成本高昂:实时推理需要 5-8 张高端 GPU,单路数字人的硬件成本超过 10 万元,无法大规模落地
为什么会这样?根本原因在于自回归(AR)扩散模型的底层设计缺陷。传统 AR 扩散方法要么训练不稳定、收敛极慢,要么推理时 KV 缓存随帧数无界膨胀,最终导致内存溢出、性能暴跌。
SoulX-LiveAct 的出现彻底打破了这一僵局:仅需2 张 H100/H200 GPU就能实现20 FPS实时流式推理,支持小时级甚至无限长视频生成,同时在唇同步精度、人体动画质量、情感表现力上全面超越 SOTA。

本文将从核心问题出发,逐层拆解 SoulX-LiveAct 的两大核心创新 ——Neighbor Forcing和ConvKV Memory,告诉你它是如何做到 "又快又好又省" 的。
参考资料
- 论文原文:https://arxiv.org/abs/2603.11746
- 项目主页:https://soul-ailab.github.io/soulx-liveact/
- 代码仓库:https://github.com/Soul-AILab/SoulX-LiveAct
一、核心问题拆解:为什么现有 AR 扩散做不到小时级实时?
要理解 SoulX-LiveAct 的创新,首先得搞清楚现有 AR 扩散方法的本质缺陷。所有 AR 扩散模型的核心问题,都可以归结为一个问题:生成下一帧时,应该用历史帧的什么表征作为参考?
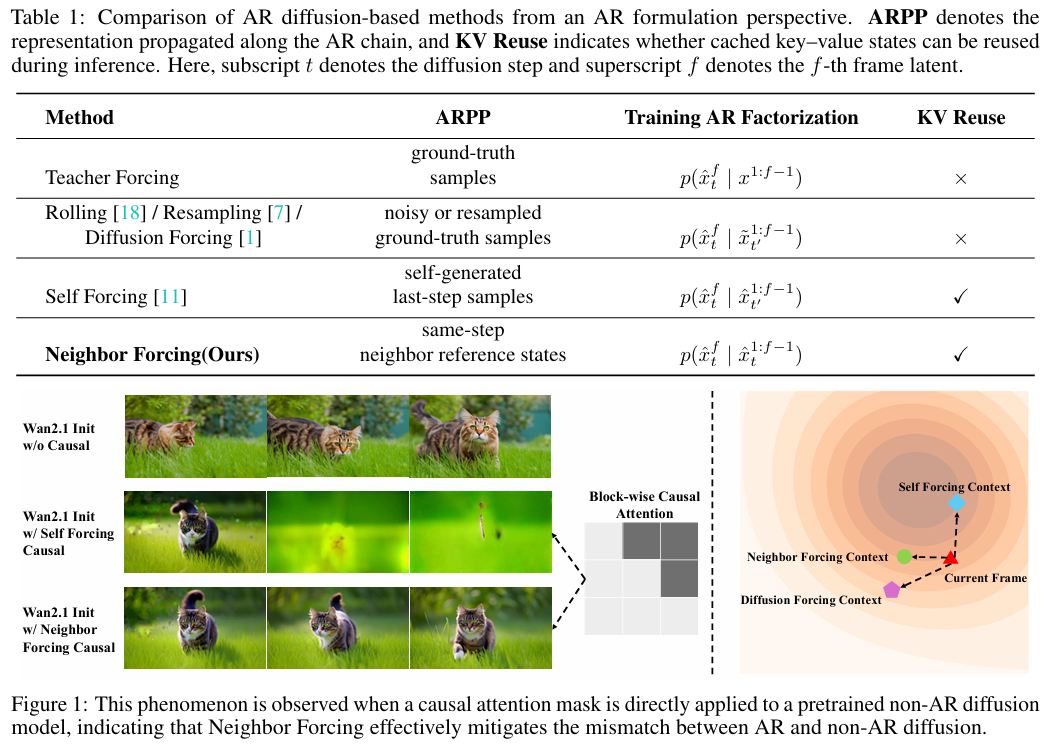
论文将这个参考表征命名为ARPP(Autoregressive Propagated Representation),并从这个维度系统对比了四类主流 AR 范式:
| 方法 | 传播的历史表征(ARPP) | 扩散步是否一致 | KV 复用 | 核心缺陷 |
|---|---|---|---|---|
| Teacher Forcing | 真实干净样本 | ❌ | ❌ | 训练 - 测试严重不匹配,误差指数级累积 |
| Diffusion Forcing | 任意步带噪真实样本 | ❌ | ❌ | 历史帧与当前帧噪声语义不一致,学习信号混乱 |
| Self Forcing | 最后一步(t'=0)干净样本 | ❌ | ✅ | 仍存在扩散步不匹配,训练不稳定,需要大量数据 |
| Neighbor Forcing(本文) | 同扩散步 t 的相邻帧隐层 | ✅ | ✅ | 无上述缺陷 |
1.1 扩散步不匹配:所有问题的根源
什么是扩散步不匹配?我们可以用一个简单的比喻来理解:
- 扩散模型的生成过程,就像把一张模糊的照片一步步变清晰,每个扩散步对应一个模糊程度
- 传统方法生成第 100 帧时,用的是第 99 帧的清晰照片(t'=0)作为参考,但第 100 帧本身还是模糊的(t=50)
- 这就相当于让一个小学生(模糊帧)去看大学课本(清晰帧)学习,自然学不好,还会越学越乱
这种跨噪声空间的对齐,不仅导致训练收敛极慢(Self Forcing 需要 16K 数据的 ODE 初始化训练 + 1000 步蒸馏),还会让模型在长视频生成中不断累积误差,最终出现身份漂移。
1.2 一个震撼的零样本实验:AR 与非 AR 并非天生不兼容
论文用一个极其简单的实验,直接推翻了 "非 AR 扩散骨干不能用于 AR 生成" 的传统认知:
- 基础模型:完全预训练的非 AR 扩散模型 Wan2.1(未经过任何 AR 训练)
- 操作:仅添加块级因果注意力掩码(强制模型只能看历史帧)
- 变量:仅改变传播的历史表征(ARPP)
实验结果令人震惊:
- 用 Self Forcing:模型直接崩溃,生成绿色噪声
- 用 Neighbor Forcing:同一个非 AR 模型,零样本就能生成主体一致、时序稳定的视频!
这说明:AR 扩散与非 AR 骨干并非天生不兼容,问题只出在历史表征的选择上。只要传播同扩散步的相邻帧隐层,非 AR 模型就能天然具备 AR 生成能力。
二、核心创新一:Neighbor Forcing—— 同扩散步对齐的自回归范式
Neighbor Forcing 的核心思想极其简单却极其有效:让历史帧和当前帧处于完全相同的扩散步,在同一个噪声空间中建模时序依赖。
2.1 数学原理:同扩散步的局部平滑性
论文附录 A 从数学上严格证明了这一设计的合理性:
- 时序相邻的干净帧在隐空间中天然接近(局部平滑性)
- 对这些帧施加相同扩散步 t的噪声后,它们的期望距离仍然保持 "信号项 + 固定噪声项" 的结构
- 邻域关系在期望意义下被完全保留,不会随扩散步变化而破坏
基于这一原理,Neighbor Forcing 的训练目标被定义为:
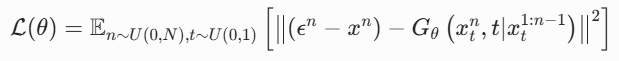
其中,![]() 到
到![]() 是同扩散步 t 的历史帧隐层,
是同扩散步 t 的历史帧隐层,![]() 是当前待生成帧隐层。所有条件和目标都处于同一个噪声空间,没有任何跨步对齐。
是当前待生成帧隐层。所有条件和目标都处于同一个噪声空间,没有任何跨步对齐。
2.2 训练优势:成本降低 3 倍以上
相比 Self Forcing,Neighbor Forcing 的训练成本呈数量级下降:
| 方法 | ODE 初始化训练 | DMD 蒸馏步数 | 总训练数据量 |
|---|---|---|---|
| Self Forcing | 需要(16K 数据) | 1000 步 | 数千小时 |
| Neighbor Forcing | ❌ 不需要 | 300 步 | 300 小时 |
这是因为同扩散步对齐提供了天然干净的学习信号,模型不需要学习跨噪声空间的复杂映射,收敛速度大幅提升。
2.3 系统优势:天然支持 KV 复用
Neighbor Forcing 还有一个极其重要的系统级优势:历史帧的 KV 在后续同一步的推理中完全不需要重新计算。
传统 AR 方法中,每个扩散步都需要重新计算所有历史帧的 KV,计算量是O(n2)。而 Neighbor Forcing 中,KV 只需计算一次,后续直接复用,计算量降至O(n)。这是实现 20 FPS 实时推理的核心基础。
三、核心创新二:ConvKV Memory—— 恒定内存的轻量 KV 压缩机制
Neighbor Forcing 解决了训练不稳定和 KV 复用的问题,但仍面临一个致命挑战:KV 缓存会随帧数线性增长。生成 1 小时视频需要存储数十万帧的 KV,内存会很快溢出。
这就是 ConvKV Memory 要解决的问题:在几乎不损失生成质量的前提下,将无限增长的 KV 缓存压缩为固定长度。
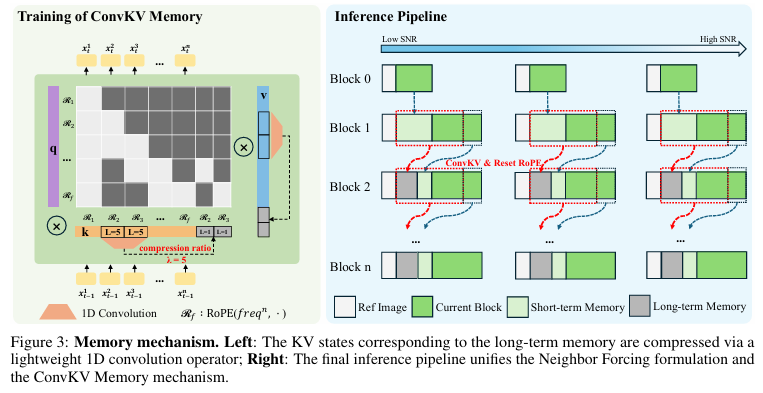
3.1 为什么 ConvKV 能做到几乎无损压缩?
ConvKV 的有效性完全建立在 Neighbor Forcing 的同扩散步对齐之上:
- 所有历史 KV 都处于完全相同的扩散步 t,分布高度一致,时序冗余度极高
- 同扩散步的相邻帧隐层满足局部平滑性,相邻 KV 块的差异极小
- 因此不需要复杂的 UNet 或 Transformer 编码器,仅用1D 卷积就能实现 5:1 的压缩比
3.2 训练机制:追加式训练,保护预训练注意力
ConvKV 的训练采用了一个非常巧妙的 "追加式" 设计,避免破坏预训练 DiT 的注意力分布:
- 生成原始 KV:所有帧隐层通过 DiT 生成原始 K 和 V 张量
- 分层压缩:
- 短期 KV:保留最近 2 个块的原始 KV,不压缩,保证精细动作
- 长期 KV:用核大小 = 5、步长 = 5 的 1D 卷积压缩,压缩比 λ=5
- RoPE 重置:将压缩后 KV 的位置编码对齐到原始时序的起始位置
- 追加而非替换:将压缩后的长期内存追加到原始 KV 张量末尾,同时修改注意力掩码
- 损失计算:仍使用同扩散步的 Flow Matching MSE 损失,仅训练 1D 卷积参数
这种设计的好处是:预训练 DiT 的注意力模式完全不受影响,训练极其稳定,仅需 400 步就能收敛。
3.3 推理机制:替换式内存管理,实现恒定内存
推理阶段采用 "替换式" 内存管理,无论生成多少小时的视频,KV 缓存总长度永远固定为6 个隐层块:
| 类型 | 数量 | 作用 |
|---|---|---|
| 参考图像 | 2 块 | 全局身份、服装、背景锚点 |
| 长期内存 | 2 块 | 压缩后的更早历史,保证全局一致性 |
| 短期内存 | 2 块 | 上一个生成块的原始 KV,保留近期动作细节 |
推理流程(从第三个块开始):
- 长期内存更新:将上一个块的短期内存送入 ConvKV 压缩,重置 RoPE 后成为新的长期内存
- 短期内存更新:将上一个块的当前块直接作为当前块的短期内存
- 当前块生成:以 "参考图像 + 长期内存 + 短期内存" 为条件,生成新的当前块
- 旧内存丢弃:直接丢弃旧的长期内存,总内存保持不变
关键细节:参考图像、长期内存、短期内存的 KV 在同一个扩散步的所有生成块中完全不需要重新计算,仅需计算当前块的 KV。这一优化让推理速度再提升一个数量级。
四、工程落地:两阶段训练流水线与系统优化
SoulX-LiveAct 将整个训练过程解耦为两个独立阶段,完美平衡了生成质量和推理效率。
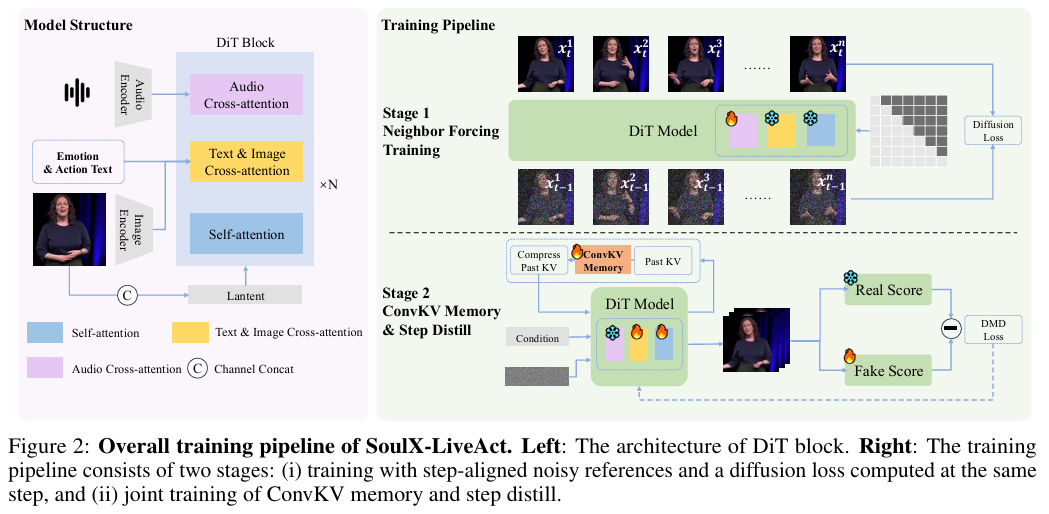
4.1 两阶段训练流水线
阶段 1:Neighbor Forcing 训练
- 目标:训练音频 - 文本 - 视频的精准对齐,保证唇同步、动作匹配、情感自然
- 权重初始化:
- 自注意力 + 文本图像交叉注意力:初始化自 Wan2.1
- 音频交叉注意力:初始化自 InfiniteTalk
- 训练数据:300 小时多模态配对数据(视频 + 音频 + 情感动作标注)
- 损失函数:同扩散步 Flow Matching MSE 损失
阶段 2:ConvKV Memory+Step Distill 训练
- 目标:实现恒定内存推理,同时将多步采样蒸馏为 3 步采样
- 权重初始化:DiT 主体权重完全冻结,仅新增 ConvKV 的 1D 卷积参数和蒸馏头
- 训练步数:仅 400 步
- 损失函数:DMD(Distribution Matching Distillation)损失
这种解耦设计的优势是:两个阶段可以独立调试,大幅降低了开发难度。
4.2 系统级优化:双 GPU 实现 20 FPS
除了算法创新,SoulX-LiveAct 还做了大量系统级优化,最终实现了双 H100 GPU 20 FPS 的实时性能:
- 端到端 FP8 精度:在不损失生成质量的前提下,将显存占用降低 50%,计算速度提升 2 倍
- 序列并行:将长序列切分到多个 GPU 上并行计算,进一步提升吞吐量
- 算子融合:将多个小算子融合为一个大算子,减少 GPU 内核启动开销
- KV 缓存复用:如前所述,将计算量从O(n2)降至O(n)
最终,单帧 512×512 分辨率的计算量仅为27.2 TFLOPs,比之前的 SOTA 方法降低了 30% 以上。
五、实验结果:全面超越 SOTA 的性能与效率
5.1 定量性能对比
论文在 HDTF(人脸)和 EMTD(全身)两个数据集上进行了全面测试,结果如下:
唇同步与视频质量(HDTF 数据集)
| 模型 | Sync-C↑ | Sync-D↓ | FID↓ | FVD↓ | 人体保真度↑ |
|---|---|---|---|---|---|
| OmniAvatar | 5.13 | 10.19 | 27.90 | 268.47 | 96.8 |
| InfiniteTalk | 7.12 | 8.01 | 18.15 | 169.88 | 99.4 |
| Live-Avatar | 7.68 | 8.38 | 15.85 | 206.20 | 99.8 |
| SoulX-LiveAct | 9.40 | 6.76 | 10.05 | 69.43 | 99.9 |
推理效率对比
| 模型 | FPS | 延迟 (s) | GPU 数 | 单帧 TFLOPs |
|---|---|---|---|---|
| InfiniteTalk | 25 | 3.20 | 8 | 50.2 |
| Live-Avatar | 20 | 2.89 | 5 | 39.1 |
| SoulX-LiveAct | 20 | 0.94 | 2 | 27.2 |
5.2 定性结果分析
- 唇同步精度:唇形与音素精准对齐,特别是双唇音和元音的表现远超基线
- 长视频一致性:生成 1 小时视频无身份漂移,配饰(戒指、项链)、服装纹理全程稳定
- 情感动作控制:支持动态修改面部表情和肢体动作,同时保留身份和唇同步
- 鲁棒性:在手势遮挡、快速运动等复杂场景下,仍能保持稳定的生成质量
六、总结与展望
SoulX-LiveAct 的核心贡献可以概括为三点:
- 提出 Neighbor Forcing 范式:一定程度上解决了 AR 扩散的扩散步不匹配问题,让训练更稳定、收敛更快、推理更高效
- 提出 ConvKV Memory 机制:用轻量 1D 卷积实现了恒定内存的小时级视频生成,推理开销仅增加 1.9%
- 构建了实时系统:仅需双 H100 GPU 就能实现 20 FPS 实时推理,将数字人的硬件成本降低了 70% 以上
未来展望
- 更高分辨率:目前支持 512×512 和 720×416,未来有望扩展到 1080P 甚至 4K
- 更复杂动作:支持全身大动作、多人交互等更复杂的场景
- 多模态交互:结合大语言模型,实现实时语音对话 + 动作生成的端到端数字人
- 边缘部署:进一步优化模型大小和计算量,实现手机端实时数字人生成
SoulX-LiveAct 的出现,标志着实时数字人技术已经从 "实验室演示" 进入了 "大规模落地" 的阶段。相信在不久的将来,我们会看到数字人出现在生活的方方面面,彻底改变人机交互的方式。
如果你对AIGC 视频生成感兴趣,欢迎在评论区留言讨论。我会持续分享最新的 AI 技术解析和工程实践。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 19
19 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)