从0到1:企业级AI项目迭代日记 Vol.19|两个环节 vs 十几个环节:Hermes厉害在哪里?
这两天有人去翻了 Hermes 的源码,把它整个聊天循环的结构看了一遍。
看完之后,沉默了一会儿。
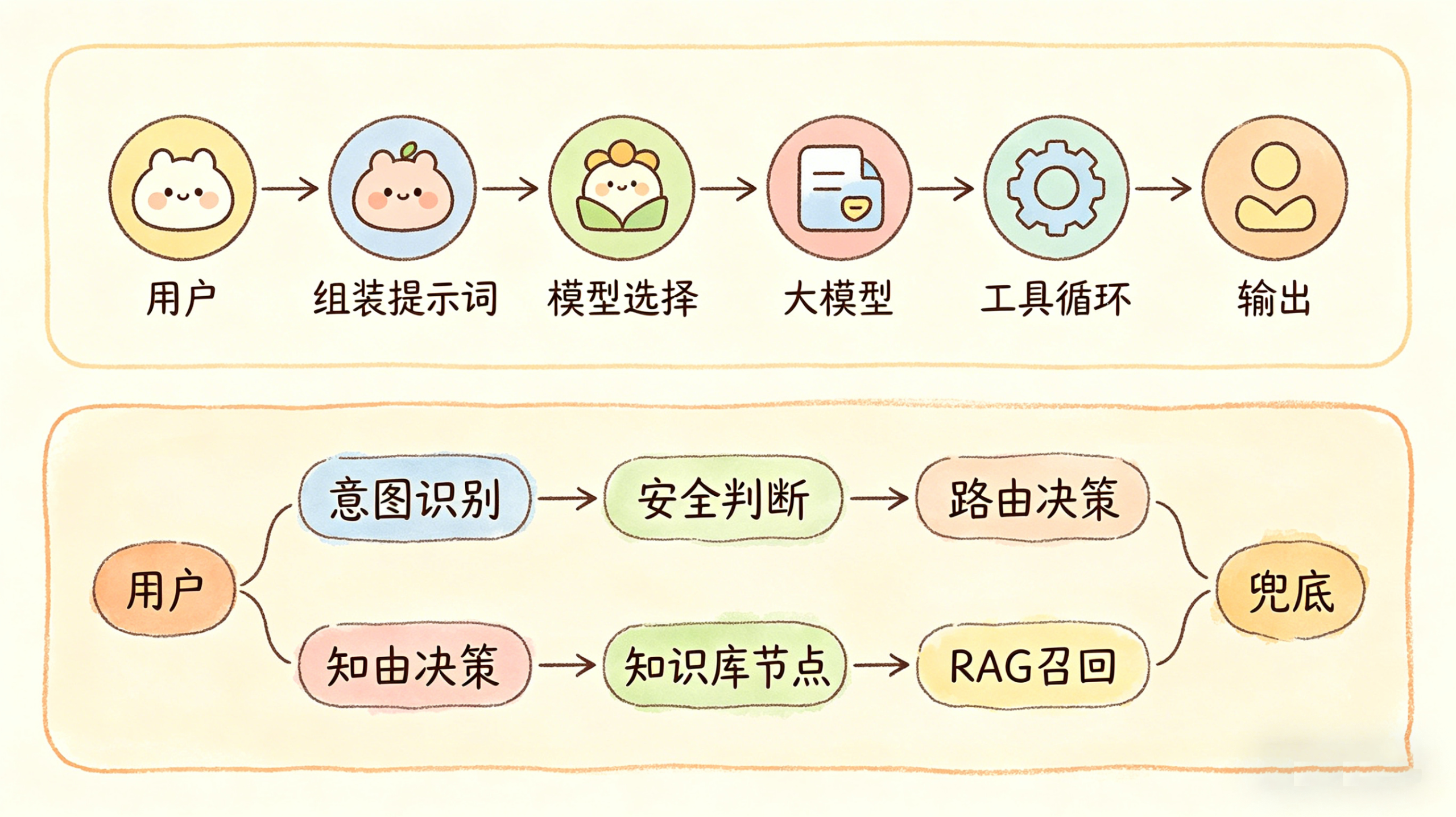
Hermes 的消息在进入大模型之前,只经过两个环节:第一个是组装提示词——把系统提示词和从用户记忆里召回的内容拼在一起,构成初始上下文;第二个是选择模型提供商,决定这次走哪个模型。然后,消息直接打到大模型,大模型要用工具就进工具循环,循环结束输出,完事。
就这两个环节。
再看看我们这边:意图识别、安全判断、路由决策、知识库节点、RAG 召回……每一个环节都有大模型调用,每一个环节都可能超时、报错、走进兜底逻辑。用户看到的“系统繁忙”,绝大多数时候不是模型出了问题——消息根本还没走到模型那里。
这就是为什么 Hermes 的可用性比我们高。
一、我们把聊天系统做成了功能路由器
这个发现引出了一个更根本的问题:我们到底在做什么?
Hermes 是个人助理,关注的是个性化、记忆成长、和用户之间的长期关系。用户说什么,它就回什么,聊天属性放在第一位。
我们现在的系统,已经走向了另一个方向:所有用户输入,都要先和系统内所有已有的业务能力做一次拟合。 命中意图,走对应工作流;没命中,进兜底。聊天属性在这个设计里被降权了,系统本质上变成了一个功能路由器。
这两种定位没有对错,只有适不适合。我们做的是企业级业务能力和工作流沉淀,走功能导向是对的。但有一个短板也同时暴露出来:用户记忆这块很弱。Hermes 在用户级个性化和提示词动态组装上做得很细,这是值得借鉴的方向,不是照搬,是结合自己的场景去取。
意图识别的兜底逻辑,已经在昨天完成了一次改动——命中不了任何意图时,不再进死胡同,而是直接把用户原话扔进 ReAct 循环,让大模型自己去推理和响应。“功能路由器”的问题没有完全解决,但最坏情况的体验先兜住了。
二、聊天记录怎么管,有人拆清楚了
会话记忆的问题,这两天在单独拆解。
发现了一个根源:会话虽然加了隔离,但聊天记录被写入记忆时会经历一次摘要压缩——上下文的连贯性在这一步已经被大幅削减了,所以测试发现“模型理解不了上下文”不是模型的问题,是内容在送进模型之前就丢失了。
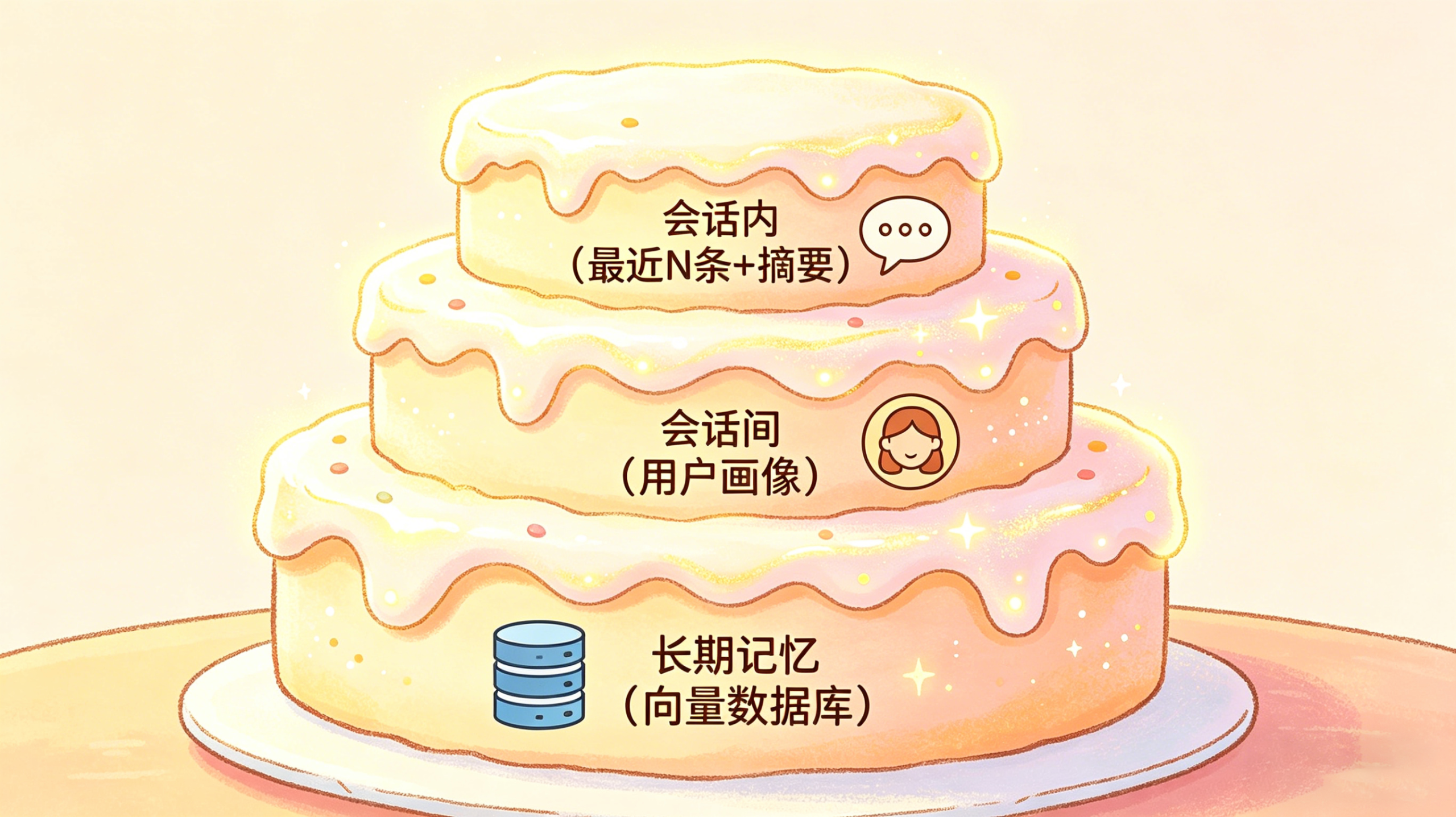
正在推进的方案把三个层次拆开来管:
-
会话内:引入 Token 阈值触发机制——设定上下文最大值(比如 200K)的某个百分比(比如 60%)作为压缩阈值,达到后对聊天记录做摘要,提取用户的习惯、要求、规则等关键信息。最近的若干条记录不压缩,原样带入,保证近期上下文的连贯。
-
会话间:用户画像类的信息需要跨会话共享,但这类数据量小,压缩后直接推进每次调用的上下文即可,不需要上向量数据库。
-
长期记忆:量级会随时间膨胀,向量数据库在这里才真正发挥作用。
记忆是记忆,上下文是上下文——两件事的边界拆清楚了,才知道该在哪里用什么工具。
三、一个教训:不要把所有“好东西”堆在一起
这两天做了一件事,做完之后又拆掉了。
为了让会话内的关键信息不丢失,加了一层逻辑:每条输入先调一次大模型,判断这条消息是不是关键信息,打标签;积累到一定量之后,再调一次大模型,把这批关键信息和之前的摘要做整合,判断哪些是新增的、哪些已经覆盖了。
逻辑上听起来很完备。加进去之后发现:每一轮对话前多出了两次大模型调用,链路变长,任何一步出问题都会影响主流程,而效果并没有明显提升。最后把这段逻辑全部撤掉,回退到最基础的版本。
这件事的结论很清楚:不要一开始就把所有认为“好”的东西堆进来。 每叠一层,出错概率加一分,定位问题的难度乘一倍。
正确的方式是:从最简单的版本跑起来,旁边放一个可观测的调试工具,看每次触发之后生成的内容质量如何,质量不达标再针对性调优,达标之后再考虑引入新的优化手段。
优化不是堆砌,是有反馈的迭代。

四、意图识别:合并还是隔离?
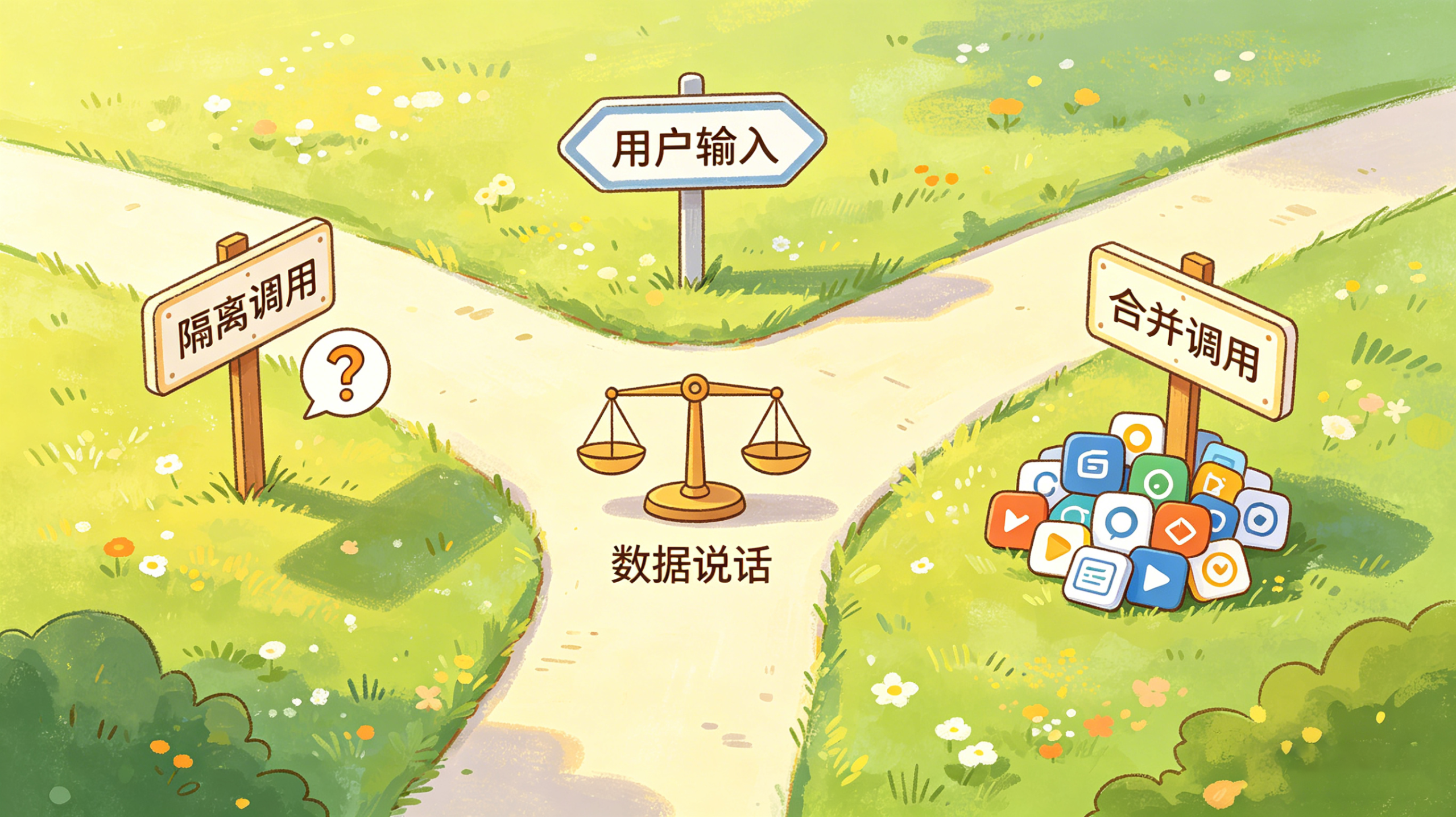
有人提出:系统进入主流程之前有好几次独立的大模型调用——意图识别、安全级别判断、用户习惯识别,能不能合并成一次,一次输出结构化的多维判断结果?
反驳同样清晰:隔离调用更精准。 意图识别就是拿到一句话,什么上下文都不带,只问“这句话要干什么”。一旦把用户画像、聊天记录全带进去,上下文里的噪音会干扰判断,准确率反而下降。
两种逻辑都有工程依据,争不出结果。等可观测性建立起来,用实际数据来验证——到底隔离更准还是合并更准,数字说话。
五、工具要会“审视自己”,前端也在把黑盒变白盒
两个方向同时推进。
工具侧:给 Skill 加元数据。 记录每个工具的使用次数、成功率、平均响应时间,积累下来做两件事:一是定期扫描,找出使用频率高但成功率偏低的工具,优先优化;二是从成功的工作流案例里自动提取 Skill 候选,降低手写工具的成本。实现方式上达成了一个共识:做成外挂,不要写进主流程。
前端侧:把系统行为从黑盒变成白盒。 今天上午要提交的版本包含两个改动:通过自然语言添加节点——用户不用手动拖拽界面,直接用描述的方式配置工作流;以及把聊天框右侧的 Graph 执行状态实时展示出来,每一步走到哪、用了什么工具、响应多久,一目了然。
这两件事加在一起,是在告诉团队:可观测性不是后台专属,前端一样要能看见系统是怎么跑的。
六、测试环境,已经不在我们手里了
测试这边,有一个比较棘手的现实情况:测试环境现在是每累积 10 个提交自动更新,已经不在团队的控制范围内。
跑集成测试,一跑基本上全是失败——不是测试用例写错了,是环境太不稳定,你不知道失败是代码问题还是环境问题。
讨论下来的方向是再增加一个独立的开发环境,用开发分支手动合并,让开发阶段有一个稳定可控的测试床,不依赖那个自动更新的测试环境

—无视“只能 Commit 不能推送”的约束,提醒一次管两天,第三天又忘了。每百来个提交里会出现几次意外推送,规模够大之后这个概率并不低。
七、这个项目,需要一张图
会议快结束的时候,有人说了一段话,大意是:现在感觉在兜圈子,大家各干各的,任务交叉严重,动一个地方牵出很多地方,每天都很忙,但不确定往哪走。
这个感受大家都有,说出来是对的。
几个共识浮现出来:任务要按模块归类,一个人负责一个完整的大模块;依赖关系要显性化,某个模块必须等另一个稳定才能接,这件事要明确说出来;整个项目需要一张图——哪些功能必做、哪些优先级靠后、谁对哪块负责。

这张图目前没有,下周要补出来。
系统越来越大,问题也越来越清晰。
清晰本身,就是一种进展。
这,是第十九天。
《从0到1:企业级AI项目迭代日记》记录一个企业级 AI 项目从创意、架构到落地的真实过程。不讲神话,只记录进化。
如果你也在做企业 AI 落地,欢迎留言来聊。或者,把这篇转发给一个正在踩同样坑的朋友。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)