DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
|
序号 |
属性 | 值 |
|---|---|---|
| 1 | 论文名称 | DexVLA |
| 2 | 发表时间/位置 | 2026 |
| 3 | Code | DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control |
| 4 | 创新点 | 1:10亿参数的“多头扩散专家” 解决传统VLA模型“脑强(7B VLM)手弱(几百万参数MLP)”的严重失衡问题。引入 ScaleDP(基于Transformer的扩散模型),将其参数量拉爆到 10亿(1B)。 采用 多头架构(Multi-head),共享物理规律主干,每个输出头控制一种具体的机器人(单臂/双臂/灵巧手),彻底解决跨形态机器人无法统一训练的难题。 2:三阶段“具身课程学习” 阶段一(脱轨苦练): 断开VLM大脑,仅用跨本体视觉动作数据预训练10亿参数的小脑,建立底层的物理“肌肉记忆”。 阶段二(灵肉合一): 接上VLM大脑,仅用目标机器人的数据进行对齐训练,让认知与特定躯体完美映射(此时已具备Zero-shot执行简单任务的能力)。 阶段三(精益求精): 针对高难度长程任务进行高质量数据的微调。 3:隐式“子步骤推理” 解决长程任务(>2分钟)中机器人容易“忘词/卡死”的痛点,淘汰了传统且高延迟的外部调度器(如 SayCan + π0π0)。 具体做法: 把“思维链(CoT)”引入底层控制。让VLM在预测动作的同时,不断向内部输出“子步骤文本”(如:正在对齐袖子)。 意义: VLM本身变成了一个自带状态机的高级规划器,直接引导扩散专家完成极度复杂的任务(如叠皱巴巴的衣服),实现了端到端(End-to-End)的超低延迟闭环。 |
| 5 | 引用量 | DexVLA 摒弃了传统VLA“盲目扩大语言大模型”的路线,提出 “大语言模型(看与想) + 10亿参数多头扩散专家(做)” 的解耦架构,通过三阶段课程学习和内部子步骤推理,以极低的数据和算力成本(100小时预训练/单卡60Hz)实现了超越了很多行业内的通用vla模型如Π0。 |

一:提出问题
现在的VLA模型往往把中心放在扩大视觉-语言模型的规模,很少关注动作空间的表示。想要VLA模型在机器人上展现更大的潜力,必须要解决动作表示和高效训练方面的局限性。DexVLA旨在提升VLA模型在不同机器人具身,执行复杂长序列任务时的效率和泛化能力。通过引入一个基于扩散模型的动作专家网络,该网络的参数拓展到了十亿级别,专门为跨具身学习而设计。提出了”具身课程学习“策略,促进了高效的训练过程:(1) 在跨具身数据上对扩散动作专家进行预训练;(2) 将 VLA 模型与特定的机器人具身进行对齐;(3) 通过后训练(post-training)来实现对新任务的快速适应。
在具身智能领域,主流的做法是把大语言模型的输出端直接接上机器人动作,这就是 VLA 模型(如 RT-2, OpenVLA)。而当前大多数现有模型痴迷于扩大视觉语言模型的参数量,但在输出机器人的物理动作时,往往采用简单的“离散化分词”策略。这就好比一个大脑极其聪明的人,却只能用僵硬的、被切割好的几个固定姿势来干活,“动作表示”成为了严重拖后腿的瓶颈。 这导致机器人在做精细活时表现极差。 而DexVLA通过一个十亿参数的插件扩散动作专家,来提升模型的动作表示,针对传统的自回归输出容易产生累积误差,且难以表示连续的、多模态的动作分布。扩散模型在生成平滑、高频、连续的多维动作轨迹方面具有天然优势。传统的 VLA 中,动作头通常只是一个很小的多层感知机或几层 Transformer。DexVLA 极其大胆地将专门负责动作生成的网络扩大到了 10 亿参数这意味着模型拥有了极强的对复杂物理世界动力学、运动学规律的建模能力。插件式也意味着视觉-语言的“高级逻辑推理”和扩散专家的“底层物理动作生成”在架构上实现了优雅的解耦。VLM 负责“想清楚要做什么”,并输出高维特征指导,而插入的 Diffusion Expert 则负责“如何极其精准地做到”。 其次就是让一个如此庞大的动作模型学会控制完全不同的硬件,直接端到端训练收敛是及其难以做到的,因此作者提出了三步走的课程学习方法:
-
跨具身预训练:先让 1B 的扩散专家看海量的、不同机器人的动作数据。这一步让模型学习到通用的“物理常识”和“空间运动规律”。
-
特定具身对齐:把 VLA和扩散专家接在一起,针对你要控制的特定硬件进行联合微调,让大脑的语言指令能够准确翻译成该硬件的扩散生成条件。
-
任务自适应后训练:在具体的下游任务上进行快速微调,实现少样本下的快速泛化。
这篇文章告诉我们,只重视VLM是不行的,要把动作模型也重视起来。动作生成本身也是一个需要极大算力和参数去你和的复杂分布。引入1B参数的扩散模型能够很好的作为action expert。
当前vla的两个问题:
1.卷数据量: 训练通用机器人,大家都在拼数据。Google/UC Berkeley 搞了 4000 小时的 Open-X 数据集;Pi 公司财大气粗,搞了 10,000 小时的数据来训练 π0。但真实的机器人数据极其昂贵,需要人戴着 VR 头显或者遥控器一点点录制,人工,财力依赖很大。DexVLA 试图打破这种“暴力美学”。
2.重视VLM忽视动作模型:现在的 VLA,脑子极大,70亿参数,看过全网的文本和图像,上知天文下知地理;但是用来控制机器人的动作输出层通常只有一个极小的多层感知机,几百万参数。这就好比霍金的大脑装在了一个小婴儿的身体上,脑子能听懂“去倒杯水”,但神经肌肉的协调性极差,根本控制不好机械臂精细倒水。
针对这种头重脚轻的问题,作者提出了一个十亿参数的动作专家,将动作生成网络直接撑到 10 亿参数。这赋予了模型极强的表达能力,使其能够拟合复杂的物理规律。采用多头架构:不同的机器人长得不一样。单臂只有 7 个自由度,双臂有 14 个,灵巧手可能有 16 到 24 个以上。直接把它们混在一起训练,模型会精神分裂。DexVLA 采用共享底层特征网络 + 不同的输出头的设计。在训练时,遇到单臂数据就更新单臂的头,遇到灵巧手就更新灵巧手的头,但中间那 10 亿参数的“物理常识骨干网络”是大家一起共享学习的!
提出了三阶段具身课程需详细方案: 1.第一节阶段进行无脑的预训练:抛开 VLM 这个“大脑”,纯粹用各种机器人的运动轨迹数据来训练 1B 的 Diffusion 专家。让它只学一件事:理解空间几何、运动学和物理连续性。 2.手眼协调:把大脑和练好肌肉记忆的身体接在一起。告诉大脑:“你现在控制的是一台双臂机器人”。此时,模型学会了把语言指令(“把红色方块放在蓝色方块上”)翻译成平滑的物理动作。 3.长序列拆解:这一步是对标 π0 的核心亮点。π0 做长任务时,必须外挂一个 SayCan 系统,每隔 2 秒钟重新想一下下一步干嘛,非常笨重。而 DexVLA 利用了大模型强大的 思维链 / 子步骤推理 能力。它在训练数据里加入了“子步骤标签”(比如叠衣服 = 抚平 + 对齐 + 翻折)。这样,VLM 直接在内部完成了长任务的规划,并源源不断地指挥 Diffusion 专家执行,动作丝滑且连贯。
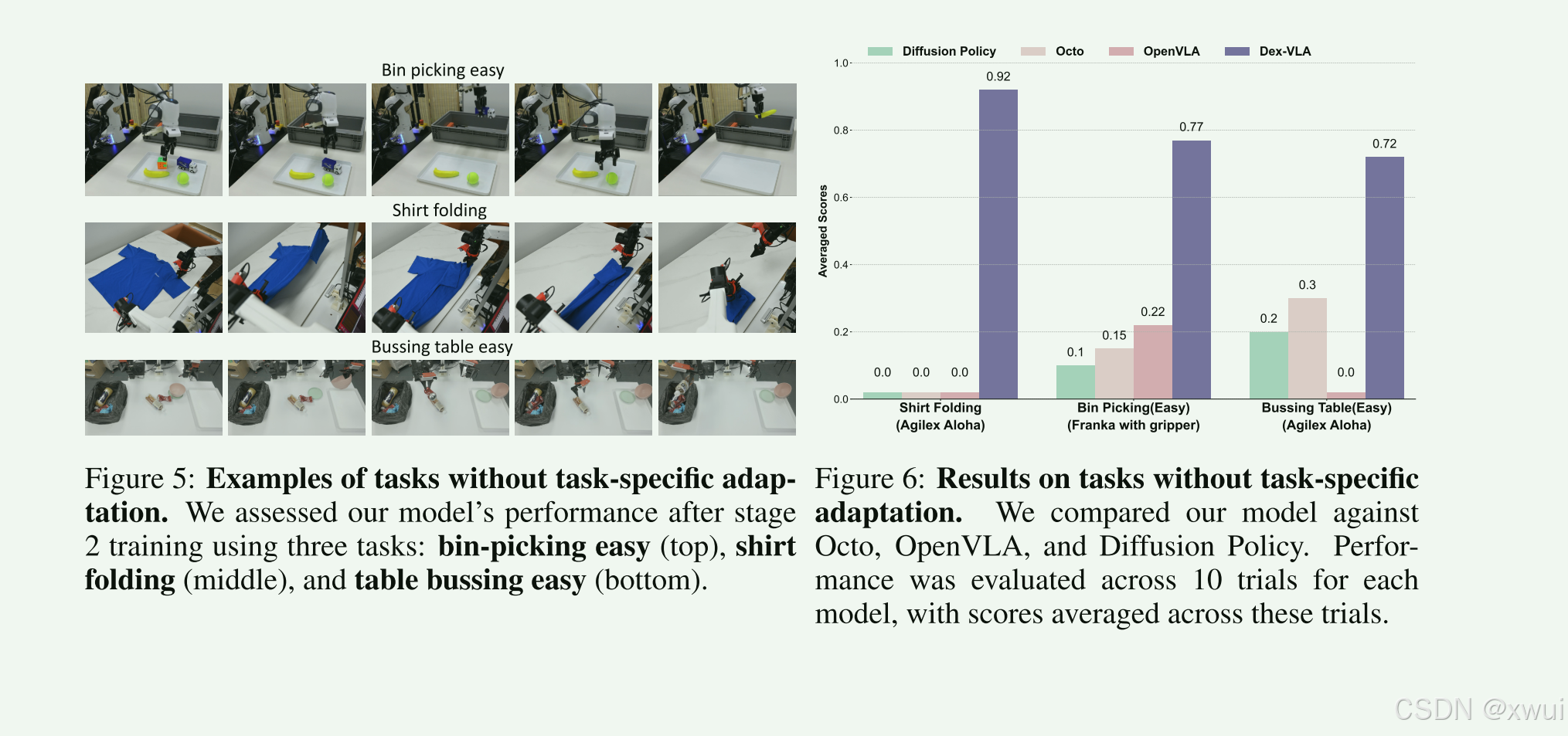
最终的实验结果表明:
极高的数据效率: π0 用了 10,000 小时数据,而 DexVLA 的预训练仅用了 100 小时数据!不到前者的 1%。更可怕的是,在灵巧手上学习新动作,竟然只需要 <100 条示范(Few-shot learning 的极致体现)。
恐怖的推理性能: VLA 模型最怕的就是卡顿。机器人控制的频率通常要求至少 10-20Hz。DexVLA 挂载了巨大的 VLM 和 1B 的 Diffusion,竟然能在一张民用级顶配卡(Nvidia A6000)上跑到 60Hz(每秒输出60次动作)。这证明了其框架设计在工程上极其优秀,使得低成本落地成为可能。
二:解决方案
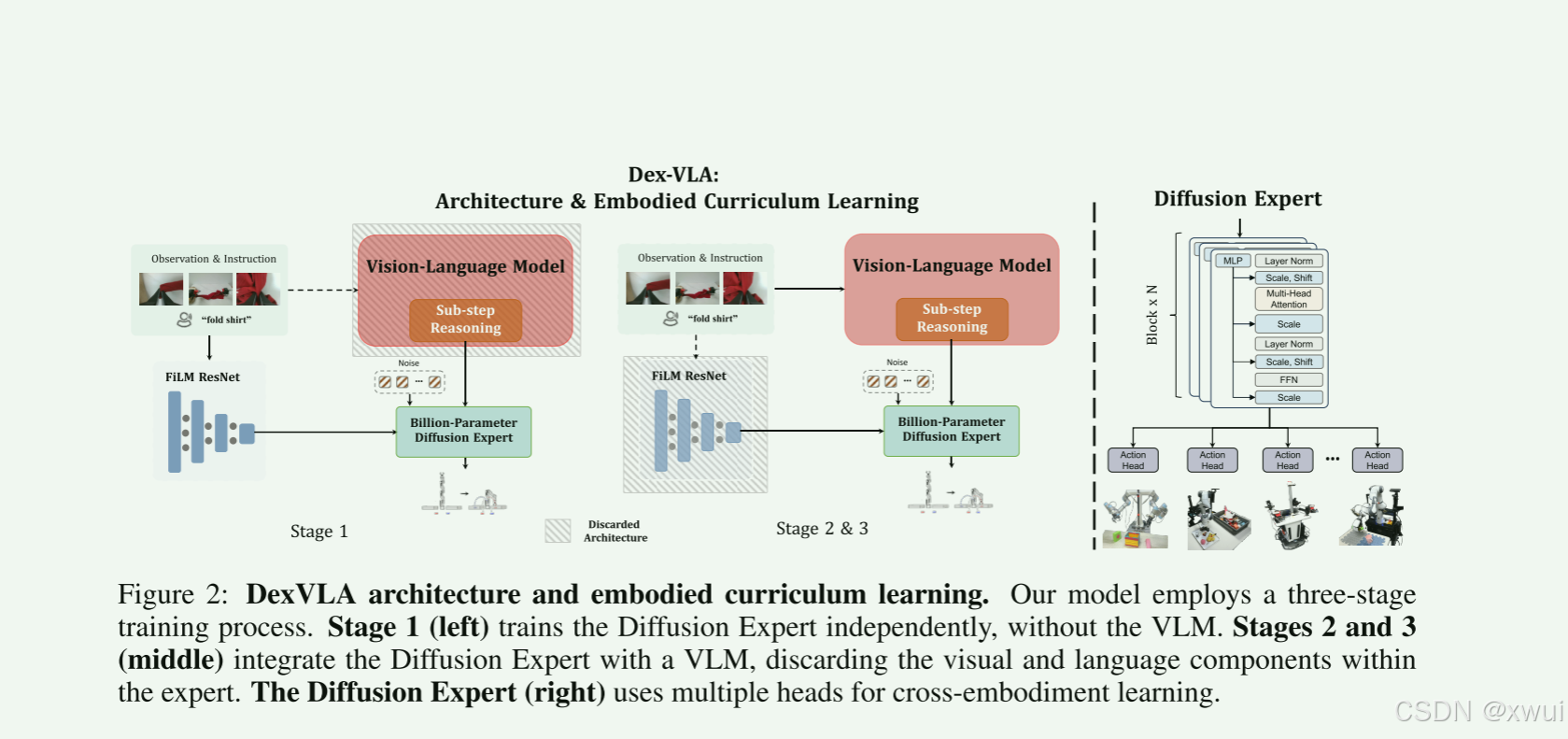
大脑:选用Qwen2-VL 作为基础模型。这是目前开源界最能打的多模态大模型之一。核心优势在于支持动态分辨率。这对机器人极为重要。机器人常常有多个摄像头,尺寸还不一样,Qwen2-VL能够很好的提取多视角的空间特征,并将这些视觉token简单粗暴的拼接送入语言模型的上下文中。
2.脑干:桥梁的双流设计 (Two-Stream Token Outputs)。传统的 VLA 模型(如 RT-2)通常是“一根筋”:看到图像和指令,直接把动作当成文字输出(比如输出 "X=10, Y=20")。DexVLA 打破了这个范式,让 VLM 输出两股截然不同的信息流:
-
1.动作 Token 这部分模仿了经典大模型 LLaVA 的做法。动作 Token 并不直接是机器人的电机角度,而是含有丰富语义的高维向量。通过一个简单的 Linear -> LayerNorm -> Linear 的 MLP 网络(投影模块),把 VLM 那几千维的词向量空间,降维/转换成下游 Diffusion 模型能够听懂的“条件输入特征”。
-
2.推理 Token(传递“怎么做”的认知逻辑)—— 这里使用了 FiLM 机制 FiLM (Feature-wise Linear Modulation)简单来说,推理 Token(比如 VLM 内部生成的思维链:“当前步骤需要先对齐衣袖”)不会直接变成动作,而是变成了一组 Scale (乘法权重 γ)和 Shift (加法偏置 β)。这些 γ和 β会直接去动态修改/调制扩散专家网络内部的特征分布:Feature_out=γ×Feature_in+β 。这意味着,大模型的高级逻辑推理能力,以一种“自适应开关/滤波器”的形式,深深注入到了底层的物理动作网络中。这就好比你在做精细手术时,你的意识(推理)在高度集中地调节你手部肌肉(动作网络)的紧张度。
3.小脑与四肢:1B 参数的 ScaleDP 与多头架构 :早期的 Diffusion Policy 通常使用卷积 UNet 来去噪生成动作轨迹。但 UNet 很难把参数量做大。DexVLA 直接采用了 ScaleDP(类似于 SORA 和 DiT 的架构,纯 Transformer 的扩散模型)。Transformer 极强的 Scaling Law 使得动作专家能被轻松扩展到 10亿(1B)参数,这是它能理解极其复杂的物理定律(如摩擦力、精细形变)的算力基础。
-
多头架构(Multi-head)解决跨具身灾难: 想象一下,数据集中同时有:7个关节的单臂机械臂、14个关节的双臂、加上夹爪、还有24个关节的灵巧手。如果用同一个输出层去预测,网络会彻底崩溃(维度都不一样)。 解决方案: 1B 参数的 ScaleDP 作为“通用躯干(Trunk)”提取所有机器人共有的物理运动规律(比如平滑性、避障逻辑);而在网络的最后一层,开枝散叶,长出多个 Head(头)。
-
头 A:专门输出 7维动作(单臂)。
-
头 B:专门输出 24维动作(灵巧手)。 训练时,如果输入是单臂数据,梯度就只通过“头A”回传更新 Trunk;这样就能把全网不同机器人的废料数据,全部拿来滋养这 1B 的通用躯干!
-
4.训练目标:快慢结合的 Loss 函数:这其实是一个多任务学习(Multi-task Learning)的过程。
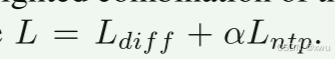
-
Lntp (Next-Token Prediction):这是大语言模型最经典的“猜下一个词”损失。因为 Qwen2-VL 已经用海量互联网数据预训练过了,所以它在生成“语言推理指令”时,Loss 下降得飞快(很快就收敛了)。
-
Ldiff(Diffusion Loss):这是去噪扩散损失,用来训练那 1B 的动作专家。因为机器人数据是全新的、高频连续的物理轨迹,它极其难学。
-
为什么这么设计? 作者发现 Lntp极快收敛后,整个庞大的网络就可以“静下心来”,利用收敛好的、高质量的推理 Token(经由 FiLM),全心全意地去攻克最难的 Ldiff(动作生成预测)。这种“先学会思考,再专注练习动手”的内在机制,极大地提高了模型的收敛效率。
2.1 Embodied Curriculum Learning
这里主要展示了作者的训练技巧,如何把庞大且复杂的网络训练好也是一个非常重要的问题。
1.预训练
如果你把 7B 的 Qwen2-VL 大脑,直接接上 1B 的多头扩散专家小脑,然后扔进包含几千小时不同机器人的数据堆里联合训练。大概率的结果是:显存爆炸、训练极慢,而且由于视觉/语言大模型的学习速率和底层运动学的学习速率不一致,整个网络会崩溃。在阶段一,作者根本没有用大模型(Qwen2-VL)! 而是把小脑拆下来单练。他们使用非常轻量级的 ResNet-50 提图像特征,DistilBERT 提语言特征,直接喂给 1B 的扩散专家进行训练。这就像是武侠小说里的“先练基本功”。不教高级战术(VLM的高层认知),而是让扩散专家纯粹地学习物理世界的基础规律(怎么抓、怎么抬、不同机械臂的运动学映射)。这样极大地节省了算力,并让 1B 的小脑充分收敛。
2.大脑和身体的链接
小脑练好基本功后,现在把 Qwen2-VL 大脑接上来。但这时的模型存在“认知错乱”——大脑的视觉特征和小脑需要的特征对不上,且跨本体学到的通用动作可能在具体某一台机器上不够精准。只拿目标机器人(单一本源)*的数据,并且*冻结了 VLM 的视觉编码器(因为视觉编码器看图的能力已经足够强了),重点训练大模型内部、连接器(Projection layer)以及扩散专家。作者发现,仅仅经过这一步“认祖归宗”的对齐过程,模型居然就能直接零样本(Zero-shot)去叠衣服和抓东西了!这说明 VLM 的高层泛化能力和小脑的通用动作能力被完美打通了。
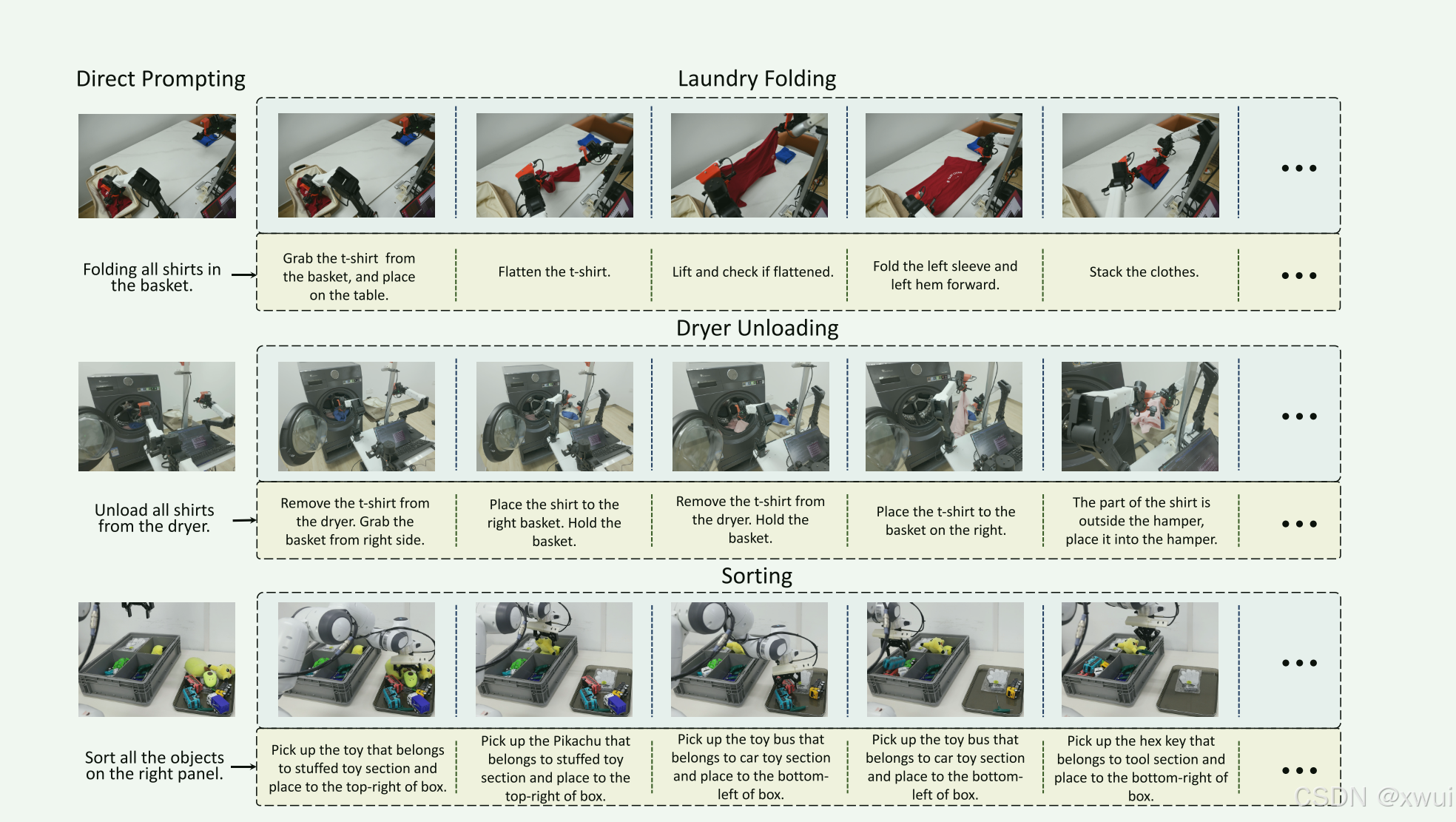
3.子步骤推理
假设你对机器人说“清理桌子”,这个动作要2分钟。如果只凭这一句话,走到第1分钟时,动作专家往往会“迷失”,不知道下一步是该擦桌子还是该收盘子,导致“跳步”或卡死。而传统的方案如Π0之类的,会弄一个外部的调度器(相当于旁边站个指导老师)。每隔两秒钟拍一张照,用另一个大模型判断一下,然后喊口令:“去拿盘子” -> “去放进水槽”。这需要两个系统来回通信,延迟高,且系统极其复杂。为此本文采用了如下的策略。
-
作者对数据进行了处理,每隔5秒加上如“对齐袖子”、“抚平褶皱”的标签。
-
关键点:这些标签不作为用户的输入提示,而是作为模型每一帧的中间输出任务!
-
大模型在输出动作的同时,必须像自言自语一样输出当前的子状态(推理词元 Reasoning Tokens)。
-
这些词元通过上一节提到的 FiLM层 实时注入扩散专家。
DexVLA 把 VLM 直接变成了一个自带状态机(State Machine)和规划器(Planner)的隐式策略模型。大脑通过内部的语言循环,时刻提醒小脑“咱们现在在干嘛”,彻底摆脱了对外部调度器(SayCan)的依赖,实现了极其紧凑、低延迟的端到端(End-to-End)长程任务执行。
三:实验
四:总结
从其他工作都重视的大语言模型,转换思路到动作模型上。利用视觉-语言模型(VLM)来学习语义信息,并采用一个十亿(1 Billion)参数的扩散专家(diffusion expert)来学习鲁棒且可泛化的视觉-运动策略。引入了一种具身课程学习策略(embodied curriculum learning strategy),使网络能够通过三个训练阶段,逐步从与本体无关(embodiment-agnostic)的运动技能,学习到复杂的、特定本体(embodiment-specific)的灵巧技能。结合了子步骤推理(sub-step reasoning),允许模型在不依赖高层策略模型(high-level policy model)的情况下执行非常长程的任务。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)