FASTAPI进阶——中间件、依赖注入、orm操作数据库
目录
三、ORM(Object-RelationalMapping对象关系映射)
一、中间件
1、概念:
每一次请求进入fastapi都会被执行的函数
2、作用:
为每一个请求添加统一的处理逻辑(记录日志、身份认证、性能监控、设置响应头等)
3、代码方式:
main.py文件中添加如下代码
@app.middleware("http")
async def middleware1(request,call_next):
print("middleware1 starting~~~")
response = await call_next(request)
print("middleware1 ending~~~~")
return response
@app.middleware("http")
async def middleware2(request,call_next):
print("middleware2 starting~~~")
response = await call_next(request)
print("middleware2 ending~~~")
return response4、执行顺序:自下而上
上边代码执行结果,会先执行下边的middleware2 再执行 上边的middleware1

二、依赖注入
1、作用:
抽取可复用的通用的逻辑(比如:连接数据库、校验用户身份、处理分页参数等)单独抽离出来写成一个函数(即“依赖项”),实现代码复用,解耦且可轻松替换依赖项进行测试
2、与中间件对比:
中间件对应所有请求,所有请求都会过中间件。依赖注入系统只作用于注入的请求函数中
3、优点
代码复用:一次编写,可在多出注入后使用
解耦:业务逻辑与基础设施代码分离,便于修改
易于测试:轻松替换依赖项就可进行测试
4、使用场景
处理请求参数:从请求中提取和验证参数(路径、查询参数,请求体)
共享业务逻辑:抽取多个路由共用的逻辑代码
共享数据库连接:管理数据库对话的创建、使用和关闭(使用 yield 关键字——生成器)
安全和认证:验证用户身份、角色要求等
5、依赖注入的标准操作步骤
① 创建依赖项:定义一个普通的函数(或类),在里面实现你想要复用的公共逻辑
② 导包:from fastapi import Depends
③ 申明依赖项:在路径操作函数的参数中,使用 Depends(依赖项函数) 进行声明
# 第二步:导入Depends包
from fastapi import FastAPI,Depends
# 第一步:创建依赖项(定义公共分页逻辑)
async def common_parameters(
skip:int =Query(0,gt=0),
limit:int = Query(10,lt=50)
):
# 这里可以做更多复杂的分页逻辑处理
return {"skip":skip,"limit":limit}
# 第三步:在接口中导入并使用 Depends 声明依赖
@app.get("/news/list")
async def get_news(
# FastAPI 会自动调用 common_parameters,并把结果注入到 commons 变量中
commons = Depends(common_parameters)
):
return commons
@app.get("/books/list")
async def get_books(
# 同样的分页逻辑,一行代码直接复用
commons = Depends(common_parameters)
):
return commons代码解释:
自动调用与注入——当你访问 /news/list?skip=5&limit=20 时,FastAPI 会先拦截请求,发现接口需要 Depends(common_parameters)。它会自动提取 URL 中的 skip 和 limit 参数,调用 common_parameters函数,最后把返回的字典 {"skip": 5, "limit": 20} 赋值给 get_news 的 commons参数
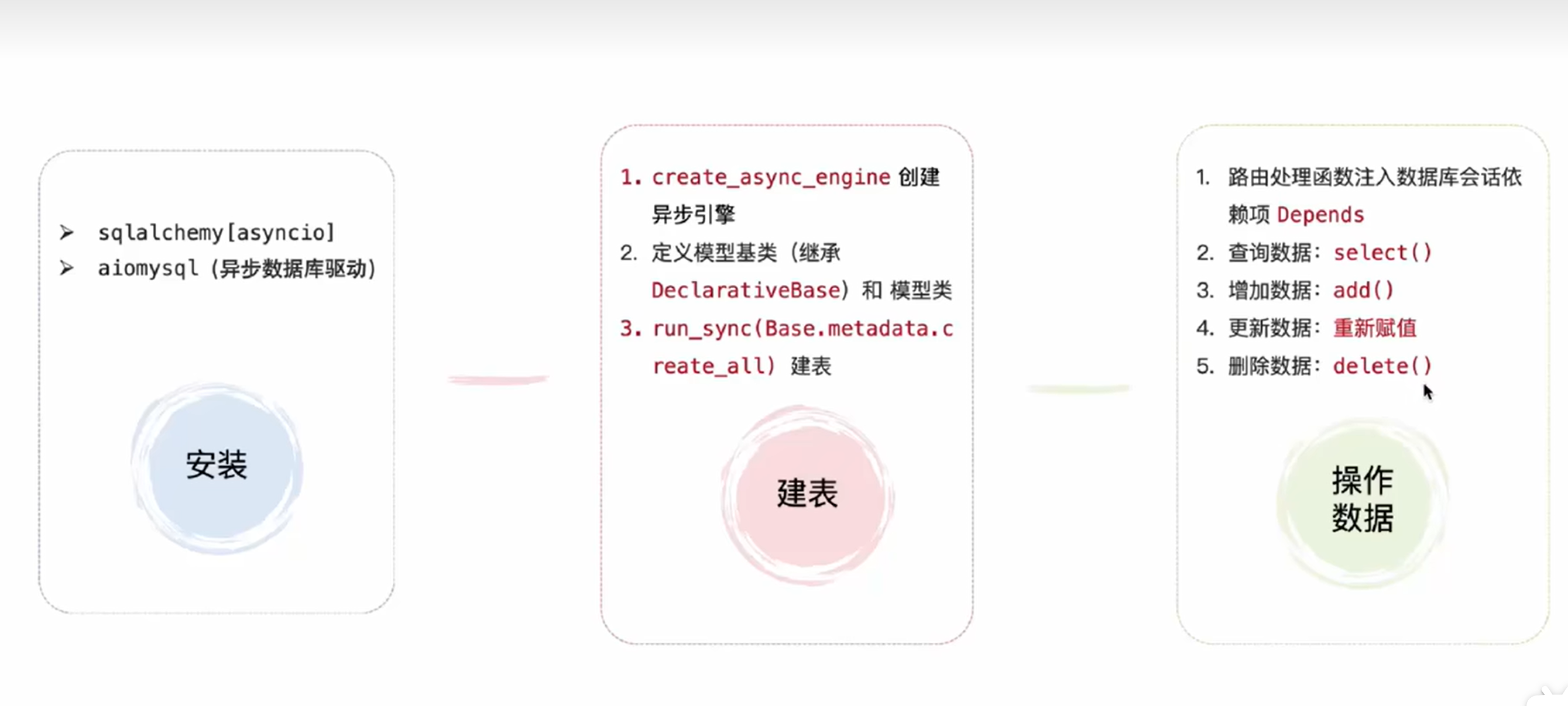
三、ORM(Object-RelationalMapping对象关系映射)
1. 作用:
用于面向对象编程语言和关系型数据库之间的建立映射,允许开发者通过操作对象的方式与数据库进行交互,而无需编写复杂的sql语句
2. 使用流程:
2.1 第一步:安装必要的依赖
安装 aiomysql、sqlalchemy[asyncio] 包
2.1.1 conda 环境安装
conda env list #查看都创建了那些虚拟环境
conda activate D:\soft\python_virtual_env\fastapi(环境名) #激活已经创建的环境
conda install 包名 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ # 在国内镜像站下载对应包
conda deactivate #退出当前环境2.1.2 pip 命令安装
D:\soft\python_virtual_env\fastapi\python.exe -m pip install aiomysql,"sqlalchemy[asyncio]" -i https://pypi.tuna.tsinghua.edu.cn/simple
2.2 第二步:配置数据库连接与模型定义
2.2.1 创建数据库引擎
创建数据库url
创建数据库引擎
from fastapi import FastAPI, Path, Query, HTTPException, Depends
from pydantic import BaseModel, Field
from fastapi.responses import FileResponse, HTMLResponse
from sqlalchemy.ext.asyncio import create_async_engine
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column
from datetime import datetime
from sqlalchemy import DateTime, func, String, Float, Integer
# 数据库url
async_database_url = "mysql+aiomysql://root:asd123456@127.0.0.1:3306/fastapi_first?charset=utf8"
# 创建数据库引擎,用于下边调用
async_engine = create_async_engine(
async_database_url,
echo=True, # 输出sql日志
pool_size=10, # 保持的持久连接数
max_overflow=20 # 允许创建的额外连接数
)2.2.2 定义模型类
创建基类——放置共用的属性
创建表模板,都有那些列 及其字段类型
# 定义模型
# 创建基类——放置共用的属性
class Base(DeclarativeBase):
creat_time: Mapped[datetime] = mapped_column(
DateTime, insert_default=func.now(), default=func.now, comment="创建时间")
update_time: Mapped[datetime] = mapped_column(
DateTime, insert_default=func.now(), default=func.now, onupdate=func.now(), comment="修改时间"
)
# 创建表模板,都有那些列 及其字段类型
class Student(Base):
__tablename__ = "student"
id: Mapped[int] = mapped_column(primary_key=True, autoincrement=True, comment="学生id")
name: Mapped[str] = mapped_column(String(255), comment="学生姓名")
age: Mapped[int] = mapped_column(Integer, comment="学生姓名")
score: Mapped[float] = mapped_column(Float, comment="分数")2.2.3 启动应用时建表
# 创建数据库表
async def creat_table():
# 获取异步引擎,创建事务、建表
async with async_engine.begin() as conn:
await conn.run_sync(Base.metadata.create_all)
@app.on_event("startup")
async def startup_event():
await creat_table()2.3 第三步:在 FastAPI 中实现 CRUD(Create\Read\Update\Delete) 接口
通过ORM查询图书
2.3.1 导包
from fastapi import FastAPI, Path, Query, HTTPException, Depends
from sqlalchemy.ext.asyncio import create_async_engine,async_sessionmaker,AsyncSession
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column
from datetime import datetime
from sqlalchemy import DateTime, func, String, Float, Integer, select2.3.2 创建异步会话工厂函数:
# 创建异步会话工厂
AsyncSessionLocal = async_sessionmaker(
bind=async_engine, # 绑定数据库引擎
class_=AsyncSession, # 指定会话类
expire_on_commit=False # 会话不过期,不重新查询数据库
)2.3.3 依赖项,用于获取数据库会话
# 依赖项,用于获取数据库会话
async def get_databases():
async with AsyncSessionLocal() as session:
try:
yield session # 返回数据库会话给路由处理函数
await session.commit() # 无异常提交事物
except Exception as e:
await session.rollback() # 出现异常事务回滚
raise
finally:
await session.close() # 关闭会话2.3.4 依赖注入、查询图书信息
@app.get('/student/list')
async def get_student(
db: AsyncSession = Depends(get_databases)
):
# 查询
result = await db.execute(select(Student))
student = result.scalars().all()
return student3. ORM操作数据
准备数据
insert into student(id, name, age, score,creat_time,update_time) values(1,"Tom",9,98,"2026-05-06 12:06","2026-05-06 12:31"),
(2,"Jerry",6,97,"2026-05-07 12:04","2026-05-07 12:31"),
(3,"DaHuang",10,99,"2026-05-07 12:05","2026-05-07 12:31"),
(4,"SuFei",6,89,"2026-05-07 12:06","2026-05-07 12:31");3.1 查询数据
核心思路:
基于数据库会话,执行 select,查询模型类
select() ->db.execute() -> 从ORM对象获取数据->响应结果
从ORM对象获取数据方式:
获取全部数据:scalars().all()
获取单条数据:
scalars().first() # 获取第一条数据
scalar_one_or_none()# 提取一条或null
scalar() # 提取标量值(配合聚合函数使用)
3.1.1 基础查询
获取所有数据:
@app.get('/student/list')
async def get_student(
db: AsyncSession = Depends(get_databases)
):
# 查询
result = await db.execute(select(Student))
student = result.scalars().all()
return student
基于数据库会话,执行 select,查询模型类
参数解读:
db :依赖注入后,形成的数据库会话
Student:上边定义的模型类(写法类似有create建表语句)
获取单条数据(第一条)
@app.get('/student/list')
async def get_student(
db: AsyncSession = Depends(get_databases)
):
# 查询
result = await db.execute(select(Student))
student = result.scalars().first()
return student获取指定主键的数据:
@app.get('/student/list')
async def get_student(
db: AsyncSession = Depends(get_databases)
):
student = await db.get(Student, 2)
return student3.1.2 条件查询
路径参数
@app.get("/student/{id}")
async def get_student_list(
id: int = Path(..., lt=50, gt=0),
db: AsyncSession = Depends(get_databases)
):
result = await db.execute(select(Student).where(Student.id == id))
book = result.scalar_one_or_none()
return book查询参数
@app.get("/student/student_list")
async def student_list(
score: float = Query(..., lt=100, gt=0, description="要查询分数"),
db: AsyncSession = Depends(get_databases)
):
result = await db.execute(select(Student).where(Student.score > score))
students = result.scalars().all()
return students3.1.3 模糊查询
@app.get("/student/search_student")
async def student_list(
db: AsyncSession = Depends(get_databases)
):
# 模糊查询姓名以T开头的
result = await db.execute(select(Student).where(Student.name.like("T%")))
students = result.scalars().all()
return students3.1.4 多个条件查询
注意:有多个条件时,每个条件都需要一个单独的括号 (条件一) & (条件二)
常用条件:
&: 与
| : 或
~ :非
==: 等于
!=: 不等于
@app.get("/student/search_student")
async def student_list(
score: float = Query(..., lt=100, gt=0, description="要查询分数"),
db: AsyncSession = Depends(get_databases)
):
# 模糊查询姓名以T开头的
list1 = [1, 2, 4]
result = await db.execute(select(Student).where((Student.id.in_(list1)) & (Student.score > score)))
students = result.scalars().all()
return students
3.1.5 范围查询
@app.get("/student/search_student")
async def student_list(
db: AsyncSession = Depends(get_databases)
):
# 模糊查询姓名以T开头的
list1 = [1, 2, 4]
result = await db.execute(select(Student).where(Student.id.in_(list1)))
students = result.scalars().all()
return students3.1.6 聚合查询
聚合查询:select(func.方法名(模型类.属性))
@app.get("/student/search_student")
async def student_list(
db: AsyncSession = Depends(get_databases)
):
# 聚合查询:select(func.方法名(模型类.属性))
# result = await db.execute(select(func.avg(Student.score)))
# result = await db.execute(select(func.max(Student.score)))
# result = await db.execute(select(func.min(Student.score)))
# result = await db.execute(select(func.sum(Student.score)))
result = await db.execute(select(func.count(Student.score)))
students = result.scalar() # 用来提取一个数值-> 标量值
return students3.1.7 分页查询
每页展示数量:page_size,跳过页数:page
offset:跳过的数量 = (page - 1) * page_size
limit:查询限制数
@app.get("/student/search_student")
async def student_list(
page: int = Query(1, gt=0, description="跳过的页数"),
page_size: int = Query(10, lt=50, gt=0, description="每页的数量"),
db: AsyncSession = Depends(get_databases)
):
skip = (page - 1) * page_size
result = await db.execute(select(Student).offset(skip).limit(page_size))
students = result.scalars().all()
return students3.2 新增数据
1、定义类型(因要使用请求体参数)
2、请求体参数拆包,转换为__dict__类型,通过模型类生成ORM对象
3、ORM对象->add->commit
# 定义类型
class StudentBase(BaseModel):
name: str = Field(..., max_length=20, description="学生姓名")
age: int = Field(default=18, lt=100, gt=10, description="学生年龄")
score: int = Field(default=60, lt=101, description="学生分数")
@app.post("/student/add_student")
async def add_student(
student:StudentBase,
db:AsyncSession = Depends(get_databases)
):
# ORM对象->add->commit
student_obj = Student(**student.__dict__)
db.add(student_obj)
await db.commit()
return student3.3 更改数据
先查后改->找到之后,重新赋值
# 更新数据、先查没有再改
# 定义类型
class StudentUpdate(BaseModel):
name: str = Field(..., max_length=20, description="学生姓名")
age: int = Field(default=18, lt=100, gt=10, description="学生年龄")
score: int = Field(default=60, lt=101, description="学生分数")
@app.put("/student/update/{stu_id}")
async def update_stundent(
data: StudentUpdate,
stu_id: int =Path(...,gt=0,description="要查询或更新学生id"),
db: AsyncSession =Depends(get_databases)
):
# 查找学生
db_student = await db.get(Student,stu_id)
# 判断有无要更新学生,没有抛出报错
if db_student is None:
raise HTTPException(
status_code=404,
detail="没有这个学生"
)
# 重新赋值
db_student.name = data.name
db_student.age = data.age
db_student.score = data.score
await db.commit()
return db_student
3.4 删除数据
先查后改->找到之后,删除
@app.delete("/student/delete/{stu_id}")
async def delete_student(
stu_id:int,
db:AsyncSession = Depends(get_databases)
):
db_student =await db.get(Student,stu_id)
if db_student is None:
raise HTTPException(
status_code=404,
detail="Not find the student!"
)
await db.delete(db_student)
await db.commit()
return {"message": f"student {stu_id} deleted!"}4. orm总结

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)