RAG技术深度解析:学习笔记
摘要:本文深入剖析RAG(检索增强生成)技术的核心原理与实现,涵盖文档处理、向量检索、生成优化及评估体系,结合大量代码示例与实战经验,助力构建高效智能问答系统。
关于rag流程看这张图回想一下关键点:(图源自bilibili:费曼学徒冬瓜)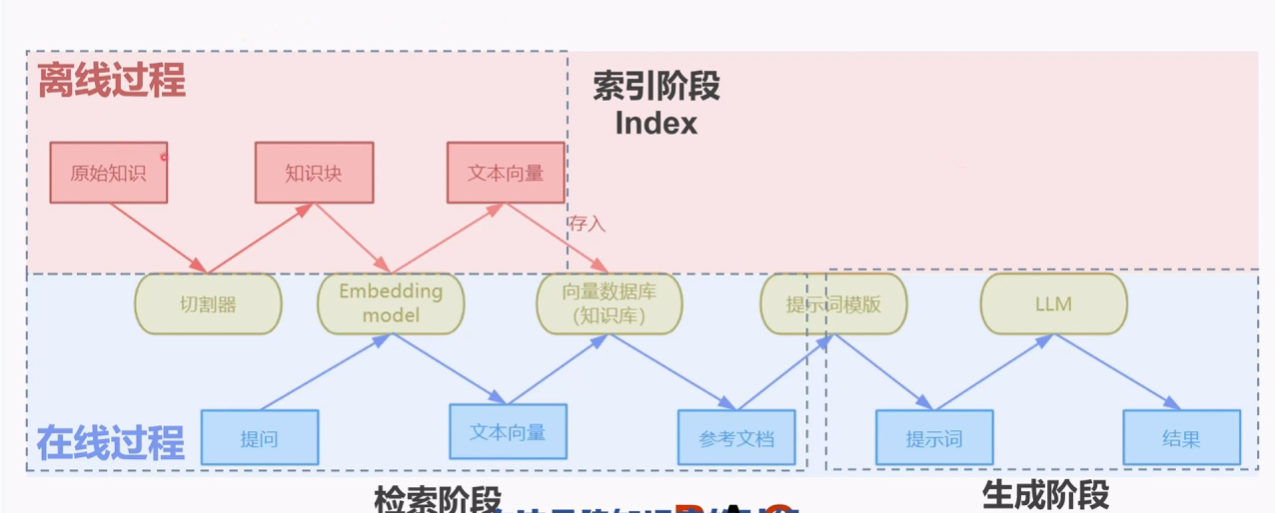
1. 引言:为什么需要RAG
1.1 大语言模型的局限性
大语言模型(LLM)在自然语言处理领域取得了革命性突破,但在实际应用中仍面临三大核心挑战:
知识时效性问题
LLM的知识来源于训练数据,无法获取训练截止日期之后的信息。例如,询问"腾讯某某规格服务器价格配置",模型可能给出错误答案或明确表示无法回答。
幻觉现象
模型可能生成看似合理但实际错误的内容。例如,询问不存在的学术论文或虚构的技术细节时,LLM可能编造出令人信服但完全虚假的信息。
领域知识缺失
通用LLM在特定领域(如医疗、法律、企业内部文档)缺乏专业知识,难以提供准确可靠的回答。
1.2 RAG技术的核心价值
RAG(Retrieval-Augmented Generation,检索增强生成)通过引入外部知识库,有效解决了上述问题:
- 动态知识更新:无需重新训练模型,通过更新知识库即可获取最新信息
- 可信回答:基于检索到的真实文档生成答案,减少幻觉现象
- 可解释性:提供答案的来源依据,增强可信度
- 领域适应:轻松接入企业知识库,实现垂直领域应用
2. RAG技术概述
2.1 RAG的定义与背景
RAG是一种结合检索(Retrieval)和生成(Generation)的技术架构,其核心思想是:
在生成答案之前,先从外部知识库中检索相关信息,将检索结果作为上下文输入到LLM,从而生成更准确、更有依据的回答。
RAG最早由Facebook AI Research在2020年提出,随着大语言模型的兴起,迅速成为企业级AI应用的首选架构。
2.2 与传统方案的对比
| 方案 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| 纯检索 | 准确、可解释 | 无法理解复杂问题 | FAQ、文档搜索 |
| 纯生成 | 灵活、流畅 | 幻觉、知识过时 | 创意写作、开放对话 |
| RAG | 准确+灵活 | 系统复杂度高 | 企业问答、知识助手 |
这里同样放上费曼学徒冬瓜博主对RAG和微调模型的看法(在企业内肯定是无脑选择RAG)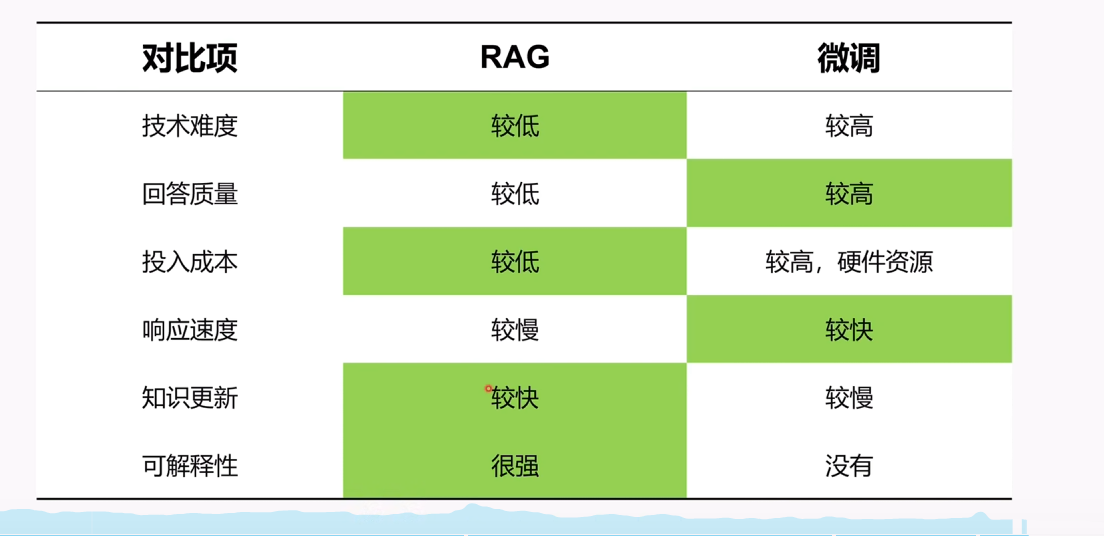
2.3 RAG的应用场景
RAG技术已在多个领域广泛应用:
- 企业知识助手:内部文档智能问答
- 智能客服:基于产品文档的自动应答
- 法律咨询:法规条文检索与解读
- 医疗诊断:医学文献辅助诊断
- 教育辅导:个性化学习材料推荐
3. RAG执行流程详解
3.1 整体架构图解
RAG系统包含四大核心阶段:
3.2 四大核心阶段详解
阶段一:索引(Indexing)
离线构建知识库索引:
- 加载文档(PDF、Word、Markdown等)
- 文档切分为合适大小的文本块
- 使用Embedding模型向量化
- 存储到向量数据库
阶段二:检索(Retrieval)
在线查询阶段:
- 将用户问题向量化
- 在向量数据库中检索相似文档
- 返回Top-K个相关文档块
阶段三:增强(Augmentation)
构建Prompt:
- 将检索到的文档块作为上下文
- 设计Prompt模板,组合问题和上下文
- 可能包含历史对话、系统指令等
阶段四:生成(Generation)
LLM生成答案:
- 将增强后的Prompt输入LLM
- 基于上下文生成回答
- 可选择流式输出或一次性返回
3.3 数据流转过程
以企业问答为例:
用户问题:"公司的报销流程是什么?"
↓
[检索阶段]
问题向量化 → 向量检索 → 返回相关文档块:
- "报销流程.doc"第3段:提交报销申请...
- "财务制度.pdf"第5页:报销审批流程...
↓
[增强阶段]
构建Prompt:
{基于以下文档回答问题:
文档1:提交报销申请...
文档2:报销审批流程...
问题:公司的报销流程是什么?}
↓
[生成阶段]
LLM输出:"根据公司规定,报销流程分为以下步骤:1. 提交申请..."
4. 关键步骤一:文档预处理与切分
4.1 文档加载技术
不同格式的文档需要使用不同的加载器:
from langchain_community.document_loaders import (
PyPDFLoader, # PDF文档
Docx2txtLoader, # Word文档
UnstructuredMarkdownLoader, # Markdown
TextLoader # 纯文本
)
# 加载PDF
pdf_loader = PyPDFLoader("company_docs/policy.pdf")
pdf_docs = pdf_loader.load()
# 加载Word
docx_loader = Docx2txtLoader("company_docs/manual.docx")
docx_docs = docx_loader.load()
# 合并所有文档
all_docs = pdf_docs + docx_docs
关键参数:
extract_images:是否提取图片中的文字(需OCR支持)chunk_size:预览时建议设置合理分块
4.2 切分策略对比
文档切分是影响检索质量的关键环节,主要策略包括:
策略一:固定长度切分(把一个句子按固定字数切分,比如500字分一次)
from langchain.text_splitter import CharacterTextSplitter
splitter = CharacterTextSplitter(
chunk_size=500, # 每块500字符
chunk_overlap=50, # 块之间重叠50字符
separator="\n\n" # 按段落分割
)
chunks = splitter.split_documents(all_docs)
优点:实现简单,块大小可控
缺点:可能切断语义完整性
适用:结构化较好的文档
策略二:递归字符切分(按段落,标点符号切分,意思比较完整)
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "!", "?", " ", ""]
)
chunks = splitter.split_documents(all_docs)
优点:优先按段落、句子分割,保持语义完整
缺点:块大小可能不均
适用:大多数场景的推荐方案
策略三:语义切分(直接导入模型,让模型根据意思来切分,肯定是最好的,成本也最大)
from langchain_experimental.text_splitters import SemanticChunker
from langchain_openai import OpenAIEmbeddings
# 基于语义相似度切分
semantic_splitter = SemanticChunker(
OpenAIEmbeddings(),
breakpoint_threshold_type="percentile"
)
chunks = semantic_splitter.split_documents(all_docs)
优点:语义完整性最佳
缺点:计算成本高,需要调用Embedding API
适用:高质量要求的场景
4.3 切分最佳实践
from langchain.text_splitter import RecursiveCharacterTextSplitter
def smart_chunk_documents(documents, chunk_size=500, chunk_overlap=50):
"""
智能文档切分
- 保持元数据
- 过滤过短块
- 平衡语义完整性与检索效率
"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", "。", "!", "?", ";", " ", ""],
length_function=len,
)
chunks = splitter.split_documents(documents)
# 过滤过短的块(少于50字符)
chunks = [chunk for chunk in chunks if len(chunk.page_content) > 50]
# 为每个块添加唯一ID
for i, chunk in enumerate(chunks):
chunk.metadata["chunk_id"] = f"chunk_{i}"
return chunks
# 使用示例
chunks = smart_chunk_documents(all_docs, chunk_size=500)
print(f"切分完成:共{len(chunks)}个文本块")
参数调优建议:
- chunk_size:一般300-800字符,过小导致信息碎片化,过大降低检索精度
- chunk_overlap:建议chunk_size的10%-20%,保证上下文连贯
- 最小块长度:过滤少于50字符的块,避免检索噪音
5. 关键步骤二:向量化与索引构建
5.1 Embedding模型选择(embedding也就是向量化,个人感觉和transformer的差不多,有兴趣可以去读一下attention is all…)
如果大家对模型排名感兴趣可以去huggingface查询
Embedding模型直接影响检索质量,主流模型对比:
| 模型 | 维度 | 性能 | 成本 | 特点 |
|---|---|---|---|---|
| OpenAI text-embedding-3-small | 1536 | 优秀 | 收费 | 通用性强,适合大多数场景 |
| OpenAI text-embedding-3-large | 3072 | 最佳 | 收费 | 高质量,适合专业领域 |
| BGE-large-zh | 1024 | 优秀 | 免费 | 中文效果好,可私有部署 |
| M3E-base | 768 | 良好 | 免费 | 开源,中文场景推荐 |
from langchain_openai import OpenAIEmbeddings
from langchain_community.embeddings import HuggingFaceEmbeddings
# 使用OpenAI模型
openai_embeddings = OpenAIEmbeddings(
model="text-embedding-3-small"
)
# 使用开源模型(私有部署)
local_embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-large-zh",
model_kwargs={'device': 'cuda'},
encode_kwargs={'normalize_embeddings': True}
)
选型建议:
- 英文场景:优先OpenAI text-embedding-3-small
- 中文场景:优先BGE-large-zh或M3E系列
- 数据安全要求高:私有部署开源模型
- 成本敏感:使用开源模型
5.2 向量数据库对比
| 数据库 | 特点 | 适用场景 |
|---|---|---|
| FAISS | Meta开源,纯内存,速度快 | 原型开发、中小规模数据 |
| Chroma | 轻量级,易上手,支持持久化 | 快速验证、开发测试 |
| Milvus | 分布式,高性能,云原生 | 生产环境、大规模数据 |
| Pinecone | 托管服务,免运维 | 快速上线、无运维需求 |
| Weaviate | 支持混合检索、知识图谱 | 复杂检索需求 |
5.3 代码实战:FAISS向量检索(这段是ai写的,等博主来验证一下)
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
# 创建向量索引
def build_vector_store(chunks, embeddings):
"""
构建FAISS向量索引
"""
vector_store = FAISS.from_documents(
documents=chunks,
embedding=embeddings
)
# 保存到本地
vector_store.save_local("faiss_index")
return vector_store
# 加载已有索引
def load_vector_store(embeddings):
"""
加载本地FAISS索引
"""
vector_store = FAISS.load_local(
"faiss_index",
embeddings,
allow_dangerous_deserialization=True
)
return vector_store
# 使用示例
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vector_store = build_vector_store(chunks, embeddings)
# 检索测试
query = "公司的报销流程是什么?"
results = vector_store.similarity_search(query, k=3)
for i, doc in enumerate(results):
print(f"\n--- 结果{i+1} ---")
print(f"内容:{doc.page_content[:200]}...")
print(f"来源:{doc.metadata.get('source', 'unknown')}")
5.4 Milvus生产级部署
from langchain_community.vectorstores import Milvus
from pymilvus import connections, utility
# 连接Milvus
connections.connect("default", host="localhost", port="19530")
# 创建向量存储
def build_milvus_store(chunks, embeddings, collection_name="rag_docs"):
"""
构建Milvus向量索引
- 支持分布式部署
- 支持数据持久化
- 支持高并发查询
"""
vector_store = Milvus.from_documents(
documents=chunks,
embedding=embeddings,
collection_name=collection_name,
connection_args={
"host": "localhost",
"port": "19530"
}
)
return vector_store
# 混合检索(向量+关键词)
def hybrid_search(vector_store, query, top_k=5):
"""
混合检索:向量相似度 + BM25
"""
# 向量检索
vector_results = vector_store.similarity_search(query, k=top_k*2)
# 关键词检索(需额外实现)
# keyword_results = bm25_search(query, k=top_k)
# 合并去重(具体实现略)
final_results = vector_results
return final_results[:top_k]
6. 关键步骤三:检索策略优化(大家知道切分后存在库里面的是一段向量,还有原来的那段语句或者词汇,可能还有图片,并不是只有向量)(检索策略还有几种方式,比如先优化查找提示词,当然也有些会在一个chunk里面也放进去几段问句方便匹配…)
6.1 相似度计算方法
向量相似度计算是检索的核心,主流方法包括:
余弦相似度(Cosine Similarity)
similarity = A ⋅ B ∥ A ∥ ∥ B ∥ = ∑ i = 1 n A i B i ∑ i = 1 n A i 2 ∑ i = 1 n B i 2 \text{similarity} = \frac{A \cdot B}{\|A\| \|B\|} = \frac{\sum_{i=1}^{n} A_i B_i}{\sqrt{\sum_{i=1}^{n} A_i^2} \sqrt{\sum_{i=1}^{n} B_i^2}} similarity=∥A∥∥B∥A⋅B=∑i=1nAi2∑i=1nBi2∑i=1nAiBi
特点:关注向量方向,对大小不敏感,适合文本语义相似度
取值范围:[-1, 1],值越大越相似
欧氏距离(Euclidean Distance)
distance = ∑ i = 1 n ( A i − B i ) 2 \text{distance} = \sqrt{\sum_{i=1}^{n} (A_i - B_i)^2} distance=i=1∑n(Ai−Bi)2
特点:关注向量绝对位置,适合物理距离计算
取值范围:[0, +∞),值越小越相似
点积(Dot Product)
similarity = A ⋅ B = ∑ i = 1 n A i B i \text{similarity} = A \cdot B = \sum_{i=1}^{n} A_i B_i similarity=A⋅B=i=1∑nAiBi
特点:计算简单,同时考虑方向和大小
取值范围:(-∞, +∞),值越大越相似
import numpy as np
def cosine_similarity(vec_a, vec_b):
"""余弦相似度"""
return np.dot(vec_a, vec_b) / (np.linalg.norm(vec_a) * np.linalg.norm(vec_b))
def euclidean_distance(vec_a, vec_b):
"""欧氏距离"""
return np.linalg.norm(vec_a - vec_b)
def dot_product(vec_a, vec_b):
"""点积"""
return np.dot(vec_a, vec_b)
6.2 混合检索策略(混合了以上的向量法和精确匹配等几种方法,个人觉得匹配应该关心正确率也就是召回率,因为模型会自己判断信息,会自己排除错误信息)混合检索 = 多路召回 + 融合策略
单一检索方式存在局限,混合检索结合多种方法优势:
# 注意:需要安装依赖
# pip install rank-bm25 jieba
from rank_bm25 import BM25Okapi
import jieba
class HybridRetriever:
"""
混合检索器:向量检索 + BM25关键词检索
"""
def __init__(self, vector_store, documents, alpha=0.5):
"""
Args:
vector_store: 向量数据库
documents: 原始文档列表
alpha: 向量检索权重(0-1),BM25权重为1-alpha
"""
self.vector_store = vector_store
self.alpha = alpha
# 构建BM25索引
tokenized_docs = [list(jieba.cut(doc.page_content)) for doc in documents]
self.bm25 = BM25Okapi(tokenized_docs)
self.documents = documents
def retrieve(self, query, top_k=5):
"""
混合检索
"""
# 向量检索
vector_results = self.vector_store.similarity_search_with_score(query, k=top_k*2)
vector_scores = {doc.metadata['chunk_id']: score for doc, score in vector_results}
# BM25检索
tokenized_query = list(jieba.cut(query))
bm25_scores = self.bm25.get_scores(tokenized_query)
# 归一化分数
vector_scores_norm = self._normalize_scores(vector_scores)
bm25_scores_norm = self._normalize_scores({i: s for i, s in enumerate(bm25_scores)})
# 加权融合
final_scores = {}
for chunk_id in vector_scores_norm:
final_scores[chunk_id] = (
self.alpha * vector_scores_norm.get(chunk_id, 0) +
(1 - self.alpha) * bm25_scores_norm.get(chunk_id, 0)
)
# 返回Top-K结果
sorted_ids = sorted(final_scores.keys(), key=lambda x: final_scores[x], reverse=True)
return [self.documents[i] for i in sorted_ids[:top_k]]
def _normalize_scores(self, scores):
"""归一化分数到0-1"""
if not scores:
return {}
max_score = max(scores.values())
min_score = min(scores.values())
if max_score == min_score:
return {k: 1.0 for k in scores}
return {k: (v - min_score) / (max_score - min_score) for k, v in scores.items()}
6.3 重排序技术(rerank!就是使用cross-encoder大模型进行提高精度,关注huggingface的测评)

初检索返回大量候选后,使用重排序模型提升精度:
# 注意:需要安装依赖
# pip install sentence-transformers
from sentence_transformers import CrossEncoder
class Reranker:
"""
使用Cross-Encoder重排序
- 更精确的相似度计算
- 考虑Query和Document的交互
"""
def __init__(self, model_name="BAAI/bge-reranker-base"):
self.model = CrossEncoder(model_name)
def rerank(self, query, documents, top_k=5):
"""
重排序
"""
# 构造query-doc对
pairs = [[query, doc.page_content] for doc in documents]
# 计算重排序分数
scores = self.model.predict(pairs)
# 按分数排序
scored_docs = list(zip(documents, scores))
scored_docs.sort(key=lambda x: x[1], reverse=True)
return [doc for doc, score in scored_docs[:top_k]]
# 使用示例
reranker = Reranker()
initial_results = vector_store.similarity_search(query, k=20)
reranked_results = reranker.rerank(query, initial_results, top_k=5)
6.4 多路召回实现(同时用 N 种不同的检索策略,把候选文档 “从四面八方捞回来”,最后合并去重 → 送给重排序精筛。)
class MultiChannelRetriever:
"""
多路召回系统
- 向量召回
- BM25召回
- 知识图谱召回(可选)
"""
def __init__(self, vector_store, documents):
self.vector_store = vector_store
self.documents = documents
self.hybrid_retriever = HybridRetriever(vector_store, documents)
def retrieve(self, query, top_k=10):
"""
多路召回并融合
"""
# 第一路:向量召回
vector_results = self.vector_store.similarity_search(query, k=top_k*2)
# 第二路:混合召回
hybrid_results = self.hybrid_retriever.retrieve(query, k=top_k*2)
# 第三路:精确匹配(可选)
exact_results = self._exact_match(query)
# 融合策略(RRF - Reciprocal Rank Fusion)
final_results = self._rrf_merge(
[vector_results, hybrid_results, exact_results],
k=60
)
return final_results[:top_k]
def _exact_match(self, query):
"""精确关键词匹配"""
results = []
# 注意:实际应用中文需使用jieba分词,这里仅演示逻辑
keywords = query.split()
for doc in self.documents:
if all(kw in doc.page_content for kw in keywords):
results.append(doc)
return results
def _rrf_merge(self, result_lists, k=60):
"""RRF融合"""
scores = {}
for results in result_lists:
for rank, doc in enumerate(results):
chunk_id = doc.metadata.get('chunk_id')
if chunk_id not in scores:
scores[chunk_id] = 0
scores[chunk_id] += 1 / (k + rank)
# 按分数排序
sorted_ids = sorted(scores.keys(), key=lambda x: scores[x], reverse=True)
return [self.documents[i] for i in sorted_ids]
7. 关键步骤四:上下文增强与生成
7.1 Prompt工程技巧
Prompt设计直接影响生成质量,关键原则:
原则一:角色定位明确
你是一个专业的企业知识助手,擅长基于提供的文档准确回答用户问题。
如果文档中没有相关信息,请明确告知用户,不要编造答案。
原则二:提供充足上下文
以下是相关的参考文档:
{context}
请基于以上文档回答问题:{question}
原则三:引导输出格式
请按以下格式回答:
1. 直接答案:[简洁回答]
2. 详细说明:[展开解释]
3. 参考来源:[引用具体文档]
7.2 Prompt模板设计
from langchain.prompts import PromptTemplate
# 基础RAG模板
basic_template = """
你是一个专业的AI助手,请基于以下参考文档回答用户问题。
【参考文档】
{context}
【用户问题】
{question}
【回答要求】
1. 答案必须基于参考文档,不要编造信息
2. 如果文档中没有相关信息,请明确说明
3. 引用来源时标注文档编号
请开始回答:
"""
# 高级RAG模板(支持多轮对话)
advanced_template = """
你是一个专业的企业知识助手。
【对话历史】
{chat_history}
【相关文档】
{context}
【当前问题】
{question}
【回答指南】
- 综合对话历史和文档信息回答
- 保持回答的一致性和连贯性
- 必要时澄清歧义问题
- 引用具体文档来源
请回答:
"""
# 创建Prompt模板
prompt = PromptTemplate(
template=advanced_template,
input_variables=["chat_history", "context", "question"]
)
7.3 上下文窗口管理
LLM存在上下文窗口限制,需要智能管理:
class ContextManager:
"""
上下文窗口管理器
- 动态调整文档数量
- 截断过长文档
- 优先保留高分文档
"""
def __init__(self, max_tokens=4000, tokenizer=None):
self.max_tokens = max_tokens
self.tokenizer = tokenizer or self._default_tokenizer
def build_context(self, query, documents, prompt_template):
"""
构建符合窗口限制的上下文
"""
# 基础Prompt占用的token
base_prompt = prompt_template.format(
context="", question=query, chat_history=""
)
used_tokens = len(self.tokenizer(base_prompt))
# 逐个添加文档
context_parts = []
for i, doc in enumerate(documents):
doc_text = f"\n【文档{i+1}】\n{doc.page_content}\n"
doc_tokens = len(self.tokenizer(doc_text))
# 检查是否超出限制
if used_tokens + doc_tokens > self.max_tokens - 500: # 预留500给回答
break
context_parts.append(doc_text)
used_tokens += doc_tokens
return "".join(context_parts)
def _default_tokenizer(self, text):
"""简单分词器(实际应用使用tiktoken)"""
return list(text) # 中文按字符,英文按空格更好
# 使用示例
context_manager = ContextManager(max_tokens=4000)
context = context_manager.build_context(query, reranked_results, advanced_template)
7.4 完整生成流程
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
def build_rag_chain(vector_store, prompt_template):
"""
构建完整的RAG生成链
"""
llm = ChatOpenAI(
model="gpt-4-turbo-preview",
temperature=0.1,
streaming=True
)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vector_store.as_retriever(search_kwargs={"k": 5}),
return_source_documents=True,
chain_type_kwargs={"prompt": prompt_template}
)
return qa_chain
# 高级RAG系统
class AdvancedRAGSystem:
def __init__(self, vector_store, documents):
self.vector_store = vector_store
self.documents = documents
self.retriever = MultiChannelRetriever(vector_store, documents)
self.reranker = Reranker()
self.context_manager = ContextManager()
self.llm = ChatOpenAI(model="gpt-4-turbo-preview")
def answer(self, query, chat_history=None):
"""
完整的RAG回答流程
"""
# 1. 多路召回
candidates = self.retriever.retrieve(query, top_k=20)
# 2. 重排序
top_docs = self.reranker.rerank(query, candidates, top_k=5)
# 3. 构建上下文
context = self.context_manager.build_context(
query, top_docs, advanced_template
)
# 4. 生成答案
prompt = advanced_template.format(
context=context,
question=query,
chat_history=chat_history or ""
)
response = self.llm.invoke(prompt)
return {
"answer": response.content,
"sources": [
{
"content": doc.page_content[:200],
"source": doc.metadata.get("source", "unknown")
}
for doc in top_docs
]
}
8. 高级优化技术
8.1 Query改写与扩展
用户原始问题可能表达不清,需要优化:
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
class QueryRewriter:
"""
Query改写器
- 扩展关键词
- 补充背景信息
- 生成多版本查询
"""
def __init__(self):
self.llm = ChatOpenAI(model="gpt-4", temperature=0)
def rewrite(self, query, chat_history=None):
"""
改写查询,提升检索效果
"""
prompt = f"""
用户提出了一个问题:"{query}"
对话历史:{chat_history or "无"}
请从以下角度优化这个问题:
1. 补充缺失的背景信息
2. 提取核心关键词
3. 生成2-3个不同表述的等价问题
以JSON格式输出:
{{
"optimized_query": "优化后的问题",
"keywords": ["关键词1", "关键词2"],
"alternative_queries": ["等价问题1", "等价问题2"]
}}
"""
response = self.llm.invoke(prompt)
return eval(response.content)
def multi_query_retrieve(self, vector_store, query, top_k=5):
"""
多查询检索,提高召回率
"""
rewritten = self.rewrite(query)
all_queries = [rewritten["optimized_query"]] + rewritten["alternative_queries"]
all_results = []
for q in all_queries:
results = vector_store.similarity_search(q, k=top_k)
all_results.extend(results)
# 去重
unique_results = {doc.metadata['chunk_id']: doc for doc in all_results}
return list(unique_results.values())[:top_k*2]
8.2 知识图谱增强
结合结构化知识图谱,提升推理能力:
class KnowledgeGraphRAG:
"""
知识图谱增强的RAG
- 实体识别
- 关系推理
- 子图检索
"""
def __init__(self, vector_store, neo4j_uri=None):
self.vector_store = vector_store
self.neo4j_driver = self._connect_neo4j(neo4j_uri) if neo4j_uri else None
def retrieve_with_graph(self, query, top_k=5):
"""
向量检索 + 知识图谱推理
"""
# 1. 向量检索
vector_results = self.vector_store.similarity_search(query, k=top_k)
# 2. 实体识别
entities = self._extract_entities(query)
# 3. 知识图谱查询
graph_facts = []
if self.neo4j_driver:
for entity in entities:
facts = self._query_graph(entity)
graph_facts.extend(facts)
# 4. 融合
enhanced_context = self._merge_context(vector_results, graph_facts)
return enhanced_context
def _extract_entities(self, text):
"""实体识别(示例)"""
# 实际应用使用NER模型
import jieba.posseg as pseg
words = pseg.cut(text)
return [word for word, flag in words if flag in ['nr', 'ns', 'nt']]
def _query_graph(self, entity):
"""查询知识图谱"""
# Cypher查询示例
query = """
MATCH (n {name: $entity})-[r]->(m)
RETURN n.name, type(r), m.name
"""
# 实际实现需连接Neo4j
return []
def _merge_context(self, vector_results, graph_facts):
"""融合向量检索和图谱事实"""
context = "\n【相关文档】\n"
for doc in vector_results:
context += f"{doc.page_content}\n"
if graph_facts:
context += "\n【相关知识】\n"
for fact in graph_facts:
context += f"{fact}\n"
return context
8.3 多轮对话管理
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
class MultiTurnRAG:
"""
多轮对话RAG系统
- 维护对话历史
- 上下文理解
- 问题消歧
"""
def __init__(self, vector_store, llm):
self.vector_store = vector_store
self.llm = llm
self.memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
def chat(self, query):
"""
多轮对话
"""
qa = ConversationalRetrievalChain.from_llm(
llm=self.llm,
retriever=self.vector_store.as_retriever(),
memory=self.memory,
return_source_documents=True,
verbose=True
)
result = qa.invoke({"question": query})
return {
"answer": result["answer"],
"chat_history": result["chat_history"],
"sources": result["source_documents"]
}
# 使用示例
rag = MultiTurnRAG(vector_store, llm)
# 多轮对话
response1 = rag.chat("公司有哪些福利?")
response2 = rag.chat("年假有几天?") # 理解为"公司的年假有几天"
response3 = rag.chat("怎么申请?") # 理解为"怎么申请年假"
9. RAG评估指标与方法
9.1 基础指标详解
召回率(Recall)
定义:在所有真正相关的文档中,检索系统成功返回的比例。
计算公式:
Recall = 检索到的相关文档数 所有相关文档总数 = T P T P + F N \text{Recall} = \frac{\text{检索到的相关文档数}}{\text{所有相关文档总数}} = \frac{TP}{TP + FN} Recall=所有相关文档总数检索到的相关文档数=TP+FNTP
其中:
- TP(True Positive):检索到且相关的文档数
- FN(False Negative):相关但未检索到的文档数
实际意义:召回率衡量系统的查全能力。高召回率意味着系统能尽可能找到所有相关信息,避免遗漏重要内容。
示例:
假设知识库中有20篇关于"报销流程"的文档,检索系统返回了15篇,其中12篇是真正相关的。
- 检索到的相关文档数(TP)= 12
- 相关但未检索到的文档数(FN)= 20 - 12 = 8
- Recall = 12 / 20 = 60%
应用场景:
- 法律合规查询:需要找到所有相关法规,不能遗漏
- 医疗文献检索:确保找到所有相关病例
- 企业知识库:尽可能覆盖所有相关信息
精确率(Precision)
定义:在检索返回的所有文档中,真正相关的比例。
计算公式:
Precision = 检索到的相关文档数 检索返回的文档总数 = T P T P + F P \text{Precision} = \frac{\text{检索到的相关文档数}}{\text{检索返回的文档总数}} = \frac{TP}{TP + FP} Precision=检索返回的文档总数检索到的相关文档数=TP+FPTP
其中:
- FP(False Positive):检索到但不相关的文档数
实际意义:精确率衡量系统的查准能力。高精确率意味着返回的文档大多相关,减少用户筛选噪音的成本。
示例:
检索系统返回了15篇文档,其中12篇是真正相关的。
- 检索到的相关文档数(TP)= 12
- 检索到但不相关的文档数(FP)= 15 - 12 = 3
- Precision = 12 / 15 = 80%
用这个图来记住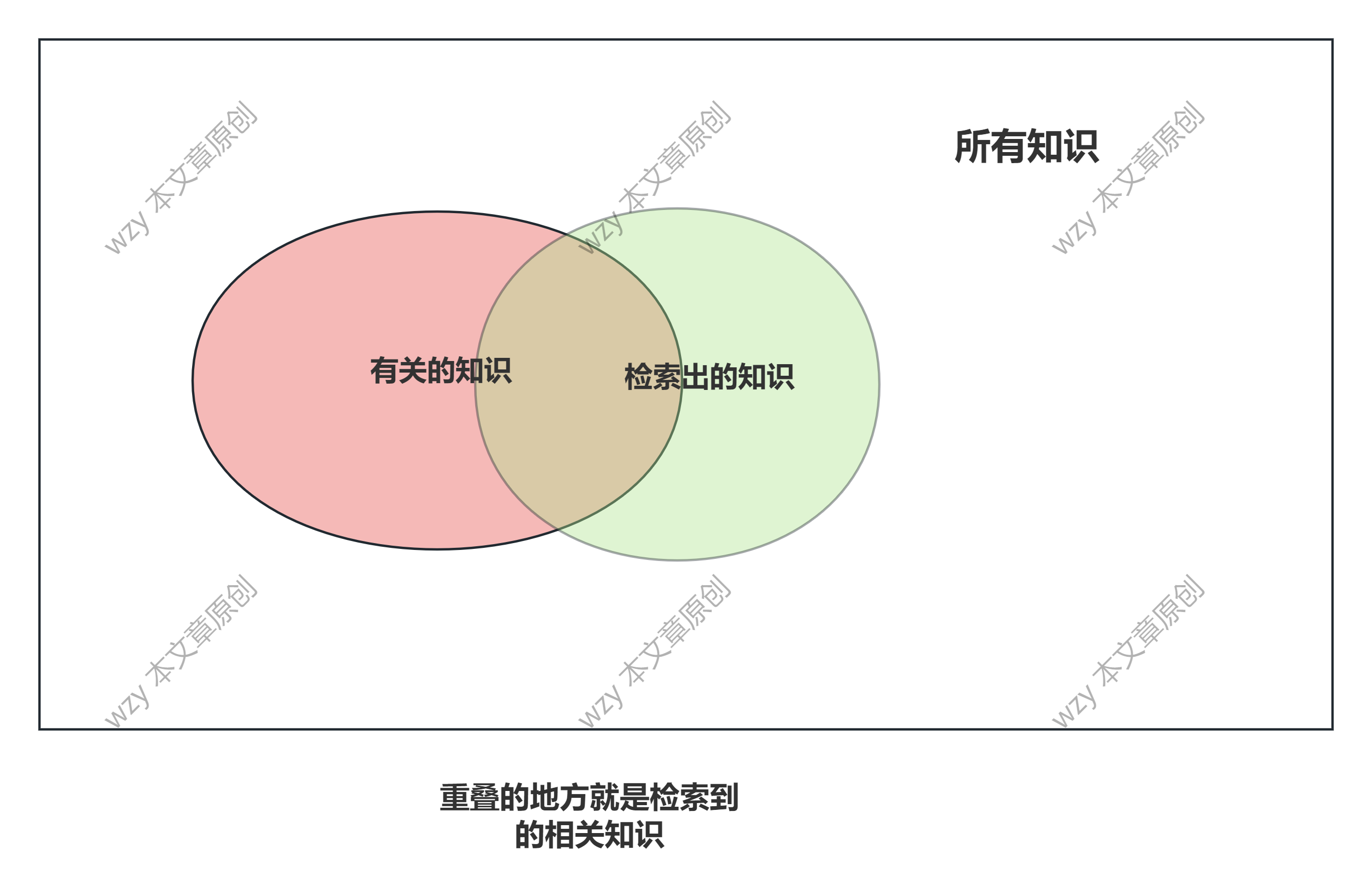
召回率是重叠/白色框框,精确率是重叠/绿色框框
其实增大绿色区域可以完全让正确率达到100%,但是准确率非常低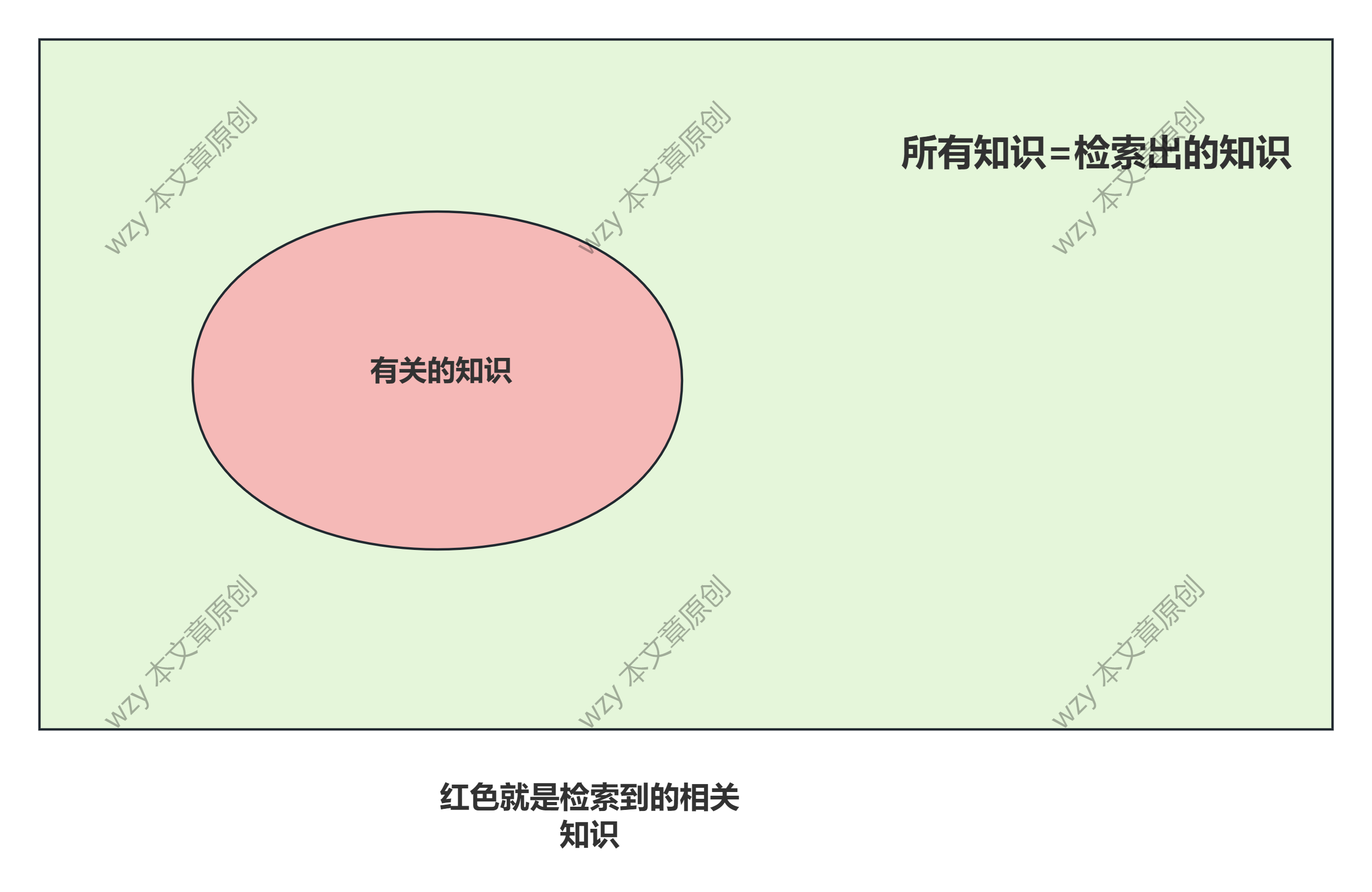
召回率与精确率的权衡
两者往往存在权衡关系:
| 策略 | 召回率 | 精确率 | 适用场景 |
|---|---|---|---|
| 返回更多文档(k值大) | 高 | 低 | 宁可多查不能漏 |
| 返回更少文档(k值小) | 低 | 高 | 精准优先 |
| 平衡策略 | 中等 | 中等 | 通用场景 |
权衡建议:
- 高召回率优先:法律、医疗、合规等不能遗漏的场景,k值设为10-20
- 高精确率优先:用户快速查询、移动端展示,k值设为3-5
- 平衡策略:企业知识库通用场景,k值设为5-10,同时使用重排序提升精确率
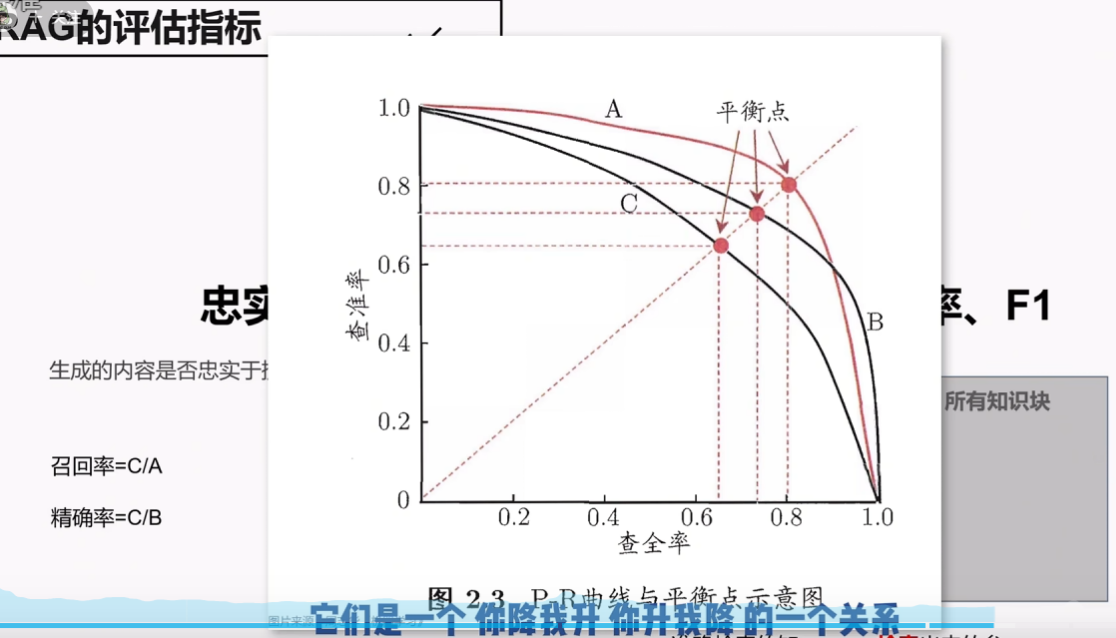
F1分数
定义:召回率和精确率的调和平均数,综合评价指标。
计算公式:
F 1 = 2 × Precision × Recall Precision + Recall F1 = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} F1=2×Precision+RecallPrecision×Recall
特点:
- 取值范围0-1,值越大越好
- 对两者都有要求,避免某一指标极低
示例:
Precision = 80% = 0.8
Recall = 60% = 0.6
F 1 = 2 × 0.8 × 0.6 0.8 + 0.6 = 2 × 0.48 1.4 = 0.686 F1 = 2 \times \frac{0.8 \times 0.6}{0.8 + 0.6} = 2 \times \frac{0.48}{1.4} = 0.686 F1=2×0.8+0.60.8×0.6=2×1.40.48=0.686
平均倒数排名(MRR, Mean Reciprocal Rank)
定义:第一个相关文档在检索结果中的排名的倒数,取平均值。
计算公式:
MRR = 1 Q ∑ i = 1 Q 1 rank i \text{MRR} = \frac{1}{Q} \sum_{i=1}^{Q} \frac{1}{\text{rank}_i} MRR=Q1i=1∑Qranki1
其中:
- Q:查询总数
- rank_i:第i个查询中第一个相关文档的排名
实际意义:衡量第一个正确答案的位置。MRR=1表示第一个结果总是相关的,MRR=0.5表示第一个相关答案平均排在第2位。
示例:
| 查询 | 第一个相关文档排名 | 倒数 |
|---|---|---|
| Q1 | 1 | 1/1 = 1.0 |
| Q2 | 3 | 1/3 = 0.33 |
| Q3 | 2 | 1/2 = 0.5 |
| Q4 | 1 | 1/1 = 1.0 |
MRR = ( 1.0 + 0.33 + 0.5 + 1.0 ) / 4 = 0.708 \text{MRR} = (1.0 + 0.33 + 0.5 + 1.0) / 4 = 0.708 MRR=(1.0+0.33+0.5+1.0)/4=0.708
应用场景:问答系统、搜索建议等场景,用户期望第一个结果就是答案。
归一化折损累计增益(NDCG)
定义:考虑文档相关性和位置的综合指标,位置越靠前权重越高。
计算步骤:
- 计算DCG(Discounted Cumulative Gain):
DCG p = ∑ i = 1 p 2 rel i − 1 log 2 ( i + 1 ) \text{DCG}_p = \sum_{i=1}^{p} \frac{2^{\text{rel}_i} - 1}{\log_2(i+1)} DCGp=i=1∑plog2(i+1)2reli−1
其中rel_i是第i个文档的相关性得分(如:高度相关=2,相关=1,不相关=0)
-
计算IDCG(理想情况下的DCG):按相关性降序排列计算
-
计算NDCG:
NDCG = DCG IDCG \text{NDCG} = \frac{\text{DCG}}{\text{IDCG}} NDCG=IDCGDCG
实际意义:同时考虑文档相关性和排序质量。NDCG=1表示排序完美,相关文档都在前面。
示例:
假设检索返回5个文档,相关性得分为[2, 1, 0, 1, 0]
DCG = 2 2 − 1 log 2 ( 2 ) + 2 1 − 1 log 2 ( 3 ) + 2 0 − 1 log 2 ( 4 ) + 2 1 − 1 log 2 ( 5 ) + 2 0 − 1 log 2 ( 6 ) \text{DCG} = \frac{2^2-1}{\log_2(2)} + \frac{2^1-1}{\log_2(3)} + \frac{2^0-1}{\log_2(4)} + \frac{2^1-1}{\log_2(5)} + \frac{2^0-1}{\log_2(6)} DCG=log2(2)22−1+log2(3)21−1+log2(4)20−1+log2(5)21−1+log2(6)20−1
理想排序应为[2, 1, 1, 0, 0],计算IDCG,最后NDCG = DCG / IDCG。
9.2 检索质量评估方法
def evaluate_retrieval(retriever, test_queries, ground_truth, k_values=[5, 10, 20]):
"""
检索质量评估
Args:
retriever: 检索器
test_queries: 测试查询列表
ground_truth: 每个查询的相关文档ID列表
k_values: 评估的k值列表
Returns:
评估结果字典
"""
results = {k: {"recall": [], "precision": [], "f1": []} for k in k_values}
for query, relevant_ids in zip(test_queries, ground_truth):
retrieved_docs = retriever.retrieve(query, top_k=max(k_values))
retrieved_ids = [doc.metadata['chunk_id'] for doc in retrieved_docs]
for k in k_values:
top_k_ids = retrieved_ids[:k]
# 计算指标
tp = len(set(top_k_ids) & set(relevant_ids))
fp = len(set(top_k_ids) - set(relevant_ids))
fn = len(set(relevant_ids) - set(top_k_ids))
recall = tp / (tp + fn) if (tp + fn) > 0 else 0
precision = tp / (tp + fp) if (tp + fp) > 0 else 0
f1 = 2 * precision * recall / (precision + recall) if (precision + recall) > 0 else 0
results[k]["recall"].append(recall)
results[k]["precision"].append(precision)
results[k]["f1"].append(f1)
# 计算平均值
for k in k_values:
results[k]["recall"] = np.mean(results[k]["recall"])
results[k]["precision"] = np.mean(results[k]["precision"])
results[k]["f1"] = np.mean(results[k]["f1"])
return results
# 使用示例
test_queries = [
"公司的报销流程是什么?",
"如何申请年假?",
"员工手册在哪里下载?"
]
ground_truth = [
["chunk_1", "chunk_5", "chunk_12"],
["chunk_3", "chunk_8"],
["chunk_20", "chunk_21"]
]
eval_results = evaluate_retrieval(retriever, test_queries, ground_truth)
for k, metrics in eval_results.items():
print(f"Top-{k}: Recall={metrics['recall']:.2%}, Precision={metrics['precision']:.2%}, F1={metrics['f1']:.2%}")
9.3 RAGAS框架详解
RAGAS(Retrieval Augmented Generation Assessment)是专门为RAG系统设计的评估框架,包含以下核心指标:
| 指标 | 评估维度 | 计算方式 | 取值范围 |
|---|---|---|---|
| Context Precision | 检索精度 | 检索文档的相关性 | 0-1,越高越好 |
| Context Recall | 检索召回 | 是否覆盖答案所需信息 | 0-1,越高越好 |
| Faithfulness | 答案忠实度 | 答案是否基于上下文 | 0-1,越高越好 |
| Answer Relevance | 答案相关性 | 答案是否回答问题 | 0-1,越高越好 |
# 注意:需要安装依赖
# pip install ragas datasets
from ragas import evaluate
from ragas.metrics import (
context_precision,
context_recall,
faithfulness,
answer_relevance
)
from datasets import Dataset
def evaluate_with_ragas(qa_pairs, vector_store):
"""
使用RAGAS框架评估RAG系统
Args:
qa_pairs: 问题-答案对列表
vector_store: 向量数据库
Returns:
RAGAS评估结果
"""
# 构建评估数据集
eval_data = {
"question": [],
"answer": [],
"contexts": [],
"ground_truth": []
}
for qa in qa_pairs:
# 检索上下文
retrieved_docs = vector_store.similarity_search(qa["question"], k=5)
eval_data["question"].append(qa["question"])
eval_data["answer"].append(qa["answer"])
eval_data["contexts"].append([doc.page_content for doc in retrieved_docs])
eval_data["ground_truth"].append(qa.get("ground_truth", ""))
dataset = Dataset.from_dict(eval_data)
# 运行评估
result = evaluate(
dataset,
metrics=[
context_precision,
context_recall,
faithfulness,
answer_relevance
]
)
return result
# 使用示例
qa_pairs = [
{
"question": "公司的报销流程是什么?",
"answer": "报销流程包括:1. 提交申请,2. 部门审批,3. 财务审核,4. 款项发放",
"ground_truth": "报销需先填写申请单,经部门主管审批后提交财务部"
}
]
ragas_result = evaluate_with_ragas(qa_pairs, vector_store)
print(ragas_result)
9.4 端到端评估指标
除了检索和生成单独评估,还需要端到端评估:
class EndToEndEvaluator:
"""
端到端RAG评估
- 答案准确性
- 响应时间
- 用户满意度
"""
def __init__(self, rag_system, test_dataset):
self.rag_system = rag_system
self.test_dataset = test_dataset
def evaluate(self):
"""
综合评估
"""
results = {
"accuracy": [],
"latency": [],
"hallucination_rate": []
}
for sample in self.test_dataset:
import time
start_time = time.time()
# 获取答案
response = self.rag_system.answer(sample["question"])
latency = time.time() - start_time
# 准确性评估(使用LLM-as-judge)
accuracy = self._evaluate_accuracy(
sample["question"],
response["answer"],
sample["reference_answer"]
)
# 幻觉检测
hallucination = self._detect_hallucination(
response["answer"],
response["sources"]
)
results["accuracy"].append(accuracy)
results["latency"].append(latency)
results["hallucination_rate"].append(hallucination)
return {
"avg_accuracy": np.mean(results["accuracy"]),
"avg_latency": np.mean(results["latency"]),
"avg_hallucination_rate": np.mean(results["hallucination_rate"])
}
def _evaluate_accuracy(self, question, answer, reference):
"""使用LLM评估答案准确性"""
judge_prompt = f"""
问题:{question}
学生答案:{answer}
标准答案:{reference}
请评估学生答案的准确性(0-10分):
- 10分:完全正确
- 7-9分:基本正确,细节略有出入
- 4-6分:部分正确
- 0-3分:错误或无关
只输出分数(数字):
"""
judge_llm = ChatOpenAI(model="gpt-4", temperature=0)
score = judge_llm.invoke(judge_prompt).content
return int(score) / 10
def _detect_hallucination(self, answer, sources):
"""检测答案是否包含幻觉内容"""
source_text = "\n".join([s["content"] for s in sources])
hallucination_prompt = f"""
基于以下参考文档,判断答案是否包含幻觉(编造的信息):
参考文档:{source_text}
答案:{answer}
输出:YES(有幻觉)或 NO(无幻觉)
"""
judge_llm = ChatOpenAI(model="gpt-4", temperature=0)
result = judge_llm.invoke(hallucination_prompt).content
return 1 if "YES" in result else 0
10. 生产环境实践与踩坑
10.1 性能优化策略
优化一:向量检索加速
# 使用IVF索引加速(适用于百万级数据)
index_ivf = faiss.index_factory(dimension, "IVF100,Flat")
index_ivf.train(vectors)
index_ivf.add(vectors)
# 使用HNSW索引(适用于高精度要求)
index_hnsw = faiss.index_factory(dimension, "HNSW32")
优化二:缓存机制
from functools import lru_cache
import hashlib
class QueryCache:
"""
查询缓存,避免重复计算
"""
def __init__(self, max_size=1000):
self.cache = {}
self.max_size = max_size
def get(self, query):
query_hash = hashlib.md5(query.encode()).hexdigest()
return self.cache.get(query_hash)
def set(self, query, result):
if len(self.cache) >= self.max_size:
# LRU清理
oldest_key = next(iter(self.cache))
del self.cache[oldest_key]
query_hash = hashlib.md5(query.encode()).hexdigest()
self.cache[query_hash] = result
10.2 常见问题与解决方案
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 检索结果不相关 | Embedding模型不匹配 | 使用领域微调的Embedding模型 |
| 答案幻觉严重 | Prompt设计不当 | 强化"必须基于上下文回答"指令 |
| 响应速度慢 | 向量数据库未优化 | 使用FAISS IVF索引、增加缓存 |
| 长文档检索失败 | Chunk切分不合理 | 采用语义切分、增加重叠度 |
| 多轮对话理解差 | 未维护对话历史 | 集成ConversationBufferMemory |
10.3 监控与运维
import logging
from datetime import datetime
class RAGMonitor:
"""
RAG系统监控
"""
def __init__(self):
self.logger = logging.getLogger("RAG")
self.logger.setLevel(logging.INFO)
def log_query(self, query, latency, num_results, user_feedback=None):
"""记录查询日志"""
log_entry = {
"timestamp": datetime.now().isoformat(),
"query": query,
"latency": latency,
"num_results": num_results,
"user_feedback": user_feedback
}
self.logger.info(log_entry)
def log_error(self, error_type, error_msg):
"""记录错误日志"""
self.logger.error(f"{error_type}: {error_msg}")
def get_statistics(self):
"""获取统计信息"""
# 实现统计逻辑
pass
11. 总结与展望
11.1 核心要点回顾
本文系统性地介绍了RAG技术的完整链路:
- 基础架构:索引、检索、增强、生成四大阶段
- 关键技术:文档切分、向量化、混合检索、重排序
- 优化策略:Query改写、知识图谱增强、多轮对话
- 评估体系:召回率、精确率、RAGAS框架、端到端评估
11.2 RAG技术趋势
- 多模态RAG:支持图像、表格、音频检索
- 自适应检索:根据问题难度动态调整检索策略
- 增量更新:实时更新知识库,无需重建索引
- 个性化RAG:结合用户画像优化检索结果
11.3 拓展学习资源
- 论文:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- 框架:LangChain、LlamaIndex、RAGAS
- 开源项目:quivr、private-gpt
系列预告
本文是RAG系列的第一篇,后续将推出:
后续依旧出一篇rag搭建
敬请关注!
本文首发于 CSDN,作者:KingWu

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)