探索OCR第四个方案:PP-OCRv5
1. 写在前面
前三篇探索OCR方案的文章,主要是发表在去年的四月份。时光飞逝,一年后的今天,科技的飞速发展让人目不暇接,OCR领域也是成果满满,让人叹为观止。
PaddleOCR的发展依然不错,截至2026年初,PaddleOCR在GitHub上已获得超过7.33万星标,问鼎全球OCR项目榜首。同时,凭借 70,000+ Stars的成绩,PaddleOCR 已获得 Dify、RAGFlow、Cherry Studio 等顶级项目的广泛信赖,是构建智能 RAG 和 Agentic 应用的核心基础组件。
2. PP-OCRv5强在哪里
一句话重点:在内部多场景复杂评估集上,PP-OCRv5较PP-OCRv4端到端提升13个百分点。同时,PP-OCRv5在手写体、竖排文本、生僻字等复杂场景下的表现也有质的飞跃。
一句话总结:你的OCR工具箱中,可以把PP-OCRv5放入其中,并作为默认的OCR工具了。
如果你正在做OCR技术选型,那么恭喜你,这篇文章最适合你了。
3. 快速上手:5分钟搭建OCR识别环境
3.0 python创建虚拟环境
为了不陷入版本地狱,还是用虚拟环境做项目隔离。可以使用自己喜欢的方式,conda也好,venv也好。
# 创建并激活虚拟环境
python -m venv ocr_env
source ocr_env/bin/activate # Linux/Mac
ocr_env\Scripts\activate # Windows
3.1 先安装paddlepaddle
5060Ti的PC要确认CUDA的版本,才能安装对应的paddlepaddle。
nvidia-smi
Wed May 6 10:58:12 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 576.88 Driver Version: 576.88 CUDA Version: 12.9 |
|-----------------------------------------+------------------------+----------------------+
官网找到对应的命令:
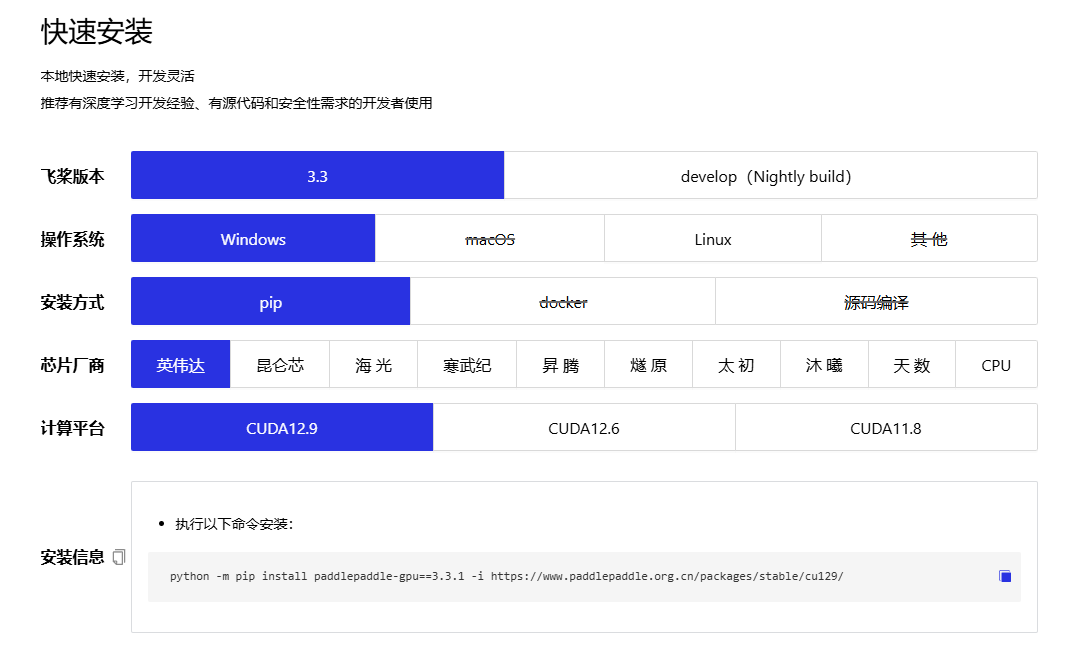
pip install paddlepaddle-gpu==3.3.1 -i https://www.paddlepaddle.org.cn/packages/stable/cu129/
考验网速的时候到了,我这边安装完毕花了1分钟:
Installing collected packages: typing-extensions, setuptools, safetensors, protobuf, Pillow, nvidia-nvjitlink-cu12, nvidia-curand-cu12, nvidia-cuda-runtime-cu12, nvidia-cublas-cu12, numpy, networkx, idna, h11, certifi, opt-einsum, nvidia-cusparse-cu12, nvidia-cufft-cu12, nvidia-cudnn-cu12, httpcore, anyio, nvidia-cusolver-cu12, httpx, paddlepaddle-gpu
Successfully installed Pillow-12.1.0 anyio-4.12.1 certifi-2026.1.4 h11-0.16.0 httpcore-1.0.9 httpx-0.28.1 idna-3.11 networkx-3.6.1 numpy-2.4.1 nvidia-cublas-cu12-12.9.0.13 nvidia-cuda-runtime-cu12-12.9.37
nvidia-cudnn-cu12-9.9.0.52 nvidia-cufft-cu12-11.4.0.6 nvidia-curand-cu12-10.3.10.19 nvidia-cusolver-cu12-11.7.4.40 nvidia-cusparse-cu12-12.5.9.5 nvidia-nvjitlink-cu12-12.9.86 opt-einsum-3.3.0 paddlepaddle-gpu-3.3.1 protobuf-6.33.4 safetensors-0.7.0 setuptools-80.9.0 typing-extensions-4.15.0
3.2 再安装PaddleOCR
pip install "paddleocr[all]"
4、验证安装与首次识别
from paddleocr import PaddleOCR
# 初始化OCR引擎,使用PP-OCRv5模型
ocr = PaddleOCR(use_angle_cls=True, lang='ch', ocr_version='PP-OCRv5')
# 图片路径
img_path = '../pic002.png'
# v4中的ocr方法变成了predict,这与yolo等库的使用更相似了
result = ocr.predict(img_path)
if result and len(result) > 0:
# result[0] 就是一个字典(或可当字典用的对象)
ocr_data = result[0]
# 直接通过键名获取数据
rec_texts = ocr_data['rec_texts']
rec_scores = ocr_data['rec_scores']
dt_polys = ocr_data['dt_polys']
# 打印识别结果
print("\n=== 识别结果 ===")
for i, (text, score) in enumerate(zip(rec_texts, rec_scores)):
print(f"{i + 1}. 文字: {text}, 置信度: {score:.4f}")
try:
ocr_data.save_to_img(save_path='result.jpg')
print("\n可视化结果已保存为 result.jpg")
except:
print("保存可视化失败,可以手动绘制")
else:
print("未识别到任何内容")
程序执行后会自动下载server v5版本的模型:
C:\Users\Administrator\.paddlex\official_models\PP-OCRv5_server_rec
C:\Users\Administrator\.paddlex\official_models\PP-OCRv5_server_det
PP-OCRv5_server_det目录是文本检测模型 (Detection Model),它的任务是分析整个输入图像,定位出所有包含文字的区域,并用多边形(通常是四边形)的坐标框将它们标记出来。
PP-OCRv5_server_rec目录是文本识别模型 (Recognition Model),它接收检测模型切出来的文字行图片,识别图片中的具体字符序列,并输出对应的文本内容。
两个模型都是80多MB大小,使用GPU推理速度还可以。
结果打印:
=== 识别结果 ===
1. 文字: 中文识别, 置信度: 0.9997
2. 文字: 高级应用场景, 置信度: 0.9994
3. 文字: 结构化数据提取, 置信度: 0.9997
我们解析结果,将文本内容和置信度打印出来,并将识别结果保存到图片中,如下图:

5、最后
时隔一年,有了v4的使用经历再次安装v5,在API的使用上也有了些许改变,识别的能力也更加强大了。很多场景比如技术选型、科研、学术,直接用PaddleOCR原生推理是最省事的选择。如果要脱离Paddle框架,可以选择使用onnx模型,这在用C++、C#做开发的场景就更加适合。后面我会找时间使用纯onnx方式做识别的部署。
下期再见!
参考
- https://www.paddleocr.ai/latest/version3.x/pipeline_usage/OCR.html#21
- https://www.paddleocr.ai
- https://github.com/PaddlePaddle/PaddleOCR.ai/latest/version3.x/pipeline_usage/OCR.html#21
- https://www.paddleocr.ai
- https://github.com/PaddlePaddle/PaddleOCR

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)