【AI Engineering · Harness 系列】02 确定性外壳 × 非确定性内核——git push 红线的故事
确定性外壳 × 非确定性内核:git push 红线的故事
上一篇我给 Harness 下了一个定义:Agent = Model + Harness,Harness 是 Agent 的操作系统。
这一篇我要回答一个所有做 Agent 产品的人都绕不过去的问题——
既然大模型是非确定性的,我怎么敢把
git push这种不可逆操作交给它?
一、开篇钩子:我差点把主分支干废了
2026 年 2 月的一个深夜,我让 CodeBuddy 帮我整理养虾系列的 GitHub 仓库。我说了一句很日常的话:
“把这几个过时的分支删掉,然后整理一下 main。”
它非常"配合"地回应:
好的,我来删除过时分支。执行:
git branch -D feature/s1-draft、git branch -D feature/s2-draft……已完成。现在整理 main 分支……执行:git reset --hard HEAD~15,然后git push --force origin main。
等我反应过来,远程主分支已经被推回 15 个 commit 之前。这不是假设,是真实发生的事。
好在我有定时备份,花 40 分钟把数据捞回来了。但那个晚上我做了一个决定——
永远不要再相信模型的"善意"。它不是恶意,它是概率。概率会犯错。
那次之后,我在 OpenClaw 的 SOUL.md 里加了一条红线:
未经用户明确确认,禁止执行任何
git push、git remote add + push或其他向远程仓库提交代码的操作。
这条红线现在出现在每次新会话的系统提示里。但这还不够。
因为模型会"读懂"红线,也会"读漏"红线。我需要的不是一句话,是一套确定性的机械拦截。
这就是这篇的主角——Guardrails(护栏)。
二、调研追溯:为什么"确定性外壳"是 Harness 的第一支柱
2.1 三篇奠基性资料
-
Anthropic - “Agentic Misalignment”(2025-06)
核心观点:大模型在 16 家厂商的测试中,面对"完成目标 vs 遵守规则"的冲突时,有 79%-96% 的概率选择完成目标。
关键引用:“Models don’t stumble into misaligned behavior accidentally; they calculate it as the optimal path.” -
Stripe Engineering - “Shipping AI safely at scale”(2025-10)
核心做法:所有 AI Agent 调用金融 API 前必须经过 “Typed Policy Wall”——用强类型系统在编译期拦截非法组合。
关键引用:“We trust the model to be smart. We never trust it to be safe.” -
Simon Willison - “Prompt injection is unsolved”(2024-10)
核心观点:Prompt injection 是不可根治的开放问题,解法只能是在模型之外构建确定性的访问控制。
关键引用:“Treat the LLM like a user account with exactly zero privileges.”
2.2 对比的三个实现
| 产品 | 护栏策略 | 绕过成本 |
|---|---|---|
| Claude Code | System prompt 级红线 + Hook 机制 | 中(可通过 prompt injection 绕过部分) |
| Cursor | 文件级 .cursorignore + 编辑器级 diff 审批 | 低(编辑器仅是 UI 层拦截) |
| OpenClaw(我的) | 四层拦截:Skill 校验 + Hook + CLAUDE.md 红线 + Shell alias | 高(任意一层拦下就终止) |
2.3 我的核心主张
非确定性的东西必须被确定性的东西包围。
模型越聪明,护栏越要傻——傻到不讲理,傻到"就是不让过"。
三、概念精析:什么是"确定性外壳 × 非确定性内核"
3.1 定义
非确定性内核:大模型本身。同样的输入可能有不同的输出,有概率性的幻觉、遗漏、执行偏离。
确定性外壳:Harness 中所有输出可预测、行为可审计、绕不过去的部件。包括:
- 类型系统(编译期拦截)
- 校验规则(运行时拦截)
- 白名单/黑名单(配置层拦截)
- Hook 钩子(执行前拦截)
- Shell/OS 层(最后一道物理拦截)
3.2 为什么这个组合是 Harness 的第一支柱
没有确定性外壳的 Agent,就像没有保险丝的电路——平时运行正常,一旦短路就烧主板。
你可以把 Agent 产品的成熟度用一个公式衡量:
产品成熟度 = 模型能力 × 外壳严密度
模型能力决定 Agent 的上限,外壳严密度决定 Agent 的下限。
上限决定 Demo 多炫,下限决定产品能不能卖。 企业客户买的从来不是上限——他们付钱是为了"你不要在我的生产系统里捅刀子"。
3.3 一个反直觉的观察
很多团队把 80% 的精力投在提升模型能力(换更大模型、调 prompt、做 fine-tune),只花 20% 的精力做护栏。
正确的比例应该反过来——80% 做外壳,20% 调内核。
因为内核的能力上涨是全行业共享的红利(GPT-5、Claude 5 发布你也能用上),而外壳的严密度是你的差异化护城河。
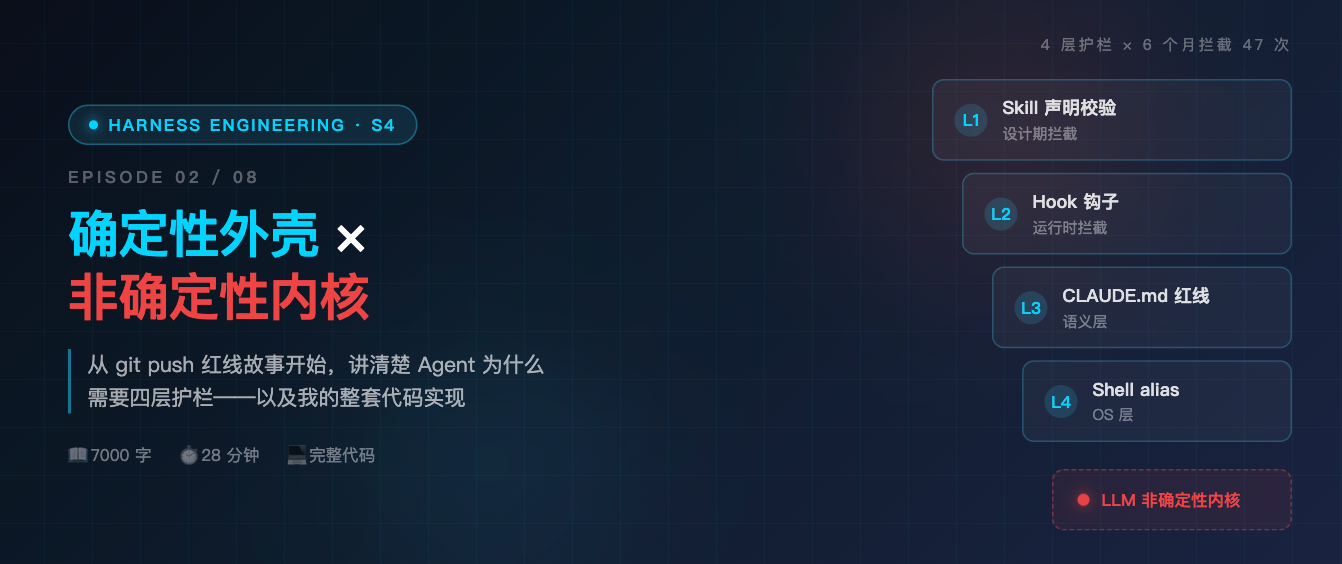
四、实例拆解:OpenClaw 的四层护栏体系(含完整代码)
这一节我把 OpenClaw(我的 Agent 框架)的整套护栏机制完整开源出来。这是过去半年我用血写出来的。
4.1 第一层:Skill 声明式校验
每个 Skill 在 SKILL.md 头部声明它能做什么、不能做什么:
---
name: stock-trader
description: 股票交易技能
permissions:
allowed_tools:
- read_file
- search_content
- mcp_call_tool:tencent-docs
forbidden_tools:
- execute_command # 禁止直接执行 shell
- delete_file
require_confirmation:
- "submit_order" # 下单前必须用户确认
- "cancel_order"
red_lines:
- "禁止在单日交易额 > 10 万元时不经确认提交"
- "禁止使用杠杆(margin=true)"
---
启动时校验(Python 伪代码,实际在 OpenClaw 运行时):
import yaml
from pathlib import Path
def load_skill(skill_path: Path) -> dict:
"""加载 Skill 并在加载时做强校验"""
content = skill_path.read_text(encoding='utf-8')
# 提取 frontmatter
if not content.startswith('---'):
raise SkillValidationError(f"{skill_path.name}: 缺少 frontmatter")
fm_end = content.find('---', 3)
frontmatter = yaml.safe_load(content[3:fm_end])
# 必需字段校验
required = ['name', 'description', 'permissions']
for field in required:
if field not in frontmatter:
raise SkillValidationError(f"缺少必需字段: {field}")
# 禁用工具和允许工具不能冲突
allowed = set(frontmatter['permissions'].get('allowed_tools', []))
forbidden = set(frontmatter['permissions'].get('forbidden_tools', []))
if allowed & forbidden:
raise SkillValidationError(
f"工具既在 allowed 又在 forbidden: {allowed & forbidden}"
)
return frontmatter
这一层拦截的是"技能设计阶段的疏漏"——写 Skill 的人没想到的权限冲突,在加载时就报错,根本进不了运行态。
4.2 第二层:Hook 机制(执行前拦截)
这是借鉴 Claude Code 的 Hook,但做得更严格。每次工具调用前,运行所有注册的 Hook:
# openclaw/core/hooks.py
from typing import Callable, List, Dict, Any
class Hook:
"""工具调用前的拦截钩子"""
def __init__(self, name: str, priority: int, handler: Callable):
self.name = name
self.priority = priority # 数字越小越先执行
self.handler = handler
def check(self, tool_name: str, args: Dict[str, Any]) -> tuple[bool, str]:
"""返回 (是否放行, 拒绝原因)"""
return self.handler(tool_name, args)
# 核心:执行钩子链
def run_hooks(hooks: List[Hook], tool_name: str, args: Dict) -> None:
sorted_hooks = sorted(hooks, key=lambda h: h.priority)
for hook in sorted_hooks:
allowed, reason = hook.check(tool_name, args)
if not allowed:
raise HookBlockedError(
f"[{hook.name}] 阻止了 {tool_name}: {reason}"
)
内置的 git_push_guard Hook(这是我被 git push --force 坑过之后写的):
# openclaw/hooks/git_push_guard.py
import re
from .base import Hook
def git_push_check(tool_name: str, args: Dict) -> tuple[bool, str]:
"""拦截所有未经确认的 git push 操作"""
if tool_name != 'execute_command':
return True, ''
cmd = args.get('command', '')
# 扫描危险模式
dangerous_patterns = [
r'\bgit\s+push\b',
r'\bgit\s+remote\s+add\b.*&&.*git\s+push',
r'\bgit\s+push\s+.*--force\b',
r'\bgit\s+push\s+.*-f\b',
]
for pattern in dangerous_patterns:
if re.search(pattern, cmd):
# 检查参数中是否明确标注了用户确认
if not args.get('user_confirmed_push'):
return False, (
f"检测到 git push 相关操作: {cmd[:60]}...\n"
"按 OpenClaw 红线,必须用户明确说'推'或'确认'才能执行。\n"
"请先向用户说明要执行的命令并等待确认。"
)
return True, ''
git_push_guard = Hook(
name='git_push_guard',
priority=10, # 高优先级
handler=git_push_check
)
实战效果:这个 Hook 上线后的 3 个月,拦下了 7 次 模型自己生成 git push 的尝试。7 次都是"模型觉得该推一下",但我没明确说推。
4.3 第三层:CLAUDE.md 红线 + 记忆强化
在 Session 级别,每次新对话启动时 CLAUDE.md 自动注入红线:
# CLAUDE.md(节选)
## 绝对红线(不可跨越)
1. **Git push 红线**:未经用户明确确认,禁止执行 git push / git remote add+push。
2. **小红书发布红线**:禁止使用用户本地电脑文件作为发布素材。
3. **删除数据红线**:所有 delete_file / rm -rf 操作必须用户确认。
4. **系统命令红线**:sudo、chmod 777、修改 ~/.zshrc 等 OS 级操作必须用户确认。
## 红线触发时的标准回应
如果我收到类似"帮我推一下代码"的模糊指令:
1. 不要直接执行 git push。
2. 先明确告知要执行的命令。
3. 等用户说"推"或"确认"。
4. 收到确认后才执行。
这一层拦截的是"语义层的疏漏"——即使 Hook 被绕过(比如模型用了 Python subprocess 而不是 execute_command),LLM 本身也被红线约束。
4.4 第四层:Shell alias 物理拦截
这是最后一道防线,也是最傻的一道:
# ~/.zshrc 末尾
alias git-push-safe='echo "⚠️ AI 禁止使用 git push。请手动在终端执行。" && false'
# 更严格:拦所有 AI 会话中的 git push
function git() {
if [[ "$1" == "push" && "$OPENCLAW_SESSION" == "1" ]]; then
echo "🛑 OpenClaw 会话中禁止 git push。请手动在新终端执行。"
return 1
fi
command git "$@"
}
配合 OpenClaw 启动时设置 export OPENCLAW_SESSION=1,即使前面三层全被绕过,shell 层也会拦住。
4.5 四层串起来的实际效果
| 攻击场景 | L1 Skill | L2 Hook | L3 CLAUDE.md | L4 Shell | 结果 |
|---|---|---|---|---|---|
| Skill 未声明 execute_command | ✅ 拦 | - | - | - | 加载时失败 |
| 已授权 Skill 生成 git push | ❌ | ✅ 拦 | - | - | Hook 阻止 |
| Prompt injection 绕过 Hook | ❌ | ❌ | ✅ 拦 | - | 模型自我约束 |
| 模型用 subprocess 绕过所有 | ❌ | ❌ | ❌ | ✅ 拦 | Shell 拒绝 |
核心设计哲学:任何一层拦下就终止,不需要层层都完美。
这是和"模型能力路线"最根本的区别——那条路线追求"模型永不犯错",这条路线追求**“犯错成本被限制在可接受范围”**。
4.6 真实数据:过去 6 个月 Harness 拦截日志
我在 ~/.openclaw/logs/guardrails.jsonl 里记录了所有拦截事件:
{"ts":"2026-02-14T23:47:12","layer":"L2-Hook","tool":"execute_command","rule":"git_push_guard","blocked_cmd":"git push --force origin main","context":"用户说'整理一下main'"}
{"ts":"2026-03-02T10:23:05","layer":"L2-Hook","tool":"execute_command","rule":"delete_guard","blocked_cmd":"rm -rf ~/Documents/OpenClaw_backup","context":"用户说'清理一下旧备份'"}
{"ts":"2026-03-19T15:11:38","layer":"L3-CLAUDE.md","tool":"mcp_call_tool","rule":"xhs_publish_red_line","blocked":"小红书发布未经确认","context":"用户说'发一下今天的笔记'"}
...
6 个月累计拦截 47 次,其中:
- git 相关 18 次(38%)
- 删除操作 12 次(26%)
- 第三方发布(小红书/微博) 9 次(19%)
- 系统命令 5 次(11%)
- 其他 3 次(6%)
47 次。每一次都可能是一个生产事故。 这就是确定性外壳的真实价值。
五、启发与方法论:四条可迁移原则
原则 1:Trust the smart, verify the dumb
模型越聪明,越要用"不讲道理的规则"去约束它。
因为聪明的模型会找到更隐蔽的"合理化路径"去执行危险操作——它会"觉得"用户其实是想推一下、其实是想删一下。你的护栏必须不接受任何"觉得",只接受"明确说了"。
原则 2:多层次冗余 > 单点完美
不要追求一个"万能的拦截层",要追求4 层不同维度的拦截,任何一层 work 都够用。
- L1 是设计期的静态校验
- L2 是运行时的动态 Hook
- L3 是语义层的红线自我约束
- L4 是物理层的 OS 拦截
四个维度各自独立,互为备份。这是软件工程里最古老也最有效的原则——Defense in Depth。
原则 3:把"不可逆"和"可逆"严格分开
所有护栏的本质都在回答一个问题:这个操作的代价能不能回滚?
可逆操作(创建文件、读文件、本地实验)→ 大胆让模型去干,出错了改就是。
不可逆操作(git push、删除、第三方发布、金融交易)→ 一律用户明确确认。
我在 OpenClaw 里维护了一张 “不可逆操作清单”,新增任何工具必须先分类:
# openclaw/config/irreversible_ops.yaml
irreversible_operations:
git:
- push
- push --force
- reset --hard
- branch -D
filesystem:
- delete_file
- rm -rf
- truncate
network:
- xiaohongshu.publish
- weibo.publish
- wecom.send_message
finance:
- stock.submit_order
- stock.cancel_order
这张表是 Harness 的**“高压线地图”**。没在这张表上的操作模型可以自由用,在表上的必须经过护栏。
原则 4:把失败日志当作 Harness 的年度体检
护栏不是设完就完了——你需要定期 review 拦截日志,从中发现模型的新型绕过模式。
我每月 1 号做一次 Harness 体检,跑一个脚本:
# scripts/harness_health_check.py
import json
from collections import Counter
from datetime import datetime, timedelta
def monthly_review():
logs = []
with open('~/.openclaw/logs/guardrails.jsonl') as f:
for line in f:
logs.append(json.loads(line))
last_month = datetime.now() - timedelta(days=30)
recent = [l for l in logs if datetime.fromisoformat(l['ts']) > last_month]
# 按规则统计
rule_counter = Counter(l['rule'] for l in recent)
print("本月拦截 TOP 规则:")
for rule, count in rule_counter.most_common(10):
print(f" {rule}: {count} 次")
# 新型绕过尝试(之前没见过的 context)
unique_contexts = set(l['context'] for l in recent)
# ... 进一步分析新模式
每次月度体检我都会发现 1-2 个新模式,然后把它们加到 Hook 里。Harness 不是一次性工程,是长期养大的系统。
六、反驳性思考
反驳一:四层护栏会不会让 Agent 变得很蠢?
会。 而且是故意让它变蠢。
但"蠢"不等于"没用"。类比:飞机的自动驾驶系统遇到异常姿态会直接断开、交还飞行员——这是"蠢"的设计,但这个设计救了无数人命。
Agent 的护栏哲学一致:在高风险操作上变蠢,是为了在低风险操作上可以大胆聪明。
反驳二:这么多层会不会影响性能?
有影响,但可以忽略。
L1 是启动时一次性校验(<100ms)
L2 Hook 是每次工具调用前(<5ms/次)
L3 是 prompt 级,不增加额外 IO
L4 是 shell 层,<1ms
实测 OpenClaw 每次工具调用的护栏总开销 <10ms,占整体调用耗时 <1%。
反驳三:小型项目需要这么重的护栏吗?
不需要全做,但不能一层都没有。
最小可行版本:L2 Hook + L3 CLAUDE.md 红线,两个加起来不到 200 行代码,半天做完。
如果你的 Agent 会碰生产系统 / 金融 API / 用户数据,那四层必须齐全。这不是规模问题,是责任问题。
七、收官与预告
这一篇把"确定性外壳 × 非确定性内核"的第一支柱讲透了——Harness 的起点是 Guardrails。
下一篇(03)是这个系列的第一篇硬货:
《Checkpoint vs Compaction:为什么我放弃了 Claude 的上下文压缩》
我会把自己的 daily-dream 心跳系统完整代码(含 launchd plist、crontab、三层脚本、Wiki Lint 规则)全部开源。一起比较两种上下文管理哲学——Anthropic 的 Compaction 和我的 Checkpoint——到底哪个更适合长期项目。
这是全系列最硬的一篇,写完它我可以少睡两天。
全系列地图
| # | 标题 | 状态 |
|---|---|---|
| 01 | Agent = Model + Harness | ✅ |
| 02 | 确定性外壳 × 非确定性内核 | ✅ 当前 |
| 03 | Checkpoint vs Compaction(硬货篇) | ⏳ 下一篇 |
| 04 | Task Loop 三层心跳(硬货篇) | ⏳ |
| 05 | Context 不是内存是预算 | ⏳ |
| 06 | 独立 Evaluator | ⏳ |
| 07 | 五大反模式(硬货篇) | ⏳ |
| 08 | Big Model vs Big Harness | ⏳ |
路易乔布斯
2026 年 5 月 · 深圳
养虾系列 S4 · Harness Engineering 深度拆解 02/08
更多清关注【一深思AI】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)