AAAI 2026论文分享|一种用于智慧教育领域的规模化且更公平的形成性反馈生成框架
本推文介绍了AAAI 2026收录的一篇论文《Scaling Equitable Reflection Assessment in Education via Large Language Models and Role-Based Feedback Agents》。该框架是一种基于大语言模型(LLM)和角色化反馈智能体的形成性反馈生成框架,旨在解决大班额课程、低资源教学场景中,教师无法为每一位学生的作业提供一对一的个性化反馈的痛点。该系统利用了基于大语言模型的多智能体,构建了一套兼顾评分准确性、评估公平性和教学适配性的作业评估与反馈系统,为教育领域中形成性反馈的规模化且公平落地,提供了完整解决方案。
论文链接:https://arxiv.org/pdf/2511.11772
项目链接:https://github.com/CharlieChenyuZhang/equitable-reflection-assessment
本文作者为王一鸣,审核为龚裕涛和黄忠祥。
一、研究背景与主要贡献
1.1 研究背景
形成性反馈是一种学生学习的持续性监测工具,其核心是提供及时反馈,而非等待课程结束后的终结性评价。高质量的形成性反馈需具备特异性、可行动性与对话性,能够促进学生的自主学习,缩小成就差距。但在大班额、低教育资源场景下,教师缺乏足够的时间与人力完成所有学生作业的审阅与个性化反馈,这就导致最需要学习支持的弱势学生群体,反而无法获得足够的形成性反馈资源。
自动化评分在教育领域有着悠久的历史。随着深度学习的快速发展,传统的工作流评分方式已经被神经模型在可靠性与泛化能力上全面超越。但是现有的LLM辅助评分研究,大多只关注AI与人类评分的整体一致性,而忽略了诸如不同水平学生是否被公平对待、反馈设计是否匹配教学目的,以及生成的工作流是否可被用于真实教学场景的问题。
1.2 主要贡献
该研究的主要贡献体现在以下两方面:
(1)提出了一套可扩展、自洽的评分工作流,能够在极少人工监督的条件下生成可审计的量规评分。
(2)设计了一套基于角色的智能体集群,能够生成契合形成性评估与元认知原理、具备偏见感知能力的对话式反馈。
二、问题描述
教学评价与反馈是智慧教育的重要研究领域之一,为了自动而高效地对学生的每一份作业进行完整且高质量地评价与反馈,首先需要能够对作业生成准确且公平的评分,随后能对学生的作业给出具备教学价值的高质量反馈。为正式定义这一挑战,作者针对学生写作任务,对作业文本评估任务进行了界定,并引入了能够精准评估评分准确性、公平性与反馈质量的符号体系。
2.1 任务定义
作者将作业文本评估任务定义为一项带有显性公平性约束的双输出预测任务,其中包括量规评分任务和反馈生成任务。
量规评分任务f,即根据表1中的4个维度,为每一份作业文本给出对应的评分。
表1 作业文本四维评分量规
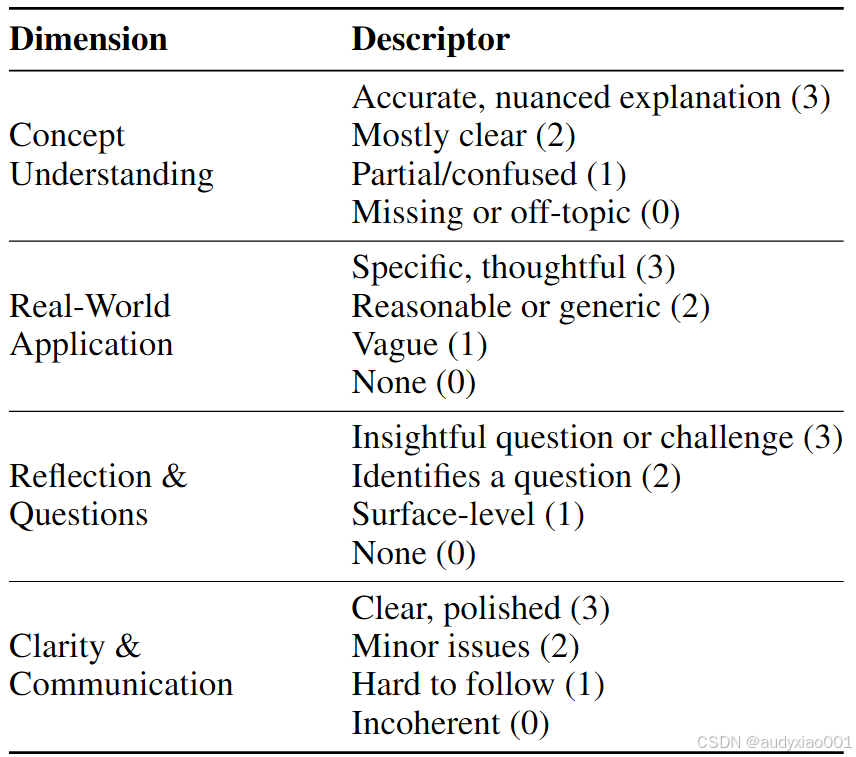
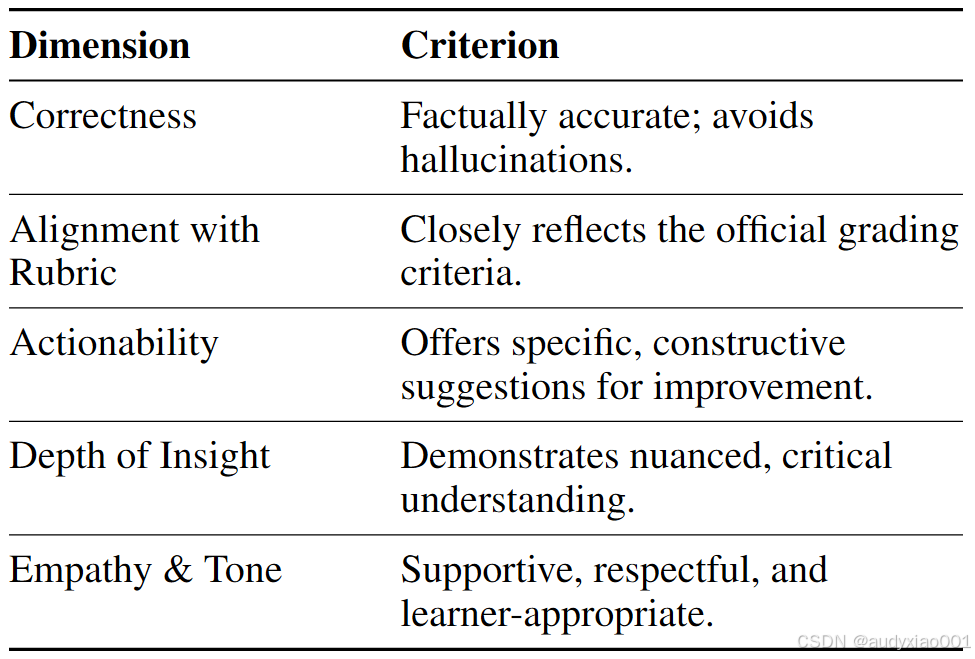
反馈生成任务g,即生成不超过120词、面向学习者的简洁评语,且符合表2中的5项质量标准。
表2 模型生成评语的质量标准
2.2 研究问题
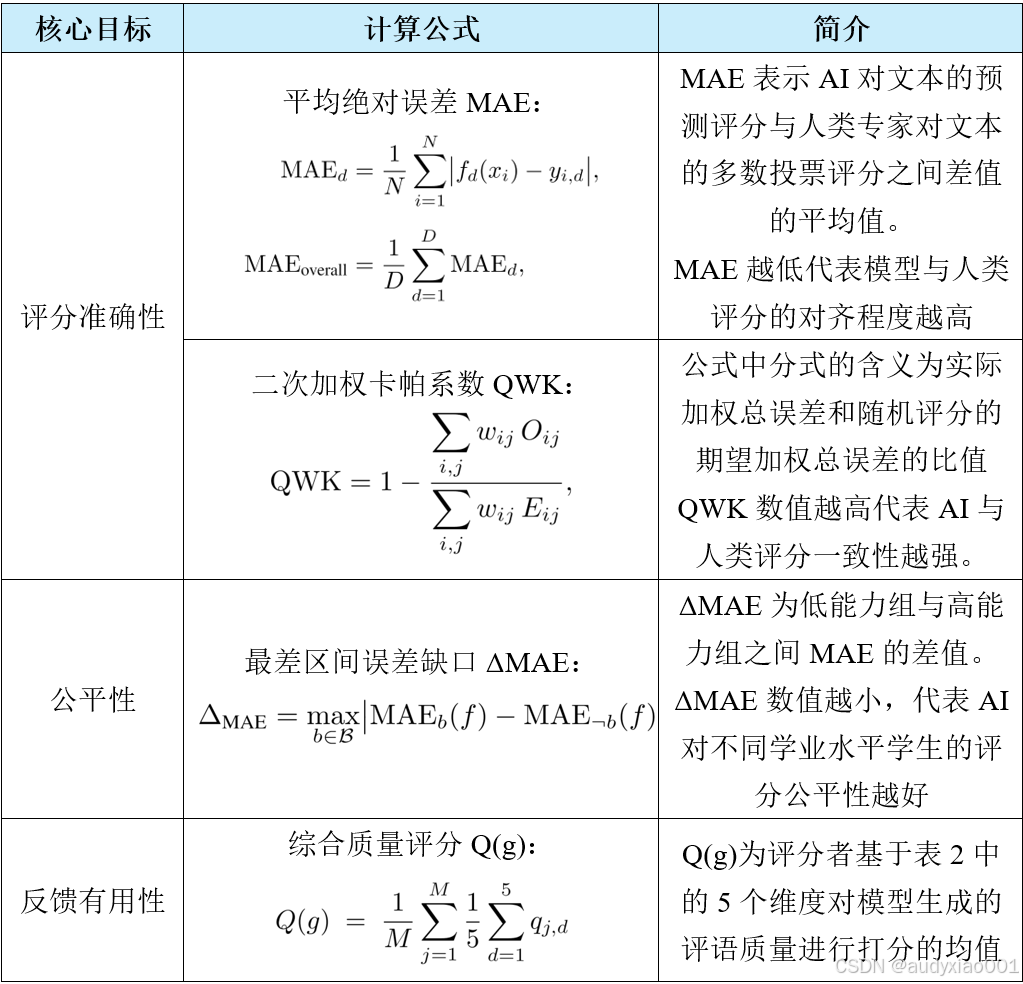
为了准确评估形成性反馈生成质量,作者设计了如表3所示的评价指标与符号体系。
表3 研究的评价指标与符号体系
三、研究方法
该研究的工作流基于AutoGen框架实现。具体而言,作者通过5个专用的GPT-4o智能体异步协同运作,为每一份作业文本生成多维度的量规评分与简洁的对话式反馈评语。该研究未进行任何强化学习或模型微调,所有自动化流程均基于提示词驱动的GPT-4o调用实现。
3.1 智能体角色配置
每个智能体角色的设计初衷是通过职责分离提升流程透明度、减少复合误差,同时允许教师对单个组件进行审计与调整。5个核心角色如下:
(1)评估者智能体
该智能体基于表1的量规对原始作业文本进行评估,输出包括量规每个维度0-3分的整数评分、对评分的简短自然语言解释和为学生标注的改进方向清单。
(2)公平性监控智能体
该智能体审阅评估者的作业反馈,排查其中存在的偏见性、排他性或文化不敏感表述,并提出修订建议。
(3)元认知智能体
该智能体会生成1-2个反思性提示词,引导学习者反思自身的推理过程并规划后续学习步骤。
(4)聚合器智能体
该智能体将前述智能体的输出整合为不超过120词、面向学生的简洁评语,仅保留少量可行动的后续改进步骤,避免学习者出现反馈过载问题。
(5)反思复核智能体
该智能体执行轻量化的事后校验,返回“可信”或“需修订”的结论,同时给出针对性的修改建议。该环节能够在反馈发布前捕捉不一致或遗漏问题,提升系统可靠性。
本研究中,模型生成温度固定为 0.3,以平衡结果的确定性与表达的丰富度。
3.2 算法流程
如图1所示,该研究提出了一个基于角色的多智能体工作流,可以有效地生成公平的作业反馈。具体而言,该系统首先将学生的作业文本交给评估者、公平性监控者和元认知智能体。它们会并行处理,生成各自的输出结果。之后,聚合器智能体会整合评估者、公平性监控者和元认知智能体的输出内容,从而生成一个评语的初稿。接着,反思复核智能体会对评语初稿进行校验,返回校验结论与修订建议。若校验结论为“需修订”,则基于修订建议优化评语。如此重复,当评语不需要修改后,最终将输出评语以及对作业文本的评分。
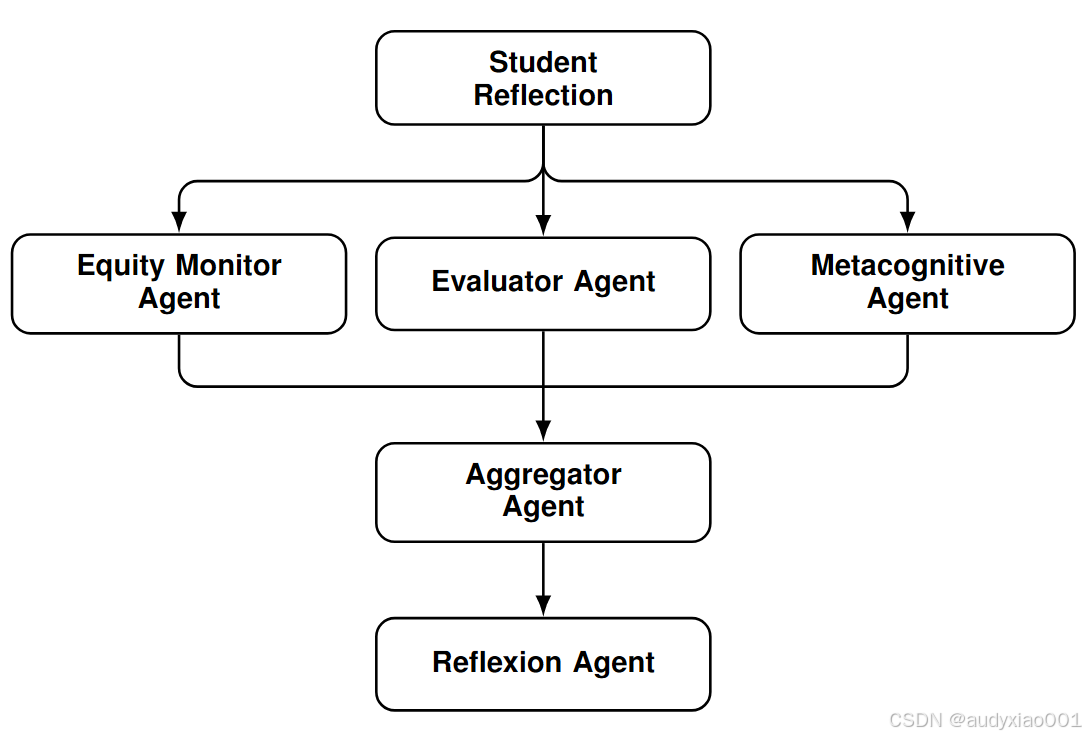
图1 研究提出的基于角色的多智能体工作流
四、实验结果
4.1 数据集与标注方式
(1)数据集
研究的分析数据来自28名成年学习者参与的线上同步AI素养课程,共收集336篇书面反思作业(每位学习者约12篇)。所有反思作业均为美式英语撰写。
(2)标注方式
研究招募了3名人类标注者并进行了完整的培训。为平衡时间覆盖度与标注者的认知负荷,研究从课程的第1课时、第6课时、第12课时中对每一名学习者各抽取1篇反思作业,最终得到84篇标注样本。每位标注者都需要对第1、6、12 课时的反思作业进行评分,同时对相同时段的AI生成反馈进行质量评估。
4.2 评分准确性与公平性
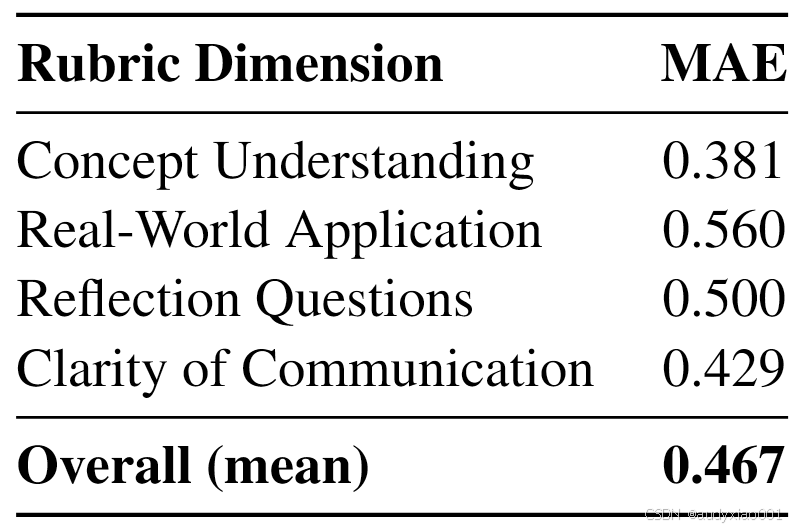
表4为模型评分与人类评分之间的平均绝对误差,即MAE得分,该得分越低证明模型与人类评分者的对齐度越高。结果显示,模型与人类评分者的对齐度在概念理解维度最高,MAE达到了0.381,在现实世界应用维度最低,MAE得分只有0.560。
表4 模型评分与人类评分之间的平均绝对误差
分课时、分量规维度的二次加权卡帕系数(QWK)结果如表5所示,三个课时汇总后的各维度均值与标准差如表6所示。结果显示,模型与人类评分者的序数一致性在反思提问维度最强,QWK均值达到了0.483,但概念理解维度最低,均值只有0.298。
表5 分课时、分量规维度的二次加权卡帕系数
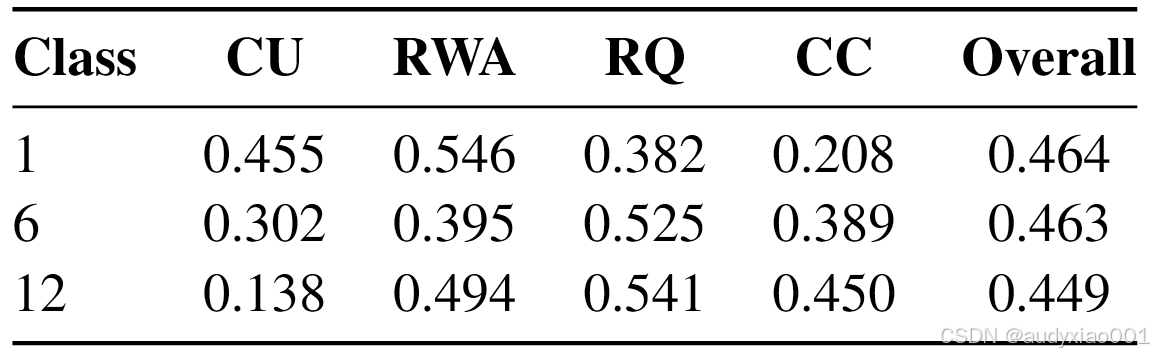
表6 二次加权卡帕系数结果汇总
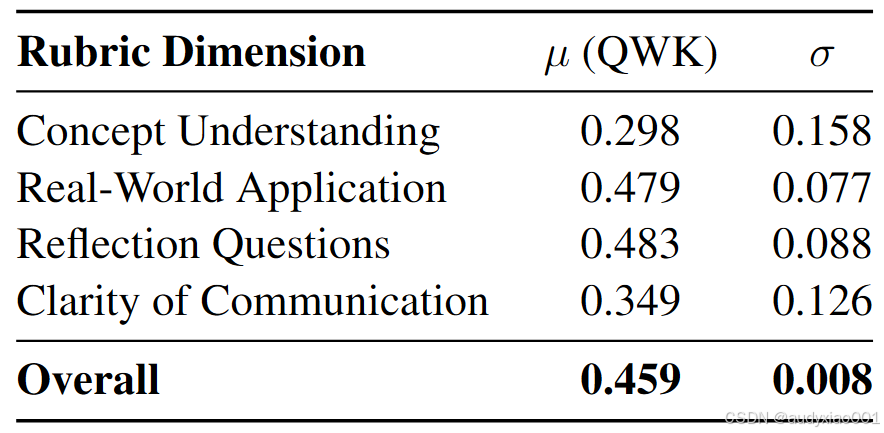
表7为各量规维度下的人类之间以及人类和AI之间的双向混合组内相关性系数ICC。该实验对比了人类评分者内部的一致性,以及AI与人类多数投票结果的一致性。结果显示,人类评分者整体呈现中等程度的内部一致性,其中反思提问维度的一致性最强。而AI与人类之间的整体一致性相对较低,其中实际应用维度与人类的对齐度最高,概念理解维度的对齐度最低,揭示了部分维度可以通过额外校准来进一步缩小人类与AI之间的一致性差距。
表7 各量规维度的双向混合组内相关性系数
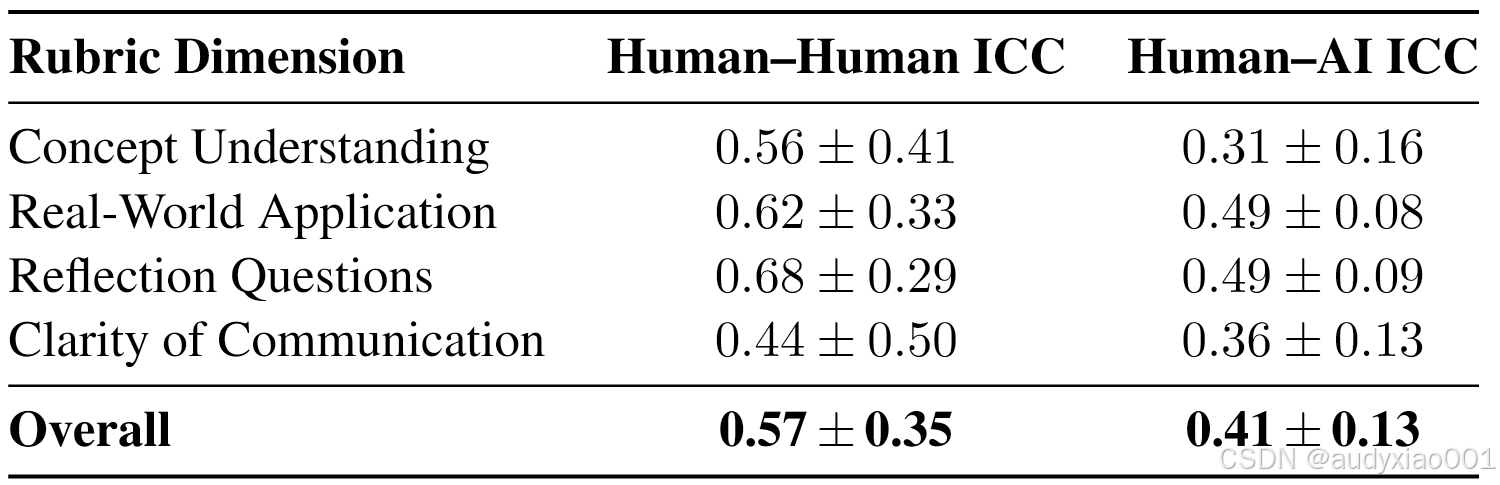
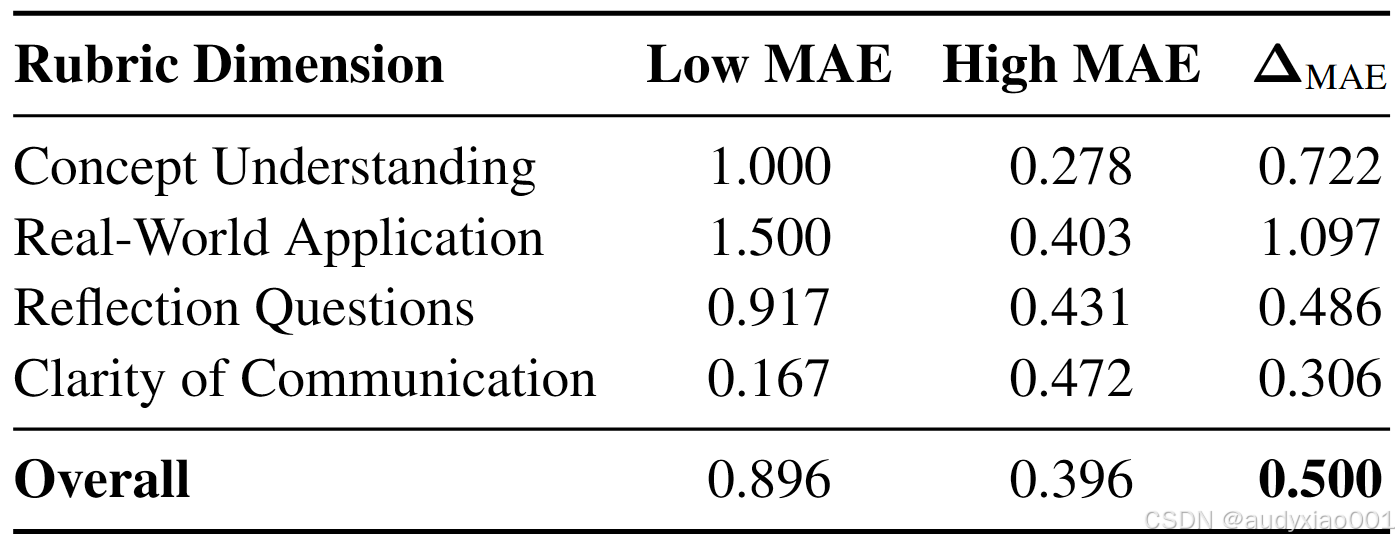
表8展示了模型在低能力组(均值0-1分)与高能力组(均值2-3分)两组中的MAE均值与误差缺口ΔMAE的结果。从表中可以看出,模型在前三个维度上对低能力组作业的准确性更低,其中实际应用维度的差距最为显著,ΔMAE达到了接近1.10。而表达清晰度维度则完全相反,对高能力组学习者的误差略高。
表8 不同能力层次的学习者MAE统计结果
4.3 反馈有用性
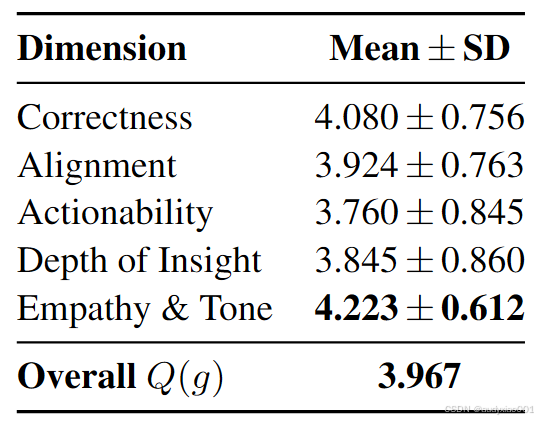
表9是3名经过培训的评分者对模型生成评语的5维反馈有用性评分的均值与标准差。结果显示,基于角色的智能体集群生成的评语,在共情性与语气维度表现最优,事实准确性维度也达到了较高水平,整体综合质量评分达到3.967,达到了中高水平。
表9 反馈有用性评分
4.4 落地实用性
3名人类评估者进行作业评分的耗时如表10所示。仅完成单篇作业的评分,平均就需要1.4分钟。作为对比,如表11所示,作者提出的系统仅执行评分环节即仅调用评估者智能体时,单篇作业的平均处理时长为7.71±0.41秒。即使调用其他智能体并执行完整流程,单篇作业的总处理耗时约为33.35秒。其效率与真人相比具有极大的优势。
表10 真人进行作业评分所花费的时间(分钟)
表11 模型进行作业评分所花费的时间

此外,在经济成本上,使用gpt-4o-mini-2024-07-18模型时,单篇作业的评分与反馈全流程处理,共消耗1216个输入token与2283个输出token,总计3499个 token。基于2024年7月18日的模型定价,单篇作业的处理成本仅为0.00155美元,价格极低。
五、总结
本推文介绍了一种规模化且更公平的形成性反馈生成框架。该系统解决了教育领域长期存在的“无法获得规模化与公平的形成性反馈资源”的核心困境,证实了基于角色的多智能体系统,能够以纯人工完全无法实现的规模与速度,为学生群体提供公平、高质量、有同理心且准确的形成性反馈。未来研究可以将该框架拓展至多语言、多文化场景,纳入能够缩小子群体差异的自适应公平性目标,并在大规模课堂部署中测量其对学生学习增益的因果性影响。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)