如何使用Python调用大模型LLM API
文章目录
背景
在AI重塑行业的今天,掌握大模型LLM开发技能是核心竞争力,本博客作为快速Python AI教程,将从0开始,用Python代码完成对现如今主流AI大模型(ChatGPT/Gemini/Claude,对标国内为DeepSeek/KiMi/Qwen)的API调用。
总之就是快速了解LLM API原理,然后低成本在我们的项目中构建AI生态系统。
我们此处的项目背景就是:
我在一个项目流程中使用爬虫等技术获取了返回的文本内容,比如说是文献文本数据等,我想要直接使用AI来获取文献的初步知识概览,也就是自动化执行文献阅读(初步的工作),我应该如何将这个LLM的API整合到我的项目代码中,以便于我可以直接在执行项目命令的同时,自动化调用LLM来帮助我阅读文献。
(PS:依旧是去年的囤货,想想还是放出来)
DeepSeek API使用
下面我们以DeepSeek的API调用文档为例,进行解释说明。
首次调用API
参考:https://api-docs.deepseek.com/zh-cn/
DeepSeek API使用与OpenAI兼容的API格式,通过修改配置,我们可以使用OpenAI SDK来访问DeepSeek API,或使用与OpenAI API兼容的软件。
| PARAM | VALUE |
|---|---|
| base_url * | https://api.deepseek.com |
| api_key | apply for an API key |

API key获取:https://platform.deepseek.com/api_keys
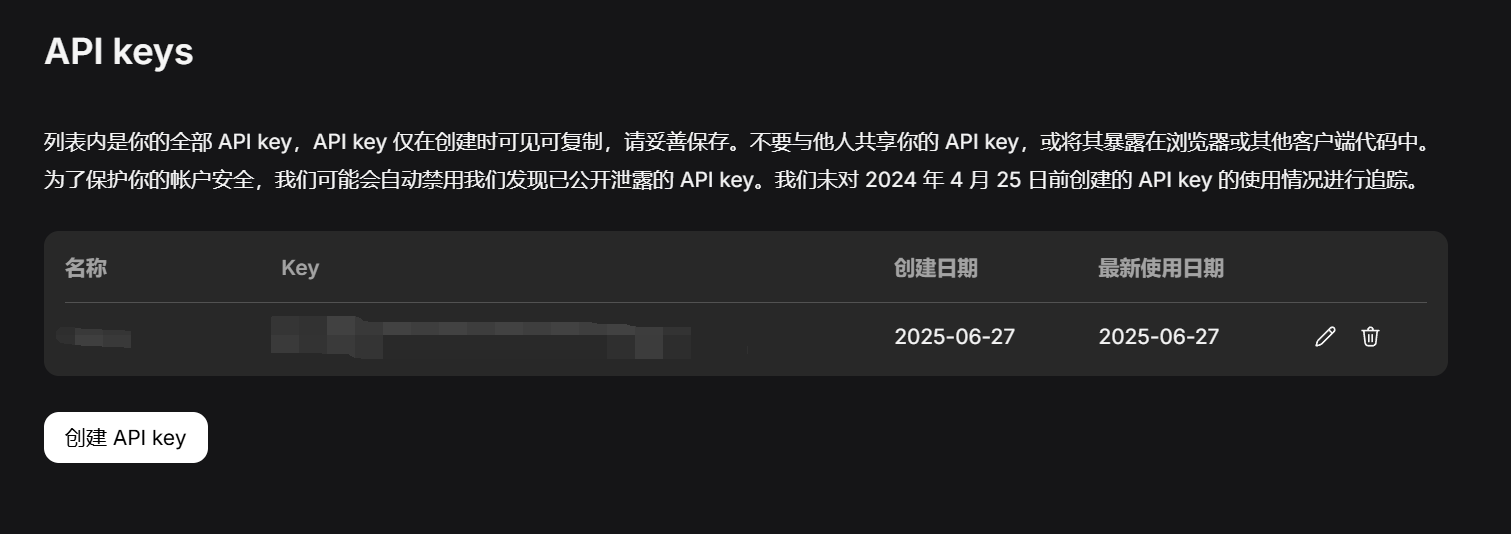
调用对话API
在创建API key之后,我们可以使用以下样例脚本来访问DeepSeek。
样例为非流式输出,我们可以将stream设置为true来使用流式输出。
首先需要安装openai这个库
pip3 install openai
紧接着:
# Please install OpenAI SDK first: `pip3 install openai`
# 安装 OpenAI SDK(如果尚未安装)
import os
# 导入必要的模块和类
from openai import OpenAI
# 使用环境变量中的 API 密钥和指定的 API 地址创建一个 OpenAI 客户端
client = OpenAI(
api_key=os.environ.get('DEEPSEEK_API_KEY'),
base_url="https://api.deepseek.com")
# 向 DeepSeek 的聊天模型发送一个包含系统消息和用户消息的请求
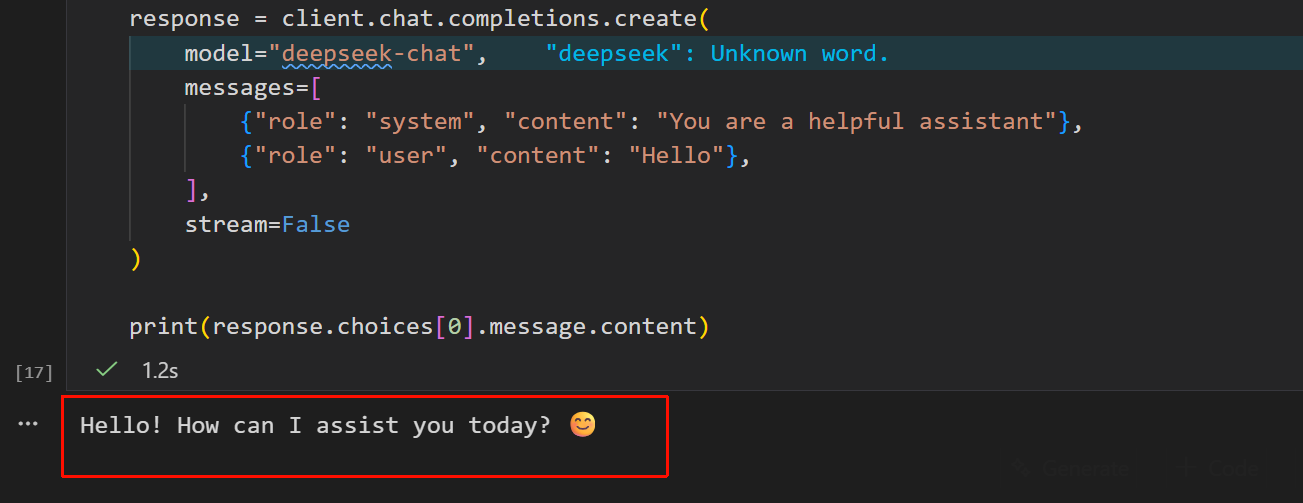
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False
)
# 打印模型返回的回复
print(response.choices[0].message.content)
这里为了安全考虑,我没有显示输入我的api key,而是设置在环境变量中。
如何在环境变量中设置这个api key?
- 临时设置环境变量,直到终端会话结束:在终端中export即可
export DEEPSEEK_API_KEY="your_api_key_here"
- 永久设置,编辑 ~/.bashrc 或 ~/.zshrc 文件(取决于我们使用的shell):同样在文件末尾
export DEEPSEEK_API_KEY="your_api_key_here"
其实就和我们安装软件设置环境变量一样的场景
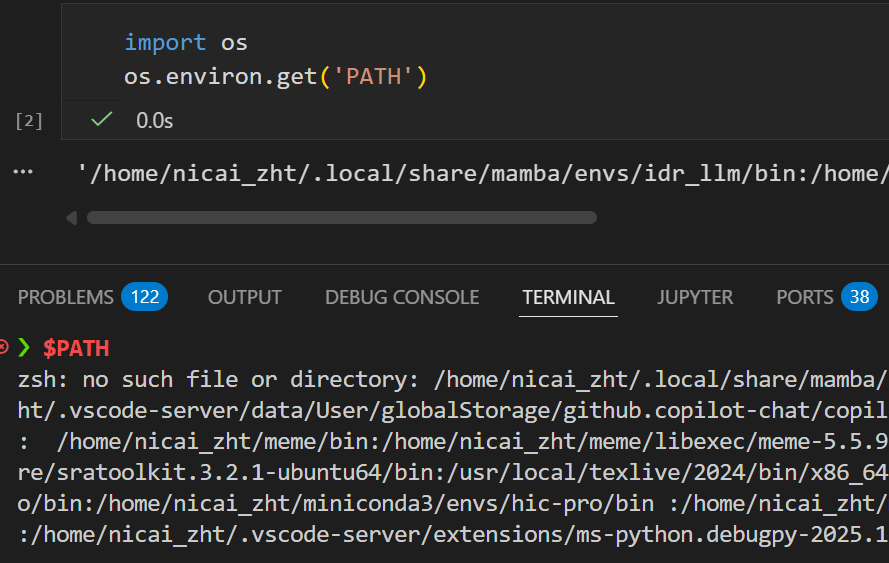
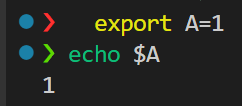

如果我们只是在notebook中简单测试用,如果还是用!+shell命令的话,
要注意magic command也就是!命令的执行逻辑是:
- 临时启动一个独立的系统终端子进程
- 在这个子进程中执行export xxx
- 子进程执行完毕以后立即退出,其内部的环境变量也会随之销毁
- 当前运行python代码的主进程,完全无法获取子进程中设置的环境变量
也就是Jupyter/IPython 中的 ! 魔法命令会启动独立子进程,子进程中设置的环境变量无法传递给当前 Python 主进程。
要么我们永久设置环境变量,
我们我们不用shell,也就是不无意识地手动创建1个与主进程的环境变量所隔离的子进程。
我们可以直接在python的主进程中设置环境变量。
举例来说:

我们可以直接设置
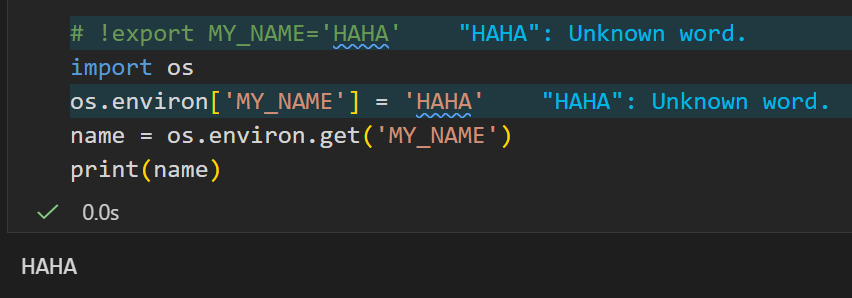
所以,我们可以直接设置
os.environ['DEEPSEEK_API_KEY']="复制粘贴下来的api key"
运行之后报错:

参考:https://api-docs.deepseek.com/zh-cn/quick_start/error_codes

参考充值页面:https://platform.deepseek.com/usage
可以看到我们确实没钱了
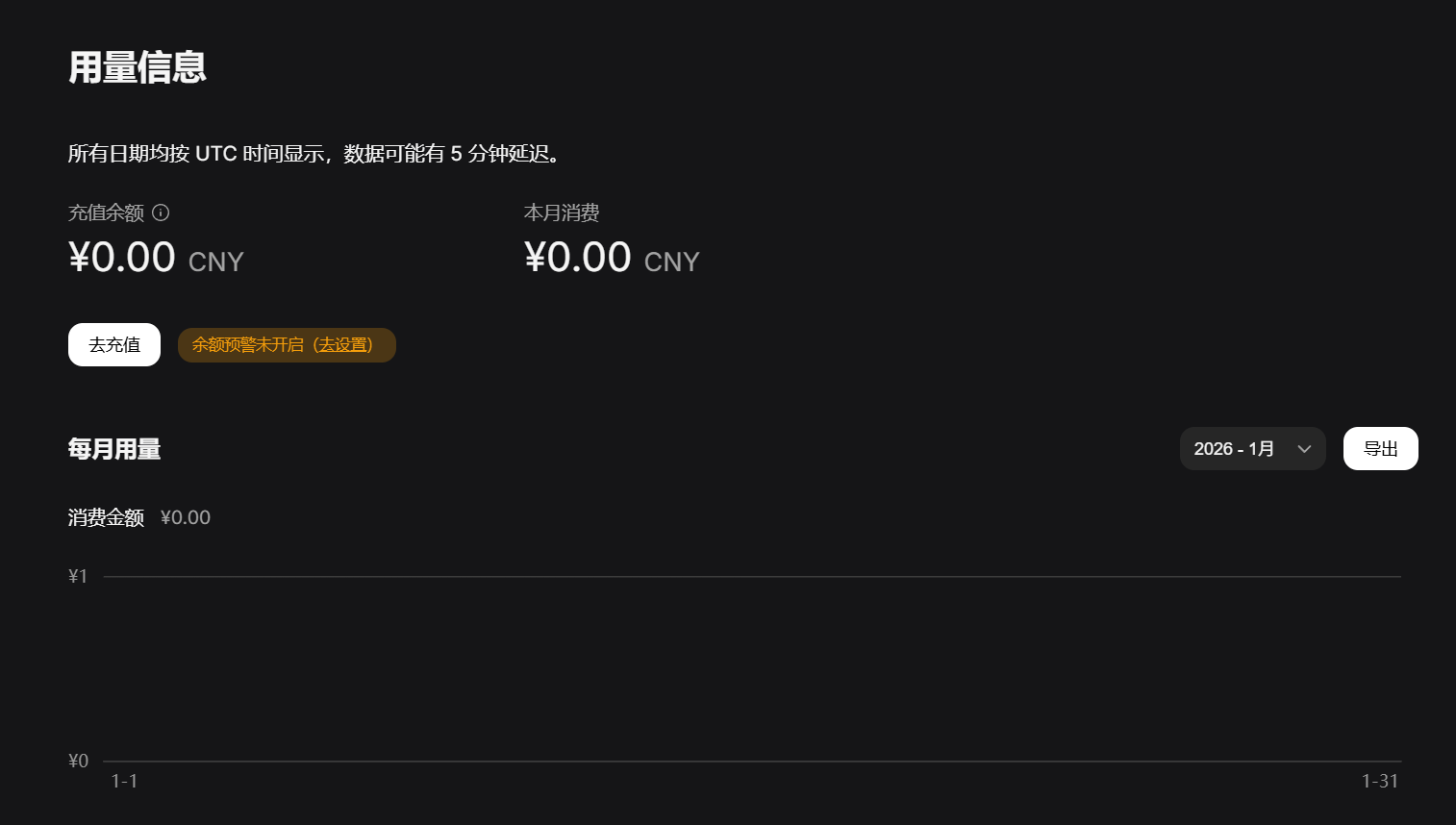
此处为了演示效果,我毅然决然地充了一点钱进去,
关于token价格,可以参考:https://api-docs.deepseek.com/zh-cn/quick_start/pricing/
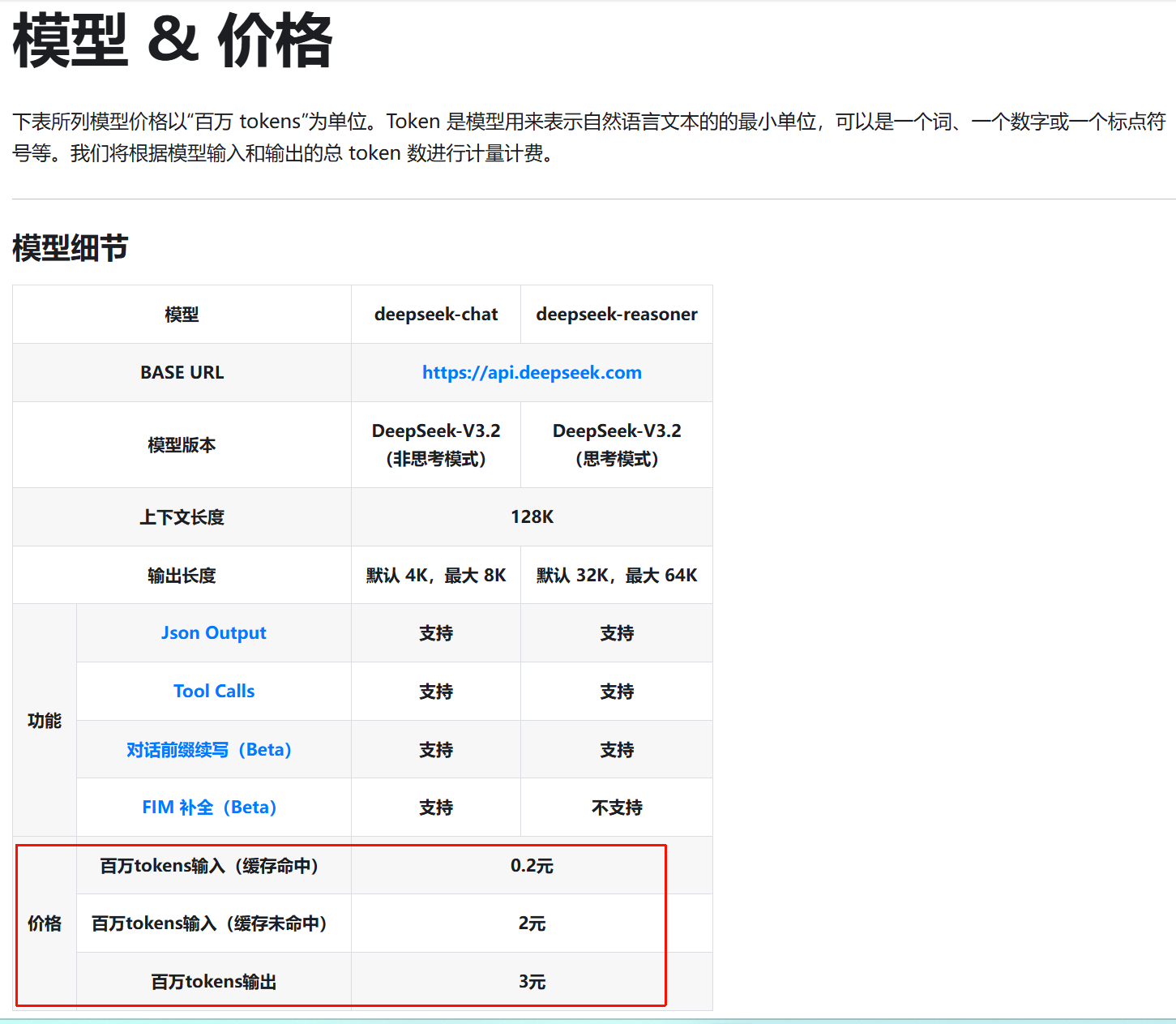
我们在这里先小充一下
现在我们有了账户余额,再来到我们前面的代码中:成功了
参考:https://stackoverflow.com/questions/40832533/pip-or-pip3-to-install-packages-for-python-3
pip 和 pip3 的核心区别是绑定的 Python 版本不同:
pip:默认绑定Python 2(部分环境中若仅装了 Python 3,pip会被映射为 Python 3 的 pip,属于兼容设置)。pip3:明确绑定Python 3,无论环境如何配置,都会给 Python 3 安装包。
由于 Python 2 早已停止维护,现在开发 / 使用均推荐用pip3,避免包安装到废弃的 Python 2 环境中。
# 查看pip绑定的Python版本
pip --version
# 查看pip3绑定的Python版本
pip3 --version

API文档
查询余额
参考:https://api-docs.deepseek.com/zh-cn/api/get-user-balance
import requests
# 要访问的 DeepSeek API 端点,这个 URL 用于查询用户账户余额信息
url = "https://api.deepseek.com/user/balance"
payload={}
headers = {
'Accept': 'application/json',
'Authorization': 'Bearer <TOKEN>'
}
# 使用 requests 库发起一个 GET 请求到指定 URL,并传入自定义请求头和数据
response = requests.request("GET", url, headers=headers, data=payload)
print(response.text)
我这里的输出如下:
{"is_available":true,"balance_infos":[{"currency":"CNY","total_balance":"9.99","granted_balance":"0.00","topped_up_balance":"9.99"}]}
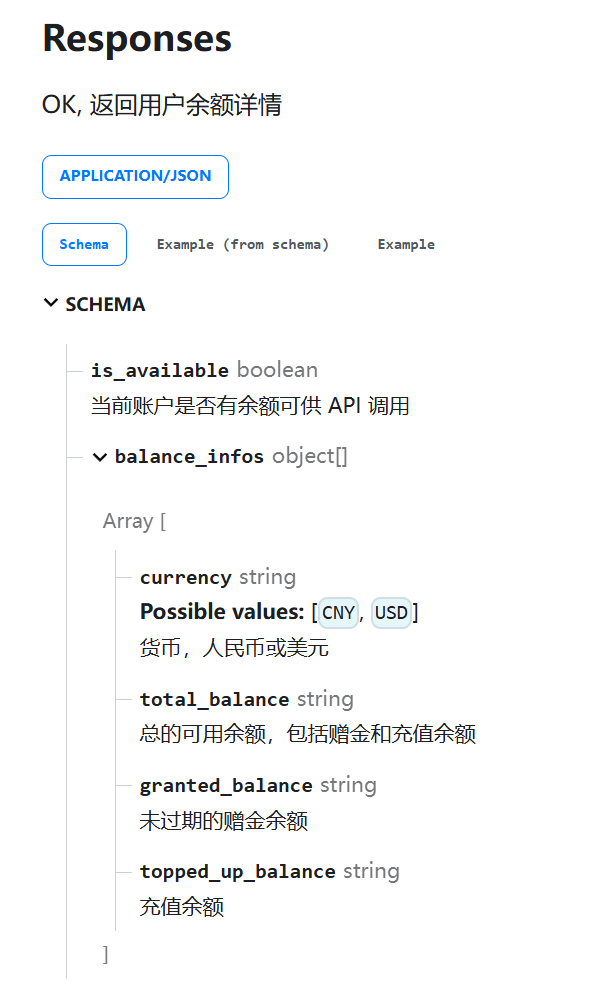
对照之下,可以看到,我们当前账户中还有余额可供API调用;
用的货币是人名币,然后账号余额是9.99,全是我们充值的余额,可以看到我们前面那么简单的一次hello对话已经消耗了1分钱了。
列出模型
参考:https://api-docs.deepseek.com/zh-cn/api/list-models
列出可用的模型列表,并提供相关模型的基本信息。请前往模型 & 价格查看当前支持的模型列表
from openai import OpenAI
# for backward compatibility, you can still use `https://api.deepseek.com/v1` as `base_url`.
# 创建一个OpenAI类的实例(即客户端对象),用于与指定的API进行交互
client = OpenAI(api_key="<your API key>", base_url="https://api.deepseek.com")
# 调用客户端对象的models.list()方法,获取模型列表
print(client.models.list())
输出如下:

很明显可以看到,就只有2个model可用
SyncPage[Model](
data=[
Model(id='deepseek-chat', created=None, object='model', owned_by='deepseek'),
Model(id='deepseek-reasoner', created=None, object='model', owned_by='deepseek')
], object='list')
关于对话,以及对话补全内容
可以参考:https://api-docs.deepseek.com/zh-cn/api/create-chat-completion
基本上快速入门使用就是前面那个简易API使用示例
API指南
DeepSeek中大部分的API使用指南,都值得一看,此处暂时只讲我们用得到的,也就是我们前面背景中提到的文献阅读自动化任务。
JSON Output

import json
from openai import OpenAI
client = OpenAI(
api_key="<your api key>",
base_url="https://api.deepseek.com",
)
system_prompt = """
The user will provide some exam text. Please parse the "question" and "answer" and output them in JSON format.
EXAMPLE INPUT:
Which is the highest mountain in the world? Mount Everest.
EXAMPLE JSON OUTPUT:
{
"question": "Which is the highest mountain in the world?",
"answer": "Mount Everest"
}
"""
user_prompt = "Which is the longest river in the world? The Nile River."
messages = [{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}]
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
response_format={
'type': 'json_object'
}
)
print(json.loads(response.choices[0].message.content))
Anthropic API
参考:https://api-docs.deepseek.com/zh-cn/guides/anthropic_api
除了DeepSeek API
1,API 为什么是连接 AI 大模型的最佳方式?
2025年,AI 技术爆发,大模型(LLM)能力指数级增长。对于开发者,通过 API 调用 AI 大模型 是性价比最高的选择。
- 无需训练:训练 大模型 需百万美元算力,调用 LLM API 仅需几分钱。
- 开箱即用:通过 API,即刻拥有 GPT-5 等全球最强 AI 能力。
- 弹性扩展:API 支持高并发,云端 AI 大模型 稳定响应。
学会调用 LLM API,是 AI 开发的起点。
2,AI 大模型 (LLM) 与 API 的工作机制?
什么是 AI 大模型 (LLM)?
大模型(LLM)是基于深度学习的超级 AI 大脑。这些 AI 大模型 阅读海量数据,具备理解语言、推理逻辑、编写代码的能力。
什么是 API?
API 是连接代码与 AI 大模型 的桥梁。通过 HTTP 向 LLM API 发送 Prompt,AI 思考后将结果通过 API 返回。全过程无需懂深度学习,只需会写 Python。
- API 是 “接口规范”,而非直接的 “传输通道”:API(应用程序编程接口)的本质是一套约定好的通信规则(比如规定请求用 POST 方式、JSON 格式、要传 api-key 参数,响应也用 JSON 格式、包含 result 字段等),而非物理通道;HTTP 是实现这套 API 规则的传输协议,简单说:API 是 “沟通的语言”,HTTP 是 “说这种语言的电话线路”。
- API 的 “返回” 是 “HTTP 响应”,而非直接返回内容:大模型的结果不会直接 “通过 API 返回”,而是先按照 API 的约定格式,把结果封装成HTTP 响应数据(比如 JSON 格式),再通过 HTTP 协议传回,API 只是保证了 “发什么格式、收什么格式” 的一致性,让代码能稳定解析结果。
个人简单总结如下:
我们通过编写代码构造包含prompt(提示词)的请求内容,再通过 LLM 提供的API 接口向大模型服务器发送标准化的 HTTP 请求;大模型服务器接收到请求后,根据 prompt 执行模型推理计算,最终将推理结果通过API 接口以标准化的 HTTP 响应形式返回给我们,我们再通过代码解析这个返回结果。
LLM API 调用的核心流程?
正常调用LLM的API流程如下:
- 编写代码:我们用python的requests库,构造符合LLM API规范的请求(设置请求方式为POST,请求头包含api-key,请求体是JSON格式,其中key为prompt,value是我们要问的问题)
- 发送请求:代码通过HTTP协议,将构造好的请求发送到我们目的LLM的API服务地址(一般是一个公网url)
- 服务器处理:我们的目标LLM的API服务器验证请求合法性(比如说api-key是否有效),验证通过后,将prompt传给后台的LLM推理集群,执行模型推理计算
- 返回响应:推理完成后,API服务器将结果封装成JSON格式的HTTP响应,通过HTTP协议传回给我们的代码
- 解析结果:我们代码进一步读取HTTP响应,解析出JSON中的结果字段,最终得到大模型的输出内容
我们以前面调用DeepSeek的API为例进行展开说明:
先明确2个核心概念
1. AI大模型(LLM,以DeepSeek-chat为例)
部署在厂商云端专用推理集群的深度学习模型,基于Transformer架构,经海量文本/知识数据预训练后,具备自然语言理解、生成、逻辑推理等能力;是纯软件化的计算模型,运行依赖高算力服务器,本地设备无法直接运行,只能通过远程调用实现能力复用。
2. LLM API(以DeepSeek兼容OpenAI的API为例)
厂商制定的跨系统通信规范,配套公网访问地址和身份验证密钥,是本地程序与云端大模型的标准化交互规则;该规范基于HTTP协议实现,定义了「请求的格式/参数/验证方式」和「响应的格式/字段/错误类型」,让本地程序无需了解大模型底层实现,即可远程调用其能力。
补充:SDK的核心作用(无代码但必须明确)
SDK是封装了HTTP底层通信逻辑的工具集,核心价值是替本地程序完成「按API规范构造请求、发送HTTP请求、解析HTTP响应」的所有工作,让本地程序只需按简单规则传递参数,即可实现与云端的交互。
LLM API 远程调用8步核心技术流程
步骤1:本地程序初始化SDK,配置API核心参数
本地程序调用SDK的初始化功能,传入厂商API的2个核心配置:
api_key:厂商颁发的身份验证密钥,作为本地程序的“调用凭证”;base_url:厂商API的公网访问地址,作为云端API服务器的“网络定位”。
SDK接收到配置后,会生成符合该厂商API规范的通信实例,为后续请求做好准备。
步骤2:本地程序向SDK传递Prompt及调用参数
本地程序按SDK的规则,传递2类核心信息给SDK:
- Prompt内容:包含大模型的角色定义(如“你是一个实用助手”)、用户的实际指令/问题(如“解释什么是LLM API”),是大模型的推理依据;
- 调用参数:如指定要调用的大模型型号(如deepseek-chat)、结果返回方式(如一次性返回/流式返回)、推理精度限制等,是对大模型推理过程的规则约束。
步骤3:SDK按API规范,构造标准化HTTP请求
SDK接收到Prompt和调用参数后,会严格遵循厂商API的规范,完成HTTP POST请求的全量构造:
- 将Prompt、模型型号、返回方式等参数,按API规定的格式(如JSON)拼接成HTTP请求体;
- 将
api_key按API规定的方式(如请求头)加入HTTP请求头,作为身份验证标识; - 结合
base_url和API规范的接口路径(如/chat/completions),拼接成完整的HTTP请求地址; - 设定HTTP请求的协议版本、编码方式、超时时间等基础属性,最终生成符合HTTP协议+厂商API规范的完整请求包。
步骤4:SDK通过网络,向云端API服务器发送HTTP请求
SDK基于计算机的网络协议栈(TCP/IP),将构造好的HTTP请求包,通过互联网发送到步骤1配置的base_url对应的云端API服务器,完成本地到云端的请求传输。
步骤5:云端API服务器验证请求的合法性
云端API服务器接收到HTTP请求后,首先执行请求合法性校验,校验不通过则直接返回对应的HTTP错误响应(如401未授权、400请求格式错误),流程终止;校验内容包括:
- 验证请求头中的
api_key是否有效(是否存在、是否未过期、是否有对应模型的调用权限); - 验证请求体的格式、参数是否符合API规范(如是否缺少模型型号、Prompt格式是否错误);
- 验证本地程序的调用配额、频率是否超出厂商限制(如单小时调用次数是否超限)。
步骤6:验证通过,API服务器转发请求至大模型推理集群
云端API服务器完成合法性校验后,会将请求体中的Prompt和调用参数,按厂商内部的通信规则,转发给云端大模型推理集群(真正运行LLM的高算力服务器集群),并指定推理的模型型号和规则约束。
步骤7:大模型推理集群执行推理计算,返回结果至API服务器
- 大模型推理集群接收到Prompt和参数后,加载指定型号的LLM(如deepseek-chat),基于模型的神经网络和预训练知识,执行token级的概率推理计算:将Prompt拆分为最小语义单元(token),通过模型的注意力机制和计算逻辑,逐个预测并拼接出符合语义、逻辑的回复token序列,最终生成完整的推理结果;
- 推理完成后,推理集群将最终结果+推理耗时+token使用量等信息,返回给云端API服务器。
步骤8:API服务器封装响应,SDK解析后回传本地程序
- 云端API服务器接收到大模型的推理结果后,按API规范将结果、耗时、token量等信息封装成标准化HTTP响应包(如JSON格式,包含结果字段、状态码、附加信息),通过互联网回传给本地SDK;
- 本地SDK接收到HTTP响应包后,按API规范解析响应内容,提取出大模型的核心推理结果,并将结果回传给本地程序;
- 本地程序获取到推理结果后,可进行展示、存储、二次处理等后续操作,整个API调用流程完成。
简单总结
本地程序→SDK(配参数/封请求)→互联网→云端API服务器(验权限/转请求)→大模型推理集群(做计算/出结果)→云端API服务器(封响应)→互联网→SDK(解响应/提结果)→本地程序。
(本地代码用 SDK 配置 API 规则 → SDK 封装 Prompt 成标准 HTTP 请求发给 DeepSeek → DeepSeek 验证后让大模型推理 → SDK 解析云端的 HTTP 响应成 Python 对象 → 提取并打印大模型回复)。
整个流程的核心是API规范的标准化和SDK对HTTP底层的封装,让本地程序与云端大模型的跨系统交互变得简单、稳定。
3,构建标准化 AI 大模型开发环境
1,获取通用 LLM API 密钥
管理不同厂商 API 比较繁琐,通过 API 聚合平台(如 n1n.ai),可以使用通用 LLM API Key。
- 注册账号。
- 生成
<font style="color:rgb(36, 41, 46);background-color:rgba(27, 31, 35, 0.05);">sk-</font>开头的 API 令牌。 - 此 Key 可调用所有主流 AI 大模型。
就是这种API平台应该很多,其实网上找能够找到一大堆,只不过付费的占多,免费的占少,
比如说前面提到的:
前面我演示的是我个人花销的DeepSeek的API,真实使用时其实费用也是很大的,所以有必要找一些免费的LLM API,可能不是很稳定,但是在这里测试用已经够了。
Github上能够找到一些收集以及免费提供API的仓库,
参考:https://github.com/popjane/free_chatgpt_api

我们后面的演示都以此例子为准(注意免费的LLM API变动大,此处例子仅以测试使用时时间为准):

点击前面那个小火箭的url链接,进入的是一个需要github账号授权访问的网站,能够拿到免费的api-key。
开发者github仓库文档中所列出的一些支持应用,多是一些调用api的二次开发产品

我们更多的还是直接调用这个API,用openAI的官方python库。
参考:https://github.com/openai/openai-python
在openai官方库开发时传入baseurl和apikey即可。
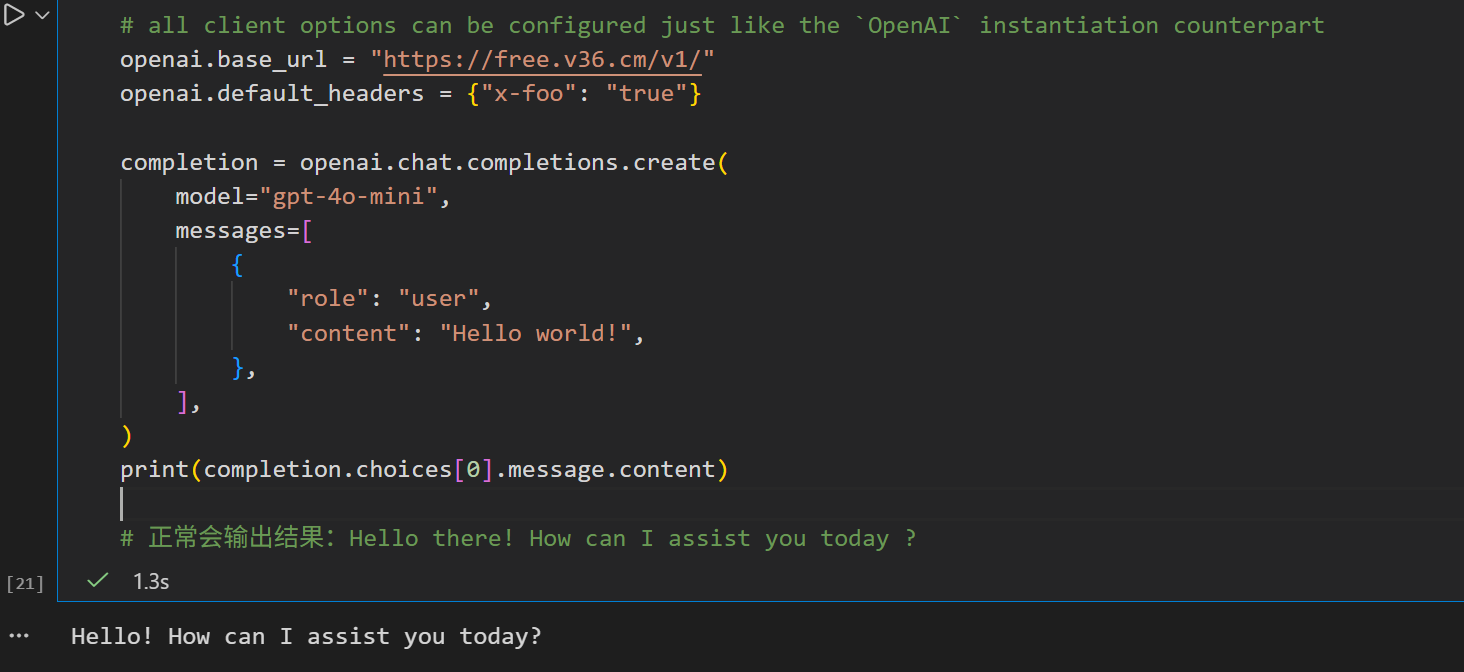
以官网的python库为例:注意,需要传入/v1/后缀。并且openai库需升级到最新版,老版本传参格式不一样,具体参考官方py库文档。
import os
import openai
# optional; defaults to `os.environ['OPENAI_API_KEY']`
openai.api_key = "您的APIKEY"
# all client options can be configured just like the `OpenAI` instantiation counterpart
openai.base_url = "https://free.v36.cm/v1/"
openai.default_headers = {"x-foo": "true"}
completion = openai.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": "Hello world!",
},
],
)
print(completion.choices[0].message.content)
# 正常会输出结果:Hello there! How can I assist you today ?
当然简单的hello world我们当然不稀罕,我们此篇博客的目的是为了能够用上尽可能先进的model来帮我们自动化阅读并处理文献。
所以我这里就简单测试了一个例子,我用了一篇简单文献的摘要,来询问gpt-4o-mini,主要是主题概括、核心要点、使用方法、得出结论的总结概要。
import os
import openai
# optional; defaults to `os.environ['OPENAI_API_KEY']`
openai.api_key = "这里就按照前面方式获取"
# all client options can be configured just like the `OpenAI` instantiation counterpart
openai.base_url = "https://free.v36.cm/v1/"
openai.default_headers = {"x-foo": "true"}
completion = openai.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": "(A central challenge in the study of intrinsically disordered proteins is the characterization of the mechanisms by which they bind their physiological interaction partners. \
Here, we utilize a deep learning-based Markov state modeling approach to characterize the folding-upon-binding pathways observed in a long timescale molecular dynamics simulation of a disordered region of the measles virus nucleoprotein N(TAIL) reversibly binding the X domain of the measles virus phosphoprotein complex. \
We find that folding-upon-binding predominantly occurs via two distinct encounter complexes that are differentiated by the binding orientation, helical content, and conformational heterogeneity of N(TAIL). \
We observe that folding-upon-binding predominantly proceeds through a multi-step induced fit mechanism with several intermediates and do not find evidence for the existence of canonical conformational selection pathways. \
We observe four kinetically separated native-like bound states that interconvert on timescales of eighty to five hundred nanoseconds. \
These bound states share a core set of native intermolecular contacts and stable N(TAIL) helices and are differentiated by a sequential formation of native and non-native contacts and additional helical turns. \
Our analyses provide an atomic resolution structural description of intermediate states in a folding-upon-binding pathway and elucidate the nature of the kinetic barriers between metastable states in a dynamic and heterogenous, or 'fuzzy', protein complex.) ——— how to understand this abstract? Please give me a simple explanation, a summary of what this paper talks about/what is the main idea of this paper/what is the key point of this paper/what method is used in this paper/what conclusion is drawn in this paper.",
},
],
)
print(completion.choices[0].message.content)
可以看到,我的问题如下:
how to understand this abstract? Please give me a simple explanation, a summary of what this paper talks about/what is the main idea of this paper/what is the key point of this paper/what method is used in this paper/what conclusion is drawn in this paper
返回的回答如下:
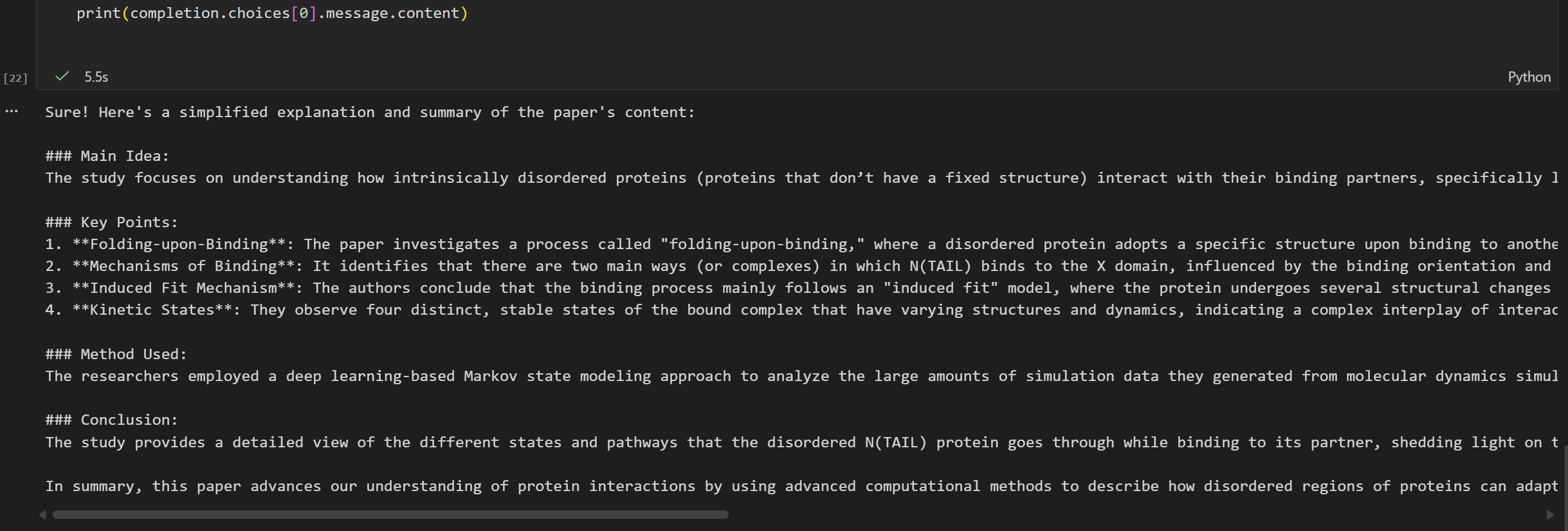
Sure! Here's a simplified explanation and summary of the paper's content:
### Main Idea:
The study focuses on understanding how intrinsically disordered proteins (proteins that don’t have a fixed structure) interact with their binding partners, specifically looking at how a region of the measles virus nucleoprotein (N(TAIL)) folds and binds to another protein (the X domain of the phosphoprotein).
### Key Points:
1. **Folding-upon-Binding**: The paper investigates a process called "folding-upon-binding," where a disordered protein adopts a specific structure upon binding to another molecule.
2. **Mechanisms of Binding**: It identifies that there are two main ways (or complexes) in which N(TAIL) binds to the X domain, influenced by the binding orientation and the folding state of N(TAIL).
3. **Induced Fit Mechanism**: The authors conclude that the binding process mainly follows an "induced fit" model, where the protein undergoes several structural changes as it binds, rather than selecting a preformed structure (conformational selection).
4. **Kinetic States**: They observe four distinct, stable states of the bound complex that have varying structures and dynamics, indicating a complex interplay of interactions even in the bound state.
### Method Used:
The researchers employed a deep learning-based Markov state modeling approach to analyze the large amounts of simulation data they generated from molecular dynamics simulations over long timescales.
### Conclusion:
The study provides a detailed view of the different states and pathways that the disordered N(TAIL) protein goes through while binding to its partner, shedding light on the dynamic nature of these interactions and the complexities involved in their folding. This could help understand how such proteins function in biological processes despite their lack of fixed structures.
In summary, this paper advances our understanding of protein interactions by using advanced computational methods to describe how disordered regions of proteins can adapt and change structure while binding to other proteins.
为了方便展示一下格式以及内容,截图如下:


1个简单token上下文的问题,花费时间大概在5.5 s,还行。
2,安装python环境
其实主要是安装 OpenAI SDK(兼容大多数 LLM API),前面也提过了这个SDK安装的作用,简化HTTP请求、解析等,封装好了
pip3 install openai
4,Python 代码接入 LLM API 接口
核心配置:
base_url: API 地址。api_key: 身份 令牌。model: AI 大模型 名称。
import os
from openai import OpenAI
# 1. 配置 AI API 客户端
# base_url 指向 聚合地址,连接全球 AI 大模型
client = OpenAI(
base_url="各大厂商api服务地址, 或免费API提供的聚合地址",
api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" # 你的 LLM API 密钥
)
# 2. 调用 AI 大模型
def call_llm(prompt):
print("连接云端 AI 大模型...")
try:
# 发送 LLM API 请求
completion = client.chat.completions.create(
model="gpt-4o", # 可切换 claude-3-5 或国产 AI 大模型, 仅此处举例
messages=[
{
"role": "system", "content": "你是一个 AI 专家。"},
{
"role": "user", "content": prompt}
]
)
# 3. 获取 AI 回复
return completion.choices[0].message.content
except Exception as e:
return f"API 调用出错: {str(e)}"
# 3. 运行
if __name__ == "__main__":
print(call_llm("解释 LLM API 的原理"))

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)