线性回归核心知识点全解:从基础到模型评估
线性回归核心知识点全解:从基础到模型评估
线性回归核心知识点全解
一、线性回归基础
1. 核心定义
线性回归:利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值) 之间关系进行建模的分析方式。

2. 分类
| 类型 | 公式 | 说明 |
|---|---|---|
| 一元线性回归 | y = wx + b | 目标值仅与一个特征相关 |
| 多元线性回归 | y = w₁x₁ + w₂x₂ + … + wₙxₙ + b | 目标值与多个特征相关 |
3. 应用场景
-
身高预测体重
-
温度预测钢轨伸缩长度
-
昆虫鸣叫次数预测天气
-
GDP 预测双十一销售额
-
房屋特征预测房价
二、线性回归 API 使用(以身高预测体重为例)
1. 核心步骤
-
导入线性回归包
-
准备特征数据 X 与目标数据 y
-
实例化线性回归模型
-
训练模型(fit)
-
模型预测(predict)
-
查看模型参数(斜率coef_、截距intercept_)

2. 代码示例
from sklearn.linear_model import LinearRegression
def dm01_lr预测播仔身高():
# 1 准备数据
x = [[160], [166], [172], [174], [180]]
y = [56.3, 60.6, 65.1, 68.5, 75]
# 2 实例化模型
estimator = LinearRegression()
# 3 训练模型
estimator.fit(x, y)
# 4 查看参数
print('斜率coef_-->', estimator.coef_)
print('截距intercept_-->', estimator.intercept_)
# 5 预测
myres = estimator.predict([[176]])
print('预测结果-->', myres)
三、线性回归求解核心要素
线性回归求解 = 数据 + 模型 + 损失函数 + 优化方法

1. 数据
-
特征值 x、目标值 y
-
假设数据符合线性分布
2. 模型(假设函数)
-
一元:y = wx + b
-
多元:y = w₁x₁ + w₂x₂ + … + b
3. 损失函数
名词解释
-
误差:预测值 − 真实值
-
损失函数:衡量预测值与真实值拟合效果的函数,也叫代价函数、目标函数、成本函数
-
常用:LS(最小二乘)、MSE(均方误差)、MAE(平均绝对误差)
核心目标
找到一组参数,让损失函数最小。
4. 优化方法
-
正规方程法(解析解,直接计算)
-
梯度下降法(迭代求解,逐步逼近)
四、必备数学基础
1. 导数
- 定义:函数在某一点的瞬时变化率
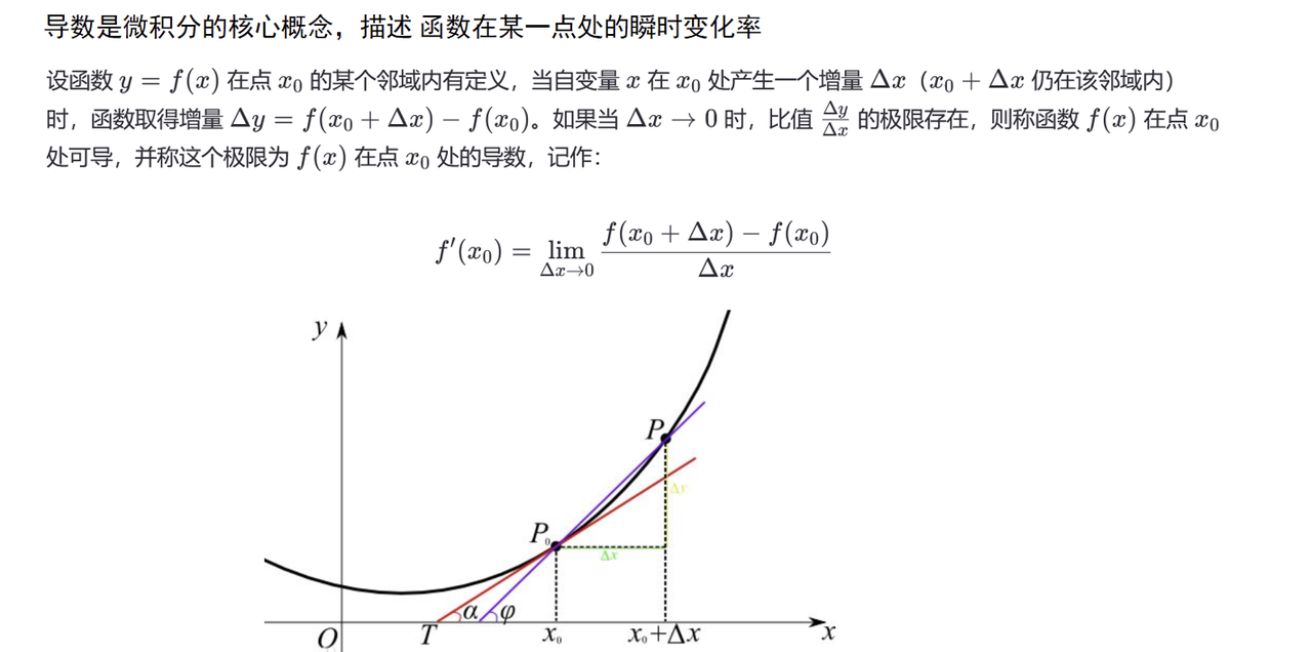
-
几何意义:函数在该点的切线斜率
-
应用:导数为 0 的点是函数极值点


2. 偏导数
-
定义:多元函数中,仅一个变量变化、其余变量固定时的函数变化率
-
计算:把不求导的变量当作常数

3. 向量与矩阵
| 概念 | 说明 |
|---|---|
| 标量scalar | 单个数值,只有大小没有方向 |
| 向量vector | 一列有序元素,有大小和方向,默认是列向量 |
| **矩阵matrix ** | 二维数组,m 行 n 列 |
| **张量Tensor ** | 向量 / 矩阵的高维推广, tensor∈R^2∗3∗4 : 2个3*4矩阵 3个2*4 或4个2*3 |
4. 范数
-
范数(norm)是数学中的一种基本概念,用于度量向量或者矩阵的大小或者长度
-
L1 范数:元素绝对值之和
-
L2 范数:元素平方和开根号(向量模长)
-
p-范数:向量中每一个元素p幂求和,在开p次根

5. 矩阵运算
-
加法 / 减法:对应元素相加减
-
乘法:行 × 列对应相乘再求和

- 单位矩阵 I:A×I = A

- 性质:不满足交换律,满足结合律


五、正规方程法
1. 定义
正规方程法:直接通过矩阵运算求解线性回归最优参数的解析方法,无需迭代。
2. 公式
θ = (XᵀX)⁻¹Xᵀy
-
Xᵀ:X 的转置
-
(XᵀX)⁻¹:XᵀX 的逆矩阵
3. 优缺点
| 优点 | 缺点 |
|---|---|
| 无需学习率 | 特征数大时计算极慢 |
| 无需迭代 | XᵀX 不可逆时无法使用 |
| 无需特征缩放 | 适合小样本、少特征 |
4.正规方程法:多元线性回归完整示例(二元特征)
4.1 设定模型
多元线性回归:y=w0+w1x1+w2x2
给出 4 组样本:
表格
4.2 构造矩阵 X、向量 y
正规方程需要给截距项加一列全 1:
X=111112342345,y=7101316
正规方程公式:w=(XTX)−1XTy
4.3 直接算出结果
最终求得:
w=w0w1w2=212
得到回归方程:y=2+x1+2x2
4.4 验证
代入第一组样本 x1=1,x2=2:
-
y=2+1+2×2=7 ✔️
-
y=2+2+2×3=10 ✔️
-
y=2+3+2×4=13 ✔️
4.5 关键结论
-
正规方程完全可以用于多元(2 个、3 个、任意个特征都行);
-
一元线性回归只是多元的特殊情况;
-
不用梯度下降,直接矩阵一步算出所有权重 w0,w1,w2。
六、梯度下降法
1. 核心思想
沿梯度负方向逐步迭代,逼近损失函数最小值(坡度最陡下山法)。
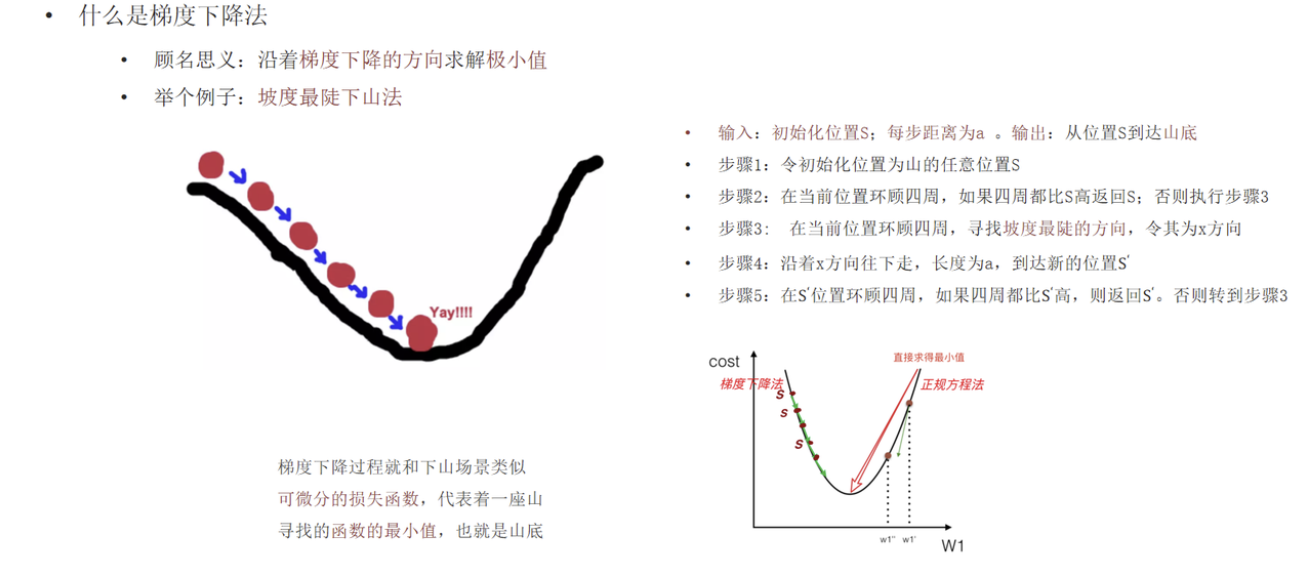
2. 名词解释
-
梯度:单变量 = 导数;多变量 = 偏导数,是函数上升最快的方向
-
学习率 α:每一步迭代的步长,0.001~0.01 常用
3. 更新公式
θ = θ − α × 梯度
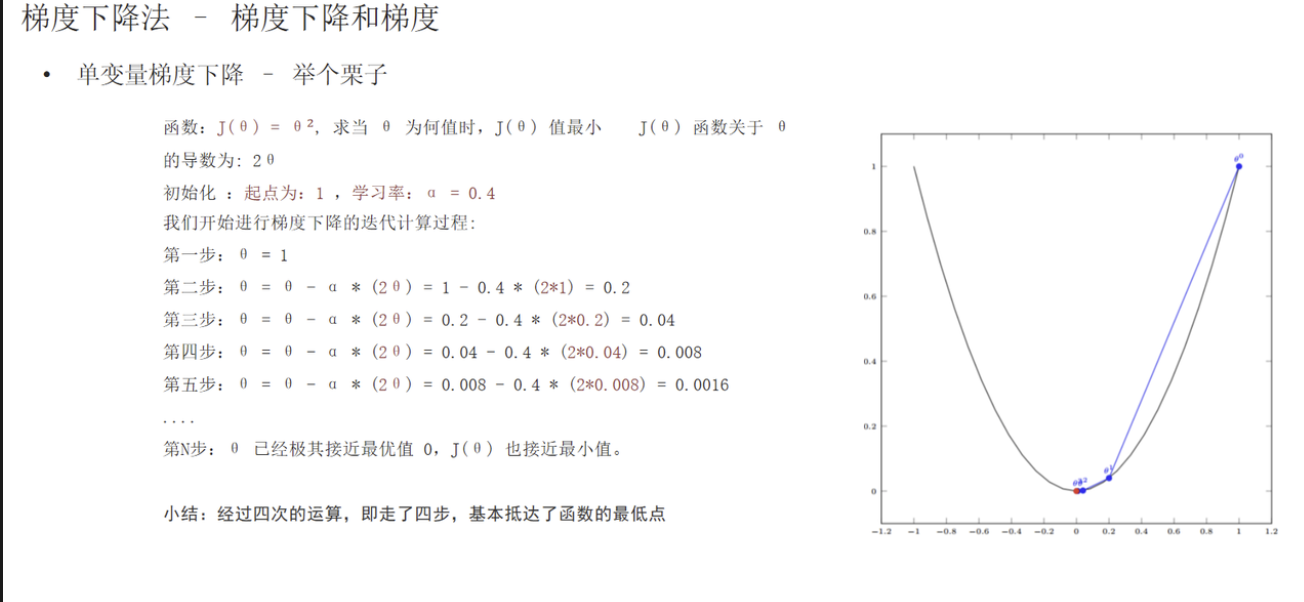
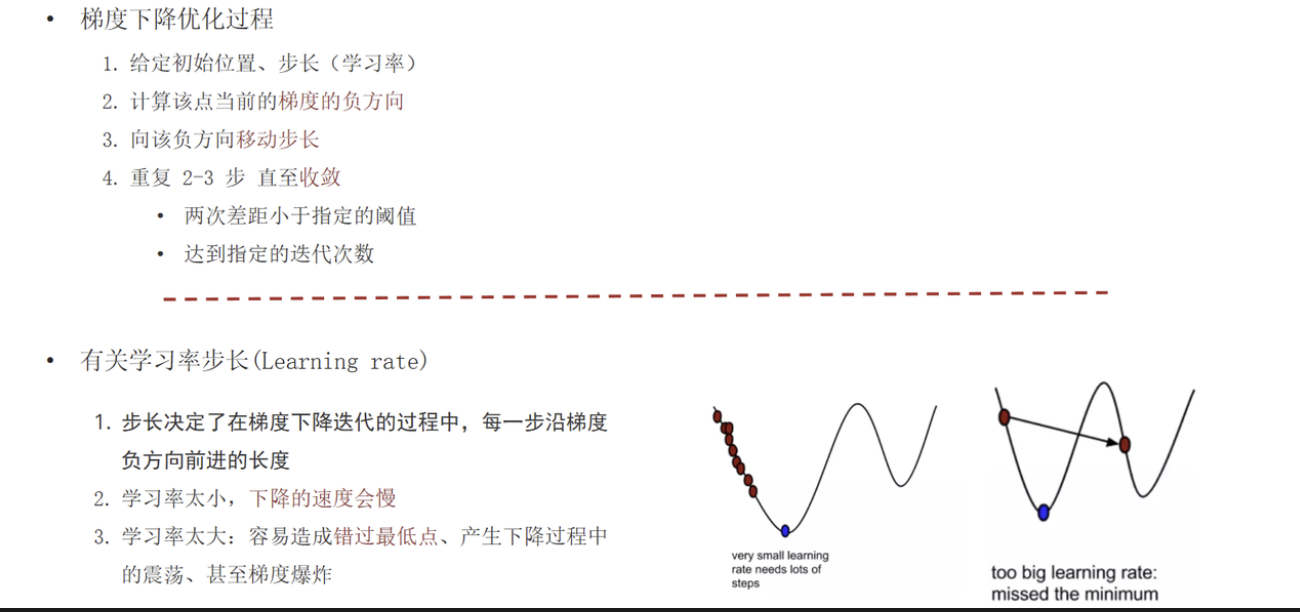
4. 学习率影响
-
太小:收敛慢
-
太大:跳过最小值、震荡、梯度爆炸
5. 算法分类
| 类型 | 特点 |
|---|---|
| 全梯度下降 FGD/BGD | 用全部样本,慢但稳定 |
| 随机梯度下降 SGD | 单样本,快但波动大 |
| 小批量梯度下降 Mini-batch | 小批量样本,工业界最常用 |
| 随机平均梯度下降 SAG | 结合历史梯度,初期慢后期稳 |
七、正规方程 vs 梯度下降
| 对比项 | 正规方程 | 梯度下降 |
|---|---|---|
| 学习率 | 不需要 | 需要 |
| 迭代 | 不需要 | 需要 |
| 特征规模 | 不适合超多特征 | 适合大数据 / 高特征 |
| 适用场景 | 小数据集 | 普适、深度学习主流 |
| 计算方式 | 矩阵求逆 | 迭代更新 |
八、模型评估指标
1. 核心指标
| 指标 | 全称 | 公式 | 特点 |
|---|---|---|---|
| MAE | 平均绝对误差 Mean Absolute Error |
1/n∑|y_true-y_pred | | 平均误差,不放大异常值 |
| MSE | 均方误差 Mean Squared Error |
1/n∑(y_true−y_pred)² | 放大误差,敏感异常值 |
| RMSE | 均方根误差 Root Mean Squared Error |
√MSE | 常用,量纲与目标一致 |
2. 使用建议
-
日常评估:MAE + RMSE 组合
-
RMSE对异常数据敏感
-
MAE对误差大小不敏感
-
MSE会放大预测误差较大的样本的影响
九、Sklearn 线性回归 API
1. 正规方程 API
from sklearn.linear_model import LinearRegression
# 参数:fit_intercept 是否计算偏置
# 属性:coef_ 回归系数;intercept_ 偏置
2. 梯度下降 API
from sklearn.linear_model import SGDRegressor
# 参数:loss 损失函数;learning_rate 学习率策略;eta0 初始学习率
# 属性:coef_ 权重;intercept_ 偏置
十、波士顿房价预测案例
1. 数据说明
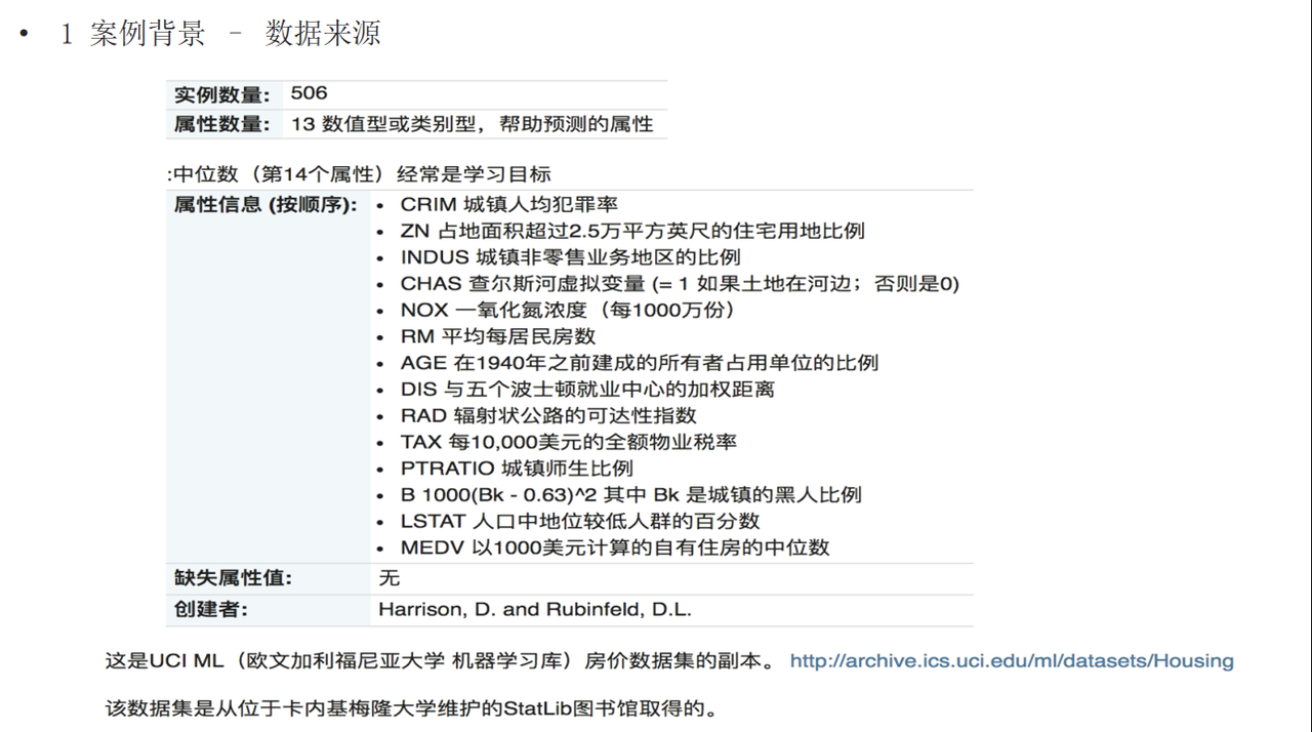
2. 流程
-
加载数据
-
划分训练集 / 测试集
-
特征标准化
-
训练模型(LinearRegression/SGDRegressor)
-
预测与评估(MSE)
3. 核心代码
- 数据获取
from sklearn.linear_model import LinearRegression *# 线性回归:正规方程求解*
from sklearn.linear_model import SGDRegressor *# 梯度下降求解*
*# from sklearn.datasets import load_boston # 提取数据 # 从错误回复中提取如下数据*
import pandas as pd
import numpy as np
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
*# sep="\s+":按任意空格 / 制表符分割#skiprows=22:跳过前 22 行说明文字#header=None:没有表头,纯数据*
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
*# raw_df.values[::2, :], # 偶数行(0,2,4...)所有列*
*# raw_df.values[1::2, :2] # 奇数行(1,3,5...)前2列*
target = raw_df.values[1::2, 2]
*#1::2:取奇数行(1,3,5...) # 2:取第 3 列(索引从 0 开始)*
print("特征",len(data),data)
print('标签',len(target),target)
- 正规方程_波士顿房价预测
*# 0.导包*
from sklearn.linear_model import LinearRegression *# 线性回归:正规方程求解*
from sklearn.linear_model import SGDRegressor *# 梯度下降求解*
*# from sklearn.datasets import load_boston # 提取数据 # 从错误回复中提取如下数据*
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error,mean_absolute_error,root_mean_squared_error
*# 1.获取数据*
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
print("特征",len(data),data)
print('标签',len(target),target)
*# 2.数据预处理*
*# 切割数据*
X_train,X_test,y_train,y_test = train_test_split(data,target,test_size=0.2,random_state=22)
*# 3.特征工程*
*# 标准化*
ss = StandardScaler()
x_train = ss.fit_transform(X_train)
x_test = ss.transform(X_test)
*# 4.模型选择*
*# 可以选择正规方程或者梯度下降*
model = LinearRegression(fit_intercept=True)
*# 5.模型训练*
model.fit(x_train,y_train)
*# 6.模型评估*
*# 方式一:直接评估(底层也是先预测)*
print(model.score(x_test, y_test))
*#方式二:*
y_predict = model.predict(x_test)
print('平方绝对误差:',mean_absolute_error(y_test,y_predict))
print('均方误差:',mean_squared_error(y_test,y_predict))
print('均方根误差:',root_mean_squared_error(y_test,y_predict))
- 梯度下降_波士顿房价预测
*# 0.导包*
from sklearn.linear_model import LinearRegression *# 线性回归:正规方程求解*
from sklearn.linear_model import SGDRegressor *# 梯度下降求解*
*# from sklearn.datasets import load_boston # 提取数据 # 从错误回复中提取如下数据*
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error,mean_absolute_error,root_mean_squared_error
*# 1.获取数据*
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
*# print("特征",len(data),data)*
*# print('标签',len(target),target)*
*# 2.数据预处理*
*# 切割数据*
X_train,X_test,y_train,y_test = train_test_split(data,target,test_size=0.2,random_state=22)
*# 3.特征工程*
*# 标准化*
ss = StandardScaler()
x_train = ss.fit_transform(X_train)
x_test = ss.transform(X_test)
m, n = x_train.shape *# m=样本数,n=特征数*
print(f"训练集:{m}个样本,{n}个特征")
*# 4.模型选择*
*# 可以选择正规方程或者梯度下降*
*# model = LinearRegression(fit_intercept=True)*
model = SGDRegressor(fit_intercept=True,max_iter=1000,loss='squared_error',eta0=0.01,learning_rate='constant') *# 梯度下降,迭代求解*
"""
model = SGDRegressor(
fit_intercept=True, # 1. 要不要学偏置项b?→ 对应我们手写的b!
max_iter=1000, # 2. 最多迭代多少次?→ 对应我们手写的epochs!
loss='squared_error', # 3. 用什么损失函数?→ 对应我们的MSE均方误差!
eta0=0.01, # 4. 学习率是多少?→ 对应我们手写的learning_rate=0.01!
learning_rate='constant' # 5. 学习率策略?→ 固定学习率,和我们手写的一样,全程不变!
)
"""
*# 5.模型训练*
model.fit(x_train,y_train)
*# 6.模型评估*
*# 方式一:直接评估(底层也是先预测)*
print(model.score(x_test, y_test))
*#方式二:*
y_predict = model.predict(x_test)
print('平方绝对误差:',mean_absolute_error(y_test,y_predict))
print('均方误差:',mean_squared_error(y_test,y_predict))
print('均方根误差:',root_mean_squared_error(y_test,y_predict))
十一、知识导图
、
线性回归基础
- 定义:特征→目标建模
- 分类:一元/多元
- 场景:预测连续值
求解四要素
- 数据:X特征/y目标
- 模型:y=wx+b
- 损失函数:误差衡量
- 优化方法:正规方程/梯度下降
数学基础
- 导数:瞬时变化率
- 偏导:多元函数变化率
- 向量/矩阵/范数
优化算法
- 正规方程:解析解,小数据
- 梯度下降:迭代解,大数据
- FGD/SGD/Mini-batch/SAG
模型评估
- MAE/MSE/RMSE
Sklearn API
- LinearRegression(正规方程)
- SGDRegressor(梯度下降)
实战案例
- 波士顿房价预测```
十二、全章总结
-
线性回归是连续值预测的基础算法,分一元与多元。
-
求解核心是最小化损失函数,两种主流方法:正规方程(小数据)、梯度下降(大数据 / 深度学习)。
-
梯度下降中小批量梯度下降最常用,学习率是关键超参。
-
模型评估优先用MAE+RMSE,可直观反映预测误差。
-
Sklearn 提供封装好的 API,可快速完成建模、训练、预测、评估全流程。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)