我在 Hermes Agent 工具里硬塞了一个 GitHub 高赞知识库,结果一周努力全废了:AI 时代「演示泡沫」下的选型陷阱与三层过滤机制
TL;DR:当你看到某个 GitHub 30k+ Stars 的知识库项目写着「5 分钟搭建」时,请保持警惕——它解决的可能是「让开发者 wow 一下」的问题,而非「让运维半夜不被叫醒」的问题。本文基于我在 Hermes Agent 框架中强行引入 Karpathy 的 LLM Wiki 知识库的真实踩坑经历,系统复盘 AI 时代「演示泡沫」(Demo-Driven Bubble)的形成机制,并提出一套可落地的 Agent 工具选型「三层过滤机制」。
一、引子:一个星期的努力,在一夜之间归零
事情的开始很美好。
那天我在 GitHub 上刷到了 Karpathy 的 LLM Wiki 项目——一个围绕大语言模型知识构建的、结构清晰、引用丰富的知识库管理系统。看着 README 里「clone 下来,一条命令启动」(不是clone下来,我是借鉴引入,从0部署的,谢谢知友提醒~。~!)的丝滑体验,以及社区里「太优雅了」「这就是 AI Native 知识库该有的样子」的溢美之词,我心动了。
彼时我正在维护一套基于 Hermes 的 Agent 工具链,负责处理复杂任务的多步骤决策、工具调用和记忆管理。我一直在思考:如果能给 Hermes 引入一个高质量的结构化知识库,岂不是如虎添翼?Karpathy 的 LLM Wiki 看起来就是完美的答案——权威、开源、社区活跃、架构现代。
我花了整整一个星期的时间:
- 阅读源码,理解它的 GraphRAG 架构和分块策略;
- 调整 Embedding 模型配置,试图对齐 Hermes 已有的向量检索链路;
- 修改数据管道,把原本分散在多个目录的文档重新组织成 Wiki 期待的格式;
- 在本地部署了完整的向量数据库、重排序服务、前端界面;
- 用 Obsidian 做了完整的演示流程,向团队展示「未来的知识管理形态」。
然而,当我真正尝试让 Hermes 的 Agent 调用这个知识库去完成实际任务时,一切都崩塌了。
Agent 期望的是结构化的 JSON 返回,Wiki 输出的是自然语言段落;Agent 有自己的记忆压缩策略和上下文管理逻辑,Wiki 强行插入了自己的上下文拼接规则;Agent 使用的是基于 MCP(Model Context Protocol)的工具调用协议,Wiki 却要求通过特定的 GraphQL 接口查询。更致命的是,当三个 Agent 实例并发查询时,知识库的检索延迟从 demo 时的 200ms 飙升到 8 秒,且返回结果中充斥着重复片段和无关引用。
我坐在电脑前,看着任务队列里堆积如山的超时请求,深刻地反省了一整晚。
原来,一个星期的努力,本质上只是在本地搭建了一座「数字废墟」——大而不用,徒耗资源。
那个瞬间我终于理解了:为什么 AI 生态里到处都是「看起来很美」的项目,但真正的生产系统却少得可怜。
二、现象定性:从「框架疲劳」到「Agent 幻觉」
传统软件工程领域曾经历过著名的「JavaScript 疲劳」(JavaScript Fatigue)——每隔三个月就有新的前端框架宣称要「彻底改变开发方式」,而开发者则在无休止的迁移和重构中疲于奔命。如今,AI 时代正在经历一场更隐蔽、更危险的「框架疲劳」升级版,我将其称为 「Agent 幻觉」。
之所以说更危险,是因为它叠加了三层相互强化的幻觉:
2.1 低门槛幻觉:部署 ≠ 投产
一个拥有 30,000 Stars 的 RAG 仓库,README 赫然写着「5 分钟搭建知识库」。无数开发者(包括一周前的我)看到这句话,下意识地认为「部署 = 投产」。
但实际上,5 分钟跑通的只是「把 3 个格式规整的 PDF 塞进向量数据库,然后问一个仓库作者预设好的问题」。这距离一个真正的生产级知识库,还差着十万八千里:
- 规模层:能否支持 10 万级文档的增量索引,而非全量重建?
- 权限层:能否实现文档级别的访问控制,避免敏感信息通过 RAG 泄漏给无权用户?
- 版本层:当源文档更新时,能否精准回溯「哪一段内容在何时被哪个版本引用」,而非简单粗暴地覆盖?
- 并发层:当 5 个 Agent 实例同时查询时,检索延迟是否还能保持在可接受范围?
- 容错层:当 Embedding 服务短暂不可用时,系统是会优雅降级,还是直接崩溃?
这些在 demo 里都被漂亮的流式输出动画和精心设计的示例对话掩盖了。用户看到的只是「输入问题 → 看到答案」的魔法时刻,却看不到魔法背后摇摇欲坠的脚手架。
2.2 黑盒幻觉:合理的输出 ≠ 可靠的系统
AI 工具的「智能」天然带有模糊性。用户看到知识库返回了一段「看起来合理」的答案,就假设它能处理所有边界情况。但知识库的核心痛苦从来不在「能问答」,而在那些 demo 永远不会展示的场景:
- 数据脏读(Dirty Read):当源文档正在更新时,知识库是否可能返回新旧内容混在一起的「弗兰肯斯坦」片段?
- 权限泄漏:用户 A 被禁止访问的文档片段,是否可能通过语义相似度检索,在用户 B 的查询结果中「间接泄露」?
- 上下文污染:当多轮对话中引入了外部工具返回的中间结果,知识库的检索是否会把这些临时上下文当作「永久知识」沉淀下来?
- 幻觉溯源:当大模型基于检索到的片段生成了错误答案时,你能否精确定位「是哪一个 chunk、哪一份源文档」导致了这次幻觉?
在黑盒幻觉的笼罩下,开发者往往把「输出看起来对」等同于「系统设计对」,直到生产环境的告警短信在凌晨三点把他们叫醒。
2.3 生态绑架:一根线 vs 一面承重墙
当你引入一套知识库管理结构(比如某套基于 GraphRAG 的架构)时,它很少以「独立组件」的姿态出现。相反,它往往捆绑了特定的 Embedding 模型、特定的向量数据库、特定的重排序策略、甚至特定的前端组件和部署方式。
而你的 Agent 工具可能已经有自己的记忆管理模块、自己的工具调用协议(如 MCP、ReAct 循环)、自己的观测性体系。两者在抽象层上根本不对齐:
- 你的 Agent 期望工具返回结构化 JSON,方便下游节点做条件分支;知识库返回的是自然语言,需要额外写一层解析适配器。
- 你的 Agent 有特定的记忆压缩策略(比如滑动窗口 + 关键信息提取),但知识库有自己的上下文拼接逻辑(比如固定前缀 + 检索结果 + 系统提示)。
- 你的 Agent 使用标准的 HTTP 工具调用协议,但知识库要求通过 WebSocket 流式返回,或者要求特定的认证中间件。
改动不是「接一根线」,而是「拆一面承重墙」。
三、案例复盘:当我把 Karpathy 的 LLM Wiki 塞进 Hermes
为了把上文的三层幻觉具体化,这里完整复盘我引入 Karpathy LLM Wiki 的全过程。需要强调的是,Karpathy 的项目本身质量极高——问题不在于项目不好,而在于好项目和好集成之间,隔着一条叫做「抽象层对齐」的鸿沟。
3.1 预期:「部署就是跑通」
起初我的想法非常朴素,甚至带着一丝乐观:「这个项目真好,我直接借鉴理念再部署不就行了?」
我按照 README 的指引,顺利地完成了以下步骤:
git clone项目仓库;- 安装依赖,配置环境变量;
- 启动向量数据库(Chroma/Pinecone/Qdrant 任选);
- 导入文档,执行索引;
- 打开前端界面,输入测试问题,看到漂亮的引用标注和流式回答。
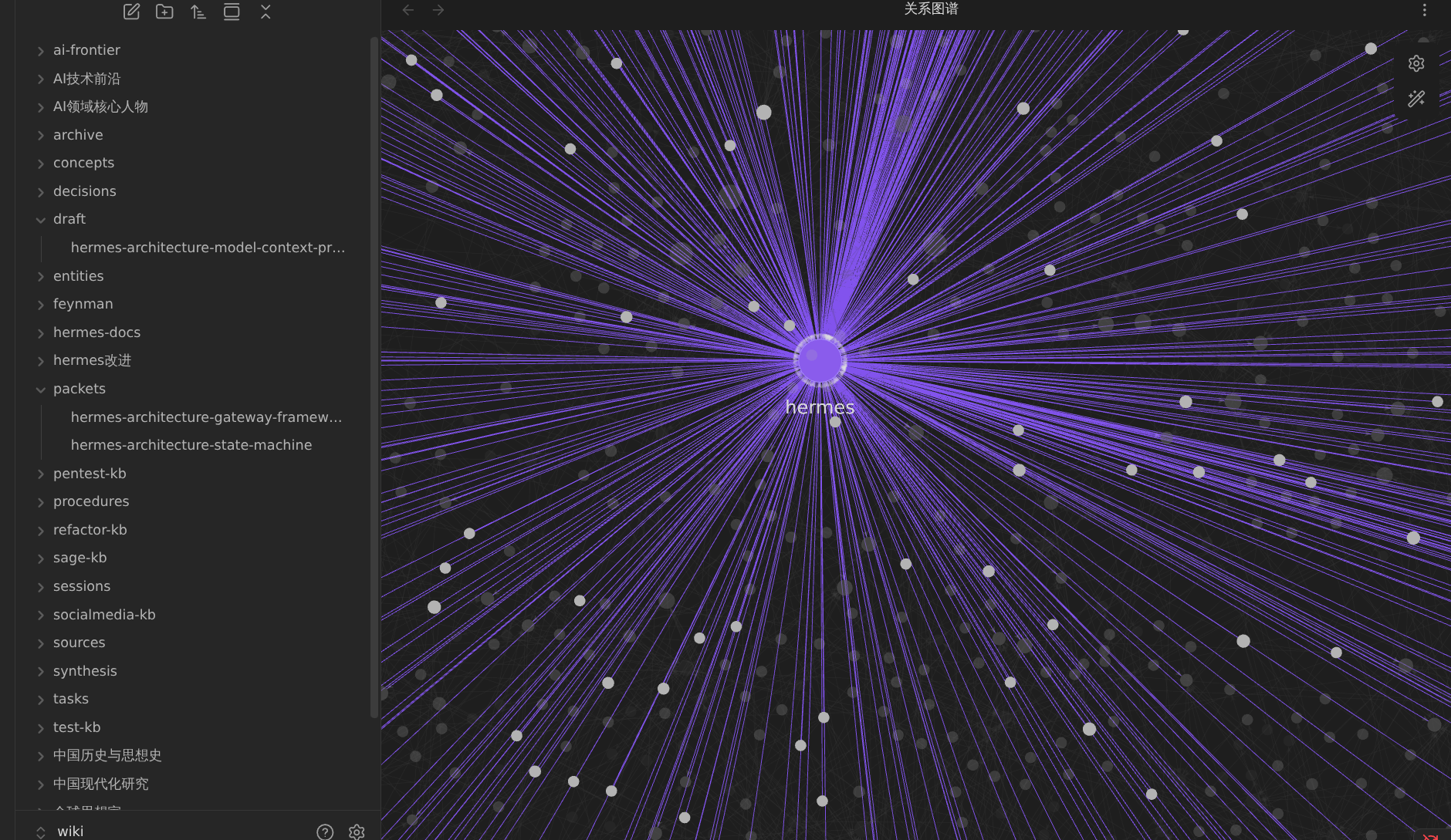
在 Obsidian 里,我甚至做了一份完整的演示文档,向团队展示了「未来的知识管理形态」。图 1 是我当时展示的截图:界面优雅,知识节点之间的关系图谱清晰可见,检索结果旁标注了来源链接,一切看起来都在掌控之中。
3.2 现实:协议转换的隐性成本
真正的噩梦从「让 Hermes Agent 调用它」开始。
第一层冲突:接口协议不对齐。
Hermes 的 Agent 使用 MCP(Model Context Protocol)进行工具调用,期望所有外部工具以标准 JSON Schema 描述自己的能力,并通过统一的 Function Calling 接口返回结构化结果。但 LLM Wiki 暴露的是一个黑盒式的聊天接口:你传入一个问题,它返回一段自然语言。没有中间态的 chunks 列表,没有置信度分数,没有元数据字段。为了让 Agent 能够基于检索结果做条件判断,我不得不写了一个复杂的正则解析层,试图从自然语言中提取关键信息——这本身就是一个脆弱且难以维护的噩梦。
第二层冲突:上下文管理逻辑打架。
Hermes 有自己的记忆压缩策略:在多轮对话中,它会维护一个「关键信息摘要」,并在每次调用大模型前,将摘要与当前轮次的上下文拼接成 prompt。但 LLM Wiki 在内部也实现了自己的上下文拼接逻辑:固定前缀 + 检索到的 Top-K chunks + 系统提示 + 历史对话。当两者叠加时,出现了严重的上下文污染:Wiki 的固定前缀覆盖了 Hermes 的系统提示,Wiki 的历史对话管理与 Hermes 的记忆模块产生了重复和冲突。
第三层冲突:并发性能雪崩。
Demo 时单用户测试,延迟 200ms,体验丝滑。但当我同时启动 3 个 Hermes Agent 实例进行并发查询时,延迟飙升到 8 秒以上。原因在于 LLM Wiki 的检索链路在设计上没有考虑高并发场景:每次查询都会触发多次向量检索 + 图遍历 + 重排序,而连接池和缓存层都没有针对并发做优化。
3.3 结果:大而不用,资源浪费
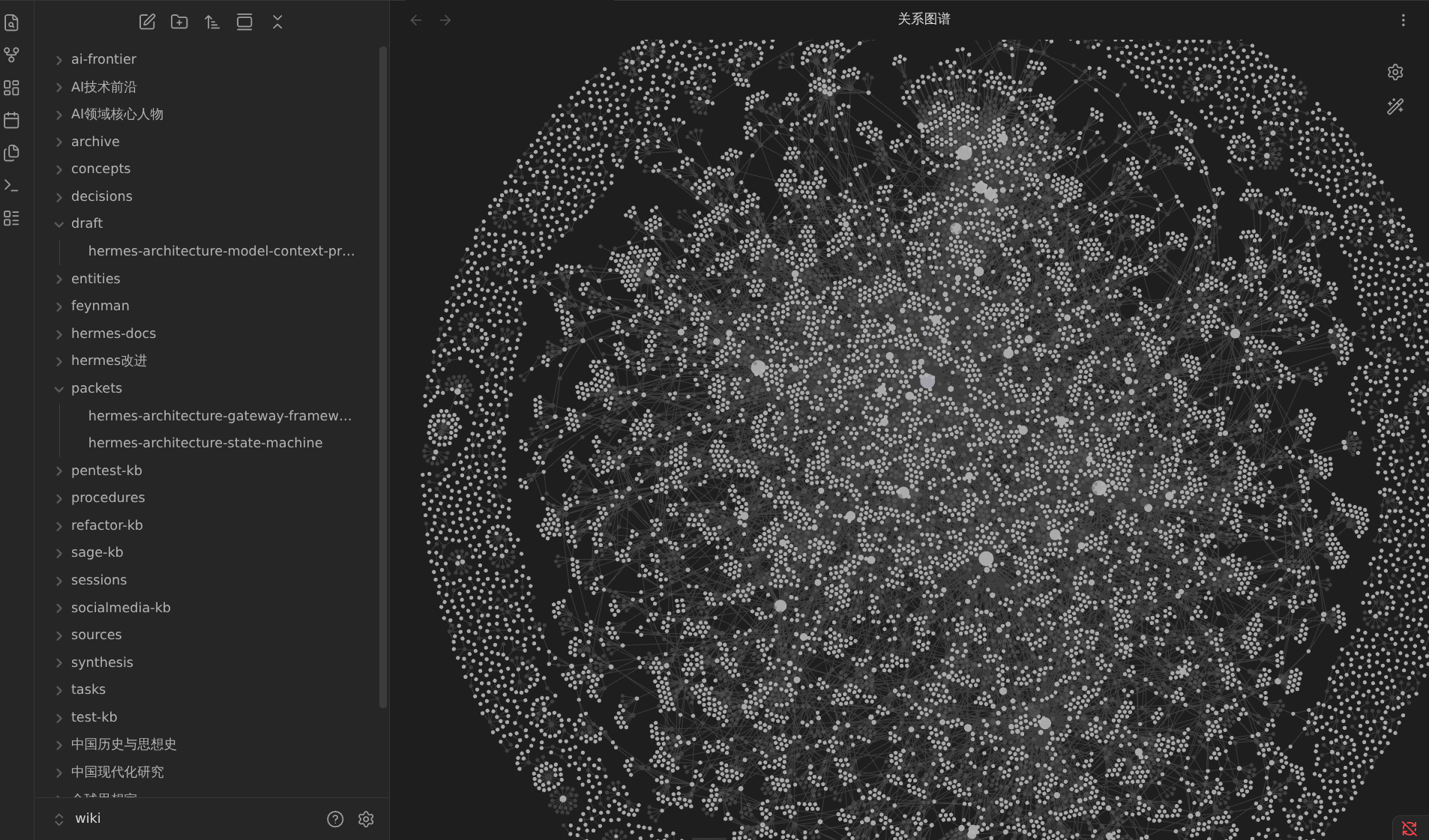
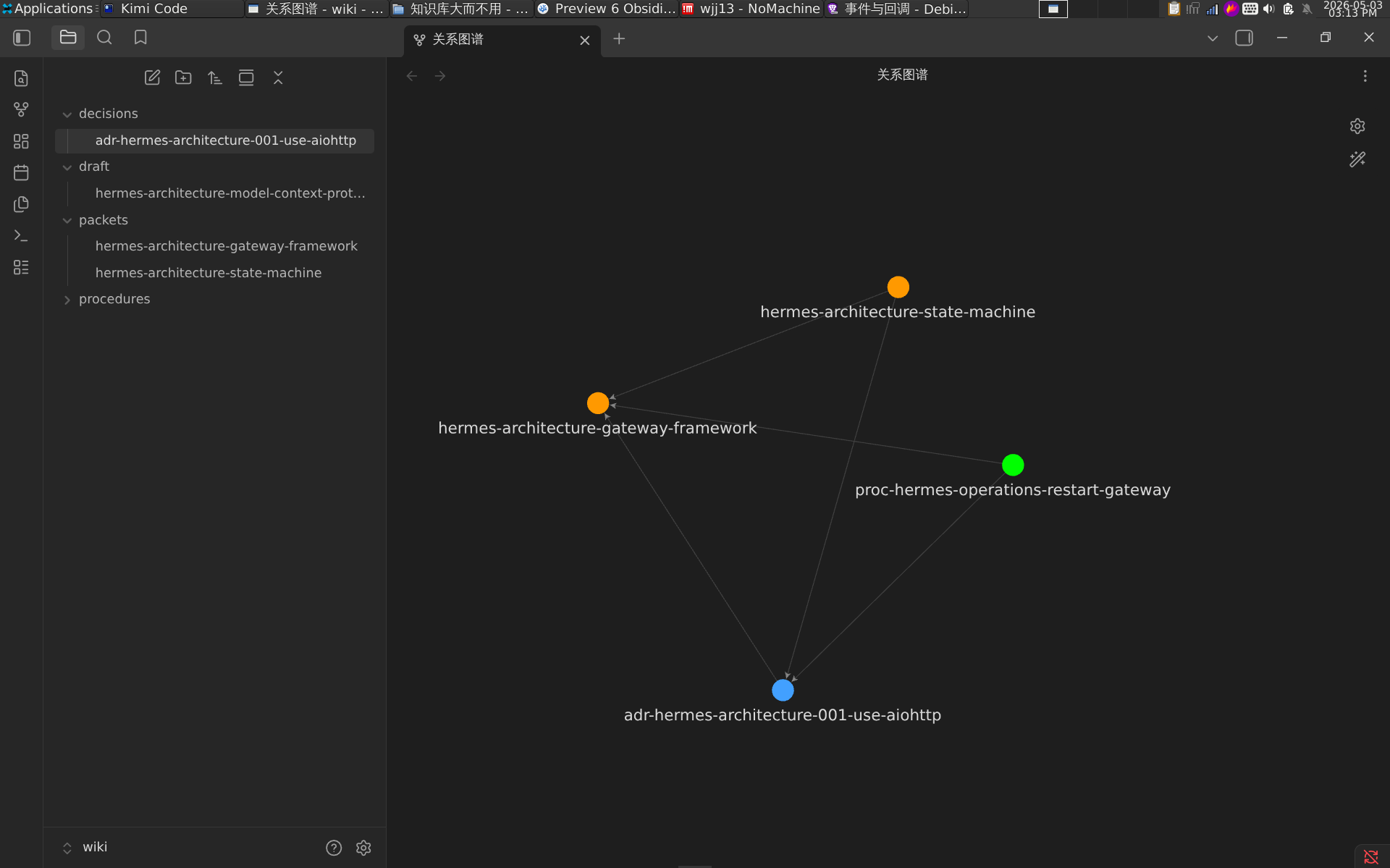
图 2 是放大后的细节:看似丰富的检索结果,实际上充斥着重复片段和来自不同版本的冲突内容。图 3 是经过全面评估后,我确定 Hermes 真正能够引用的知识——只占整个 Wiki 索引内容的极小部分。
「亚麻叠了吧?」(やめて,停手吧。)
这是我在那个深夜对自己说的唯一一句话。一个星期的时间,换来的不是能力的增强,而是本地磁盘上 20GB 的冗余数据、一个与核心架构格格不入的中间件、以及无数个需要手动维护的适配器脚本。
四、根源剖析:为什么 GitHub 高赞项目在生产环境频频翻车
这个案例不是个例。当下 AI 工具的泛滥和「拿来主义」盛行,本质上是一场「技术民主化」与「工程纪律」的冲突。GitHub 热门项目降低了「看到可能性」的门槛,但投产需要的是「管理复杂性」的能力。
4.1 GitHub Stars 是体验经济,不是工程评级
一个项目获得高赞,往往是因为它解决了「让开发者 wow 一下」的问题:
- 一键生成的炫酷演示;
- 漂亮的流式输出动画;
- 精心设计的示例对话,每次都能得到完美答案;
- README 里充满未来感的架构图。
但「让运维半夜不被叫醒」的问题——接口稳定性、降级策略、观测性、权限隔离、并发控制——在 demo 里都被有意无意地隐藏了。Stars 数量反映的是「首次体验的惊艳程度」,而非「生产环境的可靠程度」。
这不是用户的错。在信息过载的时代,GitHub Stars 几乎是普通开发者判断项目质量的唯一快速指标。但当这个指标被「体验经济」扭曲时,它就成了误导决策的噪音。
4.2 「AI Native」成了免责金牌
很多项目打着 AI Native 的旗号,把传统软件工程的基本原则当作「旧时代的包袱」扔掉:
- 接口契约:知识库项目不暴露文档级别的检索中间态(chunks、置信度、元数据),只给你一个黑盒式的答案;
- 边界清晰:Agent 框架不提供工具调用的超时熔断、重试策略和降级路径;
- 可测试性:RAG 系统的检索链路涉及向量相似度、重排序、大模型生成三个非确定性环节,几乎无法编写稳定的单元测试。
当这些基础工程能力缺失时,「AI Native」就成了一块遮羞布——它暗示你:「我们的架构是为了 AI 时代重新设计的,所以不需要遵循那些过时的原则。」但事实是,越是复杂的系统,越需要清晰的边界和可观测的中间态。
4.3 评估成本被转嫁给终端用户
为什么 80% 的用户会在未经充分评估的情况下引入知识库架构?因为评估成本极高。
要判断一个知识库架构是否适配你的 Agent,你需要深入理解:
- 它的分块策略(Chunking Strategy)是按固定长度切分,还是按语义边界切分?是否支持重叠窗口?
- 它的元数据模型是否支持自定义字段?这些字段能否被用于过滤和权限控制?
- 它与 LLM 的交互协议是单次检索后生成,还是多轮检索-推理循环(如 Self-RAG、Corrective RAG)?
- 它的索引更新机制是全量重建,还是支持增量更新和删除标记?
- 它的向量存储层是否支持多租户隔离?
理解这些问题往往需要读源码、甚至 fork 改造。而用户最初的想法可能只是「找个现成的知识库接进来」。当评估成本远高于「直接试试」的成本时,大多数人会选择后者——然后付出生产环境翻车的代价。
五、解决方案:Agent 工具选型的「三层过滤机制」
为了避免被 GitHub 热门项目绑架,我为 Agent 工具选型建立了一套「三层过滤机制」。每一层都有明确的决策时间和通过标准——如果某一层无法通过,就不要进入下一层,更不要投入集成开发。
5.1 第一层:协议层对齐(5 分钟决策)
这一层的目标是在不读源码的情况下,快速排除明显不匹配的项目。核心检查项包括:
Q1:是否强制绑定特定模型供应商?
如果一个 RAG 项目只支持 OpenAI 的 Embedding 和 GPT-4,而你的生产环境使用的是国产模型或私有化部署的模型,那么它在你的技术栈里就是一条死路。真正生产级的项目应该暴露模型配置接口,允许你注入自己的 Embedding 模型和 LLM 客户端。
Q2:检索接口是黑盒 API,还是暴露中间态?
理想的知识库应该返回结构化的检索结果,至少包含:
- 检索到的原始 chunks 列表;
- 每个 chunk 的置信度/相似度分数;
- 来源文档的元数据(文件名、版本、权限标记);
- 检索链路的时间消耗和调用路径。
如果项目只给你一个「输入问题 → 返回答案」的黑盒接口,那么当答案出错时,你将没有任何调试抓手。
Q3:能否以标准工具形态接入?
如果你的 Agent 使用 MCP(Model Context Protocol)或 Function Calling,知识库应该能以标准工具的形态被调用——即通过 JSON Schema 描述能力,返回结构化结果。如果它要求你重写 Agent 的核心循环、替换掉原有的记忆管理模块,或者侵入式地修改你的 HTTP 路由和数据库 schema,这就是一枚红色信号弹。
决策规则:三个问题中如果有任何一个的回答是「否」或「不确定」,直接淘汰。5 分钟足够做出判断。
5.2 第二层:数据层压力测试(2 小时决策)
通过第一层筛选的项目,才有资格进入真实数据测试。注意,不要用仓库提供的示例 PDF,那些文件通常经过精心挑选,格式规整、内容清晰、没有 edge case。
测试 1:脏数据兼容性
找一份你真实的业务文档——带表格混乱、OCR 识别错误、重复段落、格式混排(Word + PDF + Markdown 混合)的文件。观察知识库在索引和检索时的表现:
- 分块是否会切在句子中间,导致语义断裂?
- 重复内容是否会被去重,还是会在检索结果中反复出现?
- 表格数据是否能被正确解析为结构化格式,还是变成一团无意义的文本?
测试 2:增量更新精准度
修改一份已经索引的源文档中的某一段内容,然后触发知识库更新。检查:
- 更新是只影响对应的 chunk,还是触发了全量重建?
- 更新后的检索结果是否准确反映了修改内容?
- 旧版本的 chunk 是否已经被正确标记为失效,还是可能在新查询中「幽灵重现」?
测试 3:并发稳定性
同时启动 3 个 Agent 实例对知识库发起查询,监控:
- P99 延迟是否仍在可接受范围(通常 < 2s)?
- 并发查询是否会互相干扰结果(例如返回了本应被过滤的文档)?
- 当查询量突增时,系统是会排队等待,还是直接拒绝服务或返回错误?
决策规则:如果任何一项测试的结果不达标,记录具体问题的严重程度。如果问题涉及核心架构(如不支持增量更新、并发下数据不一致),则淘汰;如果是配置可调优的次要问题,标记为「需改造」并估算成本。
5.3 第三层:架构层回退能力(1 天决策)
这一层关注的是「明天这个项目停止维护了,我该怎么办」。
检查 1:侵入式程度评估
- 它是否要求修改你的数据库 schema?
- 它是否劫持了你的 HTTP 路由或认证中间件?
- 它是否要求你的 Agent 放弃原有的记忆管理策略,全面迁移到它的模型?
如果答案是「是」,那么它就是侵入式中间件。侵入式程度越高,剥离成本越高。
检查 2:替代方案切换成本
假设明天这个仓库归档,你能否在一天内切换到另一个知识库方案(如从 GraphRAG 切换到普通 RAG,或从自托管切换到托管服务)?
关键取决于:
- 你的业务代码是否直接依赖了该项目的特定 API 和数据结构?
- 你的向量索引是否可以导出为通用格式(如 parquet、JSONL),被其他系统读取?
- 你的 prompt 模板和检索逻辑是否与该项目深度耦合?
检查 3:松耦合设计验证
理想的知识库应该以 sidecar 或 微服务 的形态存在:
- 它通过标准协议(HTTP/gRPC)与你的 Agent 通信;
- 它不触碰你的主数据库,只维护自己的索引存储;
- 它的失败不会导致你的 Agent 主流程崩溃(即支持熔断和降级)。
决策规则:如果项目在 1 天内无法被剥离和替换,或者它的失败会级联拖垮你的 Agent 核心流程,那么你需要重新评估引入它的风险收益比。
六、深度补充:知识库集成的隐性成本清单
除了上文提到的协议冲突和架构耦合,在实际生产环境中,知识库集成还隐藏着大量容易被忽视的隐性成本。以下是我基于多个项目经验总结的「隐性成本清单」,供你在选型时逐项核对:
6.1 Embedding 模型对齐成本
不同的知识库项目可能对 Embedding 模型有特定的假设:
- 维度假设:你的旧系统使用 768 维向量,新项目要求 1024 维,意味着全量重建索引;
- 距离度量:余弦相似度 vs 欧氏距离 vs 点积——不同的度量方式会导致检索结果排序差异巨大;
- 多语言支持:如果你的知识库包含中英文混合内容,需要验证 Embedding 模型在跨语言场景下的语义对齐能力。
6.2 分块策略冲突
分块(Chunking)是 RAG 系统的核心,但也是最容易产生「隐形 bug」的环节:
- 固定长度分块(如每 512 token 切一刀)实现简单,但容易切断代码块、表格或逻辑段落;
- 语义分块(如按句子边界或主题边界切分)效果更好,但依赖 NLP 模型的质量,且处理速度更慢;
- 重叠窗口(Overlap)可以提高上下文连续性,但会显著增加索引体积和检索冗余度。
如果你的 Agent 对上下文的粒度有特定要求(比如需要完整的代码函数体、或需要跨段落的长逻辑链),知识库的分块策略必须与之匹配,否则检索回来的 chunks 将无法支撑正确的决策。
6.3 元数据模型不匹配
生产级知识库不仅需要存储文本内容,还需要丰富的元数据支持:
- 权限标记:哪些文档对哪些用户/角色可见?
- 时间戳和版本:这份内容在何时被索引?源文档是否已经更新?
- 内容类型:这是代码、设计文档、会议纪要,还是第三方参考资料?不同类型的内容在检索时应有不同的权重和处理方式。
- 自定义标签:业务特有的分类体系(如「已审核」「待确认」「deprecated」)。
如果知识库的元数据模型过于僵化,不支持自定义字段,或者无法在检索时作为过滤条件使用,那么它就无法融入你的业务权限体系。
6.4 权限隔离与数据安全
RAG 系统有一个经典的安全陷阱:语义相似度检索可以绕过显式的权限控制。
举例:用户 A 无权访问文档《内部财务报告.docx》,但文档中的某段文字与《公开新闻稿.docx》中的内容语义相似。当用户 A 查询相关话题时,知识库可能通过向量相似度,把《内部财务报告》中的对应 chunk 作为「相关上下文」返回给大模型,从而导致信息泄露。
生产级知识库必须在检索链路中集成文档级别的权限过滤器,确保检索结果在返回前已经过用户权限的二次校验。但很多开源项目的 demo 完全不涉及这一层。
6.5 版本控制与增量更新
在快速迭代的业务中,知识库内容每天都在变化。全量重建索引的成本极高(对于 10 万级文档可能需要数小时),因此增量更新是刚需。
但增量更新涉及一系列复杂问题:
- 如何检测源文档的变更(文件系统监听?Webhook?定时轮询?)
- 变更后如何精准定位受影响的 chunks,而非全量重建?
- 删除的文档如何在索引中被正确标记为失效?
- 更新过程中,正在进行的查询是否会读到「半新半旧」的混合状态?
这些问题在 demo 中不会出现,因为 demo 的数据是静态的。
6.6 观测性与调试能力
当 RAG 系统给出错误答案时,你需要回答三个问题:
- 它检索到了什么?(Retrieval Observability)
- 它为什么检索到这些?(Ranking Explainability)
- 大模型基于这些生成了什么?(Generation Traceability)
很多知识库项目在这三方面的观测性支持极为薄弱:
- 没有检索日志,无法查看某次查询命中了哪些 chunks;
- 没有相似度分数的暴露,无法判断检索结果是否「勉强匹配」;
- 没有与大模型交互的完整 prompt 记录,无法复现和调试生成错误。
在缺乏观测性的情况下,RAG 系统就是一个黑盒——它今天工作正常,明天可能因为一次索引更新就开始胡说八道,而你根本找不到原因。
七、工程哲学:让 Agent 先跑起来,再逐步替换组件
回顾整个踩坑经历,我最大的反思是:Agent 的业务逻辑和决策循环才是核心,知识库应该像数据库一样——可替换、可观察、不绑架业务架构。
对于个人开发者或小团队,我的建议是:
7.1 先跑通端到端流程,再优化组件
不要一开始就追求「完美的知识库架构」。先用最简单的方案(比如直接把关键文档塞进 prompt,或者用一个轻量级的向量检索库)让 Agent 的端到端流程跑起来。只有当你真正遇到「上下文长度不够」「检索质量太差」「响应速度太慢」这些具体的、可量化的痛点时,才引入更复杂的知识库组件。
过早优化是万恶之源,在 AI 时代尤其如此——因为组件的迭代速度极快,今天你认为「必需」的 GraphRAG,三个月后可能已经被新的架构取代。
7.2 把知识库当作「可替换的基础设施」
在你的架构设计中,知识库应该被抽象为一个接口,而非具体的实现:
# 好的抽象
class KnowledgeBase:
def retrieve(self, query: str, filters: dict) -> List[RetrievalResult]:
...
# 具体的实现可以替换
class SimpleVectorKB(KnowledgeBase): ...
class GraphRAG_KB(KnowledgeBase): ...
class NoOpKB(KnowledgeBase): ... # 用于降级和测试
这样,当你需要替换知识库实现时,只需要修改依赖注入的配置,而不需要重写 Agent 的核心逻辑。
7.3 保持对「演示泡沫」的警觉
每当你被一个 GitHub 项目的 demo 惊艳到时,请立刻问自己三个问题:
- 这个 demo 用的是什么数据?(是真实业务数据,还是精心挑选的示例?)
- 这个 demo 在什么负载下运行?(单用户单线程,还是高并发多租户?)
- 如果这个项目明天停止维护,我能不能在一天内找到替代方案?
如果任何一个问题的答案让你感到不安,那么请在投入集成开发之前,先严格执行上文提到的「三层过滤机制」。
八、总结:AI 时代,集成成本没有消失,只是转移了
知识库管理结构的引入困难,恰恰说明了一个反直觉的事实:
AI 时代,集成成本没有消失,只是从「写代码」转移到了「对齐抽象层」。
当我们欢呼「AI 让开发变简单了」时,我们往往指的是「写一个能运行的 demo 变简单了」。但把一个 demo 变成可维护、可扩展、可观测的生产系统,其难度并未降低,只是换了一种形式呈现:
- 过去我们需要对齐的是数据库 schema 和 API 契约;
- 今天我们需要对齐的是 Embedding 向量空间、分块语义边界、上下文管理逻辑、Agent 决策循环与知识检索链路的交互协议。
Karpathy 的 LLM Wiki 依然是极好的学习材料和参考实现,但它不是为 Hermes 量身定制的组件。我那一周的努力没有白费——它让我深刻地理解了「好工具」和「好集成」之间的鸿沟,也让我建立起了一套可复用的选型方法论。
如果你正在评估是否要把某个 GitHub 高赞项目引入自己的 Agent 工具链,希望本文的三层过滤机制和隐性成本清单能帮你少走一些弯路。
记住:部署只是起点,投产才是真正的长征。
关于本文的配图说明:
- 图 1:初始引入 Karpathy LLM Wiki 时的界面截图(Obsidian 演示),展示了看似完整的知识节点关系图谱和优雅的检索界面;
- 图 2:放大后的检索细节,可见结果中充斥着重复片段和来自不同版本的冲突内容;
- 图 3:经过全面评估结构后,确定 Hermes 真正能够引用的有效知识——仅占整个 Wiki 索引内容的极小部分,形成了鲜明的「大而不用」对比。
如果这篇文章帮你避开了至少一个选型陷阱,不妨点赞收藏,也欢迎在评论区分享你的踩坑经历或集成心得。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)