阿里云知识存储 Skill 上架阿里云官网首批 Agent Skill:让智能体拥有企业级知识库
知识库和 RAG 的概念已经流行了一段时间,很多团队都已经落地了自己的知识库系统。但随着规模扩大,技术债也开始显现:向量库选型纠结了一个月,部署又踩了无数坑,运维成本远超预期,当文档量从几千增长到几百万时,发现原来的架构根本撑不住。在这种"知易行难"的技术浪潮中,一种普遍的焦虑正在蔓延:大模型再聪明,它也不懂我公司的产品文档;Agent 再强大,它也无法高效检索海量企业知识。
问题不在于概念不够好,而在于规模化后的搭建和运维门槛太高。选型、部署、配置、调优,每一步都像是在闯雷区。
针对上述的痛点,Tablestore 建设了一个serverless 的知识库服务,并且将企业级知识库封装成开箱即用的 Skill,直接交到每一位智能体开发者手中。我们将这张"企业级知识网络"从复杂的系统部署和各种复杂配置中解放出来,变成了一句话就能调用的能力。
想要让你的 Agent 拥有企业级知识库吗?Tablestore 知识存储 Skill 将为你揭示答案。
01 告别"知识孤岛":从复杂搭建到自然语言对话
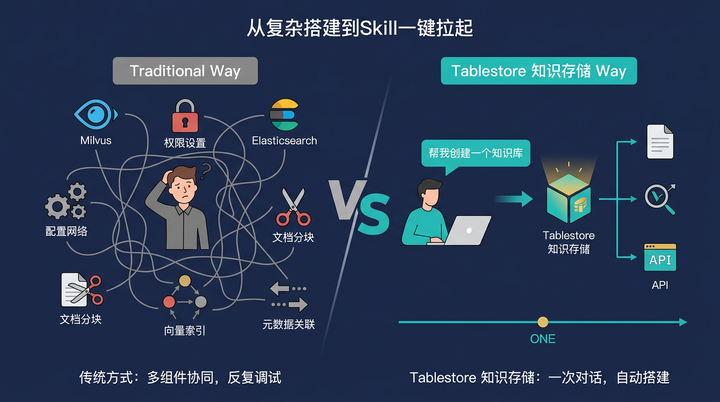
你有没有为智能体的知识库搭建头疼过?
搭建一套可靠的 RAG 知识库系统,流程不短。首先得选型:是用 Milvus 做向量库,还是用 Elasticsearch 做全文检索?选型之后要部署实例、配置网络、设置访问权限。数据模型设计更是一门学问——文档怎么分块?向量索引如何构建?元数据如何关联?整套方案涉及多个组件的协同,对不熟悉的人来说容易卡在某个环节上。
用 Tablestore 的知识存储 Skill,这些步骤可以收进一句话:
"帮我在 Tablestore 里创建一个知识库,支持文档上传和向量检索"
Agent 向 Tablestore 知识库发起 HTTP 请求,Tablestore在后台自动完成了整个知识库服务的搭建, 然后 Agent通过 API 即可上传文档和检索,文档的配置和解析都在服务内自动处理。原来需要翻阅文档、多次调试才能完成的事情,现在一次对话就搞定了。这不仅仅是效率的提升,更是一种交互体验的降维打击——它把复杂的存储架构,折叠进了一次简单的对话里。
02 混合检索:把"查询逻辑"翻译成"自然语言"
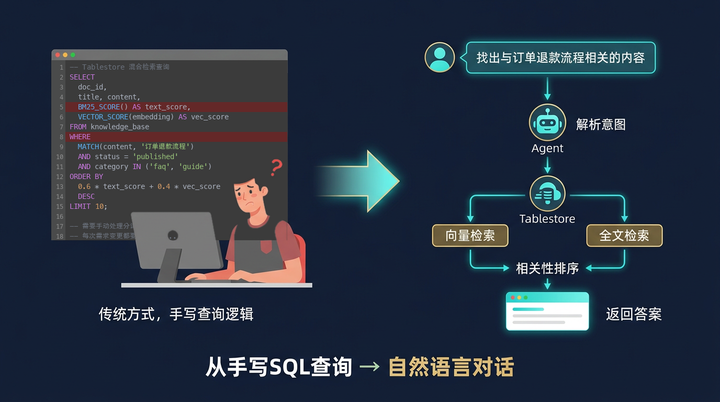
检索知识库通常是智能体开发者的日常。过去,你需要写查询语句、配过滤条件、处理向量相似度计算,稍微手抖输错一个参数,结果就不对。
现在,场景变成了这样:"帮我从产品文档知识库中,找出与'订单退款流程'相关的内容"
此时的 Agent 就像一个经验丰富的助手,它会自动解析你的需求,直接使用自然语言向 Tablestore 发起检索请求。Tablestore 知识库会自动将自然语言转换为向量检索和全文检索进行查询,然后将结果根据相关性进行排序,将最相关的结果返回给 Agent,Agent 再调用 LLM 生成最终的答案。
这种体验,就像是你不再需要亲自去写复杂的查询逻辑,而是坐在屏幕前,通过对话指挥着整个知识引擎的运转。
03 弹性伸缩与智能运维:Serverless 让资源管理触手可及

云原生的核心优势在于"弹性",但弹性的开关往往掌握在复杂的配置项里。Tablestore 知识存储 Skill 让这种弹性变得触手可及。
想象一下你的智能体应用突然爆火的场景,知识库查询量从每天几千飙升到几十万。你不需要去翻文档查找扩容接口,因为 Tablestore 本身就是 Serverless 架构,存储和计算资源自动伸缩,按量付费。
更关键的是成本优势:Tablestore 采用 DiskANN 算法,仅需将 10% 的索引加载到内存,其余 90% 存放在磁盘上,内存成本仅为传统方案的 10%。
04 零门槛体验:从安装到使用的全流程自动化
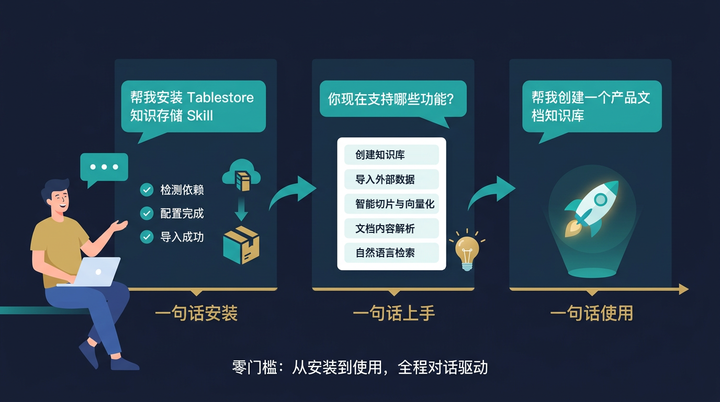
在 AI Agent 的时代,"安装"本身也可以是对话的一部分。你完全不需要自己动手去敲命令行或翻阅文档,因为你的 Agent 比你更懂怎么"照顾"自己。
作为阿里云官网首批上架的 Agent Skill 之一,Tablestore 知识存储 Skill 已经完成了完整的标准化封装。你可以在 Agent 中直接导入 Skill,或者直接在对话框里对 Agent 下达指令:
"帮我安装 alibabacloud-tablestore-agent-storage 这个 Skill"
Agent 足够智能,它会自动检测依赖,引导你完成必要的配置。
一旦 Skill 导入成功,你只需要问它一句:"你现在支持哪些功能?给我一个上手指南",Agent 就会把能力清单列给你。这才是真正的"零门槛"——不仅操作是零门槛的,连"学会使用工具"这个过程,也被 AI 承包了。
核心能力一览
Tablestore 知识库 Skill 为你封装了以下企业级能力:
-
海量知识存储:单知识库可支持上亿文档,且效果和性能和几百文档时一致
-
跨终端、跨 Agent 共享:云端知识库相对于本地知识库可以轻松实现跨终端、跨 Agent 的共享
-
混合检索引擎:单个引擎同时支持向量检索和全文检索,且内置了最佳的默认配置策略,用户无需学习知识库配置即可一键开始使用。
-
Serverless 架构:存储计算分离,无需关心运维和扩容
-
高可用保障:数据三副本存储于多可用区,99.99% 服务可用性,数据可靠性 11 个 9,相对于本地磁盘,数据可以保存更久,更安全
-
生态无缝集成:完整接入 LangChain、LlamaIndex、Dify、AgentScope 等主流框架,可以直接作为 Dify 的外置知识库使用
应用场景
Tablestore 知识库 Skill 适用于以下典型场景:
-
企业知识库问答:保存产品文档、技术手册、SOP 规范,让智能体基于私有数据准确作答,减少模型幻觉
-
智能客服系统:聚合多维度知识指标,快速响应用户咨询,向量 + 全文混合检索提高问答准确率
-
文档检索平台:支撑海量文档的全文检索与语义搜索,满足企业知识管理需求
未来展望:从"被动存储"到"主动知识管理"
目前 Skill 覆盖的是知识库管理、混合检索、容量配置、索引构建这些核心场景,已经能满足大部分智能体开发需求。接下来我们计划进一步扩展它的能力边界:
-
知识自动归档:让 Agent 能感知知识生命周期,当文档更新时,自动将旧版本转历史归档,而不是等你来操作。
-
知识关联分析:根据用户的查询模式,自动发现知识关联,帮 Agent 构建更完整的知识图谱,让每次检索都更有价值。
-
检索效果优化:当检索命中率或准确率异常时,Agent 自动分析原因并给出分块策略或索引优化建议,减少人工排查的时间。
我们希望 Tablestore 知识存储 Skill 不只是一个听指令干活的工具,而是逐步成为你在智能体开发中的搭档——你还没开口问,它已经把知识存储和检索管理安排得明明白白。
立即体验
点击下方链接下载 Tablestore 知识存储 Skill,让你的智能体拥有企业级知识库能力:
https://skills.aliyun.com/skills/alibabacloud-tablestore-agent-storage
阿里云表格存储 Tablestore,让每一个智能体都拥有不忘事的超能力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)