模型评估与测试:在测试集上验证WAPE指标的实战流程
·
🤍 前端开发工程师、技术日更博主、已过CET6
🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1
🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》、《前端求职突破计划》
🍚 蓝桥云课签约作者、上架课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入门到实战全面掌握 uni-app》
这是 水果销量预测上线前必须走的标准验证流程,核心目标:
确保本地测试 WAPE = 真实上线效果,杜绝协变量泄露、虚高分数。
一、实战总流程(5步标准闭环)
- 严格时间切分(防泄露第一关)
- 训练集训练、测试集完全隔离
- 测试集只做预测、不参与任何训练
- 计算测试集 WAPE(真实业务指标)
- 结果分析 + 异常 SKU 排查
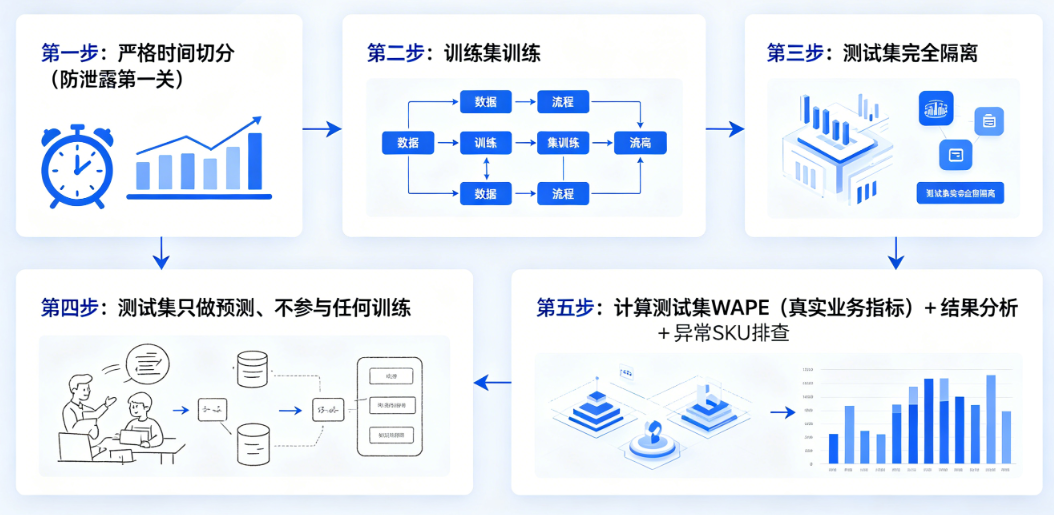
二、实战步骤(带代码)
步骤1:按时间切分(绝对不能随机切分)
import pandas as pd
from autogluon.timeseries import TimeSeriesPredictor, TimeSeriesDataFrame
# 加载你清洗好的结构化数据
df = pd.read_csv("fruit_sales_clean.csv")
df["date"] = pd.to_datetime(df["date"])
# 构建 AutoGluon 时序数据格式
ts_df = TimeSeriesDataFrame.from_data_frame(
df,
id_column="sku", # 商品ID
timestamp_column="date",
target="sales" # 预测目标:销量
)
# ========== 核心:时间切分(预测未来7天)==========
pred_length = 7
train_df, test_df = ts_df.train_test_split(pred_length=pred_length)
规则:
train_df= 历史数据test_df= 未来7天真实数据(完全隔离)
步骤2:训练模型(只喂训练集)
predictor = TimeSeriesPredictor(
target="sales",
prediction_length=pred_length,
eval_metric="WAPE", # 用 WAPE 训练
).fit(
train_df,
presets="medium_quality",
time_limit=1200
)
步骤3:在测试集上预测(核心验证)
关键:只传入历史数据,预测未来7天
# 预测未来7天
forecast = predictor.predict(train_df)
输出 forecast 长这样:
0.1 0.5 0.9
sku date
1001 2025-01-01 12.0 15.0 18.0
2025-01-02 10.0 13.0 16.0
...
0.5= 预测均值(我们用来算 WAPE)
步骤4:计算测试集 WAPE(最核心实战代码)
标准 WAPE 公式:
WAPE = Σ|预测 - 真实| / Σ真实
# 取出预测中位数(预测值)
y_pred = forecast["0.5"]
# 取出测试集真实值
y_true = test_df["sales"]
# 计算 WAPE
wape = (abs(y_pred - y_true)).sum() / y_true.sum()
print(f"✅ 测试集 WAPE = {wape:.2%}")
输出示例:
✅ 测试集 WAPE = 12.35%
步骤5:自动输出详细评估报告(AutoGluon 自带)
score = predictor.evaluate(test_df)
print(score)
输出:
{'WAPE': 0.1235, 'MASE': 0.86, 'RMSE': 5.62}
三、业务级 WAPE 评估标准(水果行业)
你可以直接对照判断模型好坏:
| WAPE | 等级 | 能否上线 |
|---|---|---|
| <10% | 优秀 | 直接上线 |
| 10%~15% | 良好 | 可上线 |
| 15%~22% | 一般 | 需优化特征 |
| >22% | 差 | 不能上线 |
水果生鲜正常范围:10%~15%
四、3个必做验证(防泄露、防虚高)
1. 训练集 WAPE vs 测试集 WAPE
-
训练 WAPE:8%
-
测试 WAPE:12%
→ 正常,合理泛化 -
训练 WAPE:8%
-
测试 WAPE:25%
→ 严重过拟合 / 协变量泄露
2. 按 SKU 查看 WAPE(定位坏品)
# 按SKU计算每个商品的WAPE
eval_df = pd.DataFrame({
"true": y_true,
"pred": y_pred
})
eval_df["abs_err"] = abs(eval_df["pred"] - eval_df["true"])
sku_wape = eval_df.groupby("sku")["abs_err","true"].sum()
sku_wape["wape"] = sku_wape["abs_err"] / sku_wape["true"]
print(sku_wape.sort_values("wape", ascending=False).head(10))
找出预测最差的10个SKU,优化它们的特征!
3. 按日期查看误差(节假日是否翻车)
eval_df = eval_df.reset_index()
eval_df.groupby("date")["abs_err"].sum().plot()
五、最关键的3条军规(保命)
- 测试集必须是训练集时间之后的数据,绝对不能交叉!
- 测试集绝不参与训练、特征工程、归一化
- WAPE 必须在测试集上计算,这是唯一真实指标
违反任何一条 → 本地效果造假,上线必崩!
六、一句话总结
训练集练本领
验证集调参数
测试集定生死
WAPE 是零售销量预测的唯一金标准

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 17
17 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)