【项目实训(个人)】8 AI智能体记忆检索与知识增强模块(RAG+ChromaDB+阿里云Embedding)
在这一阶段的阅见项目开发过程中,我主要负责负责 AI 智能体记忆检索与知识增强模块的设计与落地。在传统 AI 角色对话项目中,大模型仅依赖单次输入 Prompt 和固定人设生成回答,上下文窗口有限,无法长期留存用户对话习惯、交互细节,导致 AI 角色生硬、千人千面效果差、对话连贯性弱。因此,这里我采用如下的项目开发思路:依托 RAG 检索增强生成思想,通过 ChromaDB 向量数据库持久化对话记忆,结合阿里云通义千问 Embedding 模型完成文本语义向量化,动态检索历史对话记忆并增强 Prompt,彻底解决大模型上下文受限、无长期记忆的痛点。本文将从环境搭建、数据库设计、模块设计、代码实现、前后端联调、踩坑优化全方位讲解整套记忆系统的开发思路与实战过程。
目录
四、前后端协同:Java Spring Boot 与 Vue 前端
一、环境配置与基础架构搭建
整套 AI 记忆系统基于 Python FastAPI 搭建算力服务,核心依赖向量数据库与大模型 Embedding 能力。在项目初始化阶段,我首先考虑环境隔离、配置解耦、性能适配三大核心需求。不同于传统业务项目,AI 项目依赖版本敏感、API 密钥繁多,因此需要标准化环境搭建流程,规避版本冲突、配置硬编码、数据丢失等问题,为后续功能开发、测试、部署筑牢基础。
1.1 Python 虚拟环境与依赖安装
本地全局 Python 环境存在大量第三方依赖,不同项目版本不一致极易导致运行报错。为保证阅见 AI 服务环境纯净、可移植、可复刻,项目统一使用 Anaconda 创建独立专属虚拟环境,隔离全局依赖。同时统一梳理所有核心依赖并写入requirements.txt,保证团队协作、服务器部署环境统一。
各依赖核心作用说明:
- fastapi、uvicorn:搭建高性能异步 AI 接口服务,支撑流式对话场景
- chromadb:轻量级本地向量数据库,用于存储对话记忆向量与文本数据
- dashscope:阿里云官方 SDK,对接通义千问 Embedding 模型与大模型对话接口
- python-dotenv:读取本地 .env 配置文件,实现配置与代码解耦
- httpx、pydantic:异步请求、参数校验,保证接口请求安全稳定
requirements.txt核心依赖清单 ():
fastapi>=0.100.0
uvicorn>=0.23.0
chromadb>=0.4.0
dashscope>=1.14.0
python-dotenv>=1.0.0
httpx>=0.24.0
pydantic>=2.0.0
安装命令:
conda create -n vistaread-ai python=3.10
conda activate vistaread-ai
pip install -r requirements.txt
1.2 环境变量配置
AI 项目包含大量敏感密钥、第三方接口地址、自定义业务参数。如果直接硬编码在代码中,不仅存在密钥泄露风险,且开发、测试、生产环境参数无法快速切换。因此项目采用 .env 文件统一管理所有环境变量,代码仅读取配置,不存储参数,实现配置解耦、安全可控、环境快速切换。
配置涵盖三大模块:阿里云模型密钥、向量数据库参数、大模型对话参数,完整覆盖记忆系统所有依赖配置。
# 阿里云 DashScope API Key
DASHSCOPE_API_KEY=sk-xxxxxxxxxxxxxxxxxxxx
# 嵌入模型选择
EMBEDDING_MODEL=text-embedding-v1
# ChromaDB 本地存储路径
CHROMA_DB_PATH=./chroma_db
CHROMA_COLLECTION_NAME=vistaread_memories
# LLM 基础配置(用于对话生成)
LLM_API_BASE=https://dashscope.aliyuncs.com/compatible-mode/v1
LLM_API_KEY=sk-xxxxxxxxxxxxxxxxxxxx
LLM_MODEL=qwen-plus
1.3 ChromaDB 详细配置与调优
ChromaDB 是记忆系统的核心存储载体,数据库的算法选择、索引参数、持久化配置直接决定记忆检索的准确率、响应速度与数据安全性。针对文本语义检索场景,我针对性做了算法选型、索引调优、持久化落地三层优化,适配 AI 角色对话的业务场景。
1. 相似度算法选择:
传统欧氏距离更适合数值型数据距离计算,对文本语义不敏感。而余弦相似度聚焦两个文本向量的夹角方向,忽略向量长度,精准匹配文本语义相似度,完全适配对话记忆检索场景,能够精准匹配用户历史提问、对话习惯。因此项目全局使用余弦相似度作为度量标准。
metadata={"hnsw:space": "cosine"}
2. 索引参数优化 (HNSW):
ChromaDB 默认基于 HNSW 近似最近邻算法构建向量索引,平衡检索速度与精度。在开发中发现默认参数无法适配多轮对话海量记忆场景:参数过小检索不准,参数过大内存占用过高。因此针对性理解参数作用,预留自定义调优入口,适配不同业务量级。
- M: 每个节点的最大连接数(默认 16),增大参数可提升检索召回率,但会增加内存开销
- ef_construction: 建图时的搜索深度(默认 100),数值越高索引质量越高,检索越精准,但是初始化耗时更长
3. 持久化路径管理:
ChromaDB 默认内存存储,服务重启后数据全部丢失,无法实现长期记忆。因此通过自定义本地持久化路径,将所有对话记忆落地磁盘,保证服务重启、项目迭代升级后,用户历史记忆永久留存。
1.4 Prompt 模板设计与增强策略
单纯检索记忆无法直接生效,必须将记忆注入大模型的提示词中,引导模型参考历史对话作答。为了避免记忆拼接生硬、破坏原有角色人设,我设计了模块化分层 Prompt 架构,将人设、阅读上下文、历史记忆三层拆分,互不干扰,动态注入记忆,最大程度保留角色原生人设,同时实现记忆增强效果。
模板分层逻辑:固定人设为底层基础、阅读场景上下文为中层辅助、检索记忆为顶层动态补充,三者拼接组成最终送入大模型的提示词。
模板结构设计:
[基础人设指令]
你正在扮演《红楼梦》中的角色 {role_name}...
[阅读上下文]
{context_block}
[相关记忆参考] <-- 动态插入部分
- 用户之前提到过他叫小明,今年20岁。
- 角色曾透露自己最喜欢在潇湘馆看书。
_build_role_system_prompt实现思路:单独封装 Prompt 构建函数,解耦对话逻辑与提示词构建逻辑,后续如需修改模板、新增记忆类型、调整提示词规则,无需改动核心对话代码,提升代码可维护性。
1.5 核心模块划分
初期开发时如果将向量生成、数据库操作、记忆保存、Prompt 增强全部写在接口逻辑中,会导致代码臃肿、耦合严重、难以调试。基于单一职责原则,我将整套记忆系统拆解为五大独立模块,每个模块只负责单一功能,模块之间通过依赖注入调用,实现高内聚、低耦合,方便后续迭代拓展。
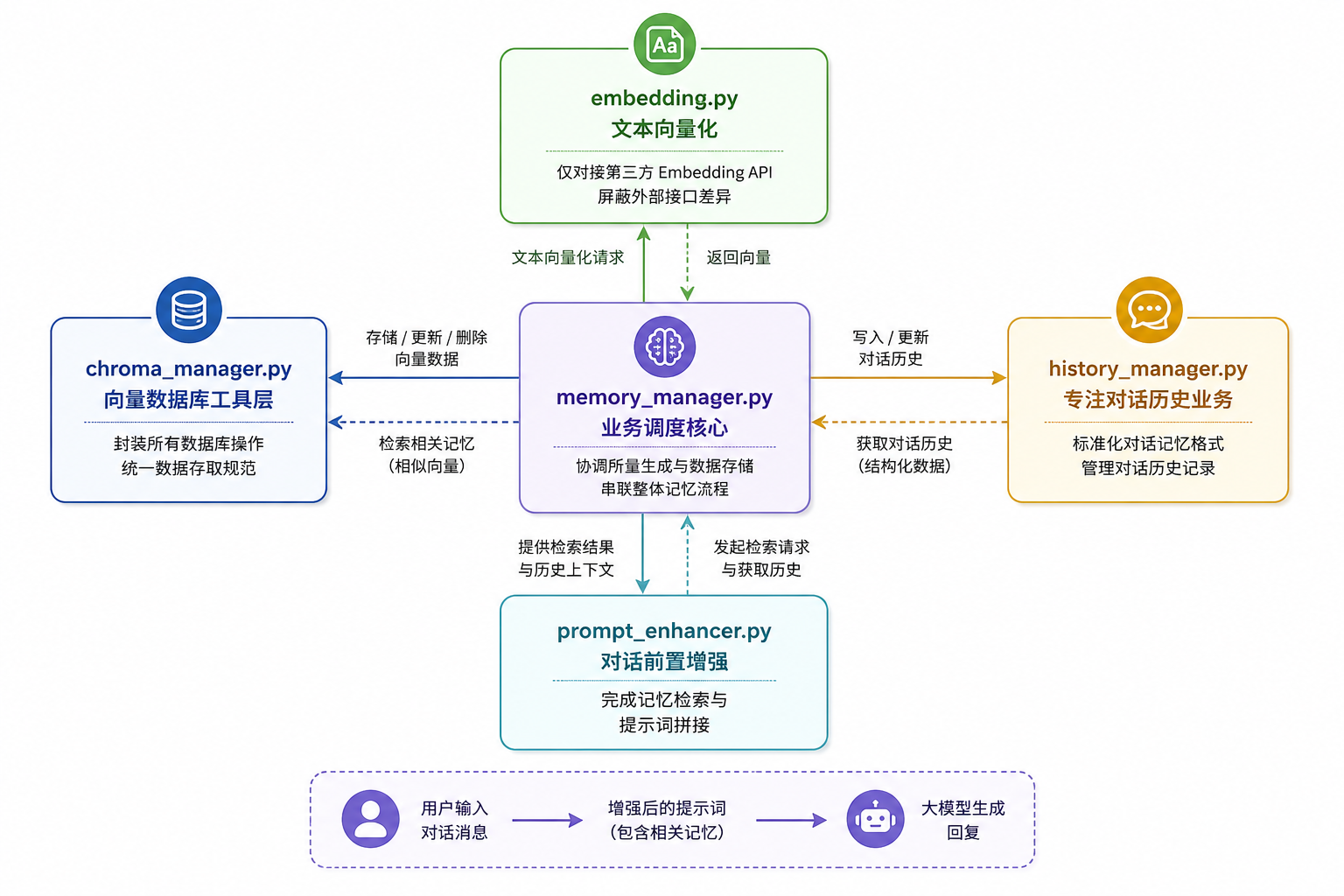
modules/embedding.py:独立负责文本向量化,仅对接第三方 Embedding API,屏蔽外部接口差异modules/db/chroma_manager.py:向量数据库工具层,封装所有数据库操作,统一数据存取规范modules/memory_manager.py:业务调度核心,协调向量生成与数据存储,串联整体记忆流程modules/history_manager.py:专注对话历史业务,标准化对话记忆格式modules/prompt_enhancer.py:对话前置增强,完成记忆检索与提示词拼接
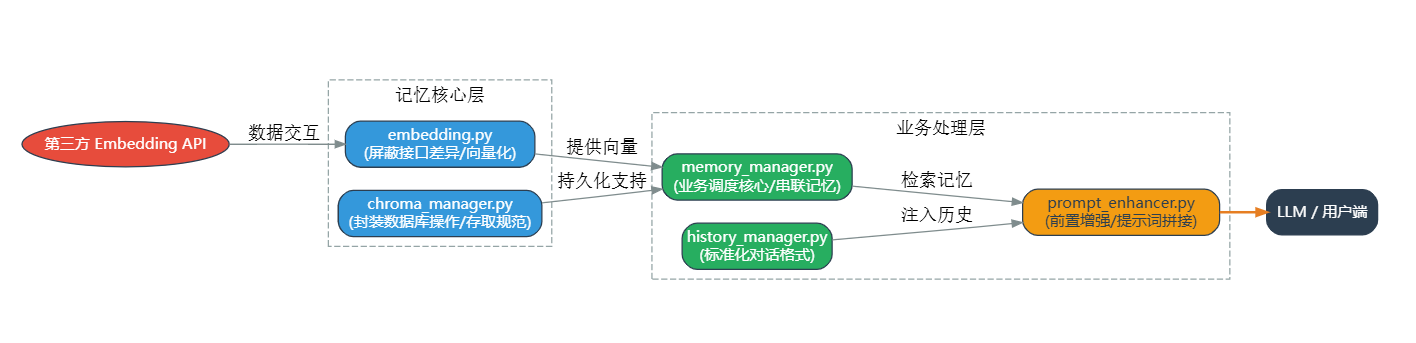
二、数据库设计:MySQL 与 ChromaDB 的协同
记忆系统的核心需求是“既能高效检索语义相似的记忆,又能安全持久化结构化业务数据”。单一数据库无法满足双重需求:MySQL 擅长结构化数据管理、分页查询和统计分析,但不支持向量语义检索;ChromaDB 擅长向量存储与快速语义匹配,但缺乏复杂业务字段管理和数据安全保障。因此设计“双引擎”协同架构,让两者各司其职、优势互补,通过 role_id 实现数据关联,确保记忆数据的安全性、可检索性和一致性。
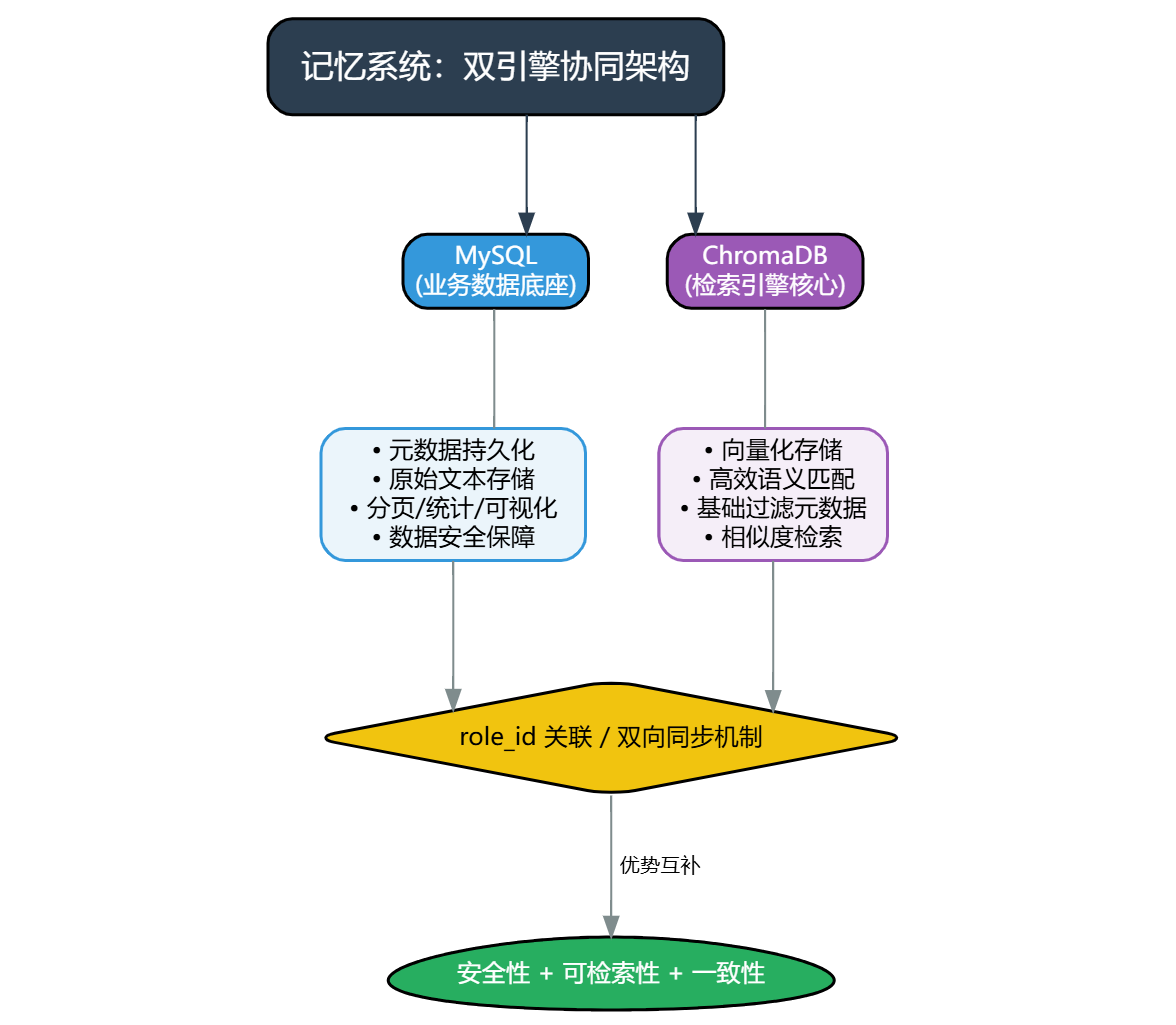
整体设计逻辑:MySQL 作为“业务数据底座”,存储记忆的元数据、原始文本,支撑前端可视化和业务统计;ChromaDB 作为“检索引擎核心”,存储文本向量和基础过滤元数据,支撑高效语义检索;通过双向同步机制,保证两者数据实时一致,规避单数据库故障导致的数据丢失或功能失效问题。
2.1 MySQL 关系型存储设计
前端记忆管理面板需要实现记忆列表展示、分页查询、角色统计等功能,这些需求依赖结构化数据的高效查询和管理。因此选用 MySQL 作为关系型存储,核心设计目标是“标准化记忆元数据存储、支持快速业务查询、预留拓展能力”。
考虑到项目迭代需求,设计两张核心表:memory 记忆主表(存储核心业务数据)和 memory_retrieval_log 检索日志表(预留拓展,用于后续检索优化),避免单表冗余,同时保证数据结构清晰、可维护性强。
表结构设计思路:
- 采用自增主键
id,保证记忆唯一标识,便于后续数据关联和修改 - 核心关联字段
role_id设为非空,建立索引,确保与 ChromaDB 数据高效关联,同时支持按角色快速筛选记忆 - 引入
memory_type字段,区分对话历史、世界事件等不同类型记忆,为后续记忆分类管理、精准检索预留拓展空间 - 使用
metadata_json字段(MySQL 5.7+ JSON 类型),灵活存储额外上下文信息,避免因业务拓展频繁修改表结构 - 增加
importance_score重要性评分字段,为未来实现记忆权重排序、遗忘机制奠定基础
表结构实现(update_memory_feature.sql):
1. 记忆主表 (memory):

CREATE TABLE IF NOT EXISTS `memory` (
`id` BIGINT NOT NULL AUTO_INCREMENT COMMENT '记忆ID',
`role_id` VARCHAR(100) NOT NULL COMMENT '角色ID或名称',
`content` TEXT NOT NULL COMMENT '记忆内容(原始文本)',
`memory_type` VARCHAR(50) NOT NULL COMMENT '类型: dialogue_history, world_event...',
`metadata_json` JSON DEFAULT NULL COMMENT '扩展元数据',
`importance_score` DECIMAL(3,2) DEFAULT 0.50 COMMENT '重要性评分',
`created_at` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
INDEX `idx_role_id` (`role_id`),
INDEX `idx_memory_type` (`memory_type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2. 检索日志表 (memory_retrieval_log):
开发思路:为了后续优化检索效果、分析检索性能,提前设计日志表,预留检索行为数据存储能力。当前项目仅完成表结构设计,未实现日志写入逻辑,属于“提前布局、逐步落地”的设计思路,避免后续拓展时重复修改数据库结构。
该表主要用于记录检索全量信息,为后续数据分析、参数调优(如 top_k 调整)、检索策略优化提供数据支撑。
预留表结构:
CREATE TABLE IF NOT EXISTS `memory_retrieval_log` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`user_id` BIGINT DEFAULT NULL COMMENT '发起检索的用户ID',
`role_id` VARCHAR(100) NOT NULL COMMENT '检索的角色',
`query_text` TEXT NOT NULL COMMENT '查询文本',
`returned_count` INT DEFAULT 0 COMMENT '返回的记忆数量',
`created_at` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
未来实现计划:在PromptEnhancer 的检索逻辑中增加异步日志记录功能,将每次检索的元数据(用户ID、角色ID、查询文本、返回数量等)写入该表,通过分析检索耗时、命中率、相似度分布,优化top_k 参数和向量检索策略,提升检索准确性和性能。
2.2 ChromaDB 向量存储设计
ChromaDB 的核心定位是“高效向量检索引擎”,无需存储复杂业务字段,专注于向量嵌入和基础过滤元数据的存储,避免数据冗余,提升检索效率。设计时严格贴合阿里云 text-embedding-v1 模型特性和语义检索需求,确保向量存储与检索的兼容性和高效性。
集合配置设计思路:
- Collection Name:设置为
vistaread_memories,与项目名称对应,便于识别和管理,避免与其他项目向量数据混淆 - Space Function:选用
cosine(余弦相似度),贴合文本语义检索场景,能够精准匹配语义相似的记忆,优于欧氏距离等其他度量方式 - Dimensions:设置为 1536,与
text-embedding-v1模型的输出向量维度完全一致,确保向量嵌入与检索的兼容性,避免维度不匹配导致的检索失效
存储结构设计思路:仅存储核心检索相关数据,不冗余存储 MySQL 中已有的业务字段,通过 id 和 metadata 中的 role_id 与 MySQL 关联,实现数据联动。
存储结构示例:
| ID | Document (文本) | Embedding (向量) | Metadata (元数据) |
|---|---|---|---|
| 贾宝玉_171... | 用户: 你是谁?\nAI: 我是贾宝玉... | [0.12, -0.45, ...] | {"role_id": "贾宝玉", "type": "dialogue_history"} |
2.3 双向同步机制
双数据库协同的核心痛点是“数据一致性”,若两者数据不同步,会出现“MySQL 有记忆但无法检索”或“ChromaDB 有向量但无原始文本”的问题。因此设计双向同步逻辑,确保新记忆产生时,MySQL 和 ChromaDB 同时写入数据,且数据一致。
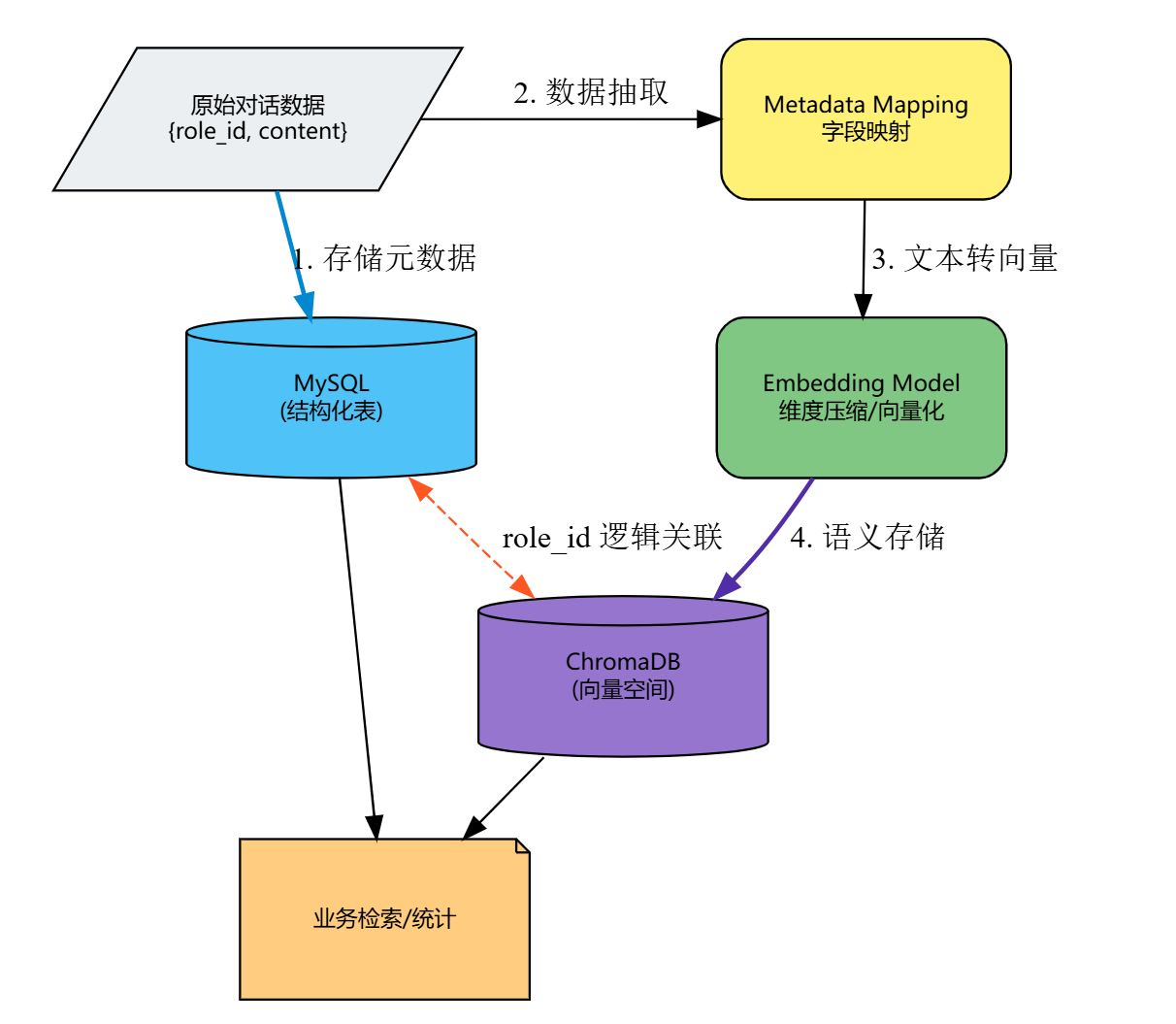
同步流程设计考量:以 MySQL 为核心业务存储,优先保证原始文本和元数据的安全,再同步至 ChromaDB 生成向量,避免向量库故障导致核心业务数据丢失。同时采用 HTTP 调用方式,实现 Java 后端与 Python AI 服务的解耦,提升系统灵活性和可维护性。
同步流程详细说明:
- 写入 MySQL:当用户与 AI 完成一轮对话,产生新记忆时,由 Spring Boot 的
MemoryService负责将记忆的元数据、原始文本等信息存入memory表,确保核心业务数据安全落地。 - 触发 Python 同步:Java 服务在写入 MySQL 成功后,通过 HTTP 调用 Python AI 服务的
/api/memory/add接口,传递记忆相关参数(role_id、content、memory_type等)。 - 写入 ChromaDB:Python 服务接收请求后,调用
EmbeddingService生成文本向量,再通过MemoryManager将向量、原始文本和元数据存入 ChromaDB,完成向量存储。
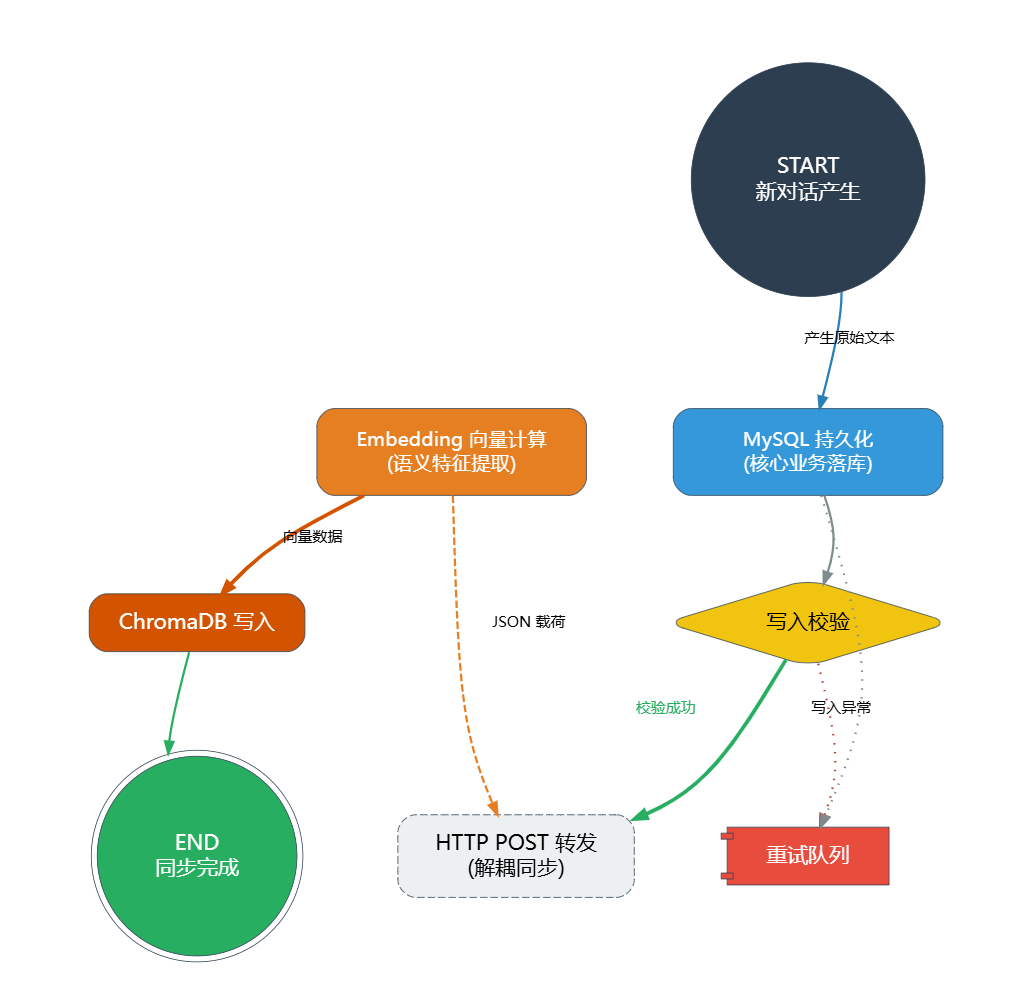
该设计的优势:即使 ChromaDB 出现临时故障,核心的记忆文本依然安全保存在 MySQL 中,待向量库恢复后,可通过同步接口补全向量数据,避免数据丢失;同时实现了业务层与 AI 算力层的解耦,便于后续单独升级或维护任一数据库。
三、后端核心实现:Python AI 服务层
Python FastAPI 服务是整套记忆系统的核心算力层,承接 Java 后端转发的对话请求,完成文本向量化、记忆检索、对话记忆入库、Prompt 增强、大模型流式对话生成全流程处理。所有 AI 相关的复杂计算、语义匹配、记忆逻辑全部在此实现。
3.1 记忆存储引擎:ChromaDB 集成与元数据过滤
项目支持多角色 AI 对话(贾宝玉、林黛玉等),所有角色记忆统一存入一个向量库。如果不做隔离,检索时会匹配到其他角色的对话记忆,出现角色串人设、对话错乱的严重问题。因此核心开发重点是基于元数据实现多角色记忆物理隔离,与 MySQL 中的 role_id 保持一致,确保双数据库数据关联的准确性。
在每条记忆入库时,自动绑定当前角色 ID,检索时强制添加角色 ID 过滤条件,实现“一角色一记忆库”的隔离效果,保证不同角色记忆完全独立、互不干扰。同时封装统一的数据库操作方法,屏蔽 ChromaDB 底层细节,便于后续切换向量数据库或调整检索逻辑。
核心代码实现:
# modules/db/chroma_manager.py
def search(self, query_embedding: list, top_k: int, role_id: str):
"""带角色过滤的相似性检索"""
return self.collection.query(
query_embeddings=[query_embedding],
n_results=top_k,
where={"role_id": role_id} # 确保只搜当前角色的记忆,与MySQL role_id对应
)
3.2 向量化服务:EmbeddingService
大模型无法识别自然语言语义,向量检索的核心原理是:将语义相似的文本生成高维相近向量。本项目选择阿里云 text-embedding-v1 模型,可生成 1536 维高精度语义向量,适配中文对话场景,与 ChromaDB 向量维度配置保持一致。
为了统一管理第三方接口调用、统一异常处理,我单独封装 Embedding 工具类,集中处理接口请求、异常捕获、数据返回,避免多处重复调用 API 导致代码冗余、异常不可控。同时预留模型切换入口,若后续更换 Embedding 模型,无需修改核心业务代码,提升代码可维护性。
核心代码实现:
# modules/embedding.py
from dashscope import TextEmbedding
class EmbeddingService:
def __init__(self, api_key: str, model: str = "text-embedding-v1"):
self.api_key = api_key
self.model = model
def embed(self, text: str) -> list:
"""将文本转换为 1536 维向量,与ChromaDB维度保持一致"""
response = TextEmbedding.call(
model=self.model,
input=text,
api_key=self.api_key
)
if response.status_code == 200:
return response.output['embeddings'][0]['embedding']
raise Exception(f"Embedding 失败: {response.message}")
3.3 记忆管理器:MemoryManager
MemoryManager 是整个记忆系统的调度中枢,承接上层所有记忆写入需求,标准化记忆入库全流程。统一封装唯一ID生成、向量生成、元数据绑定、数据入库逻辑,保证项目内所有记忆数据格式统一、字段规范,避免不同模块入库数据不一致,同时与 MySQL 记忆数据格式保持协同。
同时自定义记忆类型字段,区分对话历史、用户偏好、角色人设等不同类型记忆,与 MySQL 中的 memory_type 字段对应,为后续记忆分类管理、筛选优化预留拓展能力。ID 生成规则结合 role_id 和时间戳,确保记忆 ID 唯一且可追溯,便于与 MySQL 中的记忆数据关联排查问题。
核心代码实现:
# modules/memory_manager.py
class MemoryManager:
def __init__(self, embedding_service: EmbeddingService, store: ChromaMemoryStore):
self.embedding_service = embedding_service
self.store = store
def add_memory(self, role_id: str, content: str, memory_type: str, metadata: dict = None):
"""添加记忆的核心流程,与MySQL记忆入库逻辑协同"""
# 1. 生成唯一 ID,结合role_id确保可追溯,与MySQL id对应关联
memory_id = f"{role_id}_{int(time.time() * 1000)}"
# 2. 生成向量,调用向量化服务,确保维度为1536
embedding = self.embedding_service.embed(content)
# 3. 存入向量库,元数据与MySQL保持一致,便于数据同步和关联
meta = metadata or {}
meta.update({"role_id": role_id, "type": memory_type})
self.store.add(id=memory_id, embedding=embedding, document=content, metadata=meta)
return memory_id
3.4 历史对话管理:HistoryManager
原始对话数据分为用户提问、AI 回复两段独立文本,如果分开存储会导致记忆碎片化,无法还原完整对话场景。因此单独开发 HistoryManager 模块,核心作用是封装单轮完整对话,将用户提问与 AI 回答拼接为一条完整对话记录,统一格式入库,保证记忆完整性、可读性,同时与 MySQL 中 memory 表的 content 字段格式保持一致。
该模块完全解耦对话业务,专注对话历史持久化,让记忆系统可以精准还原每一次交互场景,同时为后续检索完整对话、分析对话逻辑提供便利,确保存入 MySQL 和 ChromaDB 的对话记忆内容一致。
核心代码实现:
# modules/history_manager.py
class HistoryManager:
def __init__(self, memory_manager: MemoryManager):
self.memory_manager = memory_manager
def save_conversation(self, role_id: str, user_message: str, ai_response: str):
"""保存一轮完整的对话,格式与MySQL memory表content字段一致"""
conversation_text = f"用户: {user_message}\\nAI: {ai_response}"
self.memory_manager.add_memory(
role_id=role_id,
content=conversation_text,
memory_type="dialogue_history" # 与MySQL memory_type字段对应
)
3.5 Prompt 增强器:PromptEnhancer
记忆存储入库后,必须在每次对话前完成检索与注入,才能真正生效。PromptEnhancer 是记忆落地的最后一环,也是最核心的业务模块。开发思路为:用户发起提问 → 根据当前角色+用户问题语义检索相似记忆 → 过滤优质记忆 → 动态拼接至系统提示词 → 送入大模型生成答案。
同时限制 Top-K 检索数量,避免记忆过多导致 Prompt 超长、大模型冗余思考,平衡增强效果与接口性能。检索时严格根据 role_id 过滤,与 MySQL 和 ChromaDB 的数据隔离逻辑保持一致,确保检索到的记忆属于当前角色,避免串人设问题。
核心代码实现:
# modules/prompt_enhancer.py
class PromptEnhancer:
def enhance_prompt(self, original_prompt: str, role_id: str, user_query: str, top_k: int = 3):
# 1. 检索相关记忆,根据role_id过滤,与双数据库协同
memories = self.memory_manager.search_memories(
role_id=role_id,
query=user_query,
top_k=top_k
)
# 2. 构建增强后的 Prompt,确保记忆拼接自然,不破坏角色人设
enhanced_prompt = original_prompt
if memories:
context_str = "\\n".join([f"- {m['content']}" for m in memories])
enhanced_prompt += f"\\n\\n【相关记忆参考】\\n{context_str}"
return enhanced_prompt, memories
四、前后端协同:Java Spring Boot 与 Vue 前端
整套项目采用三层架构解耦设计:Vue 前端负责用户交互可视化、Java Spring Boot 负责业务数据管控与请求转发、Python FastAPI 负责 AI 算力计算。Java 作为中间层承接前端所有请求,对接 MySQL 存储基础业务数据,转发 AI 对话请求至 Python 服务,实现业务与 AI 算力分离,保证系统稳定性与可拓展性。同时 Java 后端承担 MySQL 与 ChromaDB 的双向同步触发职责,是双数据库协同的核心枢纽。
4.1 Java 后端接口设计
Python 服务专注 AI 计算,不适合处理复杂的业务分页、数据统计、权限管控。因此由 Java 后端封装记忆管理相关 RESTful 接口,为前端提供标准化数据能力,包含记忆分页查询、角色统计、语义检索等功能,统一返回格式,方便前端渲染。同时 Java 后端负责 MySQL 数据的 CRUD 操作,触发双数据库同步逻辑,是业务层与 AI 层的桥梁。
同时通过 MyBatis-Plus 实现数据库高效查询,自动统计存在对话记忆的角色,无需手动维护角色列表,实现自动化数据统计。接口设计遵循 RESTful 规范,便于前端调用和后续拓展,同时与 MySQL 表结构、Python 服务接口保持协同,确保数据流转顺畅。
接口控制器代码:
// MemoryController.java
@RestController
@RequestMapping("/api/memory")
public class MemoryController {
// 获取指定角色的记忆列表(分页),对接MySQL memory表
@GetMapping("/list/{roleId}")
public ApiResult<Page<MemoryVO>> listMemories(@PathVariable String roleId, ...) { ... }
// 获取所有已存在记忆的角色列表,从MySQL memory表分组查询
@GetMapping("/roles")
public ApiResult<List<String>> listAllRoles() {
List<String> roles = memoryService.listAllRoles();
return ApiResult.ok(roles);
}
// 语义搜索记忆,联动Python服务检索ChromaDB,返回MySQL中的原始文本
@PostMapping("/search")
public ApiResult<List<MemoryVO>> searchMemories(@RequestBody SearchMemoryRequest request) { ... }
}
业务逻辑实现:通过分组去重,自动筛选所有产生过对话记忆的角色,从 MySQL memory 表中查询,确保角色列表与实际记忆数据一致
@Override
public List<String> listAllRoles() {
LambdaQueryWrapper<Memory> wrapper = new LambdaQueryWrapper<>();
wrapper.select(Memory::getRoleId).groupBy(Memory::getRoleId);
return memoryMapper.selectList(wrapper).stream()
.map(Memory::getRoleId)
.distinct()
.collect(Collectors.toList());
}
4.2 前端记忆管理面板:MemoryPanel.vue
为了让开发人员、管理员直观查看 AI 记忆数据、排查记忆失效、检索异常等问题,专门开发可视化记忆管理面板。摒弃手动输入角色名查询的繁琐操作,通过标签页切换角色,支持单角色精准查看、全角色全局浏览,降低问题排查成本。前端数据全部来自 Java 后端接口,展示 MySQL 中的记忆元数据和原始文本,同时可间接反映 ChromaDB 向量检索的效果。
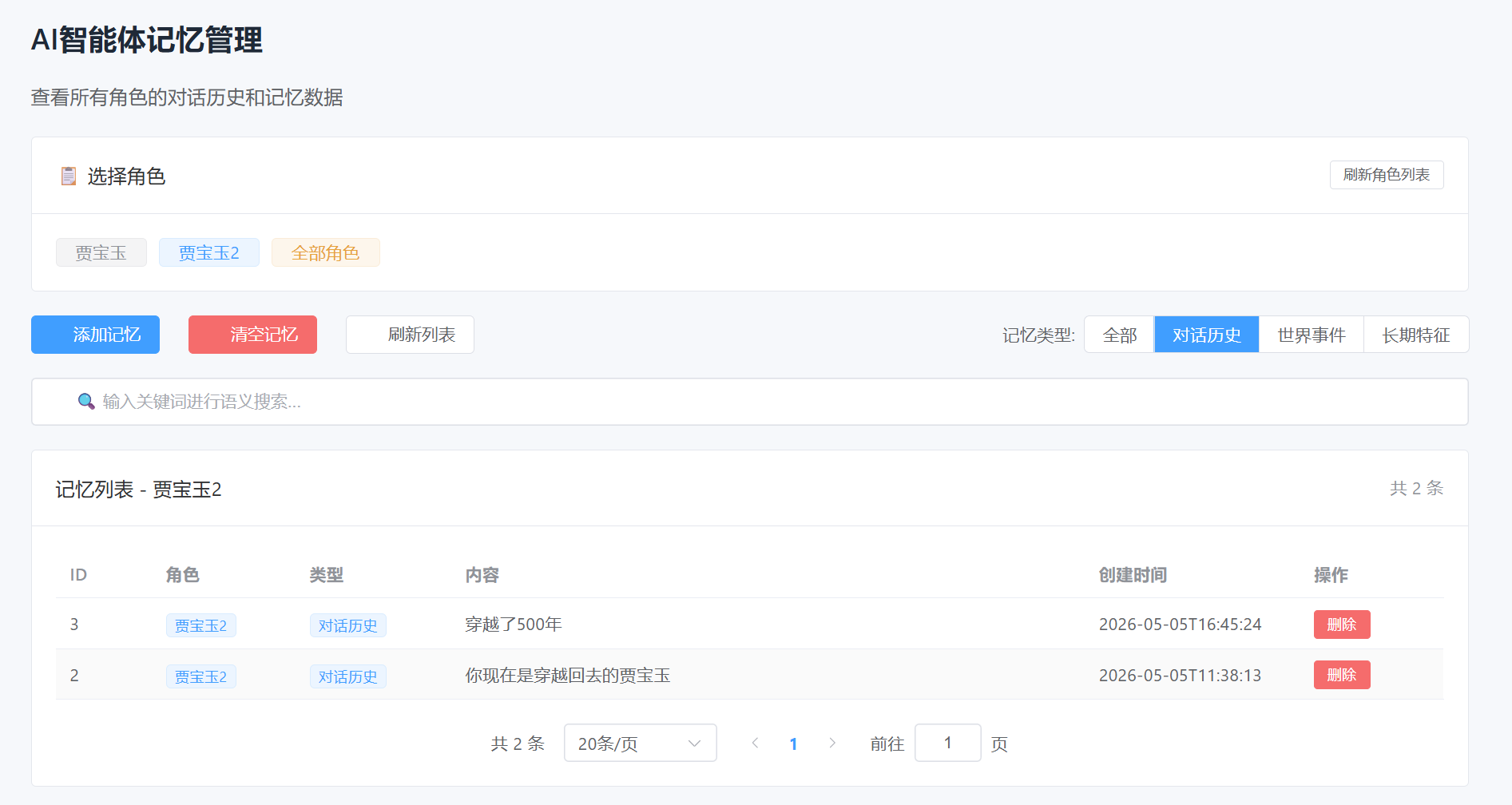
前端逻辑完全解耦,自动请求后端接口加载角色列表与记忆数据,动态渲染页面,交互轻量化、易用性高。页面设计贴合业务需求,展示记忆 ID、角色 ID、记忆内容、记忆类型等核心字段,与 MySQL memory 表字段对应,便于快速关联排查数据问题。
核心交互逻辑代码:
// 加载所有角色并展示为标签,数据来自Java后端/api/memory/roles接口
async function loadRoles() {
const res = await http.get('/memory/roles')
if (res.code === 0) {
allRoles.value = res.data || []
}
}
// 点击标签切换角色视图,加载对应角色的记忆列表
function selectRole(role) {
selectedRole.value = role
if (role) {
loadMemories() // 加载特定角色记忆,对接Java后端/api/memory/list/{roleId}接口
} else {
loadAllMemories() // 加载全部角色记忆
}
}
4.3 AI 聊天页面的记忆集成
开发思路:聊天页面是用户交互的核心入口,必须保证每次对话请求都携带角色标识与上下文信息。前端通过流式 SSE 请求对接后端接口,持续接收 AI 流式输出内容,同时传递角色名称,让后端精准匹配对应角色记忆,保证记忆功能全程生效。请求参数中的 roleName 与 MySQL、ChromaDB 中的 role_id 保持一致,确保双数据库协同工作。
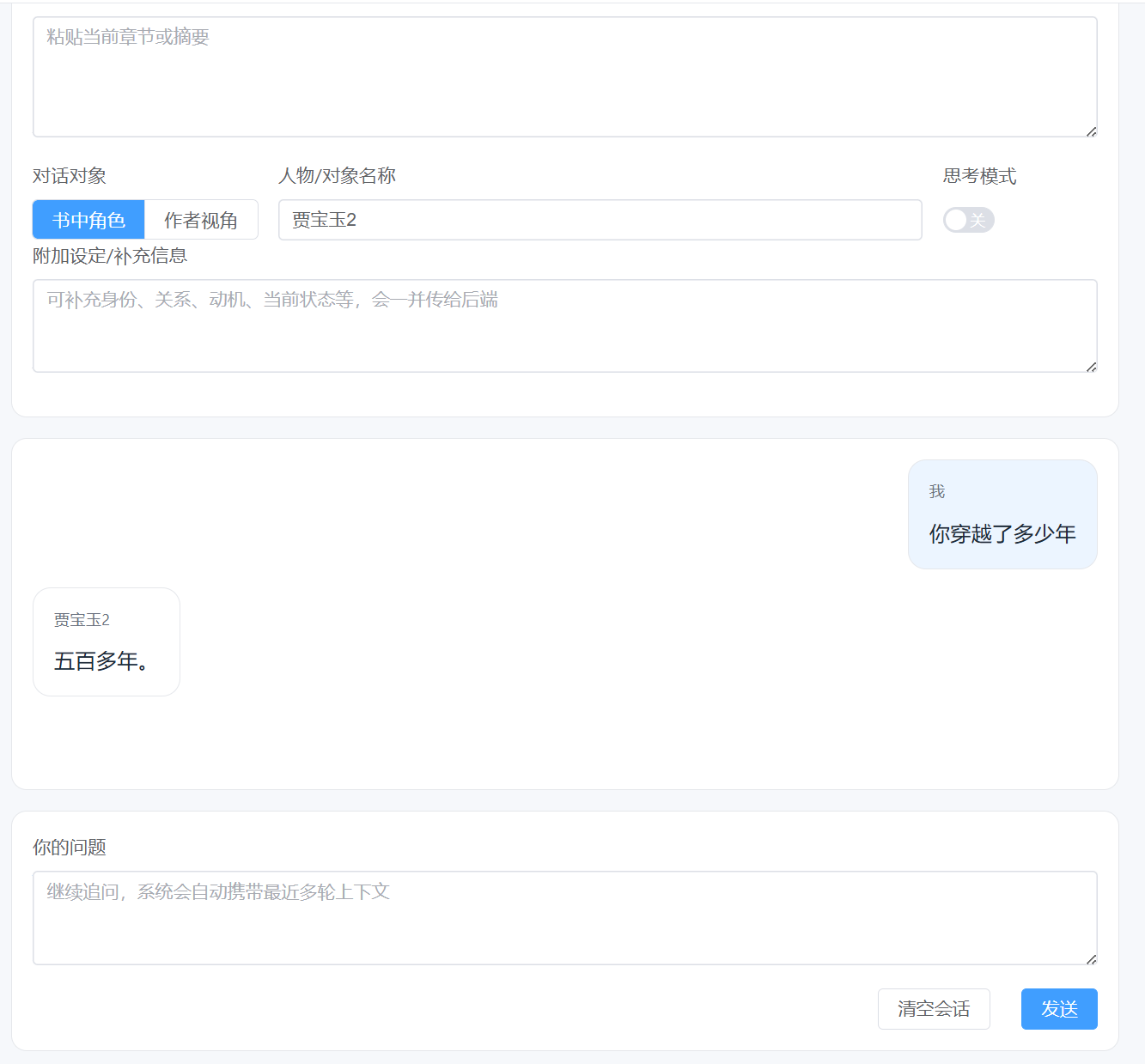
这里可以看到,贾宝玉2这个我们虚构的一个人物,拥有了关于自己“穿越500年”的记忆,并且可以通过对话看到记忆内容被成功调出来。
流式请求核心代码:
const response = await fetch('/api/ai/chat/stream', {
method: 'POST',
body: JSON.stringify({
mode: mode.value,
roleName: roleName.value, // 关键:告诉 AI 扮演谁,与role_id对应
message: text,
history: buildHistory()
})
})
五、关键技术细节与踩坑记录
5.1 流式接口的记忆同步问题
踩坑背景与问题分析:项目初期仅完成了非流式接口的记忆保存逻辑,测试时发现普通对话记忆正常留存,但用户实际使用的流式聊天接口完全无法保存记忆。根本原因是流式接口采用分段 SSE 推送机制,接口函数会持续迭代返回数据,对话并未一次性完成,原有代码没有判断对话结束时机,导致记忆保存逻辑永远不会执行。若记忆无法保存,会导致 MySQL 和 ChromaDB 均无对应数据,AI 失去长期记忆功能。
解决方案思路:监听流式接口官方定义的 [DONE] 结束标识,等待所有对话内容推送完成、本轮对话彻底结束后,统一汇总 AI 输出内容,执行记忆入库逻辑,确保每一次流式对话都能完整留存,同时触发 MySQL 与 ChromaDB 的双向同步,保证双数据库数据一致。
# main.py - chat_stream 接口修复
async for line in response.aiter_lines():
if data_str.strip() == "[DONE]":
# 1. 发送完成信号
yield f"data: {{\\"done\\": true}}\\n\\n"
# 2. 保存对话到记忆系统,触发双数据库同步
if history_manager and accumulated_content:
history_manager.save_conversation(
role_id=body.role_name,
user_message=message,
ai_response=accumulated_content
)
break
5.2 向量检索的准确性优化
踩坑背景与问题分析:初始版本仅简单实现向量检索,存在大量噪音数据,经常匹配语义无关的历史对话。原因是缺少数据隔离、检索数量过多、大模型没有强制参考记忆,导致记忆不仅无法增强回答,反而干扰模型输出。同时发现,部分记忆在 MySQL 中存在,但 ChromaDB 中无对应向量,导致检索不到,核心是双向同步逻辑存在遗漏。
分层优化思路:从数据层、参数层、提示词层、同步层四层优化:数据层通过角色 ID 过滤隔离数据,与双数据库协同;参数层限制单次检索数量,减少冗余记忆;提示词层约束模型优先级,保证记忆生效;同步层完善双向同步校验,确保 MySQL 和 ChromaDB 数据一致。
- 元数据过滤:查询时强制绑定角色 ID,隔离多角色记忆数据,与 MySQL 角色隔离逻辑保持一致
- 调整 Top-K 参数:将单次记忆检索数量固定为 3 条,避免冗余无关记忆干扰大模型判断
- Prompt 约束:在系统提示词中明确要求大模型优先参考检索到的历史记忆作答
- 同步校验:在 Java 后端同步调用 Python 接口后,增加回调校验,确保 ChromaDB 成功写入,若失败则重试,避免数据同步遗漏
5.3 角色名称的匹配与过滤
踩坑背景与问题分析:前端用户输入、页面传参可能存在人工输入空格、大小写不一致的情况,导致后端角色匹配失败,记忆检索为空,出现 AI 失忆 bug。属于典型的前后端参数格式不统一问题,同时会导致 MySQL 和 ChromaDB 中的 role_id 无法正常关联,双数据库协同失效。
解决方案思路:后端统一做参数清洗,对角色名称去除首尾空格、增加非空校验,标准化入参格式,规避前端参数不规范导致的功能异常,提升系统容错性。同时确保 Java 后端、Python 服务、MySQL、ChromaDB 中 role_id 的格式完全一致,避免因格式问题导致的数据关联失败。
if prompt_enhancer and mode == "character" and body.role_name.strip():
enhanced_context, _ = prompt_enhancer.enhance_prompt(...) # 去除空格后匹配角色
六、总结
通过本次阅见项目 AI 记忆检索功能开发,我基于 ChromaDB 向量数据库 + 阿里云通义千问 Embedding 模型 + MySQL 关系型数据库,构建“双数据库”的协同架构,落地了 RAG 检索增强方案,成功为 AI 智能体实现了长期记忆存储、语义检索、对话记忆增强、可视化记忆管理全套能力。彻底解决了传统大模型上下文窗口短、无长期记忆、角色人设僵硬、对话千人一面的行业痛点,同时通过双数据库协同和双向同步机制,保证了数据的安全性、一致性和可检索性。
项目核心收获:
- 全栈能力落地:打通 Python AI 算力服务、Java 业务后端、Vue 前端可视化三层架构,实现 AI 能力从代码到产品的工程化落地,同时掌握了双数据库协同设计与实现技巧。
- RAG 场景:验证了轻量向量数据库+Prompt 增强在角色对话、智能阅读场景的落地价值,积累了拟人化 AI 智能体开发经验,同时形成了“MySQL 管业务、ChromaDB 做检索”的双引擎设计范式。
- 数据一致性保障:通过双向同步机制和参数标准化,解决了双数据库协同的数据一致性问题,提升了系统的稳定性和可维护性。
- 用户体验升级:可视化记忆面板让 AI 记忆透明可控,大幅提升角色对话的连贯性与拟人度,同时便于开发人员排查问题、优化检索效果。
相信在后续的项目开发中,我们会持续迭代记忆体系,完善双数据库协同能力,能够进一步提升阅见项目 AI 角色的拟人化、智能化能力,为用户带来更沉浸、高质量的智能阅读交互体验。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)