机器学习-第六章 集成学习
机器学习-第六章 集成学习
目录
1.集成学习思想
2.随机森林算法
3.Adaboost算法
4.GBDT
5.XGBoost
1.集成学习思想
1.1 集成学习
🧠 一、集成学习的核心思想
多个弱学习器组合成一个强学习器 —— 三个臭皮匠(皮相/副手)顶个诸葛亮。
- 弱学习器:基学习器,比如单个决策树(效果一般)
- 强学习器:多个弱学习器组合后的整体(效果更好)
🔄 二、两大主流集成方法
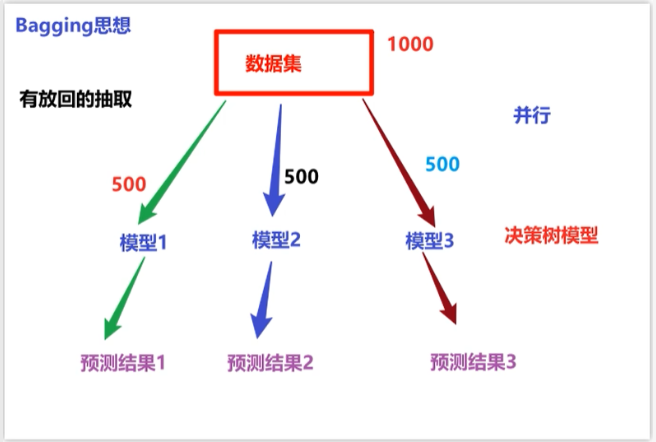
1. Bagging(并行)
- 典型代表:随机森林
- 核心做法:
- 有放回地抽样(Bootstrap)构造多个不同的训练子集
- 每个弱学习器独立并行训练
- 最终结果通过投票(分类)或平均(回归)决定
- 关键:数据集一样、模型一样,但抽到的样本不同 → 模型有差异才有集成价值
- 运行方式:✅ 可并行
2. Boosting(串行)
- 典型代表:AdaBoost、GBDT、XGBoost
- 核心做法:
- 全量数据依次训练
- 后续模型关注前面模型的错误/异常值
- 通过加权:预测正确的样本权重降低,预测错误的样本权重提高
- 运行方式:❌ 只能串行(必须等前一个模型跑完)
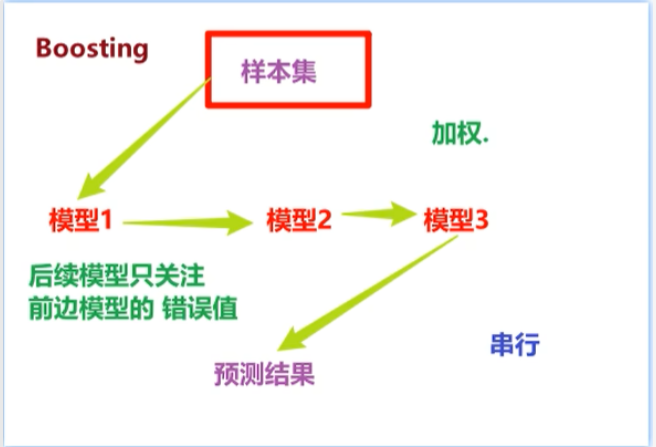
“流水线”例子很形象:第一个模型处理完,把结果交给下一个,下一个盯着前面哪里错了去改进。
📊 三、两种方法对比总结
| 特性 | Bagging(如随机森林) | Boosting(如AdaBoost/GBDT/XGBoost) |
|---|---|---|
| 训练方式 | 并行 | 串行 |
| 样本采样 | 有放回抽样(子集) | 全量数据 |
| 关注点 | 降低方差(防过拟合) | 降低偏差(提准确率) |
| 后续模型任务 | 独立训练 | 修正前序模型的错误 |
| 典型风险 | 欠拟合可能 | 过拟合可能(如果太关注异常值) |
🔮 四、最难知识点
GBDT / XGBoost 的数学推导,关键难点在于:
- 常规推导是“推到底得到一个闭式解”
- 而 Boosting 类方法推到推不动时,要用 泰勒展开式 近似,再继续推
- 会用到二阶泰勒展开
✅ 一句话记忆(集成学习)
Bagging 并行投票降方差,Boosting 串行纠错降偏差。随机森林就是 Bagging,AdaBoost/GBDT/XGBoost 就是 Boosting。
1.2 思想
一、集成学习核心思想
三个臭皮匠,顶个诸葛亮
- 将多个弱学习器组合成一个强学习器
- 通过组合多个单一预测,进一步得到更好的性能
二、Bagging(自助法)思想
核心流程
-
有放回抽样
- 从原始数据集中有放回地抽取样本
- 每个弱学习器的训练集既有交集,又有差集
-
并行训练
- 多个弱学习器可以同时进行训练
- 学习器之间没有依赖关系
-
平权投票
- 每个弱学习器权重相同(每人一票)
- 最终结果:多数表决决定
示意图理解
| 弱学习器1 | 弱学习器2 | 弱学习器3 |
|---|---|---|
| 划分方式A | 划分方式B | 划分方式A |
- 三个学习器中,两个采用方式A,一个采用方式B
- 投票结果:采用方式A作为最终分类结果
三、Boosting(提升法)思想
核心流程
-
全量数据
- 每次使用全部样本(不是有放回抽样)
- 但会调整样本的权重
-
权重调整策略
- 预测正确的样本:权重下降
- 预测错误的样本:权重提升
- 下一个学习器重点关注前面预测错误的样本
-
加权投票
- 每个学习器的投票权重不同
- 表现好的学习器权重更高
-
串行训练
- 学习器之间有依赖关系
- 必须依次训练(串行)
比喻理解
像数码宝贝进化:滚球兽 → 亚古兽 → 暴龙兽 → 机械暴龙兽 → 战斗暴龙兽
- 每新加入一个弱学习器,整体性能得到提升
- 从弱到强,不断积累
四、Boosting 代表算法
- AdaBoost
- GBDT
- XGBoost
- LightGBM(了解即可)
五、Bagging vs Boosting 对比表
| 对比维度 | Bagging | Boosting |
|---|---|---|
| 数据采样 | 有放回抽样(有交集、有差集) | 使用全部样本 |
| 样本权重 | 无 | 动态调整(错则升,对则降) |
| 学习器权重 | 平权(每人一票) | 加权投票 |
| 训练方式 | 并行(无依赖) | 串行(有依赖) |
| 关注点 | 降低方差 | 降低偏差 |
| 代表算法 | 随机森林 | AdaBoost、GBDT、XGBoost |
六、一句话总结
| 算法 | 一句话概括 |
|---|---|
| Bagging | 有放回采样 + 并行训练 + 平权投票 |
| Boosting | 全量数据 + 串行训练 + 加权关注错误样本 |
七、选择题考点
关于 Bagging 的正确描述:
- ✅ 从数据集中随机采样多个子集,每个子集训练一个弱学习器,组合成强学习器
- ✅ 从特征集中随机选取多个特征(类似随机森林)
- ❌ 是一个精度很高的分类器(错,是组合弱学习器)
- ❌ 串行训练(错,Bagging是并行)
关于 Boosting 的正确描述:
- ✅ 每次使用全部数据集
- ✅ 预测错误的样本权重会提升
- ✅ 串行训练
- ❌ 可以并行执行(错,必须串行)
2.随机森林算法
2.1 随机森林构建方法
一、学习目标
- 理解随机森林的构建方法
- 知道随机森林的API
- 能够使用随机森林完成分类任务
二、随机森林算法核心思想
“树多了,即为森林”
- 随机森林是基于 Bagging思想 实现的一种集成学习算法
- 采用决策树模型作为每一个弱学习器(基学习器)
核心步骤(训练与预测)
| 阶段 | 步骤 | 说明 |
|---|---|---|
| 训练 | 1. 有放回抽样 | 从原始数据集中有放回地随机抽取训练样本 |
| 2. 随机选择特征 | 每棵树随机选择 k 个特征(k < 总特征数) | |
| 3. 训练决策树 | 基于抽样数据和随机特征子集训练一棵决策树 | |
| 4. 重复构建 | 重复步骤1-3,构建 n 棵 决策树 | |
| 预测 | 5. 平权投票 | 所有树平权投票,多数表决输出最终结果 |
三、两个关键思考题
问题1:为什么要随机抽样训练集?
- 目的:确保各学习器的训练集 “有差异”
- 如果不随机抽样,每棵树的训练集相同 → 分类结果也完全相同 → 集成无意义
问题2:为什么要有放回地抽样?
- 目的:确保各学习器的训练集 “有交集”
- 如果没有放回,每棵树的训练样本完全无交集 → 每棵树都“有偏”,差异过大 → 投票结果不可靠
- 结论:训练集既有交集、也有差异,才能更好地发挥投票表决效果
教学比喻(抄书例子)
| 抽样方式 | 比喻 | 结果 |
|---|---|---|
| 有放回 | 10个学生各自抄了整本教材80%的内容(有重复) | 大家都学过核心概念,取平均值有意义 |
| 无放回 | 10个学生各自拿走了教材10%的内容(无重复) | 每人只懂一小部分,取均值无意义 |
四、随机森林 API(sklearn)
from sklearn.ensemble import RandomForestClassifier
常用参数详解
| 参数 | 说明 | 默认值 |
|---|---|---|
n_estimators |
决策树数量 | 10 |
criterion |
划分标准:'gini' 或 'entropy' |
'gini' |
max_depth |
树的最大深度 | None(尽可能生长) |
max_features |
每棵树使用的最大特征数量 | "auto"(即 sqrt(n_features)) |
bootstrap |
是否采用有放回抽样 | True |
min_samples_split |
节点分裂所需最小样本数 | 2 |
min_samples_leaf |
叶子节点的最小样本数 | 1 |
min_impurity_split |
节点划分最小不纯度 | 1e-7 |
max_features 常用取值
"auto"/"sqrt":max_features = sqrt(n_features)"log2":max_features = log2(n_features)None:max_features = n_features(使用全部特征)
五、参数调优建议
| 场景 | 建议 |
|---|---|
| 样本量不大 | min_samples_split 和 min_samples_leaf 用默认值即可 |
| 样本量非常大 | 适当增大 min_samples_split 和 min_samples_leaf |
| 防止过拟合 | 限制 max_depth,或增大 min_samples_leaf |
| 特征很多 | max_features 默认 sqrt 即可 |
六、随机森林流程图
原始数据集
│
▼
有放回抽样 + 随机特征子集
│
├──→ 训练集1 → 决策树1 ──┐
├──→ 训练集2 → 决策树2 ──┤
├──→ 训练集3 → 决策树3 ──┤
└──→ ... │
▼
平权投票 / 多数表决
│
▼
最终预测结果
七、一句话总结
随机森林 = Bagging + 决策树 + 有放回抽样 + 随机特征子集 + 平权投票
- 各棵树既有差异(随机抽样)又有交集(有放回)
- 集成多个弱学习器 → 强学习器
- 可有效降低过拟合,提高泛化能力
2.2 随机森林泰坦尼克号案例
一、集成学习回顾
| 思想 | 采样方式 | 投票方式 | 训练方式 | 代表算法 |
|---|---|---|---|---|
| Bagging | 有放回抽样 | 平权投票 | 并行执行 | 随机森林 |
| Boosting | 全量样本 | 加权投票 | 串行执行 | AdaBoost、GBDT、XGBoost |
随机森林 = Bagging思想 + CART决策树(二叉树)
二、随机森林 API
from sklearn.ensemble import RandomForestClassifier
常用参数
| 参数 | 说明 | 默认值 |
|---|---|---|
n_estimators |
决策树数量 | 100 |
criterion |
划分标准(gini/entropy) | gini |
max_depth |
树的最大深度 | None(不限) |
max_features |
每棵树使用的最大特征数 | auto(sqrt) |
bootstrap |
是否采用有放回抽样 | True |
min_samples_split |
节点分裂最小样本数 | 2 |
min_samples_leaf |
叶子节点最小样本数 | 1 |
注意:新版本 sklearn 中已移除部分旧参数(如
min_impurity_split)
三、泰坦尼克号案例代码实现
3.1 完整流程
"""
案例:
演示 集成学习 之 Bagging思想 随机森林算法 代码。
集成学习:
概念:
把多个弱学习期器 组成一个强学习器的过程 →集成学习
思想:
Bagging思想:
1.有放回的随机抽样
2.平权投票
3.可以并行执行
Boosting思想
1.每次训练都会使用全部样本
2.加权投票→预测正确:降低权重;预测错误:权重增加
3.只能串行执行
Bagging思想代表
随机森林算法。
随机森林算法
1.每个学习器都是CART数(必须是二叉树)
2.有放回的随机抽样,平权投票,并行执行
"""
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
# 1. 加载数据
df = pd.read_csv('./data/train.csv')
df.info()
# 2.数据预处理
# 2.1 获取特征数据
x = df[['Pclass', 'Age', 'Sex']].copy()
y = df['Survived']
# 2.2 缺失值处理
x['Age']=x['Age'].fillna(x['Age'].mean())
# 2.3 离散值处理
x = pd.get_dummies(x,columns=['Sex'])
# 2.4. 训练测试集数据
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=23)
# 3. 特征过程 省略
# 4. 模型训练,预测,评估
# 场景1:决策树模型
# 4.1 创建模型对象
estimator1 = DecisionTreeClassifier(criterion='gini')
# 4.2 模型训练
estimator1.fit(x_train,y_train)
# 4.3 模型预测
y_pred1 = estimator1.predict(x_test)
# 4.4 模型评估
print(f'准确率1:{estimator1.score(x_test,y_test)}')
# 场景2:随机森林模型 默认参数
# 4.1 创建模型对象 随机森林面向对象
estimator2 = RandomForestClassifier() # 默认 n_estimators=100
# 4.2 模型训练
estimator2.fit(x_train,y_train)
# 4.3 模型预测
y_pred2 = estimator2.predict(x_test)
# 4.4 模型评估
print(f'准确率2:{estimator2.score(x_test,y_test)}')
# 场景三:随机森林模型 参数调优
param_grid = {'n_estimators':[70,80,90,100,110],'max_depth':[4,5,6,7,8,9]}
# 4.3 创建网格搜索对象
estimator3 = GridSearchCV(estimator=RandomForestClassifier(),param_grid=param_grid,cv=5)
# 4.4 模型训练
estimator3.fit(x_train,y_train)
# 4.5 模型预测
y_pred3 = estimator3.predict(x_test)
# 4.6 模型评估
print(f'准确率3:{estimator3.score(x_test,y_test)}')
# 4.7 获取最佳参数
print(f'最佳参数:{estimator3.best_params_}')
# 4.8 获取最佳模型
print(f'最佳模型:{estimator3.best_estimator_}')
# 4.9 获取最佳模型评估结果
print(f'最佳模型评估结果:{estimator3.best_score_}')
四、运行结果参考
| 模型 | 准确率 |
|---|---|
| 单一决策树 | ≈ 0.80 |
| 随机森林(默认) | ≈ 0.79(可能略低) |
| 随机森林(网格搜索) | ≈ 0.82(调优后提升) |
随机森林不一定每次都高于决策树,需调参优化。
五、网格搜索注意事项
- 参数组合过多:例如
n_estimators有5个值,max_depth有5个值,cv=5→ 5×5×5 = 125次训练 - 先训练再传入:某些 sklearn 版本要求模型先训练一次再传入
GridSearchCVrf_tuned.fit(X_train, y_train) # 先训练 gs = GridSearchCV(rf_tuned, param_grid, cv=3) - 获得最佳参数后:可用
gs.best_params_查看最优组合,再用该参数重新训练
六、随机森林构建步骤排序题答案
题目:对随机森林构建步骤进行排序
| 步骤 | 内容 |
|---|---|
| B | 随机选取部分样本、选取部分特征训练一棵树 |
| A | 重复上述步骤,构建多棵树 |
| D | 将相同测试数据交给所有决策树进行预测 |
| C | 分类场景采用平权投票,回归场景采用简单平均,获取最终结果 |
正确顺序:B → A → D → C
七、知识点总结
| 知识点 | 内容 |
|---|---|
| 随机森林归属 | Bagging思想 |
| 基学习器 | CART决策树(二叉树) |
| 采样方式 | 有放回抽样(Bootstrap) |
| 特征选择 | 随机选取部分特征(max_features) |
| 投票方式 | 平权投票 |
| 训练方式 | 并行执行 |
| 主要优势 | 降低过拟合,提高泛化能力 |
八、注意事项
- 数据预处理:Age缺失值用均值填充;Sex字符串需编码(独热或标签编码)
- 随机森林默认100棵树,可根据数据量调整
- 网格搜索耗时:参数组合多时建议减少
cv折数(如2或3) - 版本兼容:不同 sklearn 版本参数名可能有差异,遇到报错及时查文档
3.Adaboost算法
一、Boosting 思想回顾
| 对比维度 | Bagging | Boosting |
|---|---|---|
| 数据采样 | 有放回抽样 | 全部样本 |
| 样本权重 | 无 | 动态调整(错则升,对则降) |
| 学习器权重 | 平权投票 | 加权投票 |
| 训练方式 | 并行 | 串行(有依赖) |
| 关注点 | 降低方差 | 降低偏差 |
| 代表算法 | 随机森林 | AdaBoost、GBDT、XGBoost |
Boosting 核心思想:预测正确 → 权重降低;预测错误 → 权重提升
下一个学习器重点关注前面预测错误的样本
二、AdaBoost(Adaptive Boosting)概述
- 全称:Adaptive Boosting(自适应提升)
- 本质:基于 Boosting 思想的一种集成学习算法
- 核心:逐步提高那些被前一步分类错误样本的权重
三、AdaBoost 算法核心公式
3.1 模型权重(学习器权重)
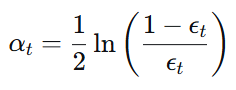
- α_t:第 t 个弱学习器的权重
-ε_t :第 t 个弱学习器的错误率 - 错误率越低,权重越大
3.2 样本权重更新公式
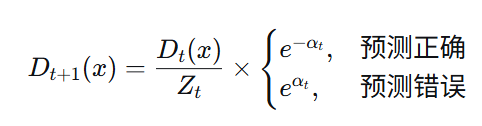
- D_t(x):当前样本权重
- Z_t :归一化因子(所有样本权重和)
- 预测正确:×e^-α_t→ 权重降低
- 预测错误:×e^α_t → 权重提升
3.3 最终集成预测
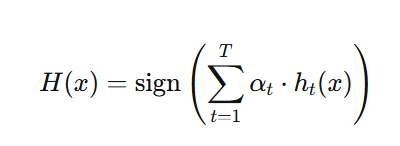
- 加权投票,通过 sign 函数输出最终类别(正/负)
四、AdaBoost 构建过程(图示理解)
初始状态
- 所有样本权重相等(如10个样本,各占10%)
- 寻找错误率最小的切分点
第一轮
- 在某个位置(如 x=6.5)做切分
- 左边全对(权重降低),右边有错误样本(权重提升)
- 错误样本在图中变大(权重增加)
第二轮
- 基于更新后的样本权重,重新寻找最优切分点
- 重点关注上一轮错误的样本
- 本轮预测正确的样本权重降低,错误的再次提升
迭代多轮
- 竖着切、横着切……共 N 刀(N 个弱学习器)
- 每轮都调整权重,错误样本权重越来越大
最终集成
- 所有弱学习器加权投票,输出最终分类结果
- 图示结果:所有圈在一边,所有叉在另一边
图中现象:预测错误的样本(圆圈/叉)会随着轮次越变越大
五、算法步骤总结
| 步骤 | 内容 |
|---|---|
| 1 | 初始化训练数据权重相等(如 1/N) |
| 2 | 训练第一个弱学习器,找到错误率最小的切分点 |
| 3 | 根据错误率计算该学习器的权重 α_t |
| 4 | 更新样本权重:正确样本降低,错误样本提升 |
| 5 | 用更新后的权重训练下一个弱学习器 |
| 6 | 重复步骤 2-5,直到训练出 M 个学习器 |
| 7 | 集成:加权投票得到最终结果 |
六、关键概念对比
| 概念 | 含义 | 公式/说明 |
|---|---|---|
| 错误率 ε_t | 第 t 个学习器分类错误的样本权重之和 | 错误样本权重 ÷ 总权重 |
| 模型权重 α_t | 该学习器在最终投票中的重要性 | 1/2ln(1-ε_t/ε_t) |
| 样本权重更新 | 调整样本被下一轮关注的概率 | 对则乘 e^-α,错则乘 e^α |
| 归一化因子 Z_t | 使更新后样本权重之和为 1 | 所有新权重之和 |
七、一句话总结
AdaBoost = 串行训练 + 动态样本权重 + 加权投票
核心口诀:预测正确权重降,预测错误权重升,错误越大越关注,加权投票定结果。
八、与随机森林(Bagging)的直观区别
| 算法 | 采样方式 | 样本权重 | 学习器权重 | 训练方式 | 关注点 |
|---|---|---|---|---|---|
| 随机森林 | 有放回抽样 | 不变 | 平权 | 并行 | 降低方差 |
| AdaBoost | 全量样本 | 动态调整 | 加权 | 串行 | 降低偏差 |
3.2 Adaboost算法-构建过程
一、核心公式回顾
1. 模型权重(学习器权重)
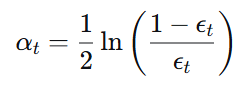
- α_t:第 t 个弱学习器的权重
- ε_t:第 t 个弱学习器的错误率
2. 样本权重更新
- 预测正确:新权重 = 旧权重 × e^ -α_t → 权重降低
- 预测错误:新权重 = 旧权重 × e^ α_t → 权重提升
3. 归一化因子

4. 最终样本权重(归一化后)

二、完整推导案例(10个样本)
初始数据
| 序号 | 特征 X | 标签 Y | 初始权重 |
|---|---|---|---|
| 1 | 0 | +1 | 0.1 |
| 2 | 1 | +1 | 0.1 |
| 3 | 2 | +1 | 0.1 |
| 4 | 3 | +1 | 0.1 |
| 5 | 4 | +1 | 0.1 |
| 6 | 5 | -1 | 0.1 |
| 7 | 6 | -1 | 0.1 |
| 8 | 7 | -1 | 0.1 |
| 9 | 8 | -1 | 0.1 |
| 10 | 9 | -1 | 0.1 |
- 正样本(+1):X=0~4(5个)
- 负样本(-1):X=5~9(5个)
三、第一轮训练(第一个弱学习器)
步骤1:找到最优切分点
遍历所有切分点,计算错误率(此时所有样本权重相等均为0.1):
| 切分点 | 错分样本 | 错误率 |
|---|---|---|
| 0.5 | 右边5个负样本全错 | 0.5 |
| 1.5 | 错4个 | 0.4 |
| 2.5 | 错3个(X=5,6,7) | 0.3 |
| 3.5 | 错4个 | 0.4 |
| 4.5 | 错5个 | 0.5 |
| 5.5 | 错6个 | 0.6 |
| … | … | … |
最优切分点:X = 2.5
错误率 ε₁=0.3
步骤2:计算模型权重
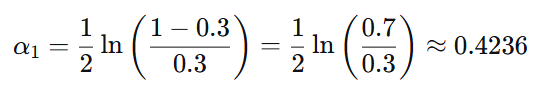
步骤3:更新样本权重
- 预测正确样本(7个):新权重 = 0.1 × e^{-0.4236} ≈ 0.1 × 0.6547 = 0.06547
- 预测错误样本(3个,X=5,6,7):新权重 = 0.1 × e^{0.4236} ≈ 0.1 × 1.5275 = 0.15275
步骤4:归一化
- 归一化因子 Z₁ = 7 × 0.06547 + 3 × 0.15275 = 0.45829 + 0.45825 = 0.91654
- 正确样本最终权重:0.06547 / 0.91654 ≈ 0.07143
- 错误样本最终权重:0.15275 / 0.91654 ≈ 0.16667
第一轮结果
| 样本 X | 0~4 | 5,6,7 | 8,9 |
|---|---|---|---|
| 是否错分 | 正确 | 错误 | 正确 |
| 原权重 | 0.1 | 0.1 | 0.1 |
| 新权重 | 0.07143 | 0.16667 | 0.07143 |
错误样本权重提升,正确样本权重下降
四、第二轮训练(第二个弱学习器)
新权重分布
- X=0~4(5个正样本):权重 0.07143
- X=5,6,7(3个负样本):权重 0.16667
- X=8,9(2个负样本):权重 0.07143
计算带权错误率
以切分点 8.5 为例:
- 左侧(X≤8.5):包含X=0~8(9个样本)
- 错分:X=5,6,7(3个负样本被预测为正)→ 错误权重 = 3 × 0.16667 = 0.5
- 右侧(X>8.5):X=9(1个样本,负样本)
- 错分:无
- 错误率 = 0.5
经比较,最优切分点为 8.5,错误率最小(约0.2143)
计算模型权重
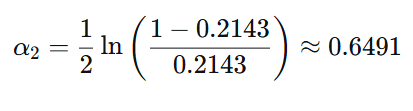
更新并归一化权重
得到第二轮后的新权重分布(略),继续满足:错误样本权重提升,正确样本权重下降
五、第三轮训练(第三个弱学习器)
最优切分点:5.5
- 错误率 ≈ 0.018
- 模型权重α₃= 0.7514
六、最终强分类器
集成三个弱学习器,加权投票:
H(x) = sign( α₁h₁(x) + α₂h₂(x) + α₃h₃(x) )
预测示例:X = 3
| 学习器 | 切分点 | 预测结果 | 权重 |
|---|---|---|---|
| 1 | 2.5 | 3 > 2.5 → 负类(-1) | 0.4236 |
| 2 | 8.5 | 3 < 8.5 → 正类(+1) | 0.6491 |
| 3 | 5.5 | 3 < 5.5 → 正类(+1) | 0.7514 |
加权和 = 0.4236 ×(-1) + 0.6491 ×1 + 0.7514×1 = 0.9769 > 0
最终预测:正类(+1)
七、核心要点总结
| 关键点 | 说明 |
|---|---|
| 错误率计算 | 带权重的错误率 = 错分样本的权重之和 |
| 模型权重 | 错误率越低 → 模型权重越大 |
| 样本权重更新 | 正确样本权重 × ( e^{-\alpha} ) ↓,错误样本权重 × ( e^{\alpha} ) ↑ |
| 归一化 | 保证更新后所有样本权重之和为 1 |
| 最终集成 | 加权投票(不是平权投票) |
八、与 Bagging 的区别
| 对比项 | Bagging(随机森林) | Boosting(AdaBoost) |
|---|---|---|
| 样本权重 | 固定 | 动态调整(错升对降) |
| 学习器权重 | 平权 | 加权(错误率低则权重大) |
| 训练方式 | 并行 | 串行 |
| 关注点 | 降低方差 | 降低偏差 |
九、一句话总结
AdaBoost = 串行训练 + 动态样本权重(错升对降)+ 加权投票
每一轮重点学习上一轮的错误样本,最终组合成一个强学习器。
3.3 Adaboost葡萄酒分类案例-代码实战
一、案例目标
- 数据集:葡萄酒数据集(Wine Dataset)
- 任务:根据葡萄酒的酒精含量和色泽两个特征,对葡萄酒进行分类
- 算法:AdaBoost(自适应提升)
二、核心知识点
AdaBoost 底层基学习器
- 默认基学习器:决策树(CART树,二叉树)
- 由于 CART 树只能做二分类,因此需要将多分类问题转换为二分类问题
数据集类别处理
原始葡萄酒数据集有 3 个类别(1, 2, 3):
- 需要去掉一个类别(如去掉类别1),只保留类别2和3
- 再用 LabelEncoder 将类别2和3转换为 0 和 1
三、API 介绍
3.1 标签编码器(新知识点)
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_new = le.fit_transform(y) # 将类别标签转为 0, 1, 2, ...
3.2 AdaBoost 分类器
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
# 基学习器:决策树
base_model = DecisionTreeClassifier(criterion='gini', max_depth=3)
# AdaBoost 集成
model = AdaBoostClassifier(
estimator=base_model, # 基学习器
n_estimators=200, # 弱学习器数量
learning_rate=0.1, # 学习率
algorithm='SAMME' # 算法版本(避免警告)
)
重要参数说明
| 参数 | 说明 | 默认值 |
|---|---|---|
estimator |
基学习器(通常是决策树) | None(必须指定) |
n_estimators |
弱学习器数量 | 50 |
learning_rate |
学习率(每棵树权重缩减系数) | 1.0 |
algorithm |
算法版本(‘SAMME’ 或 ‘SAMME.R’) | ‘SAMME.R’(新版本) |
版本注意:旧版本参数名为
base_estimator,新版本改为estimator;算法默认值可能已过时(deprecated),建议显式指定algorithm='SAMME'
四、完整代码实现
"""
案例:
演示AdaBoost苏阿散发 之 葡萄酒案例
AdaBoost 算法介绍:
他属于Boosting思想,即:串行执行,每次使用全部样本,最后加权投票。
原理:
1.使用全部样本,通过决策树模型(第一个弱分类器)进行训练,获取结果。
思路:
预测正确→权重下降
预测错误→权重上升
2.把第一个弱分类器的处理结果,交给第二个弱分类器进行训练,获取结果。
思路:
预测正确→权重下降
预测错误→权重增加
3. 以此类推,串行执行,直至获取最终执行结果
"""
import pandas as pd
from sklearn.preprocessing import LabelEncoder #标签编码器
from sklearn.model_selection import train_test_split #训练集测试集分割
from sklearn.tree import DecisionTreeClassifier #决策树分类器
from sklearn.ensemble import AdaBoostClassifier #AdaBoost分类器---集成学习boosting思想
from sklearn.metrics import accuracy_score #模型评估-准确率
# 1. 获取数据集
df_wine = pd.read_csv('./data/wine0501.csv')
df_wine.info()
print(df_wine['Class label'].unique()) # [1 2 3] 葡萄酒类别有3种,但是决策树只能识别二叉树。
# 2. 数据预处理
# 2.1 从标签列Class label中,过滤掉1类别,获取2,3类别
df_wine = df_wine[df_wine['Class label'] != 1]
print(df_wine['Class label'].unique()) #[2 3]
# 2.2 获取标签列和特征列
x = df_wine[['Alcohol', 'Hue']] #酒精 和 颜色
y = df_wine['Class label']
# 2.3 打印数据
print(x[:5])
print(y[:5])
# 2.4 通过标签编码器,将标签列转换成数字列
le = LabelEncoder()
y = le.fit_transform(y)
print(y[:5]) # [2 3] → [0 1]
# 2.5 训练集测试集分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=23,stratify=y)
# 3. 特征工程,此处省略
# 4.模型训练,预测,评估
# 场景1:单一决策树→充当弱分类器
# 4.1 创建模型对象
estimator1 = DecisionTreeClassifier(max_depth=3)
# 4.2 训练模型
estimator1.fit(x_train, y_train)
# 4.3 预测
y_predict = estimator1.predict(x_test)
# 4.4 评估
print('准确率:', accuracy_score(y_test, y_predict)) #0.9166666666666666
#场景2:AdaBoost → 集成学习,CART树,200棵
# 4.1 创建模型对象
# 参1:弱分类器(决策树对象) 参2:弱分类器数量 参3:学习率
estimator2 = AdaBoostClassifier(estimator=estimator1, n_estimators=200, learning_rate=0.1)
# 4.2 训练模型
estimator2.fit(x_train, y_train)
# 4.3 预测
y_predict2 = estimator2.predict(x_test)
# 4.4 评估
print('准确率:', accuracy_score(y_test, y_predict2)) #0.9583333333333334
五、运行结果示例
| 模型 | 准确率 |
|---|---|
| 单一决策树 | ≈ 0.9167 |
| AdaBoost(默认算法) | ≈ 0.958 |
六、常见问题与解决
问题1:ValueError(类别超过2类)
- 原因:AdaBoost 基学习器(CART树)只支持二分类
- 解决:过滤掉一个类别,保留两个类别
问题2:FutureWarning(算法已过时)
- 警告信息:
The default algorithm 'SAMME.R' is deprecated... - 解决:显式指定
algorithm='SAMME'
AdaBoostClassifier(algorithm='SAMME', ...)
问题3:参数名变化
| 旧版本(< 1.2) | 新版本(≥ 1.2) |
|---|---|
base_estimator |
estimator |
七、AdaBoost 核心思想总结
| 要点 | 说明 |
|---|---|
| 所属思想 | Boosting(串行执行) |
| 样本使用 | 每次使用全部样本 |
| 权重调整 | 预测正确 → 权重下降;预测错误 → 权重上升 |
| 学习器权重 | 加权投票(错误率低的学习器权重大) |
| 基学习器 | 决策树(CART,二叉树) |
| 算法名称含义 | Adaptive Boosting(自适应提升) |
4.GBDT
一、GBDT 核心思想概述
1.1 与之前算法的对比
| 算法 | 所属思想 | 核心机制 |
|---|---|---|
| 随机森林 | Bagging(并行) | 有放回抽样 + 平权投票 |
| AdaBoost | Boosting(串行) | 动态样本权重(错升对降) |
| GBDT | Boosting(串行) | 拟合残差(负梯度) |
1.2 BDT(残差提升树)核心思想
残差 = 真实值 − 预测值
生活案例(猜年龄):
- 真实年龄:100岁
- 第一次猜:80岁 → 残差 = 20
- 第二次以残差20为目标,猜16 → 残差 = 4
- 第三次以残差4为目标,猜3.2 → 残差 = 0.8
- 最终预测 = 80 + 16 + 3.2 = 99.2(不断逼近真实值)
BDT 核心:每次训练拟合上一轮的残差,将所有弱学习器的预测结果相加作为最终输出。
1.3 为什么叫梯度提升树(GBDT)?
- 对损失函数求导,得到负梯度方向
- 发现:负梯度 = 真实值 − 预测值 = 残差
- 因此:GBDT = 用负梯度(即残差)来拟合的 Boosting 树
一句话总结:GBDT 通过拟合负梯度(残差),将多个弱学习器的预测结果累加,不断逼近真实值。
二、GBDT 数学推导(简化版)
2.1 初始化
第一个弱学习器的预测值,选择使平方损失最小的值:
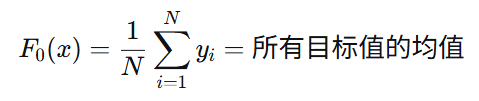
2.2 负梯度(残差)计算
对于第 t 棵树:
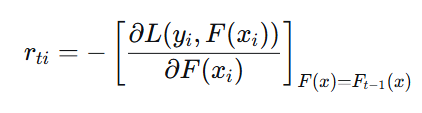
当损失函数为平方损失时:

2.3 构建第 t 棵树
- 目标值:上一轮计算出的残差(负梯度)
- 划分标准:寻找使平方损失最小的切分点
- 叶子节点输出:该节点内所有残差的均值
2.4 更新预测值
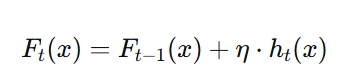
- h_t(x):第 t 棵树的预测值(残差拟合值)
- η:学习率(shrinkage),防止过拟合
三、完整案例推导(10个样本)
3.1 初始数据
| 样本 X | 真实值 y |
|---|---|
| 1~10 | 5.56, 5.70, 5.91, 6.40, 6.80, 7.05, 8.90, 9.00, 9.05, 9.20 |
3.2 第一棵树
步骤1:初始化预测值 = 均值
F₀(x) = (5.56+…+9.20)/10 = 7.31
步骤2:计算负梯度(残差)
r = y - 7.31(得到10个残差值)
步骤3:找到最优切分点
遍历切分点(1.5, 2.5, …, 8.5),计算划分后的平方损失:
| 切分点 | 左子样本 | 右子样本 | 平方损失 |
|---|---|---|---|
| 1.5 | [5.56] | 其余9个 | 15.72 |
| 2.5 | [5.56,5.70] | 其余8个 | … |
| … | … | … | … |
| 6.5 | 前6个 | 后4个 | 1.93(最小) |
步骤4:确定第一棵树结构
- 切分点:6.5
- 左子节点输出:前6个残差的均值 = -1.07
- 右子节点输出:后4个残差的均值 = 1.60
3.3 第二棵树
步骤1:目标值 = 上一轮的残差(即第一棵树计算出的负梯度值)
步骤2:在新目标值上找最优切分点 → 切分点为 3.5
步骤3:计算子节点输出(残差均值)
3.4 第三棵树
同理,继续拟合上一轮的残差,找到切分点为 6.5(再次分割)
3.5 最终预测(以 X=6 为例)
| 树 | 预测值 |
|---|---|
| F₀ | 7.31 |
| 树1 | -1.07 |
| 树2 | -0.22 |
| 树3 | 0.15 |
| 最终 | 7.31 + (-1.07) + (-0.22) + 0.15 = 6.17 |
(真实值 ≈ 6.17,拟合成功)
四、GBDT 算法流程总结
1. 初始化:F₀(x) = 所有目标值的均值
2. 对于 t = 1 到 T(T 棵树):
a. 计算负梯度(残差): r_ti = y_i - F_{t-1}(x_i)
b. 用残差作为新目标值,训练一棵回归树 h_t(x)
c. 找到最优切分点(最小化平方损失)
d. 叶子节点输出 = 该节点内残差的均值
e. 更新:F_t(x) = F_{t-1}(x) + η · h_t(x)
3. 输出:F_T(x)(所有树预测值累加)
五、GBDT vs AdaBoost 对比
| 对比项 | AdaBoost | GBDT |
|---|---|---|
| 核心机制 | 调整样本权重(错升对降) | 拟合残差(负梯度) |
| 基学习器 | 决策树(CART) | 决策树(CART,回归树) |
| 损失函数 | 指数损失 | 平方损失(回归)/ 对数损失(分类) |
| 更新方式 | 加权投票 | 累加预测值 |
| 学习率 | 有(learning_rate) | 有(shrinkage) |
六、GBDT 代码实战(泰坦尼克号分类)
6.1 完整代码
# 1. 导包
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
# 2. 加载数据
df = pd.read_csv('./data/train.csv')
# 3. 特征提取
X = df[['Pclass', 'Sex', 'Age']].copy()
y = df['Survived'].copy()
# 4. 缺失值处理
X['Age'] = X['Age'].fillna(X['Age'].mean())
# 5. 性别独热编码
X = pd.get_dummies(X) # 生成 Sex_female, Sex_male
# 6. 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=23)
# ================= 场景一:单一决策树 =================
dt = DecisionTreeClassifier(random_state=23)
dt.fit(X_train, y_train)
print("单一决策树准确率:", accuracy_score(y_test, dt.predict(X_test)))
# ================= 场景二:GBDT(默认参数)=================
gbdt = GradientBoostingClassifier(random_state=23)
gbdt.fit(X_train, y_train)
print("GBDT默认准确率:", accuracy_score(y_test, gbdt.predict(X_test)))
# ================= 场景三:GBDT + 网格搜索 =================
param_grid = {
'n_estimators': [60], # 树的数量
'learning_rate': [0.1], # 学习率
'max_depth': [3] # 树的最大深度
}
# 创建 GBDT 对象(可直接传入网格搜索)
gbdt_tuned = GradientBoostingClassifier(random_state=23)
# 网格搜索交叉验证
gs = GridSearchCV(gbdt_tuned, param_grid, cv=3)
gs.fit(X_train, y_train)
print("GBDT调优后准确率:", gs.best_score_)
print("最佳参数:", gs.best_params_)
6.2 运行结果参考
| 模型 | 准确率 |
|---|---|
| 单一决策树 | ≈ 0.80 |
| GBDT(默认参数) | ≈ 0.82 |
| GBDT(网格搜索) | 需调参(树越多通常越准) |
注意:GBDT 是累加所有树的预测结果,理论上树的数量越多,效果越好(但也会增加过拟合风险)。
七、GBDT 参数说明
| 参数 | 说明 | 默认值 |
|---|---|---|
n_estimators |
弱学习器数量(树的数量) | 100 |
learning_rate |
学习率(每棵树贡献的缩减系数) | 0.1 |
max_depth |
每棵树的最大深度 | 3 |
subsample |
子采样比例(防止过拟合) | 1.0 |
loss |
损失函数(‘deviance’=对数损失,‘exponential’=指数损失) | ‘deviance’ |
八、常见面试题
1. GBDT 的梯度是指什么?
损失函数对预测值的负梯度,在平方损失下等于残差。
2. GBDT 和 AdaBoost 的主要区别?
- AdaBoost:调整样本权重,错误样本权重升高
- GBDT:拟合残差(负梯度),累加预测值
3. GBDT 可以用于回归吗?
可以。回归时用平方损失,拟合残差;分类时用对数损失,拟合负梯度。
4. GBDT 为什么需要学习率?
防止过拟合,每棵树只学习残差的一小部分,逐步逼近。
九、与随机森林的对比
| 对比项 | 随机森林 | GBDT |
|---|---|---|
| 思想 | Bagging(并行) | Boosting(串行) |
| 采样 | 有放回抽样 | 全部样本 |
| 核心 | 降低方差 | 降低偏差 |
| 输出 | 投票平均 | 累加残差 |
| 过拟合 | 不易过拟合 | 需控制学习率和树数量 |
十、一句话总结
GBDT = 串行训练 + 拟合残差(负梯度) + 累加预测结果
每一棵树学习上一棵树预测值与真实值之间的差距(残差),最终所有树的预测值相加得到最终结果。
十一、扩展:GBDT vs XGBoost
| 对比项 | GBDT | XGBoost |
|---|---|---|
| 二阶导数 | 只用一阶导数 | 用一阶+二阶导数 |
| 正则化 | 无 | 有(L1/L2) |
| 缺失值处理 | 需手动 | 自动学习 |
| 并行 | 不支持 | 支持(特征并行) |
| 速度 | 较慢 | 更快 |
XGBoost 可以看作是 GBDT 的工程优化版本。
5.XGBoost
5.1 XGBoost概念
一、XGBoost 概述
- 全称:eXtreme Gradient Boosting(极限梯度提升)
- 本质:对 GBDT 的改进和优化
- 地位:集成学习中的“王牌”,在数据挖掘竞赛中大部分获胜者都使用了 XGBoost
核心思想(一句话)
通过打分函数来判断是否分裂:比较分裂前后的得分,分裂后得分更高则考虑分裂
二、XGBoost vs GBDT
| 对比项 | GBDT | XGBoost |
|---|---|---|
| 损失函数 | 仅拟合负梯度(残差) | 损失函数 + 正则化项 |
| 防止过拟合 | 靠学习率 | 显式正则化(叶子节点数、权重模长) |
| 结构风险 | 无 | 有(控制模型复杂度) |
| 类比 | ID3(仅信息增益) | C4.5(信息增益率) |
XGBoost = GBDT + 正则化项
三、XGBoost 目标函数(损失函数)
3.1 基本形式
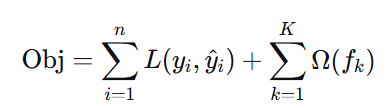
- 第一项:训练损失(衡量预测值与真实值的差距)
- 第二项:正则化项(衡量模型复杂度)
3.2 正则化项(复杂度惩罚)
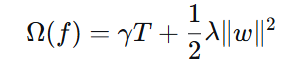
| 符号 | 含义 | 作用 |
|---|---|---|
| ( T ) | 一棵树的叶子节点数量 | 叶子越多,惩罚越大 |
| ( γ ) | 叶子节点数的惩罚系数 | 控制是否继续分裂 |
| ( w ) | 叶子节点输出值组成的向量 | |
| ( ||w||² ) | 向量模长的平方(L2范数平方) | 控制输出值大小 |
| ( λ ) | L2正则化系数 | 防止输出值过大 |
3.3 模长计算回顾
对于向量 ( w = [2, 0.1, 1] ):
- 模长 ( ||w|| = √{2² + 0.1² + 1²} )
- 模长平方 ( ||w||² = 2² + 0.1² + 1² )
正则化项中的 ( ||w||²) 直接就是各叶子节点输出值的平方和,无需开根号。
四、正则化的作用
- 降低模型复杂度,防止过拟合
- 考虑多维度因素:
- 叶子节点数量(树的结构复杂度)
- 叶子节点输出值的大小(权重)
GBDT 只考虑拟合残差,XGBoost 同时考虑拟合效果和模型复杂度
五、XGBoost 分裂判断逻辑(打分函数)
核心思想
分裂前得分 ← 当前节点的损失 + 复杂度
分裂后得分 ← 左子节点损失 + 右子节点损失 + 复杂度
如果 分裂后得分 < 分裂前得分:
考虑分裂(效果更好)
否则:
不分裂
注意:XGBoost 的“得分”是损失值,越小越好。
实际推导中,通过比较**分裂前后的增益(Gain)**是否大于阈值来决定是否分裂。
六、XGBoost 与 GBDT 的完整对比
| 对比维度 | GBDT | XGBoost |
|---|---|---|
| 损失函数 | 仅拟合残差 | 损失 + 正则化 |
| 正则化 | 无 | 有(γT + ½λ‖w‖²) |
| 防止过拟合 | 靠学习率 | 显式惩罚复杂度 |
| 二阶导数 | 只用一阶(梯度) | 一阶+二阶(海森矩阵) |
| 缺失值处理 | 需手动填充 | 可自动学习 |
| 并行能力 | 串行 | 支持特征并行 |
| 速度 | 较慢 | 更快 |
七、案例理解:预测电子游戏喜好程度
树1(按年龄和性别划分)
年龄 < 15 ?
├── 是 ── 性别?
│ ├── 男 → 输出 +2
│ └── 女 → 输出 +0.1
└── 否(≥15) → 输出 +1
树2(按性别划分)
性别?
├── 男 → 输出 +0.9
└── 女 → 输出 -0.9
最终预测(与 GBDT 一样,累加)
- 年轻男性:2 + 0.9 = 2.9
- 年老男性:1 + 0.9 = 1.9
- 年轻女性:0.1 - 0.9 = -0.8
- 年老女性:1 - 0.9 = 0.1
复杂度计算(正则化项)
树1:叶子节点 T=3,输出值 [2, 0.1, 1]
树2:叶子节点 T=2,输出值 [0.9, -0.9](平方后相同)
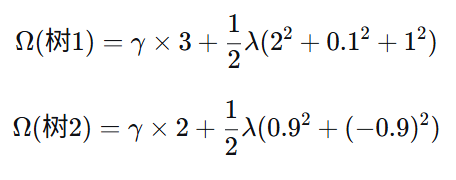
复杂度越高,惩罚越大,模型倾向于选择更简单的树结构
八、XGBoost 核心优势总结
| 优势 | 说明 |
|---|---|
| 正则化 | 显式控制模型复杂度,防止过拟合 |
| 二阶近似 | 使用一阶+二阶导数,收敛更快 |
| 缺失值处理 | 自动学习缺失值分裂方向 |
| 并行计算 | 特征粒度并行,训练速度快 |
| 剪枝 | 负增益时自动停止分裂 |
| 交叉验证 | 内置 CV 功能 |
九、与之前算法的对比总结
| 算法 | 核心机制 | 防过拟合手段 | 类比 |
|---|---|---|---|
| ID3 | 信息增益 | 无 | 基础 |
| C4.5 | 信息增益率 | 除以特征熵 | 优化 |
| GBDT | 拟合残差(负梯度) | 学习率 | 基础 |
| XGBoost | 残差 + 正则化 | γT + ½λ‖w‖² | 优化 |
十、一句话总结
XGBoost = GBDT + 正则化项(叶子节点数惩罚 + 输出值平方和惩罚)
通过打分函数比较分裂前后的损失,决定是否分裂,从而控制模型复杂度,防止过拟合。
5.2 XGBoost推导
说明:本笔记涵盖从目标函数到最终打分函数(Gain)的完整数学推导。面试中要求能用自己的话术讲清四个核心步骤,无需默写全部公式。
一、XGBoost 核心思想回顾
| 对比项 | GBDT | XGBoost |
|---|---|---|
| 目标函数 | 仅拟合残差(负梯度) | 损失函数 + 正则化项 |
| 防止过拟合 | 靠学习率 | 显式惩罚模型复杂度 |
| 分裂判断 | 拟合残差 | 打分函数(Gain) |
XGBoost = GBDT + 正则化项
通过打分函数比较分裂前后的得分,决定是否分裂。
二、XGBoost 推导四步法(面试核心)
| 步骤 | 核心内容 | 目的 |
|---|---|---|
| 第一步 | 在损失函数基础上加入正则化项 | 控制每个弱学习器的复杂度,防止过拟合 |
| 第二步 | 使用泰勒二阶展开将目标函数转换为近似函数 | 利用上一轮(T-1轮)已知结果,求解当前轮(T轮)损失 |
| 第三步 | 将问题从样本角度转换为叶子节点角度 | 统一计算,便于求导 |
| 第四步 | 推导出打分函数(Gain),判断是否分裂 | Gain > 0 则考虑分裂(分裂后损失更小) |
面试要求:能用自己的话术把这四步讲清楚即可,不需要默写公式。
三、详细推导过程
第一步:加入正则化项
原始 GBDT 目标函数(仅损失函数):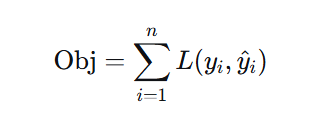
XGBoost 目标函数(损失 + 正则化):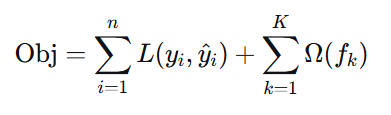
正则化项(惩罚模型复杂度):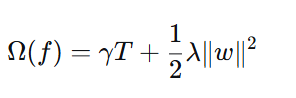
| 符号 | 含义 | 作用 |
|---|---|---|
| ( T ) | 叶子节点数量 | 叶子越多,惩罚越大 |
| ( γ ) | 叶子节点惩罚系数 | 控制是否继续分裂 |
| ( ||w||² ) | 叶子节点输出值的平方和 | 控制输出值大小 |
| ( λ ) | L2正则化系数 | 防止输出值过大 |
第二步:泰勒二阶展开(转换为近似函数)
核心思想:第 T 轮的预测值 = 第 T-1 轮预测值 + 第 T 轮损失(残差)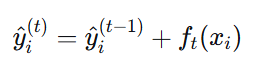
代入目标函数并对
进行泰勒二阶展开:
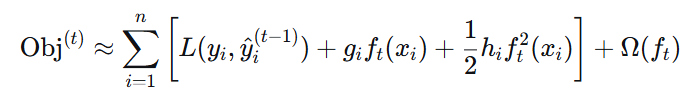
其中: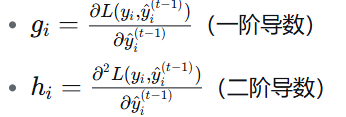
去掉常数项(上一轮损失
为已知常数),得到简化形式:
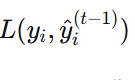
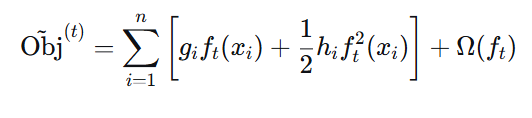
第三步:从样本角度转换为叶子节点角度
核心:将样本累加转换为按叶子节点累加。
假设一棵树有 ( T ) 个叶子节点,每个叶子节点 ( j ) 上的样本集合为 ( I_j ),该叶子节点的输出值为 ( w_j )。
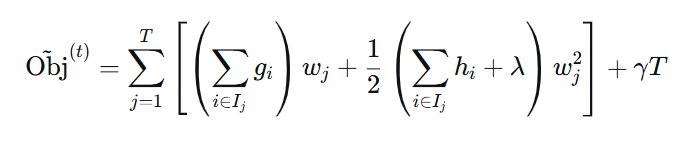
令:
代入得: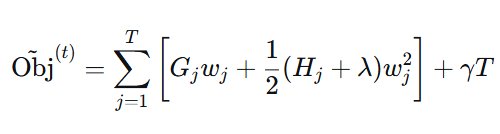
第四步:求导并推导最优输出值及打分函数
对 ( w_j ) 求导,令导数为 0: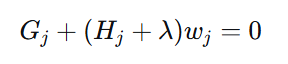
最优叶子节点输出值: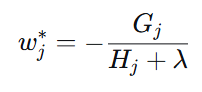
代入原式得最终打分函数(衡量一棵树的优劣):
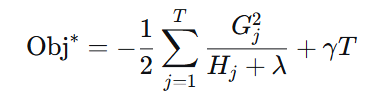
该值越小,说明树的结构越好(损失 + 复杂度 越小)
四、分裂判断:Gain(增益)
分裂前后的得分变化:
Gain = 分裂前得分 - (左子树得分 + 右子树得分)
代入打分函数公式: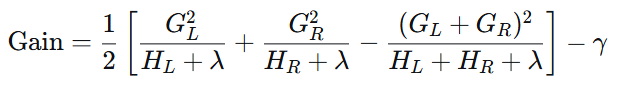
| Gain 值 | 含义 | 决策 |
|---|---|---|
| Gain > 0 | 分裂后得分 < 分裂前得分(损失更小) | 考虑分裂 ✅ |
| Gain ≤ 0 | 分裂后得分 ≥ 分裂前得分(损失未减少) | 不分裂 ❌ |
注意:XGBoost 中的“得分”是损失值,越小越好。因此 Gain > 0 表示分裂后损失降低,应该分裂。
五、XGBoost 与 GBDT 对比总结
| 对比维度 | GBDT | XGBoost |
|---|---|---|
| 目标函数 | 仅拟合残差 | 损失 + 正则化(γT + ½λ‖w‖²) |
| 梯度利用 | 仅一阶导数 | 一阶 + 二阶导数(泰勒展开) |
| 分裂判断 | 拟合残差 | 打分函数(Gain) |
| 防止过拟合 | 靠学习率 | 显式复杂度惩罚 |
六、面试核心要求(四句话)
| 步骤 | 核心内容 |
|---|---|
| 1. | 在损失函数基础上加入正则化项,控制每个弱学习器的复杂度 |
| 2. | 使用泰勒二阶展开,利用 T-1 轮结果求解 T 轮损失,转换为近似函数 |
| 3. | 将问题从样本角度转换为叶子节点角度,统一计算 |
| 4. | 推导出打分函数(Gain),判断是否分裂:Gain > 0 则考虑分裂 |
要求:能用自己的话术把以上四步讲清楚即可,不需要默写公式。
七、重要概念区分
| 术语 | 含义 |
|---|---|
| BDT | 残差提升树(仅拟合残差) |
| GBDT | 梯度提升树(用负梯度拟合残差,仅一阶导) |
| XGBoost | 极限梯度提升(损失 + 正则化 + 二阶导) |
八、最终打分函数公式(了解即可)
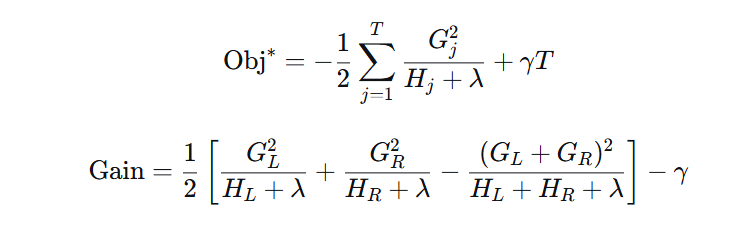
5.3 XGBoost API 介绍
一、XGBoost 安装
1.1 为什么需要单独安装?
在 sklearn 机器学习库中没有集成 XGBoost,需要手动安装。
1.2 安装命令
打开 Anaconda Prompt(以管理员身份运行):
pip install xgboost
或使用国内镜像加速:
pip install xgboost -i https://pypi.tuna.tsinghua.edu.cn/simple
注意:安装包大小约 150MB,下载可能需要一些时间。
1.3 顺带安装
pip install jieba
jieba分词器将在 K-Means 聚类 案例中使用。
二、XGBoost 官方文档
- 官方网址:https://xgboost.ai/
- Python API 参考:进入官网 → Python API Reference
多语言支持
| 语言 | 支持情况 |
|---|---|
| Python | ✅ |
| R | ✅ |
| Java (JVM) | ✅ |
| Ruby | ✅ |
| C/C++ | ✅ |
三、XGBoost 两种 API 风格对比
3.1 Sklearn 风格(推荐)
- 参数命名与 sklearn 保持一致
- 使用方式与
RandomForestClassifier、GradientBoostingClassifier完全相同 - 优点:无需学习新参数名,上手快
| Sklearn 参数名 | 含义 |
|---|---|
n_estimators |
弱学习器数量(树的数量) |
learning_rate |
学习率 |
max_depth |
树的最大深度 |
n_jobs |
并行线程数 |
3.2 XGBoost 原生风格
- 参数命名不同,需要单独记忆
- 功能与 Sklearn 风格完全相同
| 原生参数名 | 含义 | 对应 Sklearn 参数 |
|---|---|---|
num_round |
弱学习器数量 | n_estimators |
eta |
学习率 | learning_rate |
max_depth |
树的最大深度 | max_depth(相同) |
nthread |
并行线程数 | n_jobs |
lambda |
L2 正则化系数 | reg_lambda |
alpha |
L1 正则化系数 | reg_alpha |
建议:统一使用 Sklearn 风格,避免记忆两套参数名。
四、重要参数:objective(损失函数类型)
| 任务类型 | objective 参数值 |
说明 |
|---|---|---|
| 回归 | reg:linear 或 reg:squarederror |
平方损失 |
| 二分类 | binary:logistic |
逻辑回归 |
| 多分类 | multi:softmax |
多分类(输出类别) |
| 多分类(概率) | multi:softprob |
输出每个类别的概率 |
本案例使用:红酒品质预测是多分类问题 →
objective='multi:softmax'
五、XGBoost 基本使用流程(Sklearn 风格)
# 1. 导包
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 2. 准备数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 3. 创建模型(Sklearn 风格)
model = xgb.XGBClassifier(
n_estimators=100, # 树的数量
learning_rate=0.1, # 学习率
max_depth=3, # 最大深度
objective='multi:softmax', # 多分类
num_class=5, # 类别数量(多分类必须指定)
random_state=42
)
# 4. 训练
model.fit(X_train, y_train)
# 5. 预测
y_pred = model.predict(X_test)
# 6. 评估
print("准确率:", accuracy_score(y_test, y_pred))
六、安装验证
安装完成后,在 Python 中运行以下代码验证:
import xgboost as xgb
print(xgb.__version__)
不报错且输出版本号即表示安装成功。
七、一句话总结
| 要点 | 说明 |
|---|---|
| 安装 | pip install xgboost |
| API 风格 | 推荐 Sklearn 风格(参数名与 sklearn 一致) |
| 多分类 | objective='multi:softmax' + 指定 num_class |
| 原生风格 | 参数名不同(如 num_round、eta),不推荐记忆 |
。
5.4 XGBoost 红酒品质分类
一、案例概述
| 项目 | 说明 |
|---|---|
| 数据集 | 红酒品质分类数据(3,269条) |
| 特征数 | 11个特征(前11列) |
| 标签 | 第12列(品质评分:3~8分,共6个类别) |
| 任务 | 多分类(6分类) |
| 问题 | 样本不均衡(少数类别样本极少) |
二、整体流程
数据预处理 → 模型训练 → 模型保存 → 模型加载使用 → 网格搜索优化
三、第一部分:数据预处理
3.1 代码实现
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
from collections import Counter
# 1. 加载数据
df = pd.read_csv('./data/红酒品质分类.csv') # 假设文件名
# 2. 查看数据分布
print(df.info())
print("标签分布:", Counter(df.iloc[:, -1])) # 最后一列是标签
# 3. 特征和标签
X = df.iloc[:, :-1] # 所有特征
y = df.iloc[:, -1] - 3 # 标签值减3,将 3~8 转换为 0~5
# 4. 划分训练集和测试集(分层采样,防止样本不均衡)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=23, stratify=y
)
# 5. 拼接并保存为CSV文件
train_data = pd.concat([X_train, y_train], axis=1) # 横向拼接(列拼接)
test_data = pd.concat([X_test, y_test], axis=1)
train_data.to_csv('./data/红酒_train.csv', index=False)
test_data.to_csv('./data/红酒_test.csv', index=False)
print("数据预处理完成,已保存训练集和测试集")
3.2 关键点说明
| 操作 | 说明 |
|---|---|
y = y - 3 |
将标签从 3~8 转换为 0~5(6个类别) |
stratify=y |
分层采样,保持训练/测试集中各类别比例与原始数据一致 |
axis=1 |
横向拼接(列拼接),将特征和标签合并 |
四、第二部分:模型训练与保存
4.1 完整代码
import pandas as pd
import xgboost as xgb
import joblib
from sklearn.metrics import accuracy_score
from sklearn.utils.class_weight import compute_sample_weight
# 1. 读取预处理后的数据
train_data = pd.read_csv('./data/红酒_train.csv')
test_data = pd.read_csv('./data/红酒_test.csv')
# 2. 提取特征和标签
X_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
X_test = test_data.iloc[:, :-1]
y_test = test_data.iloc[:, -1]
# 3. 处理样本不均衡 - 计算样本权重
sample_weights = compute_sample_weight(class_weight='balanced', y=y_train)
# 4. 创建 XGBoost 模型(sklearn 风格)
model = xgb.XGBClassifier(
n_estimators=100, # 树的数量
learning_rate=0.1, # 学习率
max_depth=5, # 树的最大深度
objective='multi:softmax', # 多分类损失函数
random_state=23
)
# 5. 训练模型(传入样本权重)
model.fit(X_train, y_train, sample_weight=sample_weights)
# 6. 评估模型
y_pred = model.predict(X_test)
print("模型准确率:", accuracy_score(y_test, y_pred))
# 7. 保存模型
joblib.dump(model, './model/红酒品质分类.pkl')
print("模型保存成功")
4.2 关键参数说明
| 参数 | 值 | 说明 |
|---|---|---|
objective |
'multi:softmax' |
多分类(输出类别) |
n_estimators |
100 | 弱学习器数量 |
learning_rate |
0.1 | 学习率 |
max_depth |
5 | 树的最大深度 |
sample_weight |
动态计算 | 样本不均衡解决方案 |
4.3 样本权重计算
from sklearn.utils.class_weight import compute_sample_weight
sample_weights = compute_sample_weight(class_weight='balanced', y=y_train)
class_weight='balanced':自动调整权重,样本少的类别权重高- 传入
model.fit()的sample_weight参数
五、第三部分:模型加载与网格搜索优化
5.1 分层K折交叉验证
为什么使用分层K折?
| 方式 | 特点 | 适用场景 |
|---|---|---|
| 普通K折 | 随机分割 | 样本均衡 |
| 分层K折 | 保持每折中各类别比例与原始数据一致 | 样本不均衡 ✅ |
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=23)
5.2 完整网格搜索代码
import pandas as pd
import xgboost as xgb
import joblib
from sklearn.model_selection import GridSearchCV, StratifiedKFold
from sklearn.metrics import accuracy_score
# 1. 读取数据
train_data = pd.read_csv('./data/红酒_train.csv')
test_data = pd.read_csv('./data/红酒_test.csv')
X_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
X_test = test_data.iloc[:, :-1]
y_test = test_data.iloc[:, -1]
# 2. 加载已训练模型(或创建新模型)
model = joblib.load('./model/红酒品质分类.pkl')
# 3. 定义参数网格
param_grid = {
'max_depth': [5, 6, 7], # 树的最大深度
'n_estimators': [50, 100, 150], # 树的数量
'learning_rate': [0.1, 0.3, 1.0]
}
# 4. 创建分层K折对象
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=23)
# 5. 创建网格搜索对象
gs = GridSearchCV(
estimator=model,
param_grid=param_grid,
cv=skf, # 使用分层K折
scoring='accuracy',
n_jobs=-1 # 并行计算
)
# 6. 训练
gs.fit(X_train, y_train)
# 7. 输出最优结果
print("最优参数:", gs.best_params_)
print("最优评分:", gs.best_score_)
# 8. 测试集评估
y_pred = gs.predict(X_test)
print("测试集准确率:", accuracy_score(y_test, y_pred))
六、XGBoost 目标函数与正则化
6.1 目标函数
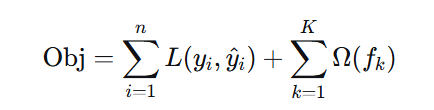
- 第一项:损失函数(拟合残差)
- 第二项:正则化项(控制模型复杂度)
6.2 正则化项
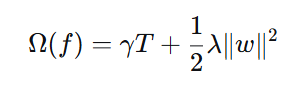
| 符号 | 含义 | 作用 |
|---|---|---|
| ( T ) | 叶子节点数量 | 惩罚复杂树结构 |
| ( \gamma ) | 叶子节点惩罚系数 | 控制是否分裂 |
| ( |w|^2 ) | 叶子节点输出值平方和 | 防止输出值过大 |
| ( \lambda ) | L2正则化系数 | 控制输出值大小 |
七、XGBoost API 总结
7.1 安装
pip install xgboost
7.2 Sklearn 风格常用参数
| 参数 | 说明 | 默认值 |
|---|---|---|
n_estimators |
树的数量 | 100 |
learning_rate |
学习率 | 0.1 |
max_depth |
树的最大深度 | 3 |
objective |
损失函数类型 | 'reg:squarederror' |
random_state |
随机种子 | None |
7.3 objective 参数取值
| 任务 | objective 值 |
|---|---|
| 回归 | 'reg:squarederror' |
| 二分类 | 'binary:logistic' |
| 多分类 | 'multi:softmax' |
| 多分类(输出概率) | 'multi:softprob' |
多分类时需额外指定
num_class参数(某些版本需要)
八、常见面试选择题
第1题:关于 XGBoost 的描述,错误的是?
- ✅ XGBoost = eXtreme Gradient Boosting 缩写
- ✅ 数据挖掘方面拥有更好的性能
- ✅ XGBoost 使用了正则化(L1/L2)
- ❌ XGBoost 不可以使用线性模型进行集成 → 错误,XGBoost 底层可用线性模型作为基学习器
第2题:关于正则化项的说法,错误的是?
- ✅ 使用 CART 回归树作为弱学习器
- ❌ 正则化项只包含一棵树的结果 → 错误,包含所有树
- ✅ 由叶子节点个数 + L2正则化项组成
- ✅ 可通过超参数调整惩罚力度
第3题:关于损失函数的描述,错误的是?
- ❌ 第 T 棵树的损失与第 T-1 棵树无关 → 错误,有关(残差拟合)
- ✅ 计算第 T 棵树时,前一棵树结构视为常数
- ✅ 使用了二阶泰勒展开
- ✅ 损失函数值越小,模型效果越好
第4题:关于树结构的描述,错误的是?
- ✅ 使用打分函数确定是否分裂
- ✅ 使用打分函数确定最佳分割点
- ✅
max_depth和min_samples_leaf可调节树结构 - ❌ 超参数 γ 的大小对树结构没有影响 → 错误,γ 控制叶子节点数量惩罚
九、一句话总结
| 阶段 | 核心要点 |
|---|---|
| 预处理 | 标签减3转0~5,分层采样,保存CSV |
| 训练 | 计算样本权重(解决不均衡),objective='multi:softmax' |
| 优化 | 分层K折交叉验证 + 网格搜索 |
| 保存 | joblib.dump() / joblib.load() |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 29
29 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)