Agent 如何管理其他 Agent:四种Sub Agent 模式
Agent 如何管理其他 Agent:2026 年的四种子 Agent 模式
之前有篇文章专门聊了子 Agent 的崛起,以及为什么把任务隔离成独立的 Agent(各自拥有独立的上下文、工具和指令)能让系统更可靠。那篇讲的是"子 Agent 是什么"和"为什么要用它们"。
时至今日,模型在规划、工具调用和多步骤指令执行上已经强了不少,这也让一些以前太脆弱、跑不起来的模式变得可行了——比如让主 Agent 管理一批持久化的 Worker,或者让 Agent 之间直接互发消息。
下面介绍四种模式,按主 Agent 对子 Agent 生命周期的控制程度由低到高排列。
1. 内联工具:子 Agent 就是一个函数调用
最简单的模式。主 Agent 调用一个工具,工具内部启动一个子 Agent,子 Agent 跑完把结果作为工具返回值传回来。从主 Agent 的视角看,调用子 Agent 和调用 read_file、run_command 没有任何区别。
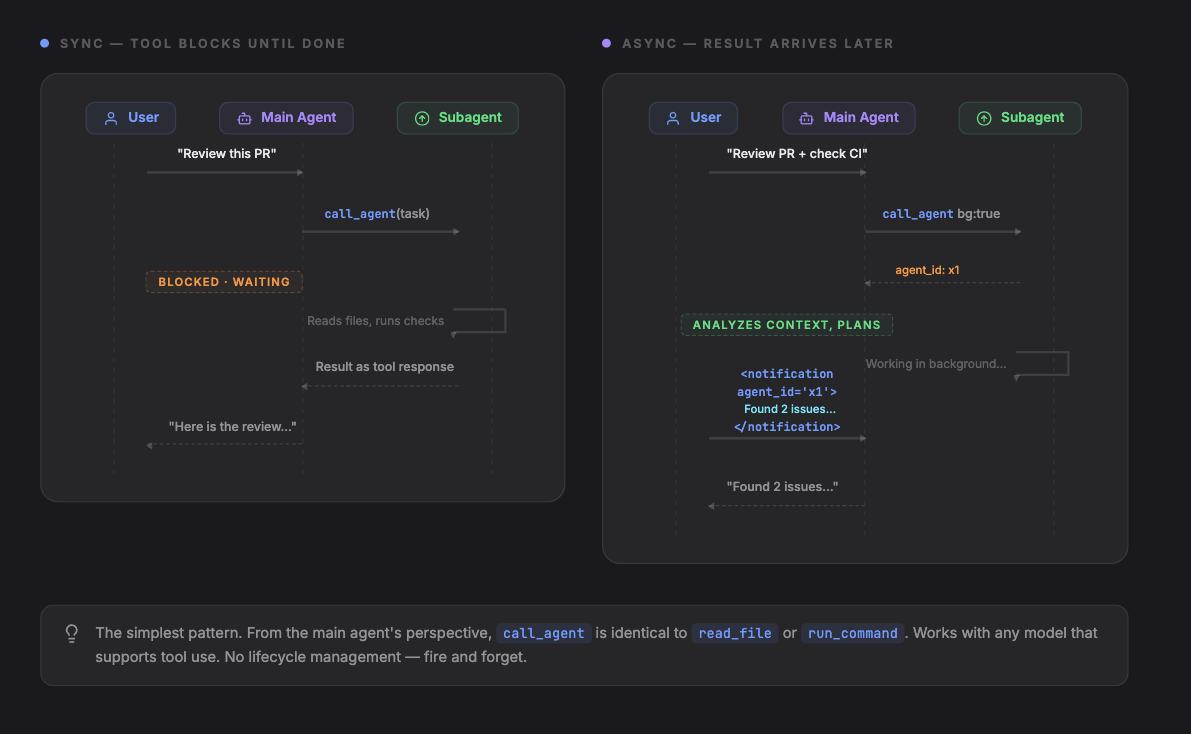
主 Agent 有一个叫 call_agent 的工具,发一个任务进去,拿到结果出来。子 Agent 在自己独立的上下文里运行,有自己的工具和指令。主 Agent 完全不用操心子 Agent 的生命周期。
[
{ "role": "user", "content": "检查 PR #42 的安全问题" },
{ "role": "assistant", "tool_calls": [
{ "name": "call_agent", "arguments": { "task": "检查 PR #42 的安全问题,重点关注鉴权变更", "agent": "security-reviewer", "tools": ["read_file", "search_code"] } }
]},
{ "role": "tool", "name": "call_agent", "content": "发现 2 个问题:1) /api/users 接口未校验 Auth Token;2) 登录处理器中 Session Cookie 缺少 HttpOnly 标记。" },
{ "role": "assistant", "content": "审查发现了 2 个安全问题……" }
]
这个模式在工具层面有同步和异步两种玩法。
同步(如上): 工具调用会阻塞,主 Agent 的这一轮暂停,等子 Agent 跑完,结果作为正常的工具返回值回来。
异步: 工具立刻返回一个 Agent ID,子 Agent 跑完后,结果会以通知消息的形式注入到对话里。主 Agent 在等结果的同时,可以继续做别的工具调用。
[
{ "role": "user", "content": "检查 PR #42 并顺手看一下 CI 日志" },
{ "role": "assistant", "tool_calls": [
{ "name": "call_agent", "arguments": { "task": "检查 PR #42 的安全问题", "agent": "security-reviewer", "background": true } },
{ "name": "read_file", "arguments": { "path": "ci/logs/latest.txt" } }
]},
{ "role": "tool", "name": "call_agent", "content": "agent_id: agent-x1,正在后台运行。" },
{ "role": "tool", "name": "read_file", "content": "构建通过,142 个测试全绿。" },
{ "role": "assistant", "content": "CI 没问题。等安全审查结果……" },
{ "role": "user", "content": "<notification agent_id='agent-x1' status='completed'>发现 2 个问题:……</notification>" },
{ "role": "assistant", "content": "安全审查发现了 2 个问题……" }
]
同步模式下,工具返回值直接是结果;异步模式下,工具返回值是个 ID,结果后续以注入的 user 消息形式到来。
适用场景: 自包含的独立任务,比如资料查询、代码审查、文件分析、测试生成。大多数子 Agent 的使用场景,从这里出发就够了,而且很多都不需要往后走。
局限: 支持工具调用的模型都能用,包括小模型和便宜的模型。结果以单条工具返回值(同步)或注入通知消息(异步)的形式到达。没办法在子 Agent 运行过程中发补充指令、查进度或提前取消。如果子 Agent 理解错了任务,只能等结果回来才知道。
2. Fan-Out:批量启动 Agent,等结果汇总
主 Agent 启动多个子 Agent,然后用 wait_agent 工具收集结果。与内联工具模式不同的是,启动和收集是两个独立的步骤。spawn_agent 始终立即返回,模型自己决定接下来怎么做:马上调用 wait_agent,还是先做点别的事,或者再启动更多 Agent 之后再统一等待。
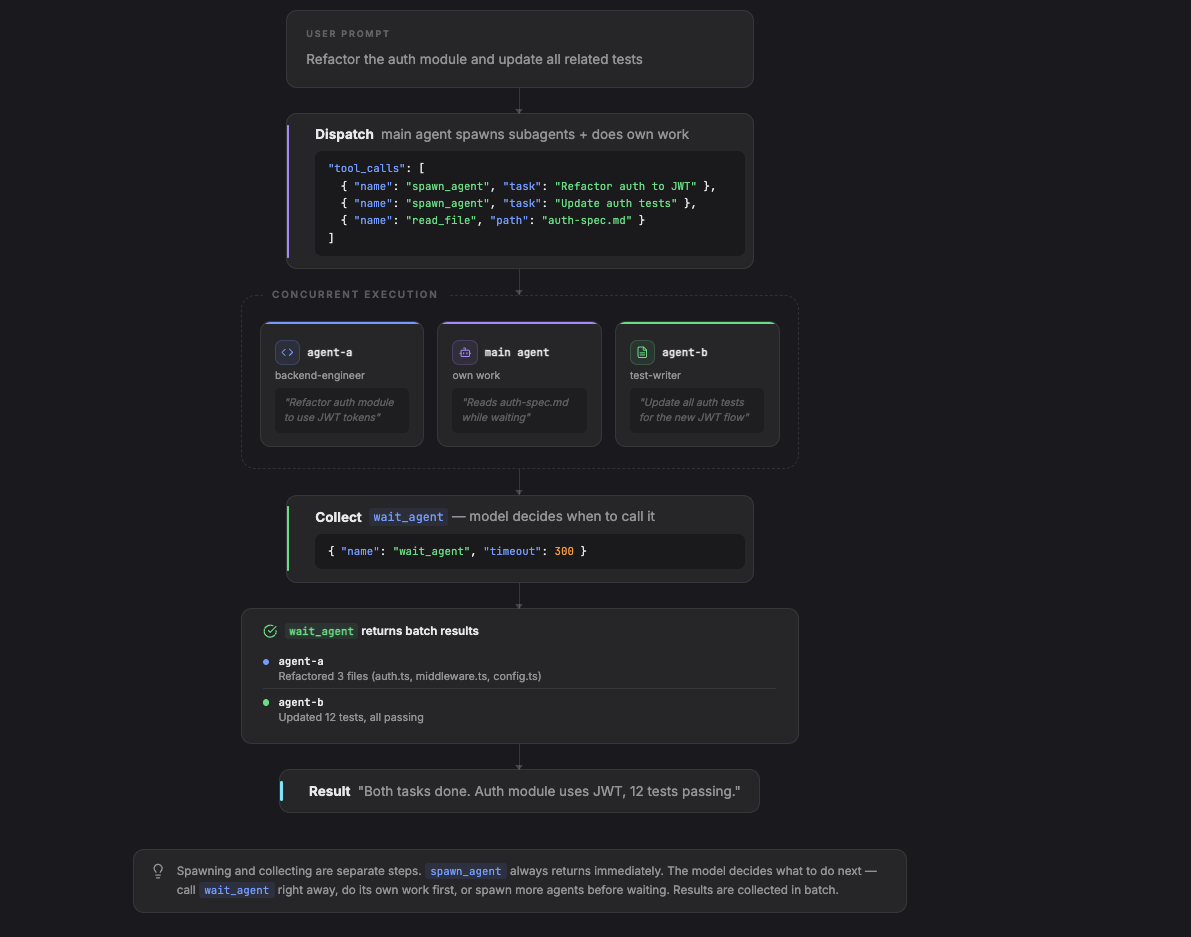
两个核心工具:spawn_agent 派发任务,立即返回一个 ID;wait_agent 阻塞到一个或多个 Agent 完成。
模型控制时序。它可以启动 Agent 后马上调用 wait_agent(退化为同步),也可以先穿插做自己的工作:
[
{ "role": "user", "content": "重构鉴权模块并更新相关测试" },
{ "role": "assistant", "tool_calls": [
{ "name": "spawn_agent", "arguments": { "task": "将鉴权模块重构为 JWT Token 方式", "agent": "backend-engineer" } },
{ "name": "spawn_agent", "arguments": { "task": "为新 JWT 流程更新所有鉴权相关测试", "agent": "test-writer" } },
{ "name": "read_file", "arguments": { "path": "docs/auth-spec.md" } }
]},
{ "role": "tool", "name": "spawn_agent", "content": "已启动 agent-a(backend-engineer),运行中。" },
{ "role": "tool", "name": "spawn_agent", "content": "已启动 agent-b(test-writer),运行中。" },
{ "role": "tool", "name": "read_file", "content": "# 鉴权规范\nJWT Token 使用 RS256……" },
{ "role": "assistant", "content": "两个任务都已开始。规范确认用 RS256。" },
{ "role": "assistant", "tool_calls": [{ "name": "wait_agent", "arguments": { "timeout": 300 } }]},
{ "role": "tool", "name": "wait_agent", "content": "2 个 Agent 已完成:\n- agent-a:重构了 3 个文件(auth.ts、middleware.ts、config.ts)\n- agent-b:更新了 12 个测试,全部通过" },
{ "role": "assistant", "content": "两个任务都完成了。鉴权模块现在使用 JWT……" }
]
这里模型同时启动了两个 Agent 并读了一个文件,然后决定等待。换一个模型可能会在启动后立刻等,或者先多读几个文件再等。工具接口是一样的,怎么调度完全由模型决定。
与模式 1 的核心差别:模型控制什么时候收集结果。它可以启动 5 个 Agent,自己先读几个文件,然后再调用 wait_agent。wait_agent 就像一个全局收件箱,等有 Agent 完成就被唤醒,把所有可用结果一次性返回。
适用场景: 多个相互独立的并行任务,主 Agent 不需要某个子 Agent 的结果才能启动另一个。
局限: 模型需要正确判断什么时候该等待。如果每次启动 Agent 后立刻就调用 wait_agent,那跟模式 1 没什么区别,并行的价值体现不出来。还是没办法给运行中的子 Agent 发补充指令或中途纠偏。
3. Agent Pool:持久化 Agent + 消息通信
主 Agent 启动长期存活的子 Agent,并通过消息与它们持续交互。Agent 跨多次交互保持存活,主 Agent 可以发补充指令、查状态,还能在 Agent 之间协调工作。
这需要更丰富的工具接口:spawn_agent、send_message、wait_agent、list_agents、kill_agent。
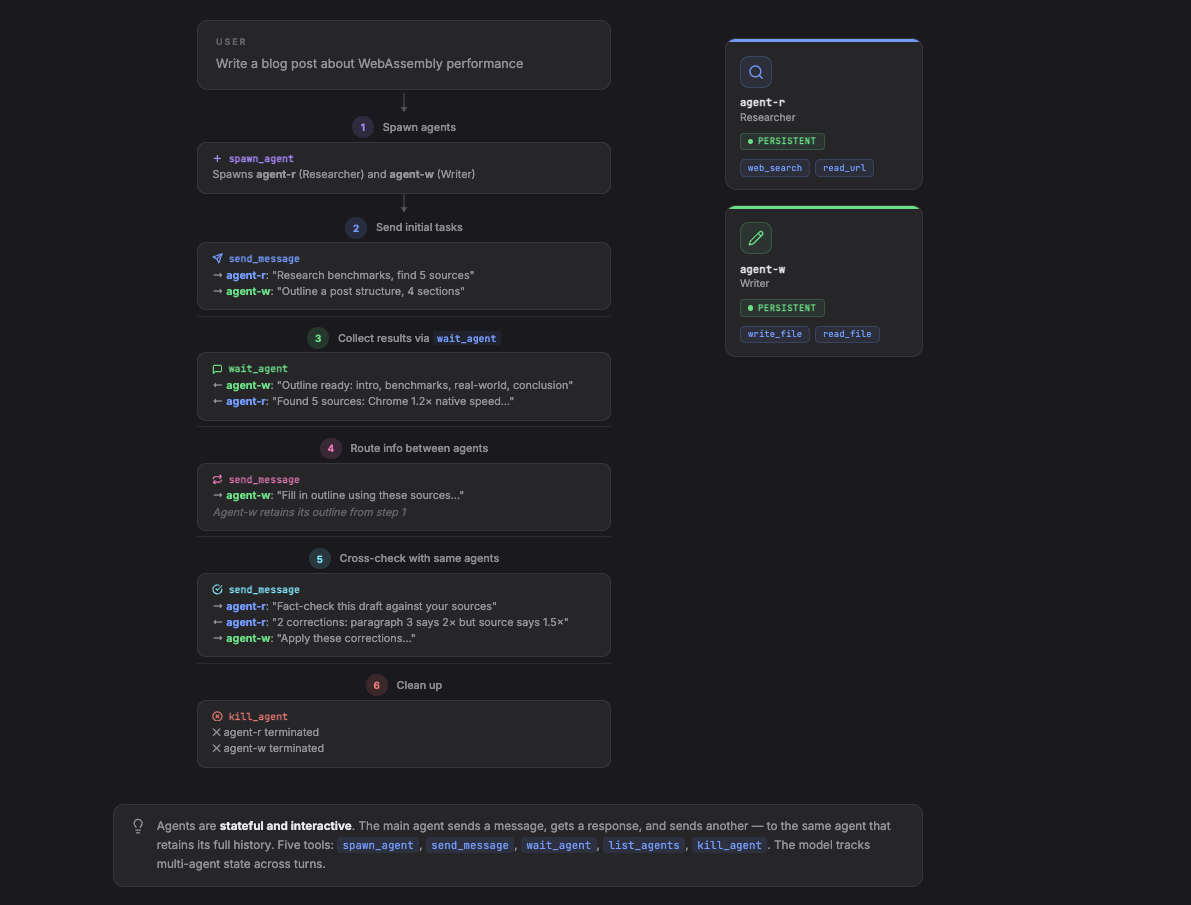
与模式 2 不同,这里的 Agent 是有状态的、可交互的。主 Agent 发一条消息,收到回复,再发下一条消息给同一个 Agent,而这个 Agent 保留了完整的对话历史。这就支持了多步协作的工作流,主 Agent 在不同专家 Agent 之间扮演调度员的角色。
[
{ "role": "user", "content": "写一篇关于 WebAssembly 性能的博客" },
{ "role": "assistant", "tool_calls": [
{ "name": "spawn_agent", "arguments": { "role": "researcher", "tools": ["web_search", "read_url"] }},
{ "name": "spawn_agent", "arguments": { "role": "writer", "tools": ["write_file", "read_file"] }}
]},
{ "role": "tool", "name": "spawn_agent", "content": "已启动 agent-r(researcher)" },
{ "role": "tool", "name": "spawn_agent", "content": "已启动 agent-w(writer)" },
{ "role": "assistant", "tool_calls": [
{ "name": "send_message", "arguments": { "to": "agent-r", "message": "调研 WebAssembly 性能基准测试,找到 5 个有具体数据的来源。" } },
{ "name": "send_message", "arguments": { "to": "agent-w", "message": "拟一个关于 WebAssembly 性能的博客结构大纲,分 4 个部分。" } }
]},
...
{ "role": "tool", "name": "wait_agent", "content": "agent-r 回复:找到 5 个来源:1) Chrome 基准测试显示达到原生速度的 1.2 倍……" },
{ "role": "assistant", "tool_calls": [{ "name": "send_message", "arguments": { "to": "agent-w", "message": "用这些来源填充你的大纲……" } }]},
...
{ "role": "assistant", "tool_calls": [{ "name": "send_message", "arguments": { "to": "agent-r", "message": "对这份草稿进行事实核查……" } }]},
...
{ "role": "tool", "name": "wait_agent", "content": "agent-r 回复:发现 2 处错误:第 3 段引用了 2 倍速,但来源写的是 1.5 倍……" },
{ "role": "assistant", "tool_calls": [
{ "name": "send_message", "arguments": { "to": "agent-w", "message": "应用这些修正:第 3 段改为 1.5 倍……" } },
{ "name": "kill_agent", "arguments": { "agent_id": "agent-r" }}
]},
...
{ "role": "assistant", "content": "最终文章如下……" }
]
agent-r 被调用了两次(先调研,后事实核查),并且在第二次调用时还记得第一次找到的资料。模型在一开始就并行给两个 Agent 分配了任务,之后在事实核查环节又转为顺序协调。工具接口不变,调度逻辑全由模型掌控。
结果按消息粒度通过 wait_agent 逐步到达,每次调用 wait_agent 返回下一个 Agent 的回复,主 Agent 可以根据结果即时调整下一条指令。
适用场景: 需要 Agent 跨多个步骤协作的工作流,主 Agent 在专家 Agent 之间充当信息路由。
局限: 主 Agent 需要同时跟踪多个 Agent 的状态、判断什么时候该发追问还是等待、正确地在 Agent 之间传递信息。小模型很容易搞混哪个 Agent 有哪些上下文,或者忘了在做完任务后调用 kill_agent。即使是前沿模型,同时管 2-4 个 Agent 也只能说"还行"。
4. Teams:Agent 之间直接互发消息
Agent 之间直接通信,不经过主 Agent 中转。主 Agent 负责组建团队、定义角色,然后退到幕后。各 Agent 通过直接消息或共享邮箱自行协调。
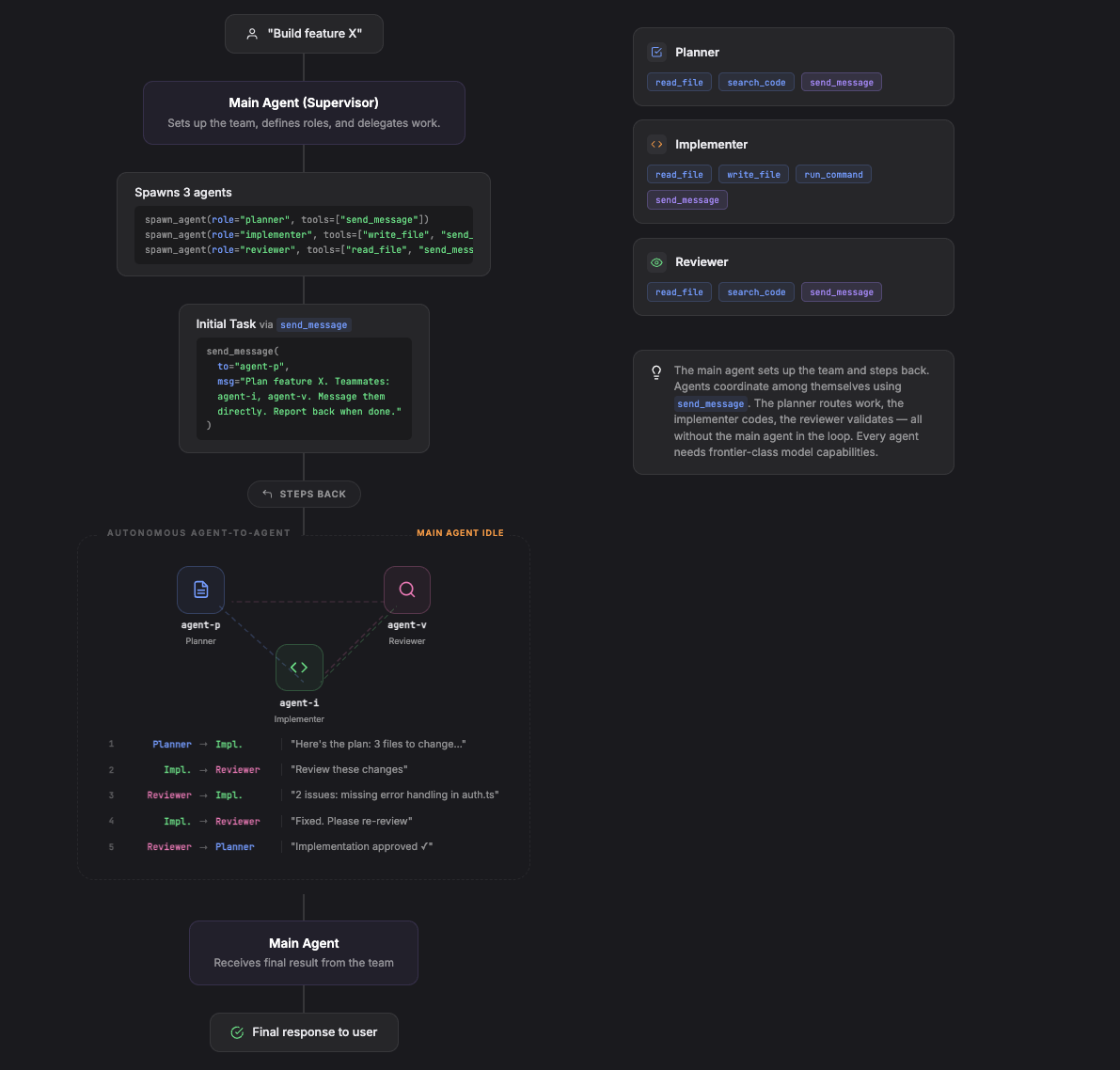
工具接口需要支持跨 Agent 寻址。每个 Agent 的工具集里都有 send_message,可以按名字或路径给其他 Agent 发消息。
从主 Agent 的视角来看,整个对话非常短——组建团队、踢球给规划者,然后等最终汇报。模型可以选择静默等待,也可以定期用 list_agents 查一下进度:
[
{ "role": "user", "content": "开发 Feature X" },
{ "role": "assistant", "tool_calls": [
{ "name": "spawn_agent", "arguments": { "role": "planner", "tools": ["read_file", "search_code", "send_message"] } },
{ "name": "spawn_agent", "arguments": { "role": "implementer", "tools": ["read_file", "write_file", "run_command", "send_message"] } },
{ "name": "spawn_agent", "arguments": { "role": "reviewer", "tools": ["read_file", "search_code", "send_message"] } }
]},
...
{ "role": "assistant", "tool_calls": [{ "name": "send_message", "arguments": { "to": "agent-p", "message": "规划并协调 Feature X 的开发。你的队友:agent-i(实现)、agent-v(审查)。直接给他们发消息。完成后向我汇报。" } }]},
...
{ "role": "assistant", "tool_calls": [{ "name": "wait_agent", "arguments": { "timeout": 60 } }]},
{ "role": "tool", "name": "wait_agent", "content": "超时,没有 Agent 响应。" },
{ "role": "assistant", "tool_calls": [{ "name": "list_agents", "arguments": {} }]},
{ "role": "tool", "name": "list_agents", "content": "agent-p:运行中,agent-i:运行中,agent-v:空闲" },
{ "role": "assistant", "tool_calls": [{ "name": "wait_agent", "arguments": { "timeout": 120 } }]},
{ "role": "tool", "name": "wait_agent", "content": "agent-p 回复:Feature X 已完成。3 个文件有改动,所有测试通过。摘要:……" },
{ "role": "assistant", "content": "Feature X 已开发完成。以下是完成情况……" }
]
规划者给实现者发消息、实现者把代码发给审查者、审查者请求修改——这些全都发生在各 Agent 自己的对话内部,主 Agent 的上下文保持干净。主 Agent 只有在某个 Agent 主动向它汇报时才能看到结果,其余的 Agent 间交流对它完全不透明。
适用场景: 任务规模大到一个 Agent 难以逐步管理所有协调逻辑。
局限: 团队里的每个 Agent 都需要前沿级别的模型能力,不只是主 Agent 一个。每个成员都要独立判断什么时候联系队友、发什么内容、什么时候汇报。模型可能给错 Agent 发消息、忘记汇报完成,或者陷入循环。工程层面也有不少挑战:死锁检测(A 等 B、B 等 A)、冲突解决(两个 Agent 同时改一个文件)、关闭协调。Debug 也很痛苦,Agent 间的消息链难以追踪,而且故障会级联扩散。
怎么选模式
| 模式 | 工具 | 主 Agent 角色 | Agent 生命周期 |
|---|---|---|---|
| 内联工具 | call_agent |
调用方 | 单次任务 |
| Fan-Out | spawn_agent, wait_agent |
调度方 | 单次任务 |
| Agent Pool | spawn, send, wait, list, kill |
协调方 | 多轮持久 |
| Teams | 以上全部 + 跨 Agent send_message |
监督方 | 持久化 |
从模式 1 出发。很多感觉需要多 Agent 协作的任务,用一个精心设计的内联工具调用就能搞定。如果任务确实是多个相互独立的并行子任务,再升级到模式 2。如果 Agent 之间需要跨多步骤协作,才考虑模式 3。模式 4 留给那些协调逻辑本身已经超出单个 Agent 管理能力上限的大型任务。
每往上走一个台阶,对模型能力的要求就高一截。模式 1 只要能调工具就行;模式 2 需要模型能推理"该什么时候 wait";模式 3 需要模型能跨轮次追踪多个 Agent 的状态;模式 4 则要求团队里的每个 Agent 都是前沿级别。如果用的是小模型或者便宜的模型,老老实实待在模式 1 或模式 2。
结果收集的方式也随着模式的升级而变化:模式 1 结果内联在工具返回值里;模式 2 通过 wait_agent 批量收集;模式 3 逐消息增量到达;模式 4 只有 Agent 主动汇报的内容才能被主 Agent 看到,其余的全在 Agent 内部消化。
对于模式 2-4,spawn_agent 永远立即返回,wait_agent 在模型决定调用时收集结果。框架提供工具,模型控制调度。今天需要 4 个 Agent 协作的任务,也许明天一个更强的模型单打独斗就能解决。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)