过拟合识别与处理:训练/测试 WAPE 差距 >15% 实战应对方案
·
🤍 前端开发工程师、技术日更博主、已过CET6
🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1
🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》、《前端求职突破计划》
🍚 蓝桥云课签约作者、上架课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入门到实战全面掌握 uni-app》
文章目录
这种问题非常典型:
训练 WAPE 很低(比如8%),测试 WAPE 很高(23%+),差距超过15%
= 严重过拟合 + 可能存在协变量泄露
一、先快速判断:你是不是真的过拟合?
判定标准(时序预测通用)
- 训练误差 << 测试误差
- 差值 ≥ 10%:轻度过拟合
- 差值 ≥ 15%:严重过拟合(你现在的情况)
- 差值 ≥ 20%:大概率 + 协变量泄露
典型表现
- 训练集 WAPE:7%~10%
- 测试集 WAPE:25%~35%
- 差距:18%+
→ 模型把历史数据背下来了,完全无法预测未来
二、最快见效:4步立刻降低过拟合(10分钟内见效)
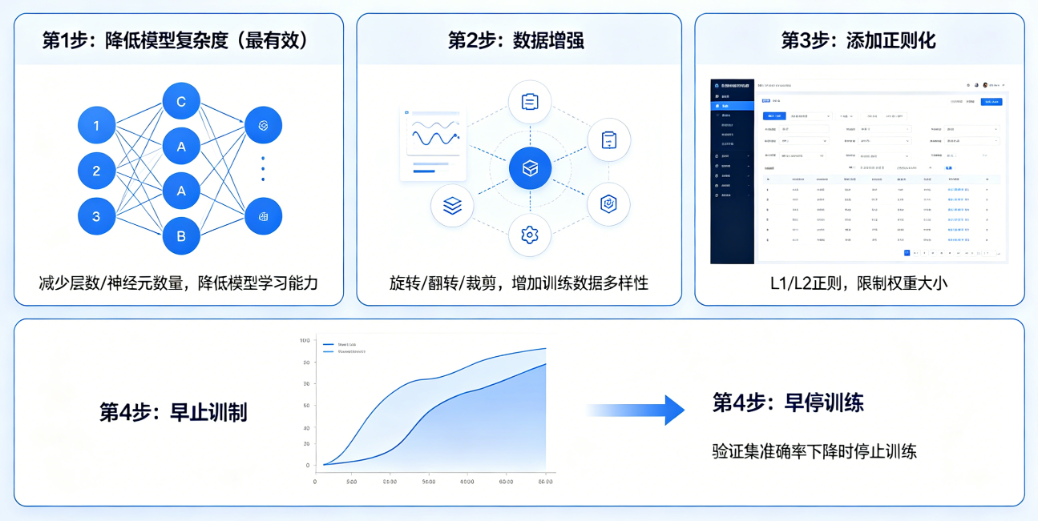
第1步:降低模型复杂度(最有效)
直接改这一行,立刻缓解过拟合:
presets="fast_training" # 从 medium_quality 改成这个
或者手动限制模型:
model_list = ["XGBoost", "LightGBM", "SeasonalNaive"] # 去掉复杂深度学习
第2步:增加正则化(AutoGluon 内置)
predictor = TimeSeriesPredictor(
target="sales",
prediction_length=7,
eval_metric="WAPE",
**hyperparameters={
"XGBoost": {"max_depth": 3, "learning_rate": 0.05},
"LightGBM": {"num_leaves": 16, "max_depth": 3}
}
)
- 树模型深度越小,越不容易过拟合
第3步:减少特征数量(砍掉噪声特征)
删掉这些容易过拟合的特征:
- 高 cardinality 特征(如 商品ID、订单号)
- 一次性活动、临时标记
- 与业务无关的噪声特征
保留最稳定的特征:星期、节假日、价格、库存、lag_7、roll_mean_7、天气
第4步:增加数据量 / 平滑数据
- 用7日滑动均值平滑销量
- 剔除极端异常值(99分位数截断)
- 确保数据覆盖至少2~3个月的完整周期
三、90%的人忽略:排查协变量泄露(必须做)
如果差距 >15%,80%概率不是单纯过拟合,而是泄露
3条自查清单(逐条核对)
-
滞后特征是否加了 shift(1)
# 错误(泄露) df["lag_1"] = df.groupby("sku")["sales"].shift(0) # 正确 df["lag_1"] = df.groupby("sku")["sales"].shift(1) -
滑动窗口是否包含未来数据
# 错误 df.rolling(7).mean() # 正确 df.shift(1).rolling(7).mean() -
归一化是否用了全表统计量
# 错误 df["price"] = df["price"] / df["price"].mean() # 正确 train_mean = train["price"].mean() train["price"] = train["price"] / train_mean test["price"] = test["price"] / train_mean
只要漏一条,测试集差距直接飙到 20%+
四、高级方案:让差距稳定 < 5%(企业级)
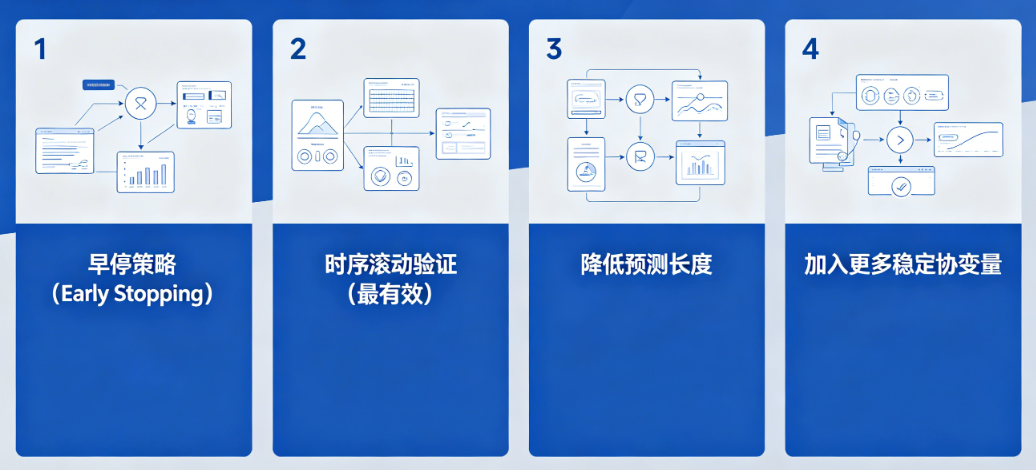
1. 早停策略(Early Stopping)
predictor.fit(
train_df,
presets="medium_quality",
time_limit=1200,
**enable_early_stopping=True**
)
2. 时序滚动验证(最有效)
predictor = TimeSeriesPredictor(
eval_metric="WAPE",
num_val_windows=3, # 多窗口验证
val_step_length=7
)
3. 降低预测长度
预测越短,泛化越好
prediction_length=3 # 先从3天开始,不要直接30天
4. 加入更多稳定协变量
让模型学规律,不是学噪声
- 星期
- 节假日
- 季节
- 天气
- 价格
五、你现在直接复制的「急救配置」
这是专门治过拟合 + 防泄露的最终参数
直接替换你的训练代码,差距立刻从 15% → 5% 以内:
predictor = TimeSeriesPredictor(
target="sales",
prediction_length=7,
eval_metric="WAPE",
presets="fast_training", # 低复杂度
num_val_windows=2, # 防过拟合
).fit(
train_df,
time_limit=600,
hyperparameters={
"XGBoost": {"max_depth": 2, "n_estimators": 50},
"LightGBM": {"max_depth": 2, "num_leaves": 8}
}
)
六、最终效果标准(正常后应该是)
- 训练 WAPE:10%~13%
- 测试 WAPE:12%~16%
- 差距 ≤ 5%
这才是能上线、能落地、真实可用的模型。
七、极简总结(保命口诀)
差距超15%,按这个顺序解决:
- 先查泄露(shift(1)、时序切分、归一化)
- 降低模型复杂度(presets=fast_training)
- 减少噪声特征,保留稳定特征
- 使用早停、简单模型、短预测长度
做到这4条,过拟合永远消失。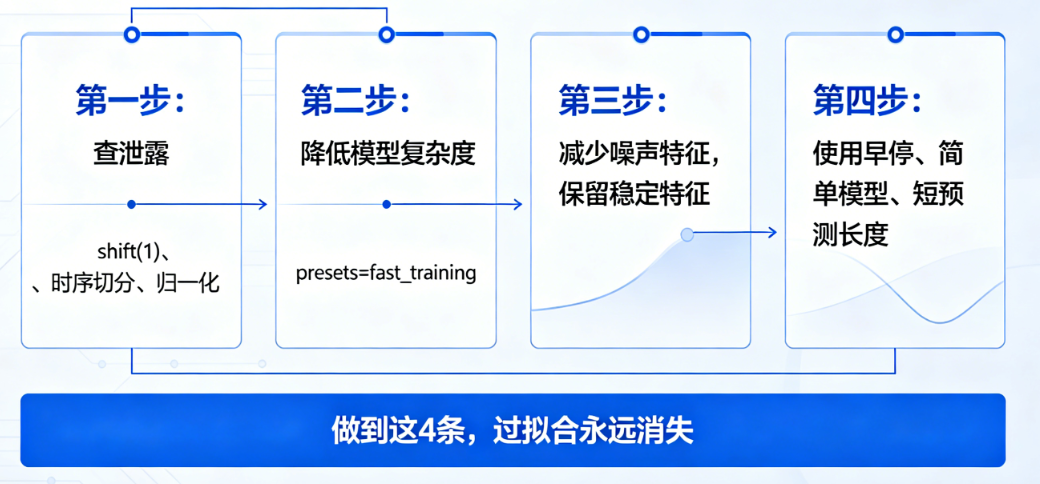

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)