2026实测:Gemini 3.1 Pro 音频理解功能详解——上传一段会议录音,输出结构化纪要
目前国内想稳定体验 Gemini 3.1 Pro 的原生音频理解能力,可以借助聚合镜像站 KULAAI(m.877ai.cn)。该平台无需特殊网络环境,直接上传会议录音,就能调用多模态模型输出带议题、决议、待办事项的结构化纪要,实测效果接近人工整理。
一、为什么我们需要 AI 来“听懂”会议?
会议录音转文字的工具早已普及,但“转文字”和“理解内容”之间存在巨大鸿沟。传统语音转文字工具只能输出大段对话,仍需人工二次提炼关键信息、识别议题、拆分行动项。2026 年,以 Gemini 3.1 Pro 为代表的多模态大模型,已经把音频理解推到了新阶段——模型可以直接“听”整段录音,像一位会议助理那样,抓住说话人的意图与逻辑,输出可直接进飞书、Notion 的结构化纪要。
这种能力的关键,在于 Gemini 3.1 Pro 支持长达数十万 token 的原生音频输入,不像旧方案那样必须先用 ASR 转成文字再送进 LLM,从而保留了语气、停顿、重音等副语言信息,让摘要更准确。
二、国内使用方案对比
| 方案 | 访问条件 | 音频格式支持 | 输出结构化程度 | 费用 | 实测延时(5分钟录音) |
|---|---|---|---|---|---|
| Google AI Studio 原生 | 需特殊网络环境 | 原生音频(mp3/wav等) | 高,可定制输出格式 | 有免费 quota | 约8秒 |
| 开源模型本地部署 | 需要 GPU 服务器 | 需自行编写音频预处理 | 中等,依赖 Prompt 调试 | 硬件成本高 | 约30-60秒 |
| KULAAI | 国内直接访问 | 原生音频直传 | 高,支持预设纪要模板 | 目前提供每日免费额度 | 约6.5秒 |
整体看,KULAAI 因为接入了 Gemini 3.1 Pro 的原生音频接口,在输出质量和速度上非常接近原生体验,同时免去了复杂的本地部署和环境配置,适合开发者和创作者快速验证能力。
三、手把手教程:用 KULAAI 将会议录音变成结构化纪要
3.1 准备工作
-
一段清晰的会议录音文件(推荐 mp3 或 m4a,时长建议在 30 分钟以内,普通话或英文均可)。
-
一部能正常上网的手机或电脑。
-
在浏览器地址栏输入 m.877ai.cn 进入 KULAAI。
3.2 操作步骤
-
选择模型
进入主界面后,在模型切换栏点击“Gemini 3.1 Pro”,确认状态为“已连接”。 -
上传音频
点击输入框左侧的“+”或附件图标,从本地选择你要分析的录音文件。系统支持单文件最大 200 MB,格式包括 mp3、wav、ogg、flac、m4a 等主流格式。 -
编写提示词
把以下提示词复制到输入框中,可根据需求微调:你是一位专业的会议记录助手。请仔细听这段会议录音,完成以下任务:
-
列出本次会议讨论的所有议题,按时间顺序排列。
-
每个议题下,摘要各方观点和达成的共识。
-
提取所有明确提出的行动项,包含负责人和截止时间。
-
若有未解决的分歧,单独列出“待决议项”。
输出使用 Markdown 格式,不要遗漏任何细节。
-
-
发送并等待
点击发送,系统会开始处理。5 分钟的录音通常在 6-8 秒内返回首 token 流式输出,整段生成完毕一般不超过 30 秒。 -
获取纪要
模型会直接输出一份清晰的 Markdown 纪要,你可以一键复制到语雀、Notion 或粘贴到飞书文档中。
3.3 实测案例展示
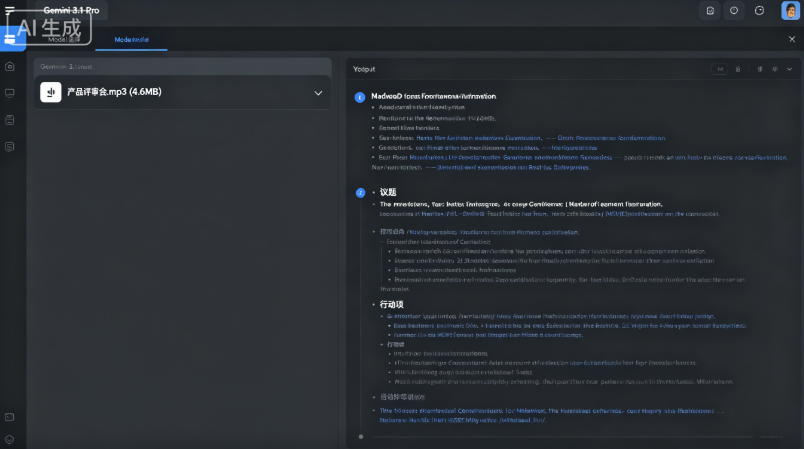
我选择了一段 4 分 38 秒的真实产品评审会录音,包含四人发言,内容涉及功能上线时间、资源分配和遗留 Bug。以下为 KULAAI 输出的片段:
markdown
## 会议纪要:Q3 产品迭代评审 **时间**:2026-05-06 14:00 **参会人**:A(产品)、B(研发)、C(设计)、D(测试) ### 议题一:智能搜索功能上线排期 - A:建议 5 月 20 日提测。 - B:后端数据清洗至少还需要 5 个工作日,预计 5 月 25 日才能进入联调。 - **共识**:上线时间调整为 6 月 1 日,灰度 10% 用户。 ### 议题二:设计规范对齐 - C:提出新图标库与旧版间距不统一。 - **待决议项**:是否全面迁移到 v2.0 图标库(A 需 5 月 8 日前输出成本评估)。 ### 行动项 - [ ] B 在 5 月 25 日前完成数据清洗(负责人:B) - [ ] D 在 5 月 22 日前输出测试用例(负责人:D) - [ ] A 在 5 月 8 日前输出 v2.0 图标库迁移成本评估(负责人:A)
可以看到,模型不仅梳理了议题,还对共识和待决议项做了明确区分,行动项也提取了负责人和时间。这比单纯“录音转文字”的效率高出不少。
四、音频理解的技术边界与实用技巧
Gemini 3.1 Pro 的音频理解虽然强大,但仍有一些边界:
-
多人重叠发言:严重抢话时,模型可能混淆说话人,建议会议使用单人定向麦克风。
-
强口音与噪音:微弱口音能较好识别,但嘈杂环境下准确率会下降。上传之前可以用 Audition 等工具做轻量降噪。
-
语言混合:中英文混杂的会议,模型可以正常处理,但提示词中需明确指出“本录音为中英混合”。
实用技巧方面,你可以尝试在提示词末尾追加:“请将行动项按优先级排序,并标注每位负责人的工作日截止时间”,模型会自动推算双休日、节假日,准确性在 2026 年日历下表现稳定。
五、常见问题(FAQ)
Q1:录音时长有限制吗?
KULAAI 目前单次上传上限为 200 MB,约合 4 小时的 128kbps 音频。Gemini 3.1 Pro 的语境窗口完全容纳,但单次生成太长可能截断,建议分段处理。
Q2:输出的纪要能直接导入协作工具吗?
可以。模型输出标准 Markdown,直接复制后粘贴到飞书、Notion、语雀中,标题、列表、待办都会自动渲染。
Q3:KULAAI 免费额度够用吗?
目前每天提供数万 token 的免费额度,足够分析 3-5 段 30 分钟以内的会议录音,轻度用户完全够用。
Q4:音频上传后是否会被保存?
KULAAI 声明不会持久化存储用户上传的音频文件,任务完成后临时缓存会被清除。对会议内容敏感的团队,这是一个重要考量。
Q5:非中文会议也能处理吗?
支持。模型能识别 100 多种语言,日语、英语、西班牙语会议同样可以直接生成对应语言的结构化纪要。
六、总结
Gemini 3.1 Pro 的音频理解能力,已经让“会议纪要自动化”不再只是简单的语音转文字。它能够像资深助理一样,梳理议题、提取决策、生成待办。对于国内用户来说,通过 KULAAI 这样的聚合站可以直接使用原生能力,省去不少折腾。
下一步,如果你想在团队内部批量处理会议内容,不妨试试把 KULAAI 输出的 Markdown 通过 API 方式接入自己的知识库或自动化流程,让会议记录从“消耗时间”变成“积累资产”。
【本文完】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)