卡尔曼滤波原理与工程实践
卡尔曼滤波是非常经典的预测追踪算法,能够在系统存在噪声干扰的情况下进行系统状态的最优估计,广泛使用在导航、制导、控制相关的领域。
1. 一个简单的场景
假设我们开发了一台无人机(假设它的名字是Eva),想要用它来在城市中送快递,Eva身上有一些传感器。
可以让我们知道它的速度v(比如三维空间中沿x, y, z各轴的速度大小),同时Eva身上还有GPS系统、气压计等设备,可以获知它的位置p(比如经纬度,海拔等),也就是说我们可以实时观测Eva的状态。
那么我们可以把Eva的某一个时刻的状态表示为一个向量:
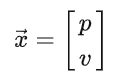
不确定性和相关性
虽然我们比较肯定Eva此时的状态,但是无论如何系统总是会存在误差的,无论是计算上,还是传感器的检测上,所以我们只能认为当前状态是当前真实状态的一个最优估计。
那么我们不妨认为Eva的当前状态服从一个高斯分布,如下图所示:
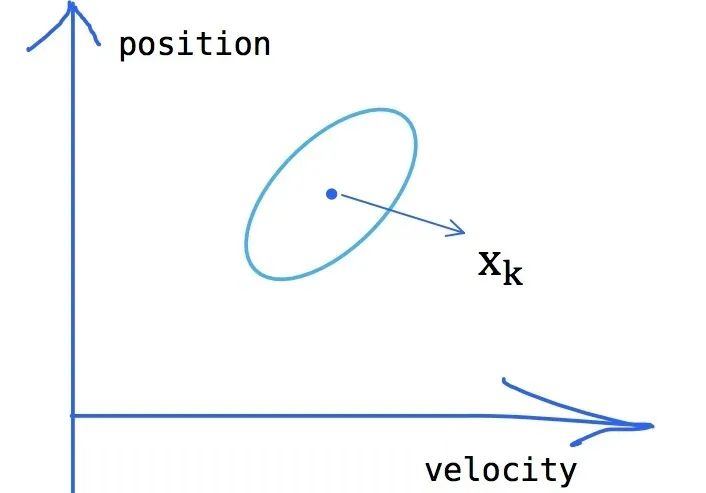
高斯分布的中心 就是图中的
对于方差 (也就是图中的椭圆的范围),因为我们有两个变量,所以可以用一个协方差矩阵
来表示(如果对协方差矩阵还不了解,戳此了解):
所以Eva的真实状态可能就位于上图椭圆的范围内,位于圆心的概率最大。
2. 预测下一个位置的系统状态和系统误差
Ok,接下来我们需要通过Eva当前的状态,运用一些物理学的知识来预测它的下一个状态,通过简单的物理学知识,通过k-1时刻的位置和速度,可以推测下一个时刻的状态为:
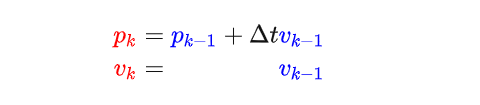
写成矩阵形式就是:
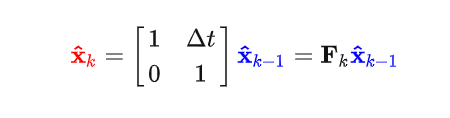
此处的Fk就是状态转移矩阵。Eva的系统误差通过协方差矩阵来表示,根据协方差矩阵的性质:
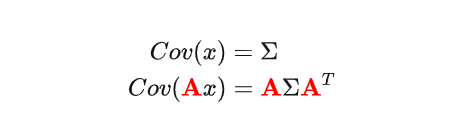
那么我们所预测的Eva下一个时刻的状态误差为:
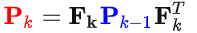
3. 考虑系统内部控制
为了能让Eva到达任何地方,毫无疑问我们需要对它进行控制,比如加速和减速,假设某个时刻我们施加给Eva的加速度是a,那么下一时刻的位置和速度则应该为:
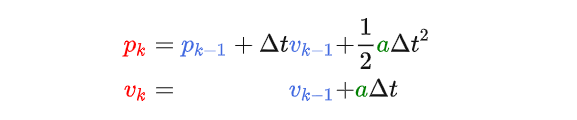
因此我们的状态预测方程更新为:
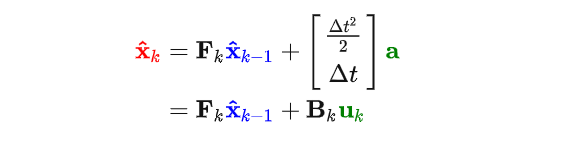
Ok,新方程中的Bk我们称为状态控制矩阵,而uk称为状态控制向量,含义很明显,前者表明的是加速减速如何改变Eva的状态,而后者则表明控制的力度大小和方向。
4. 考虑系统外部影响
但是,外界可能有很多影响因素,导致我们对Eva实施控制的时候并不总是如我们所愿,有时候会逆风,有时候则是顺风。
在此我们猜测外部的不确定因素对Eva造成的系统状态误差服从均值为0高斯分布
,至此我们就能得到Kalman滤波中完整的状态预测方程:
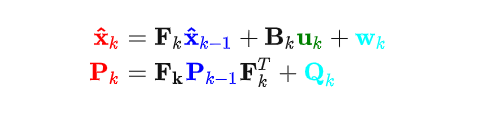
因为为0,所以有的文章可能会忽略不写,但是如果明确知道均值不为零的是时候,就需要注意了,这要看实际应用时候的场景,理解了它的原理,就能对各部分的变化有深入体会。
5. 此时应该观测到什么?
前面我们通过Eva的上一个状态,对它的当前状态做了缜密的预测,此时我们要考虑我们事先安装在Eva身上的各种传感器应该能够观测到什么?
Eva当前的状态和我们观测到的传感器数据应该具备特定的关系,假设这个关系通过矩阵表示为,如下图所示:
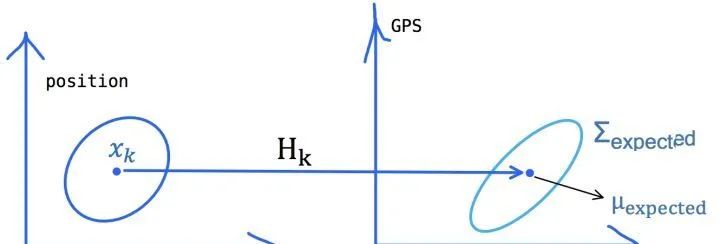
在此前对Eva所做的预测状态下,我们应该观测到传感器的观测值为:
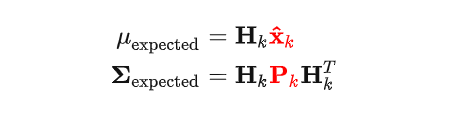
因此我们就完成了对观测值的预测,预测其结果服从如下高斯分布:

6. 考虑实际观测的结果
好的,我们不仅推测了Eva当前的状态,还推测了我们应该观测到的传感器数据,但是现实和理想之间必然是存在差距的,我们预测的观测结果和实际的观测结果可能如下图所示:
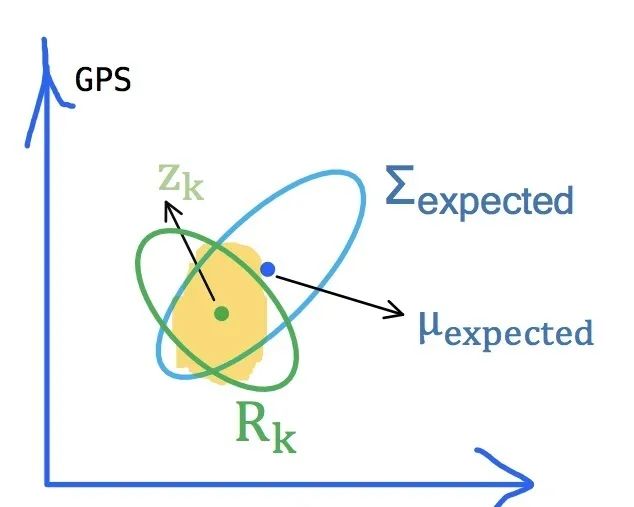
上图中的表示实际观测的结果,但是观测的结果肯定也是不准确的,所以我们认为其观测噪声
是一个均值为0,协方差矩阵为
的高斯分布,即:
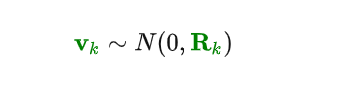
其实也就是说我们对Eva的观测值服从高斯分布,Eva真实的情况应该存在以为椭圆心的椭圆内,即观测结果服从高斯分布:
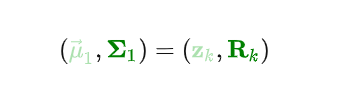
终于来到了最关键的一步:卡尔曼滤波需要做的最重要的最核心的事就是融合预测和观测的结果,充分利用两者的不确定性来得到更加准确的估计。
通俗来说就是怎么从上面的两个椭圆中来得到中间淡黄色部分的高斯分布,看起来这是预测和观测高斯分布的重合部分,也就是概率比较高的部分。
7. 两个高斯概率密度函数的乘积
一维的高斯分布通过高斯概率密度函数来表示,在坐标轴上画出来是一个类似草帽的形状。
下面给出两个高斯概率密度函数相乘的直观的结果。
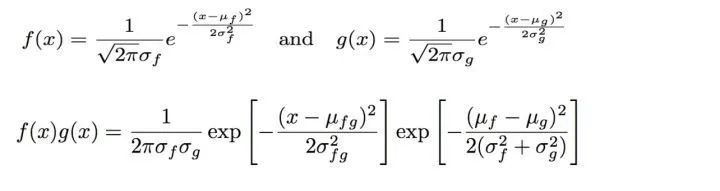
对比标准的高斯概率密度函数,相乘的结果是一个乘了特定系数的新的高斯概率密度函数(这个系数在后面的演示代码中会计算),并且我们可以求解得到这个新的高斯分布的均值和方差分别为:
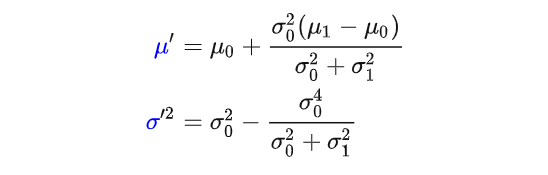
通过MATLAB我们可以计算两个高斯概率密度函数的乘积,以及通过上述公式计算得到的新的高斯概率密度函数,以下是相关的代码和运行截图:
clear all
x=-1:0.01:2.5;
mu0 = 0.3;
mu1 = 0.8;
sigma0 = 0.2;
sigma1 = 0.5;
sigma0_sq = 0.04;
sigma1_sq = 0.25;
y1=normpdf(x,mu0,sigma0);
y2=normpdf(x,mu1,sigma1);
y3=y1.*y2;
k = sigma0_sq / (sigma0_sq + sigma1_sq);
mu = (mu0*sigma1_sq + mu1*sigma0_sq) / (sigma0_sq + sigma1_sq);
sigma = sqrt((sigma0_sq * sigma1_sq) / (sigma0_sq + sigma1_sq));
scale = (1.0 / (sqrt(2*pi*(sigma0_sq + sigma1_sq)))) * exp(-1.0 * ((mu0-mu1)^2/(2.0 * (sigma0_sq + sigma1_sq))));
y4 = normpdf(x,mu,sigma);% * scale;
figure;
plot(x,y1,x,y2,x,y3, x, y4,'MarkerSize',20,'LineWidth',5);
grid;
tip1 = sprintf('(\\mu_0,\\sigma_0) = (%.4f, %.4f)', mu0, sigma0);
tip2 = sprintf('(\\mu_1,\\sigma_1) = (%.4f, %.4f)', mu1, sigma1);
tip3 = '(\mu_0,\sigma_0)*(\mu_1,\sigma_1)';
tip4 = sprintf('(\\mu^\\prime,\\sigma^\\prime) = (%.4f, %.4f)', mu, sigma);
legend({tip1, tip2, tip3, tip4});运行截图:
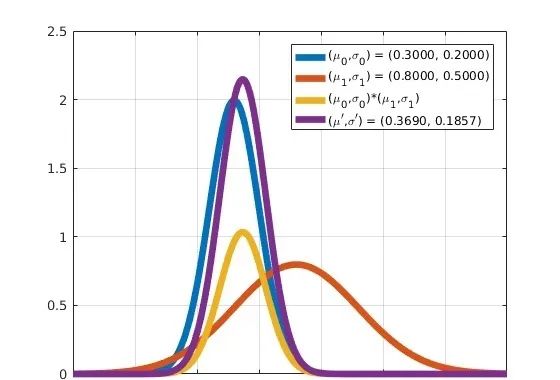
因为MATLAB的函数normpdf使用的参数是均值和标准差,所以代码和截图中也是使用均值和标准差表示一个高斯分布。
图中蓝色和橙色两个波形的直接乘积是黄色这个波形,而它其实可以通过紫色的波形乘上一个系数得到,也就是前面代码中的scale这个变量,计算公式在上面的已经提供。
如果在计算y4(紫色的波形)的时候乘上这个系数,你会发现它的波形就和黄色的波形 (y3) 完全重合了。把对应行稍作修改即可:
y4 = normpdf(x,mu,sigma) * scale;8. 新的高斯分布
那么我们把关注点放在这个乘积中这个新的高斯概率密度函数,其实它就描述了一个新的高斯分布,这正是卡尔曼滤波想要的最优估计。在新的均值和方差计算公式中,我们令:
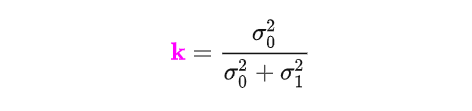
那么可以得到:

将它们写成矩阵形式就是:
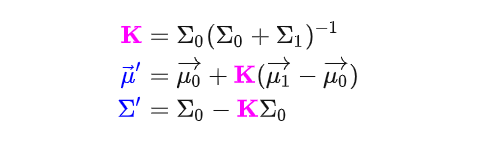
前面我们已经得到了预测结果和观测结果服从的两个高斯分布,如下:
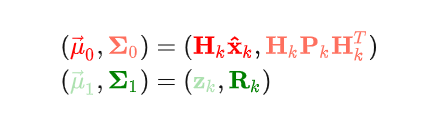
所以我们可以进行如下推导,来得到卡尔曼滤波对当前状态(基于预测和观测的)最优估计的计算方程:
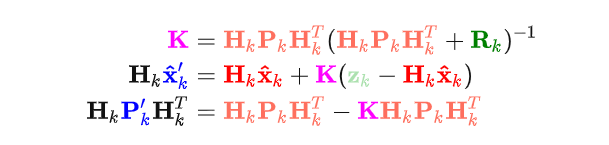
好的,两边化简下,注意K可以展开,于是可以得到:
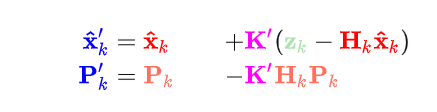
此处的K′就是传说中的卡尔曼增益:
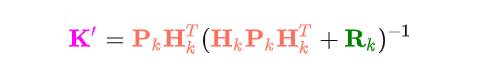
9. 实际实现时的计算步骤
在实际使用卡尔曼滤波的时候,计算的步骤一般为(这里把下标去掉了,因为在实现的时候,即使下标不一样,我们用的其实就是一个变量,注意和前面的方程进行比对):
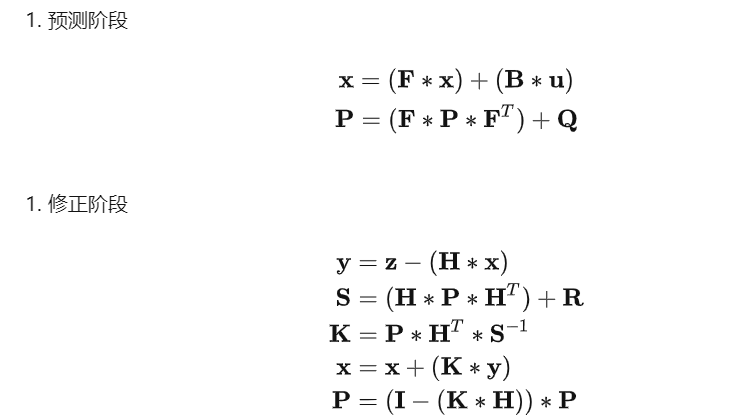
上面的y是测量余量 (measurement residual),S是测量余量协方差矩阵。
最重要的是,我们要时刻关注不断迭代的系统变量,分别是系统的状态:x,其误差协方差矩阵:P,和卡尔曼增益:K。
在实际应用时,对Q和R的选择要依据实际情况来定,可以不断调试来寻找一个最优解,也可以是可变的,只要最终效果能够更好。
10. 实践中的主要难点
10.1. 运动学模型的建立
也就是预测方程。这个一方面可以通过比较细的系统辨识来做,这方面要结合具体的应用背景,不一而足,也是普遍做的比较差的地方。
10.2. 噪声的统计特性
我们得到了2(或多个)个反馈同一件事的信息A和B,但不知道该相信哪个结果,所以简单的,将两个信息相加除以2(加权平均),得到一个结果0.5A+0.5B。但这个方法过于粗暴,不能反映出水平。现在知道了其中一个信息可靠度更好,而另一个可靠度不好,就要更相信好的信息,如,现在给可信度好的B更大的权重,得到0.2A+0.8B,这个结果会好于第一个。但仍然觉得low,因为A与B的参数是根据经验设置的,并不知道是否是最合理的,是否是最优化的。所以高级的,用优化的方法,根据A与B的高斯分布特征,去融合A和B信息,这个就是卡尔曼。
因为建模误差不知道。观测方程到还可以测一下ZRO算一下均值和方差。然后下一步就是大家喜闻乐见的调参的阶段,据说是群魔乱舞花样百出。
参考文献

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)