▲基于DE-SARSA强化学习的跳频通信系统智能抗干扰策略matlab仿真
目录
✅1.问题描述
基于DE-SARSA(TS)的跳频系统智能抗干扰决策算法是一种面向复杂电磁环境的深度强化学习方法。该算法将Dyna架构(模型学习)、Expected SARSA(期望时序差分学习)和Thompson Sampling(汤普森采样)三种机制有机结合,解决了传统跳频抗干扰系统在面对多类型干扰共存场景下的自适应决策难题。在现代电子战环境中,通信系统需要同时应对高斯白噪声、窄带干扰、宽带干扰和扫频干扰等多种威胁,DE-SARSA(TS)算法通过智能学习实现最优跳频参数的自主选择,显著提升系统生存能力。
DE-SARSA(TS)算法的完整执行流程为:初始化Q表和模型参数→感知当前干扰状态→Thompson采样结合Tanh退火选择动作→执行动作获取奖励→Expected SARSA更新Q值→更新Dyna模型→执行模型规划→更新Thompson参数→转移至下一状态。该算法通过模型学习加速收敛、通过概率探索避免局部最优、通过期望更新降低估计方差,三重机制协同工作,在复杂干扰环境中实现了快速稳定的智能抗干扰决策。
✨2.状态-动作空间建模原理
状态空间设计:以每个时隙对应的干扰电磁环境作为马尔可夫决策过程的状态。状态集合定义为:
![]()
分别对应无干扰、窄带干扰、宽带干扰、扫频干扰和复合干扰五种典型电磁环境类型。
动作空间设计:动作由跳频速率hr、信号瞬时带宽bw和频率序列模式fs三个维度联合构成:
![]()
动作空间总维度为∣A∣=∣H∣×∣B∣×∣F∣,本算法中为4×4×4=64个离散动作。
🚀3. Expected SARSA学习原理
Expected SARSA是SARSA算法的改进形式,使用下一状态所有动作的期望Q值代替单个采样动作的Q值,降低了更新方差。其核心更新公式为:
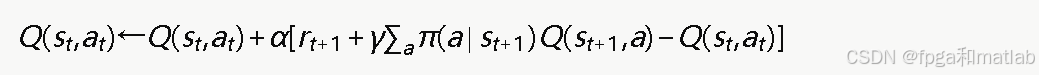
其中α为学习率,γ为折扣因子,π(a∣st+1)为策略在下一状态选择各动作的概率分布。策略概率通过Softmax函数计算:
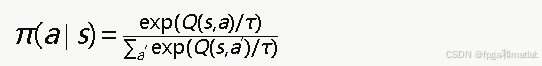
其中ττ为温度参数,控制策略的随机性程度。
💡4. Dyna模型架构集成
Dyna架构的核心思想是通过构建环境模型来加速学习。算法在与真实环境交互的同时,维护一个内部环境模型M^,记录历史经验的状态转移和奖励信息:
![]()
每次真实交互后,算法从已访问的状态-动作对中随机采样kk个经验,利用模型进行虚拟规划更新:
![]()
Dyna模型使算法在有限的真实交互样本下获得更多学习机会,显著提升收敛速度。每步实际交互后执行k=5次模型规划,等效将样本效率提升数倍。
🎂5. 奖励函数设计
奖励函数综合考虑抗干扰效果和资源消耗,有效信干噪比计算为:
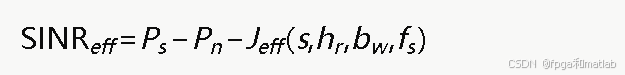
其中干扰抑制效果Jeff与动作参数相关,高跳频速率对扫频干扰抑制效果更强,大带宽对宽带干扰适应性更好。综合奖励函数为:
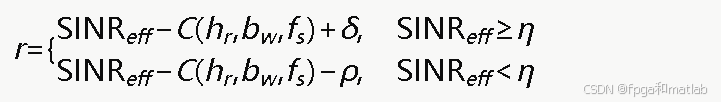
其中C(⋅)为资源消耗代价函数,η为信噪比门限,δ和ρ分别为成功通信奖励和通信失败惩罚。
💼6.MATLAB程序
num_freq_channels = 16; % 可用频率信道数
num_hop_rates = 4; % 跳频速率等级数
num_bandwidths = 4; % 信号瞬时带宽等级数
num_freq_sequences = 4; % 频率序列模式数
num_states = 5; % 状态数(干扰环境类型)
num_actions = num_hop_rates * num_bandwidths * num_freq_sequences; % 动作空间维度
num_episodes = 1000; % 训练回合数
max_steps = 200; % 每回合最大步数
gamma = 0.95; % 折扣因子
alpha = 0.1; % 学习率
dyna_steps = 5; % Dyna规划步数
SNR_threshold = 10; % 信噪比门限(dB)
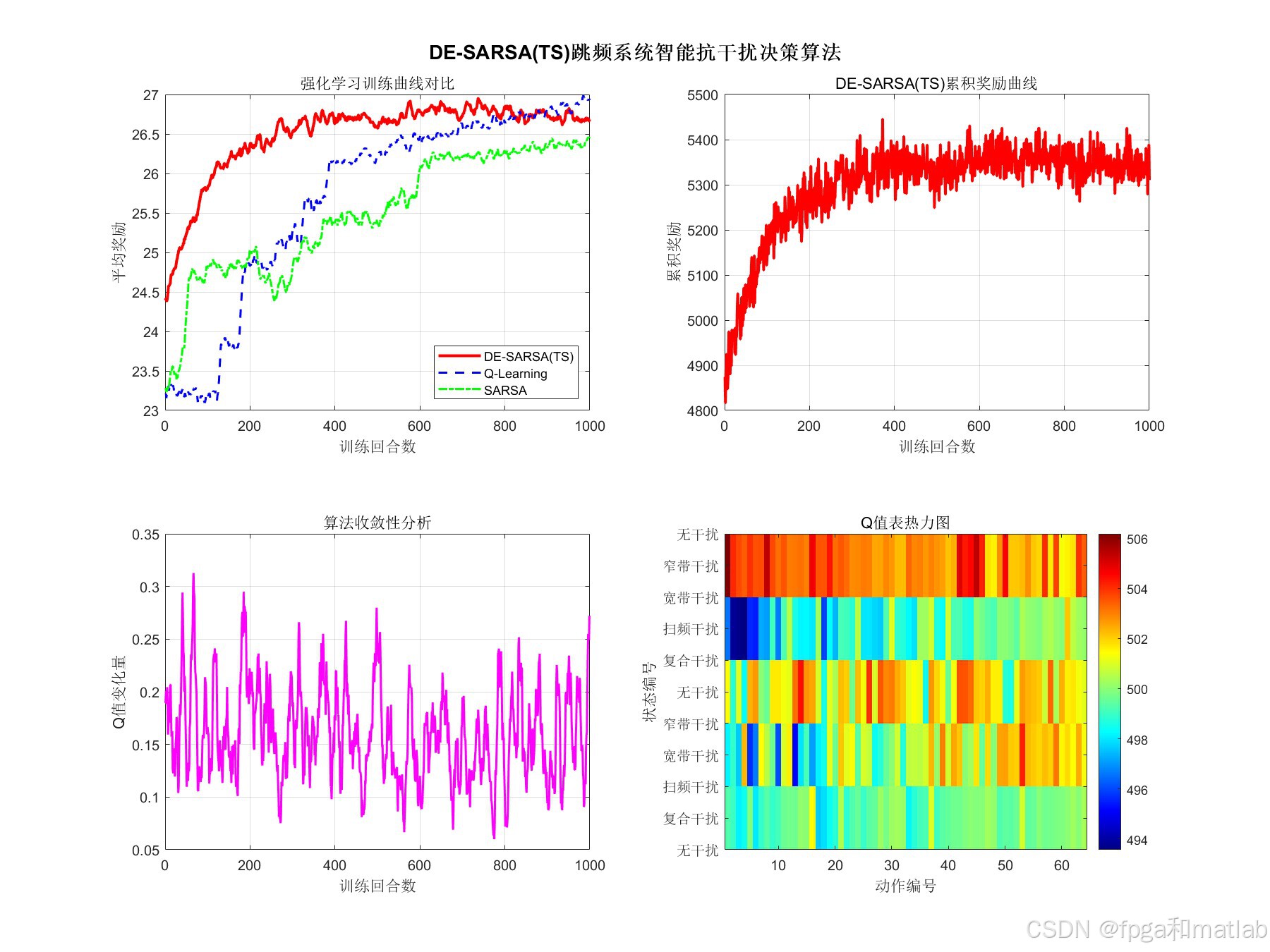
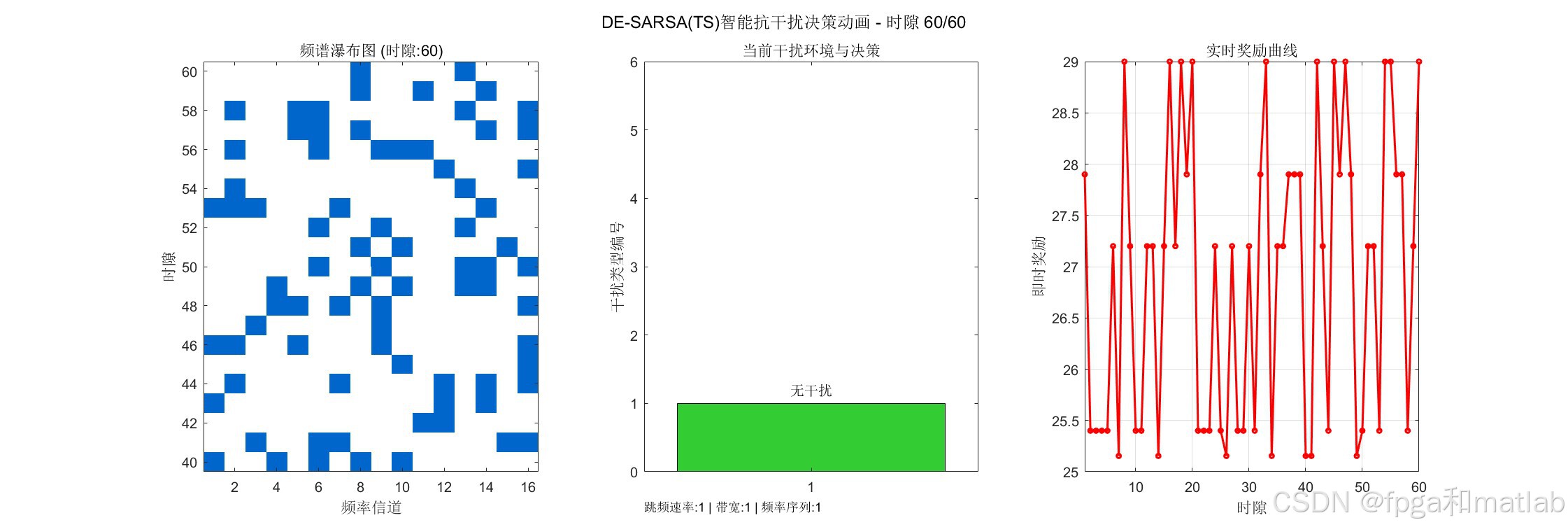
💡7.仿真结果分析
👇8.完整程序下载
完整可运行代码,博主已上传至CSDN,使用版本为MATLAB2024b:
(本程序包含程序操作步骤视频)
基于DE-SARSA强化学习的跳频通信系统智能抗干扰策略matlab仿真【包括程序,中文注释,程序操作视频】资源-CSDN下载

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)