一套可视化流程,带你看懂OCR如何识别文字(一)
很多人每天都在用 OCR,比如截图翻译、文档扫描、发票识别,但如果你问一句:
OCR 到底是怎么把图片里的文字“读取出来”的?
大多数人的印象可能只有一句话:“就是用AI识别一下。”
但如果你真的把这个过程拆解开来看,会发现它远没有那么“黑盒”。一张图片变成一段文字,中间其实经历了很多步骤,每一步都各司其职。
这篇文章,我不打算从模型原理讲起,而是换一种更直观的方式——用一套可视化流程,把OCR的每一步都“摊开”给你看。
你可以把它理解成一条流水线:图片从左边进来,文字从右边出来,而中间发生的每一步,我们都能看见。如下图: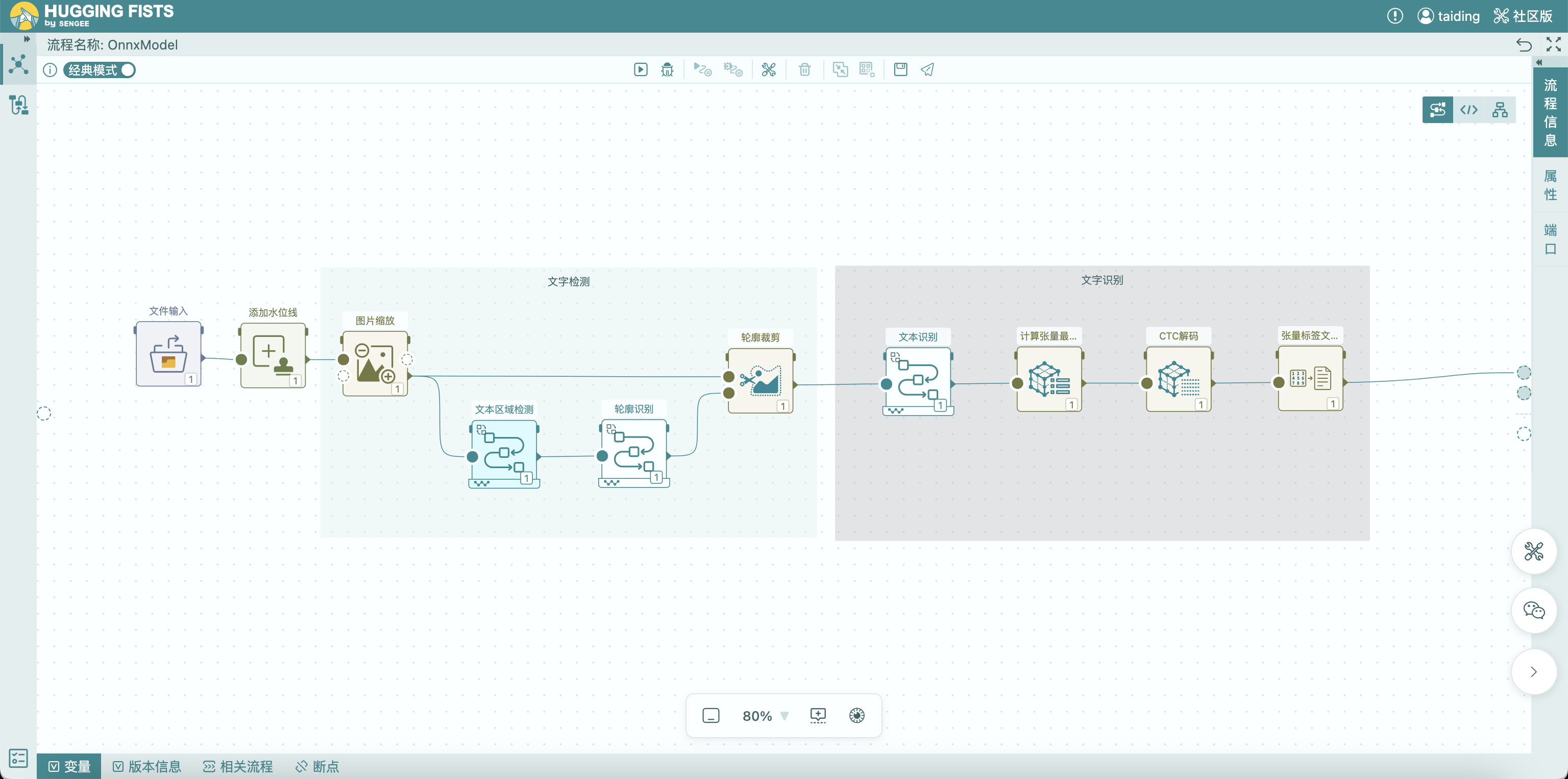
OCR在做的,其实是两件事
在拆解具体流程之前,可以先有个整体认知:OCR并不是“一步到位”识别文字,而是分成了两件完全不同的事情:
-
先找到哪里有文字(检测)
-
再判断这些文字是什么(识别)
你可以把它想象成:
先在一张图里“圈出文字的位置”,再逐块去“读内容”。
这也是为什么,大多数OCR系统其实不是一个模型,而是两个模型配合完成。接下来,我们先看第一步:它是怎么“找到文字”的。
第一步:模型先给你一张“哪里像文字”的图
当一张图片进入OCR流程后,并不会直接输出“文字框”。模型做的第一件事,其实有点“间接”——它会生成一张概率图(也可以理解为热力图)。这张图的含义是:
-
越亮的地方 → 越可能是文字
-
越暗的地方 → 越可能是背景
如果你把这张图展示出来,看起来会有点像这样:
一片灰黑背景上,文字区域是亮的“块状区域”
这一步其实对应的是常见的文本检测模型(比如DBNet这一类)。它并不是直接画框,而是先告诉你:
“这里,大概率是文字。”
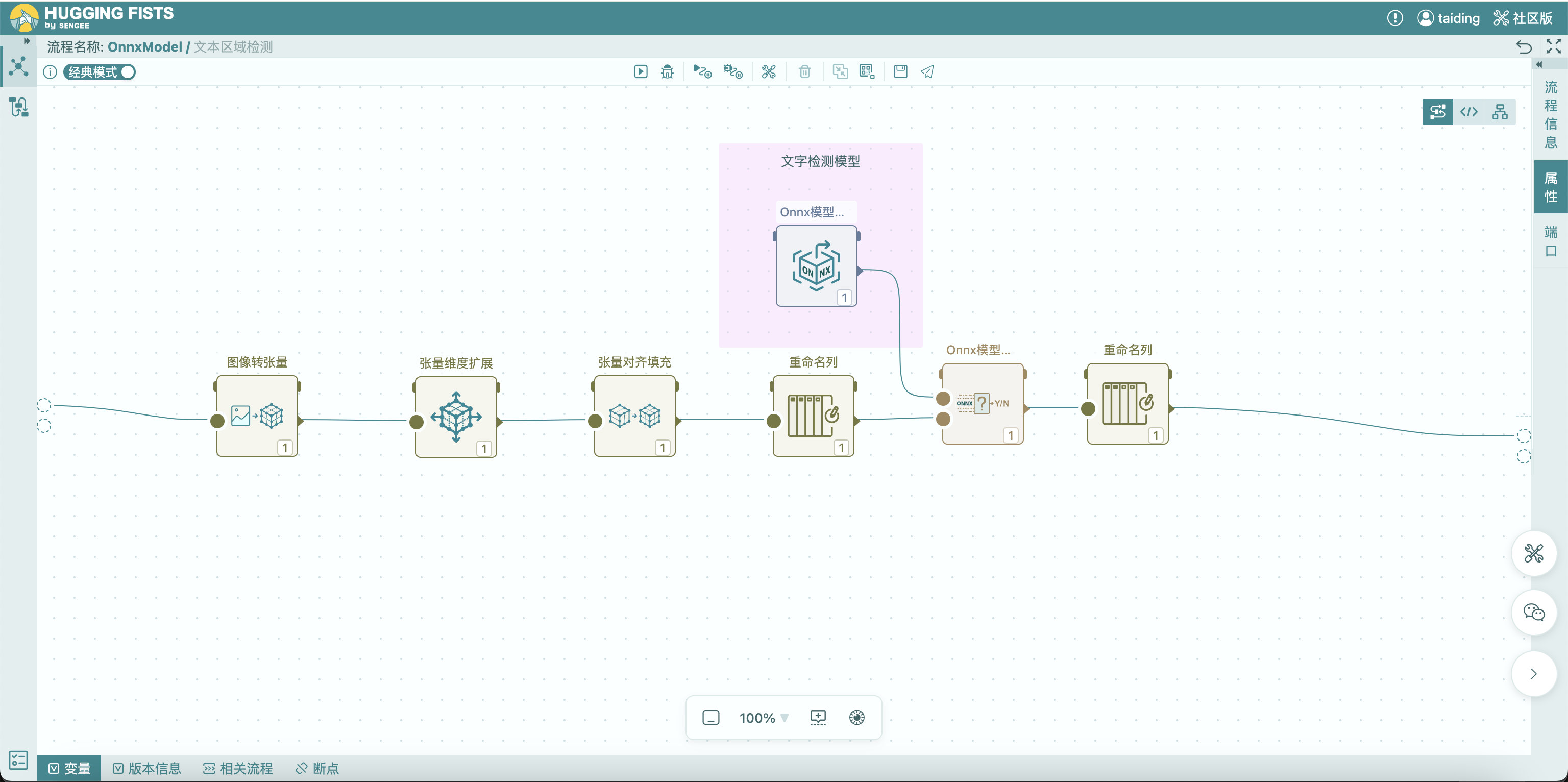
如流程所示,图片首先被转换为张量的形式。然后需要对张量进行必要的布局调整和维度扩展。这些必要的前置处理工作主要取决于文本检测模型可接受的张量式。比如:模型接受NCHW布局的图像张量,如果输入的数据为HWC布局张量,则需要对张量进行必要的布局调整和维度扩展。
第二步:把“概率图”变成真正的文字区域
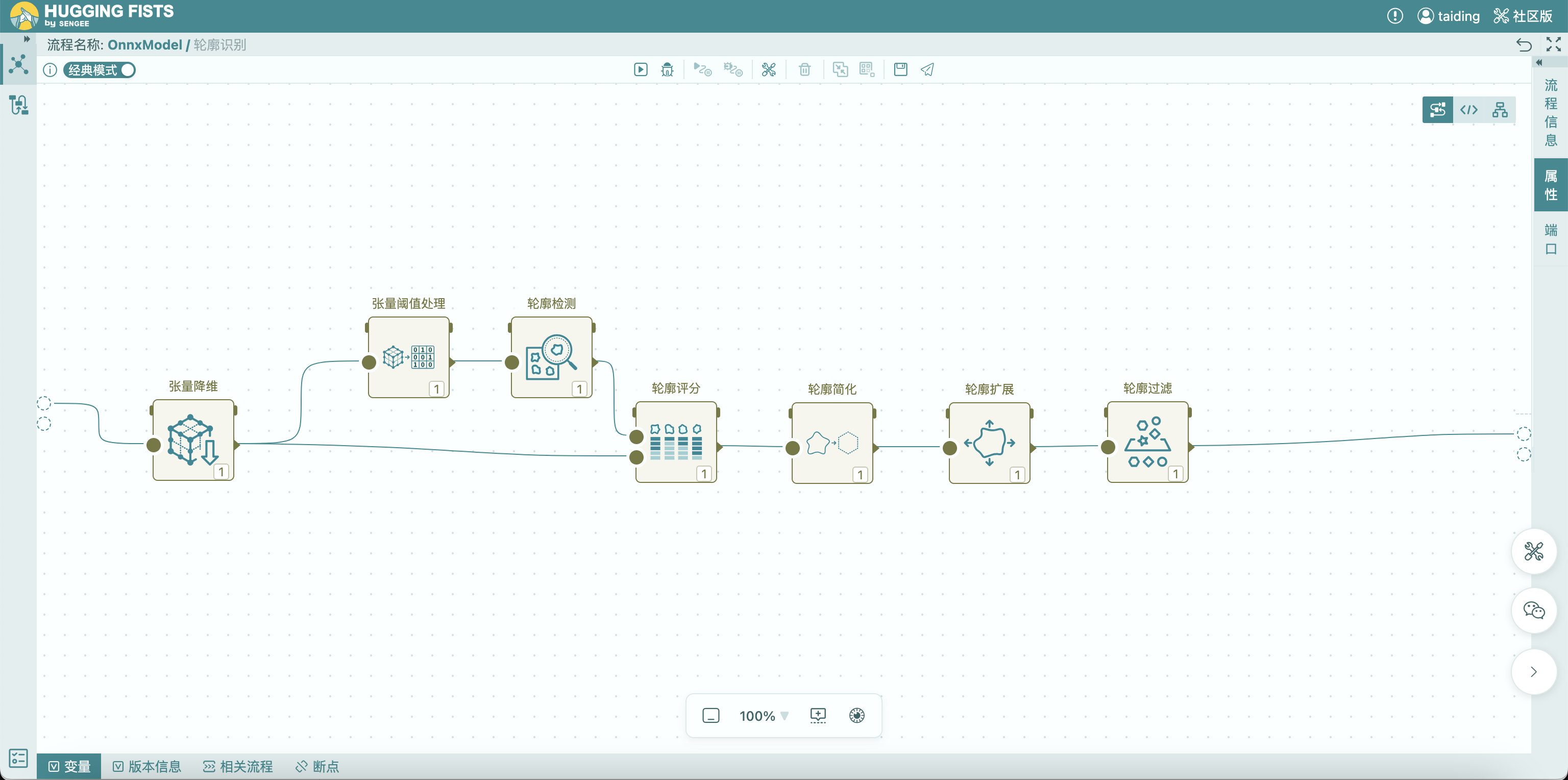
有了这张“哪里像文字”的图,还不够。因为它只是一个连续的概率分布,我们还需要把它变成明确的区域。这个过程在流程里被拆成了几步:
1. 阈值处理:从“模糊”变成“黑白分明”
首先,会对概率图做一个简单但关键的操作:设一个阈值(比如 0.1)
-
高于阈值 → 当成“文字”
-
低于阈值 → 当成“背景”
这一步之后,整张图就从“灰度图”变成了黑白图。可以理解为:
把“可能是文字”的区域,直接“抠出来”。
2. 轮廓检测:把区域变成一个个“块”
接下来,会在这张黑白图上做一件很经典的事情:找轮廓(Contours)
简单说就是:
-
把连在一起的白色区域,识别成一个个独立的“块”
每一个块,都可以理解为:
一个“可能包含文字的区域”
3. 打分 + 过滤:去掉不靠谱的区域
不是所有检测出来的区域都靠谱,比如:
-
太小的噪点
-
形状奇怪的区域
-
置信度很低的部分
所以流程里会做几件事:
-
根据原始概率图,对每个区域打分
-
过滤掉低于阈值的区域
-
限制最小尺寸,避免噪声
这一步的目的很明确:
只保留“看起来真的像文字”的区域
4. 轮廓简化 + 扩展:让框更“像文本框”
检测出来的轮廓,一开始可能是比较不规则的形状。所以通常会再做两步优化:
-
简化轮廓 → 转成规则的四边形(更像文本框)
-
适当扩展(unclip) → 避免框太紧,把文字裁掉一部分
处理之后,每个区域基本就变成了:
一个比较规整、刚好包住文字的矩形框
(注:以上的步骤3,4可以根据实际需要调整前后关系)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)