深度学习到底在学什么?先别急着背公式
很多人学深度学习,第一步就被劝退了。
不是因为它真的完全学不会,而是很多教程一上来就太“硬”了:矩阵、梯度、反向传播、损失函数、优化器……每个词看起来都很重要,但连在一起就让人有点迷糊。
所以在这个系列的第一天,我们先不急着背公式,也不急着写复杂代码。
今天只解决一个问题:
深度学习到底在学什么?
换句话说,为什么我们给模型看很多图片、文本或者数据之后,它就好像能慢慢“变聪明”?
1.先从一个生活例子说起
假设你要教一个小朋友认识猫和狗,你会怎么教?
你大概率不会这样教:
耳朵长度大于多少厘米的是狗,胡须数量大于多少的是猫,脸部轮廓满足某种数学公式的是猫……
现实中,我们通常会这样教:
你给他看很多猫的照片,也给他看很多狗的照片。看多了以后,他慢慢就能分辨出来:这个是猫,那个是狗。
一开始,他可能会认错。
比如把小狗认成猫,把猫认成狐狸。但随着看到的例子越来越多,他会慢慢总结出一些规律:
猫通常有比较明显的胡须;
狗的脸型和耳朵可能不一样;
猫和狗的身体轮廓、眼睛、毛发也有区别。
深度学习其实也是类似的思路。
我们不是直接把所有规则都写死在程序里,而是给模型大量样本,让它自己从数据里总结规律。
这就是深度学习最核心的思想:
不是人手写规则,而是让模型从数据中学习规律。
2. 人工智能、机器学习、深度学习是什么关系?
很多初学者刚开始会分不清这几个词:人工智能、机器学习、深度学习。它们不是三个完全独立的东西,而是一层套一层的关系。
可以简单理解为:
人工智能 AI
└── 机器学习 Machine Learning
└── 深度学习 Deep Learning
人工智能是一个很大的概念,只要是让机器表现出某种“智能”的任务,都可以放到人工智能里面。
例如:
人脸识别
语音助手
自动驾驶
智能推荐
机器翻译
AI聊天机器人
机器学习是人工智能中的一种方法,它的核心是:让机器从数据中学习规律。
而深度学习又是机器学习中的一种重要方法,它主要依靠多层神经网络来自动学习数据中的特征。
可以这样理解:
人工智能是目标,机器学习是一类方法,深度学习是机器学习中非常强大的一种技术路线。

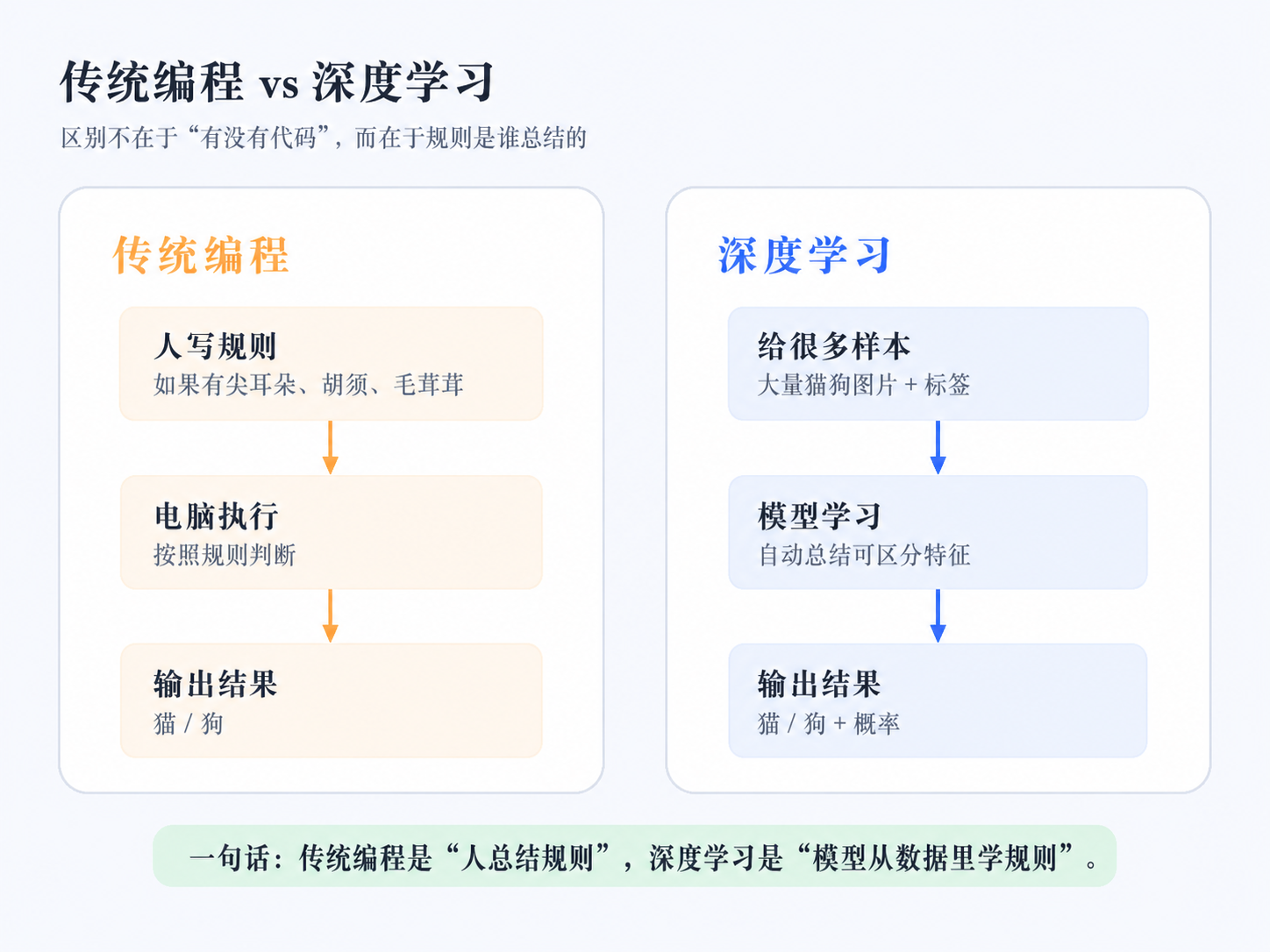
3. 传统编程和深度学习有什么不同?
为了更直观地理解深度学习,我们可以把它和传统编程做一个对比。
传统编程通常是:
人总结规则 → 写成代码 → 电脑执行 → 得到结果
比如我们写一个简单规则:
如果成绩 >= 60,则通过;
否则,不通过。
这个过程里,规则是人写出来的。电脑只是按照规则执行。
但是深度学习不太一样。
深度学习通常是:
给模型大量数据 → 模型自己学习规律 → 输入新数据 → 输出预测结果
比如猫狗分类任务中,我们不需要人工告诉模型:
猫耳朵是什么形状;
狗鼻子是什么形状;
猫和狗的毛发纹理有什么区别。
我们只需要准备大量猫和狗的图片,并告诉模型每张图片的正确答案。经过训练之后,模型会自己学习哪些特征更像猫,哪些特征更像狗。
所以两者最大的区别是:
传统编程:规则由人总结
深度学习:规则由模型从数据中学习
4. 深度学习到底“学”的是什么?
很多人听到“学习”这个词,会觉得模型好像真的像人一样在思考。
其实不是。
模型所谓的“学习”,本质上是不断调整内部参数,让自己的预测结果越来越接近真实答案,这里的参数,可以先简单理解为模型内部的一堆“可调旋钮”。训练模型的过程,就是不断调整这些旋钮,让模型的输出越来越接近正确答案。。
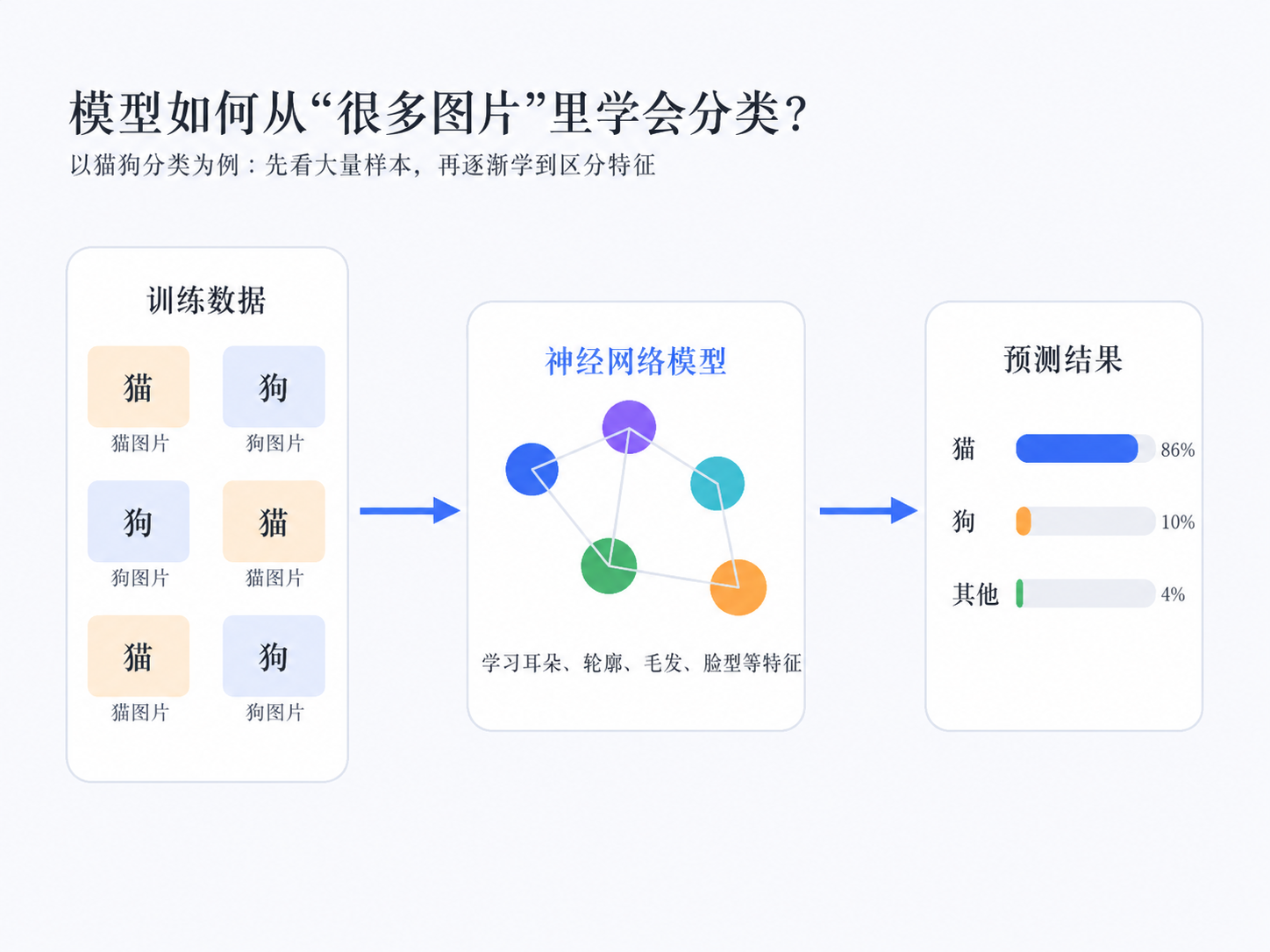
我们还是用猫狗分类举例。
假设我们给模型一张猫的图片,模型第一次预测可能是:
猫:0.20
狗:0.70
其他:0.10
这说明模型觉得这张图更像狗。
但真实答案是猫,所以模型预测错了。
接下来,模型会根据这个错误调整自己的参数。经过很多次训练后,它可能会变成:
猫:0.86
狗:0.10
其他:0.04
这时候模型就更接近正确答案了。
所以深度学习的训练过程,可以简单理解为:
先预测
发现错误
调整参数
再预测
再调整
不断重复
最后,模型就会从大量数据中逐渐学到一些有用的规律。
5. 模型学到的“规律”长什么样?
这也是初学者很容易困惑的地方。
我们人类识别猫狗时,可能会说:
猫有胡须;
狗的鼻子比较明显;
猫的脸比较圆;
狗的体型变化更大。
但神经网络学到的东西不一定会用人类语言表达出来。
在图像任务中,神经网络的浅层可能学到的是:
边缘
颜色变化
纹理
线条方向
简单形状
更深层可能会慢慢组合出:
眼睛
耳朵
鼻子
脸部轮廓
身体结构
完整目标
所以可以把神经网络想象成一个逐层观察图片的系统:
第一层:看边缘和颜色
第二层:看纹理和局部形状
第三层:看眼睛、耳朵、鼻子等部件
更深层:判断这是不是猫、狗、车、人等目标
这也是为什么它叫“深度”学习。
这里的“深度”,主要指的是神经网络有很多层,每一层都在上一层的基础上继续提取更复杂的特征。
6. 为什么深度学习适合处理图片、语音和文本?
因为图片、语音和文本都有一个共同特点:它们很难完全靠人工规则写清楚。比如识别一张猫的图片,如果用传统规则来写,问题会非常复杂:
猫可能是黑色、白色、橘色;
可能正脸、侧脸、背影;
可能坐着、趴着、跳着;
图片可能清晰,也可能模糊;
背景可能是沙发、草地、街道。
如果所有情况都靠人工写规则,几乎不现实。但是深度学习可以通过大量样本自己学习规律。
语音识别也是类似的,不同人的声音、语速、口音都不一样。如果完全靠人工规则,很难覆盖所有情况。文本任务也是一样,一句话的意思往往和上下文有关,不能只靠几个关键词判断。
所以深度学习特别适合处理像图像识别、目标检测、语音识别、自然语言处理、机器翻译、医学影像分析、工业缺陷检测、自动驾驶感知等这些复杂任务:
7. 深度学习是不是只要数据越多越好?
数据很重要,但不是唯一因素,一个深度学习项目通常需要这几个部分:数据、模型、损失函数、优化器、训练策略、评价指标、计算资源。可以先不用理解每个词的细节,后面的文章会一步步拆开讲,今天你只需要先记住:
数据:给模型学习的样本
模型:负责从数据中找规律
损失函数:判断模型错得有多离谱
优化器:负责更新模型参数
评价指标:判断模型最终效果好不好
它们组合起来,就形成了一个完整的深度学习训练流程。
8. 总结
今天我们先不追求记住很多术语,只需要理解几个核心,写到这感觉写的像上课一样,但是今天这个博客确实是没有什么特别有用的知识,也就是先理解深度学习是什么,虽然大家可能已经看了无数遍类似的第一章的介绍,但是我还是要写,要不就不完整了:
1. 深度学习是机器学习中的一种重要方法。
2. 它的核心不是人工写规则,而是让模型从数据中学习规律。
3. 模型一开始并不聪明,需要通过大量样本不断调整参数。
4. 图像、语音、文本这类复杂任务,很适合用深度学习处理。
如果用一句话总结:深度学习就是让模型通过大量数据,自己学习从输入到输出之间的规律。
9. 这个专栏会怎么写
其实这是我第一次写教学类的博客,其实是因为闲着没事,不想做课题,也不想写论文,然后又想到我最开始学深度学习的时候,学的乱七八糟,想找一个有趣的教学也找不到,于是心血来潮想自己写一些,我计划用30篇左右的博客来讲清楚深度学习,至少让初学者能够入门并且看得懂代码,不至于连AI写的代码都看不懂,也不知道专栏起什么名字,就起了个《30天深度学习从入门到实战》,显得比较专业。当然我自己的知识储备也比较有限,希望看到的朋友不要太苛责,可以有问题就骂我,然后我就改,也可以说我写的烂,当然也可以说我拿AI写教学,因为我写的过程中确实会借助AI来帮我组织语言并且丰富细节,也希望通过写这个专栏来增加我的一些对深度学习更深度的理解。
这个系列不会一上来就堆复杂公式,而是按照下面的路线来:
先理解概念-->再看图解-->再写小代码-->再做小项目-->最后进入真实任务和项目复现
当然很多人也会这么写,但是我想的是能够尽量简单的把深度学习讲明白!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)