山东大学软件学院创新实训(四)
前言
上周我们完成了 RAG 检索增强生成和视觉题目识别两大核心功能,让 AI 错题本具备了基础的智能。本周,我重点推进了错因分析报告生成和个性化推题两大功能,让系统成为能初步诊断问题、推荐方案的智能学习助手。
一、错因分析报告
1.1 为什么需要错因分析?
传统的错题本只记录"题目 + 正确答案",但学生真正需要的是:
(1)我为什么错了?(概念理解错误?计算失误?方法选择错误?)
(2)我的知识漏洞在哪里?(具体到哪个知识点没掌握)
(3)我该怎么改进?(针对性的学习建议和练习方向)
错因分析功能就是要回答这三个问题,让每一道错题都成为学习的契机。
1.2 技术架构设计
错因分析的核心流程分为三个阶段:
用户提交错题 → RAG 检索相关知识 → AI 生成结构化报告
关键技术点:
知识库构建:从 LaTeX 教材中提取知识点,向量化存储到 FAISS。
相似度检索:根据题干内容检索最相关的 5 个知识点片段。
结构化输出:强制 AI 返回 JSON 格式,包含错误类型、知识薄弱点、正确解法、学习建议等字段。
1.3 核心代码实现
(1)错因知识库构建脚本
本来打算从docx和pdf文件中提取知识点并导入知识库,但由于公式是以图片的形式呈现的,提取后往往会出现断片的情况,导致知识点极不完整,所以我选择从公共资源上找到的 LaTeX 教材中提取知识点:
class ErrorAnalysisKBBuilder:
"""错因分析知识库构建器"""
def extract_from_latex(self, tex_file, subject="数学"):
"""从LaTeX文件中提取知识点"""
with open(tex_file, 'r', encoding='utf-8') as f:
content = f.read()
# 提取章节结构
chapter_pattern = r'\\chapter\{([^}]+)\}'
section_pattern = r'\\section\{([^}]+)\}'
subsection_pattern = r'\\subsection\{([^}]+)\}'
chapters = re.findall(chapter_pattern, content)
sections = re.findall(section_pattern, content)
subsections = re.findall(subsection_pattern, content)
# 按 subsection 粒度组织知识点
for i, subsection in enumerate(subsections):
knowledge_text = f"【章节】{current_chapter}\n【节】{current_section}\n【知识点】{subsection}"
# 提取该知识点下的内容(简化:取后续500字符)
idx = content.find(subsection)
if idx != -1:
following_content = content[idx:idx + 500]
clean_content = re.sub(r'\\[a-zA-Z]+\{[^}]*\}', '', following_content)
knowledge_text += f"\n\n【内容】{clean_content[:300]}"
knowledge_points.append({
'content': knowledge_text,
'metadata': {
"subject": subject,
"source": os.path.basename(tex_file),
"type": "knowledge_point",
"chapter": current_chapter,
"section": current_section,
"subsection": subsection
}
})
执行后在 data/ 目录生成:
kb_error_analysis.index - FAISS 索引文件
kb_error_analysis.docs.json - 文档和元数据
(2)RAG 服务的错因分析接口
def generate_error_analysis(self, question_stem: str, user_answer: str,
correct_answer: str, user_id: str = "system",
top_k: int = 5) -> Dict:
"""
生成错因分析报告
"""
try:
logger.info(f"开始生成错因分析 - UserId: {user_id}")
# 1. 从错因知识库检索相关知识点
docs = self.vector_store.similarity_search(question_stem, k=top_k)
if not docs:
knowledge_context = "暂无相关知识点"
else:
knowledge_parts = []
for i, doc in enumerate(docs, 1):
content = doc.get('content', '')
metadata = doc.get('metadata', {})
chapter = metadata.get('chapter', '')
section = metadata.get('section', '')
subsection = metadata.get('subsection', '')
knowledge_parts.append(
f"【知识点 {i}】{chapter} > {section} > {subsection}\n{content[:200]}"
)
knowledge_context = "\n\n".join(knowledge_parts)
# 2. 构建错因分析提示词
analysis_prompt = self.error_analysis_prompt.format(
question_stem=question_stem,
user_answer=user_answer if user_answer else "未提供",
correct_answer=correct_answer if correct_answer else "未提供",
knowledge_context=knowledge_context
)
# 3. 调用AI生成错因分析
messages = [
{"role": "system", "content": "你是一个专业的数学教育专家。"},
{"role": "user", "content": analysis_prompt}
]
response = self.ai_service.client.chat.completions.create(
model=settings.ai.model,
messages=messages,
temperature=0.5,
max_tokens=2000
)
result_text = response.choices[0].message.content
# 4. 解析JSON结果
try:
# 清理大模型可能返回的 Markdown 代码块标记
cleaned_text = result_text.strip()
# 处理以 ```json 开头的情况
if cleaned_text.startswith("```json"):
cleaned_text = cleaned_text[7:]
# 处理以 ``` 开头的情况
elif cleaned_text.startswith("```"):
cleaned_text = cleaned_text[3:]
# 处理以 ``` 结尾的情况
if cleaned_text.endswith("```"):
cleaned_text = cleaned_text[:-3]
# 处理 LaTeX 反斜杠转义问题
import re
cleaned_text = re.sub(r'\\(?!["\\/bfnrtu])', r'\\\\', cleaned_text)
# 再次去除首尾空白字符
cleaned_text = cleaned_text.strip()
# 尝试解析 JSON
analysis_report = json.loads(cleaned_text)
except json.JSONDecodeError as e:
# 捕获 JSON 解析错误,返回安全默认值
logger.warning(f"JSON解析失败,原始内容: {result_text[:100]}... Error: {e}")
analysis_report = {
"error_type": "未知",
"error_description": result_text,
"knowledge_gaps": [],
"correct_approach": "",
"study_suggestions": [],
"similar_topics": []
}
logger.info(f"错因分析生成完成(降级返回)- UserId: {user_id}")
return analysis_report关键设计思考:
- temperature=0.5:错因分析需要稳定性和准确性,不能使用过高的随机性。
- JSON 解析容错:大模型可能返回 Markdown 代码块或转义字符,需要多层清理。
- 降级策略:如果 JSON 解析失败,仍返回原始文本,避免服务中断。
(3)消息队列集成
在消费者中新增错因分析任务处理器:
def handle_error_analysis_task(self, task): """处理错因分析任务""" user_id = task.get('user_id') question_stem = task.get('question_stem') user_answer = task.get('user_answer', '') correct_answer = task.get('correct_answer', '')
logger.info(f"收到错因分析任务 - UserId: {user_id}")
# 调用RAG服务生成错因分析
report = rag_service.generate_error_analysis(
question_stem=question_stem,
user_answer=user_answer,
correct_answer=correct_answer,
user_id=user_id,
top_k=5
)
# 将报告发送给Java端
result_message = {
"task_type": "error_analysis_result",
"user_id": user_id,
"report": report,
"timestamp": datetime.now().isoformat()
}
self.channel.basic_publish(
exchange='',
routing_key='error-analysis-result-queue',
body=json.dumps(result_message, ensure_ascii=False),
properties=pika.BasicProperties(delivery_mode=2)
)1.4 运行效果
当用户提交一道积分计算错误的题目时,系统返回的错因分析报告如下:
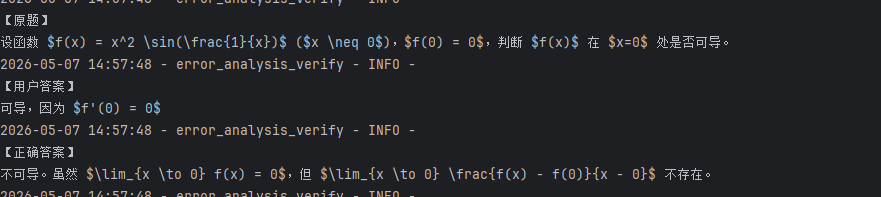
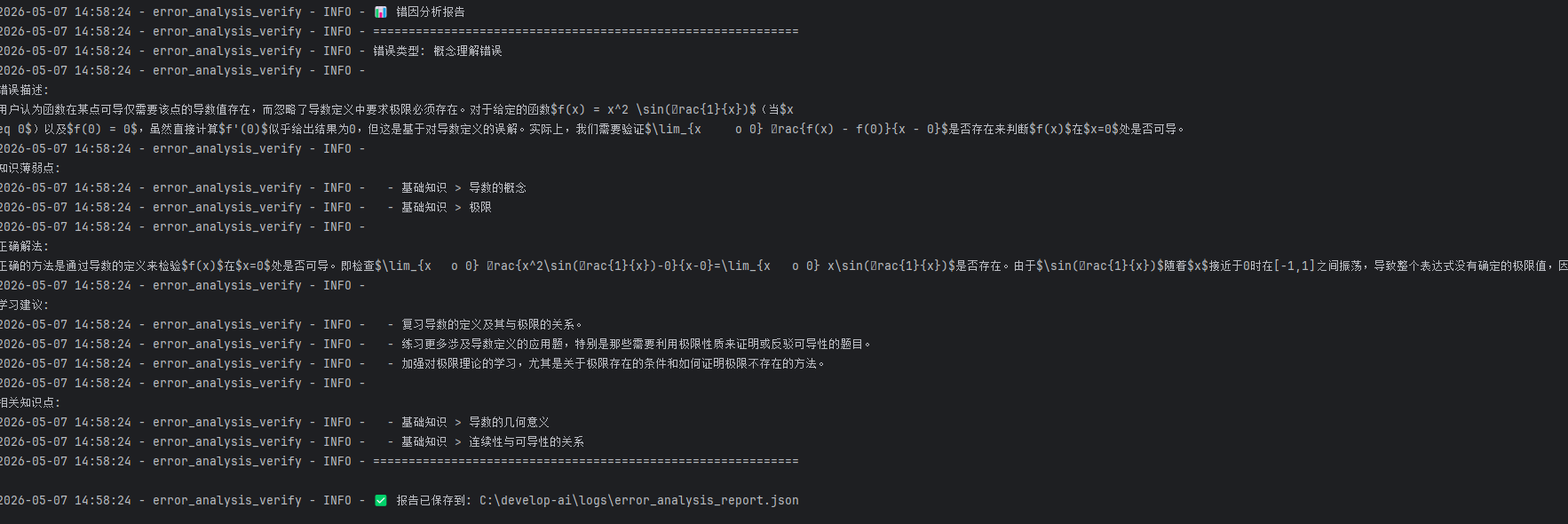
可以看出错误类型精确到不同的分类(概念理解错误/计算错误/方法选择错误/审题不清等等),且知识薄弱点具体到知识点名称,学习建议也具有较强的可操作性。
二、个性化推题
2.1 功能需求与实现思路
推题系统设计上采用"用户画像 + 向量检索"的双层架构,即先通过MySQL 统计用户薄弱标签,再使用FAISS 检索相似题目。
但是目前在数据库数据有限的情况下,我们先采用纯向量检索的方式实现推题功能,核心思路是:
用户输入/识别题目 → FAISS 向量库语义检索 → 返回最相似的 Top 3 题目
这种方案只要有题库向量库就能工作,且基于句子嵌入的相似度搜索,比关键词匹配更智能。
2.2 技术实现方案
(1)题库向量库构建
我们目前从本地 DOCX 考研真题文档构建题库向量库:
def import_from_local_docs(self):
"""从本地考研文档中提取题目并导入题库"""
subjects = {
"math": "数学",
"english": "英语",
"politics": "政治"
}
for folder_name, subject_name in subjects.items():
folder_path = os.path.join(base_dir, folder_name)
docx_files = glob.glob(os.path.join(folder_path, "*.docx"))
for docx_file in docx_files:
questions = self._extract_questions_from_docx(docx_file, subject_name)
if questions:
texts = [q['content'] for q in questions]
metadatas = [q['metadata'] for q in questions]
self.rag_service.add_knowledge(texts, metadatas)
题目提取逻辑使用正则表达式识别题干模式:
def _extract_questions_from_docx(self, file_path, subject):
"""从DOCX文档中提取结构化题目"""
doc = Document(file_path)
questions = []
current_question = {}
for para in doc.paragraphs:
text = para.text.strip()
# 匹配题目开头:第1题、第2题、【题目 1】等格式
question_match = re.match(r'^(?:第?(\d+)[题\.、]|【题目[\s]*(\d+)[\s]*】)', text)
if question_match:
# 保存上一道题
if current_question and 'stem' in current_question:
content = f"题目:{current_question['stem']}\n答案:{current_question.get('answer', '')}\n解析:{current_question.get('analysis', '')}"
questions.append({
'content': content,
'metadata': {
"subject": subject,
"source": os.path.basename(file_path),
"type": "question"
}
})
# 开始新题目
current_question = {'stem': text, 'answer': '', 'analysis': ''}
elif '答案' in text or '正确答案' in text:
current_question['answer'] = text
elif '解析' in text or '分析' in text:
current_question['analysis'] = text
else:
current_question['stem'] += '\n' + text
return questions
(2)向量检索核心方法
在 FAISSStore 类中实现了 search_similar 方法,支持语义相似度搜索:
def search_similar(self, query_text: str, k: int = 3) -> List[Dict]:
"""根据题干文本搜索同类题"""
# 1. 在 FAISS 中进行向量相似度搜索
docs = self.similarity_search(query_text, k=k)
# 2. 收集所有 topic_id(如果有)
topic_ids = []
for doc in docs:
topic_id = doc['metadata'].get("topic_id")
if topic_id:
topic_ids.append(topic_id)
# 3. 如果找到了 topic_id,从 MySQL 获取完整信息
if topic_ids:
from database.mysql_client import mysql_client
try:
placeholders = ','.join(['%s'] * len(topic_ids))
sql = f"""
SELECT id, stem as questionStem, correct_answer as answer,
analysis, tags, subject, create_time as createTime
FROM topic
WHERE id IN ({placeholders}) AND deleted = 0
"""
topics = mysql_client.execute_query(sql, tuple(topic_ids))
# 转换为前端需要的格式
result = []
for topic in topics:
result.append({
"id": topic['id'],
"title": topic.get('subject', '未知科目'),
"questionStem": topic['questionStem'],
"questionStemPictureUrls": [],
"answer": topic.get('answer', ''),
"answerPictureUrls": [],
"createTime": str(topic.get('createTime', '')),
"labels": []
})
return result
except Exception as e:
logger.error(f"从MySQL获取题目详情失败: {str(e)}")
# 4. 降级方案:直接返回向量库中的简化格式
return [{
"id": doc['metadata'].get("topic_id"),
"title": doc['metadata'].get("subject", '未知'),
"questionStem": doc['content'],
"questionStemPictureUrls": [],
"answer": "",
"answerPictureUrls": [],
"createTime": None,
"updateTime": None,
"labels": []
} for doc in docs]
关键技术点:
- 两级检索策略:先在 FAISS 快速筛选候选集,再从 MySQL 获取完整信息。
- 降级容错机制:如果 MySQL 查询失败,仍返回向量库中的基础信息。
- 数量限制:默认 k=3,避免推送过多题目造成用户负担。
2.3 测试效果演示
执行 测试文件,输出结果如下:

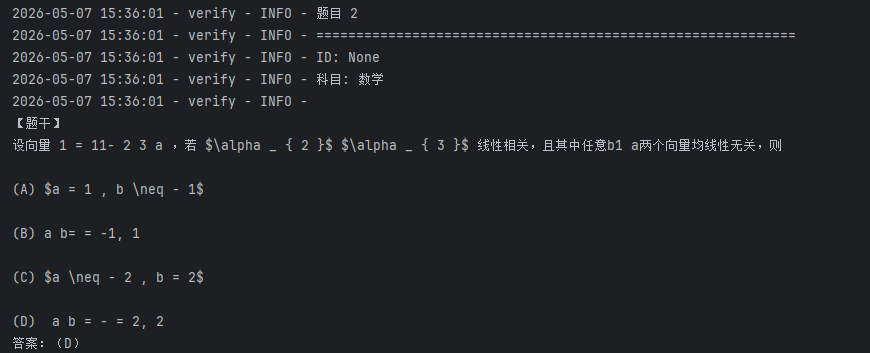
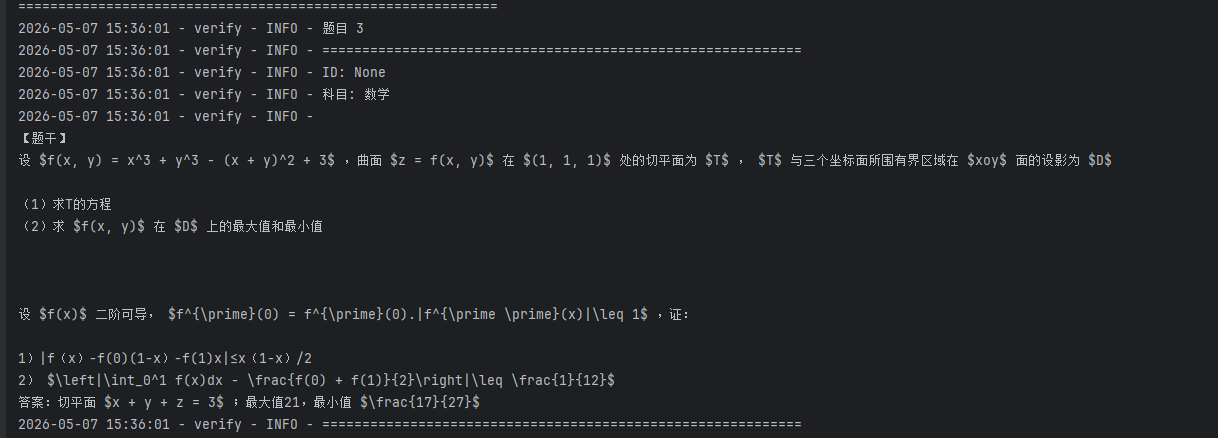
可以看到系统查询"导数与微分的计算",推送了三道有关的微积分题目,且这些题目格式规范统一,自动清理了"题目:"、"答案:"等前缀,具有较好的可读性。
2.4 与图片分析功能的集成
在视觉识别场景中,我们也集成了类似题推送功能:
def on_picture_message(self, ch, method, properties, body):
"""处理图片分析任务(增强版:错因分析 + 类似题推送)"""
# 1. 调用视觉模型识别题目
result = ai_service.analyze_image(url)
question_stem = result.get("question_stem", "")
# 2. 基于识别结果,检索类似题目(最多3道)
similar_questions = []
if question_stem:
try:
similar_questions = rag_service.vector_store.search_similar(
question_stem,
k=3 # 严格限制3道题
)
logger.info(f"检索到 {len(similar_questions)} 道类似题目")
except Exception as e:
logger.warning(f"类似题检索失败: {str(e)}")
# 3. 构建响应
response = {
"requestId": request_id,
"questionStem": question_stem,
"analyseQuestion": result.get("analysis", ""),
"suggestLabels": result.get("tags", []),
"recommendTopics": similar_questions # 新增:类似题列表
}
这样用户拍照录入错题后,不仅能得到题目解析,还能立即获得 3 道类似的练习题进行巩固。
三、总结与规划
本周的开发使得错题本从一个题目"记录工具"变成了"智能学习助手"。它不仅能识别题目、回答问题,更能诊断错误原因、推荐学习方案。这种从"被动记录"到"主动指导"的转变,正是 AI 技术在教育领域的核心价值所在。
最初我直接把检索到的知识丢给 AI,结果生成的分析报告泛泛而谈。后来我在提示词中明确要求"错误类型必须从设计的几种中选择"、"知识薄弱点要具体到知识点名称",效果显著提升。这也让我意识到了提示词的重要性:好的提示词工程 = 清晰的约束 + 具体的示例 + 结构化的输出要求
目前的系统已经具备了"诊断 + 推荐"的核心能力,但仍有一些优化空间。后续将实现向量检索与传统数据库的互补,同时优化推送算法,真正实现:用户历史错题 → MySQL 统计薄弱标签 → FAISS 检索相似题目 → 去重排序 → 推送 的"用户画像 + 向量检索"的双层架构,做到个性化精准推题。同时进一步扩充知识库和题库,增加多样性控制,避免同一知识点下推送过于相似的题目。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)